
1. 소개
이 글에서는 모델의 성능 평가하는 지표들에 대해 알아보자
모델을 평가하는 목적은 오버피팅을 방지하고, 최적의 모델을 찾는 것이다.
모델 성능을 평가하기 위해선 결국 답안지가 있어야 하므로, 지도학습에서만 사용 가능하다.
모델 성능을 평가하는 방법은 여러가지가 있지만 크게 회귀와 분류에 따라 평가 방법이 달라지게 된다.
| 모델링 목적 | 목표 변수 유형 | 관련 모델 | 평가 방법 |
|---|---|---|---|
| 회귀 | 연속형 | 선형회귀 등 | MSE,RMSE,MAE, MAPE 등 |
| 분류 | 범주형 | 로지스틱 회귀 등 | 정확도, 정밀도, 재현율, F1 - score |
2. 회귀 모델 성능 평가
회귀 모델에서 평가지표로는 MSE, RMSE, MAE. MAPE, R2 - score 등이 있다.
이 값들은 오차이기 때문에 작을 수록 해당 모델의 성능이 좋다는 것을 의미한다.(R2 score 제외)
MSE(Mean Squared Error) 평균 제곱오차
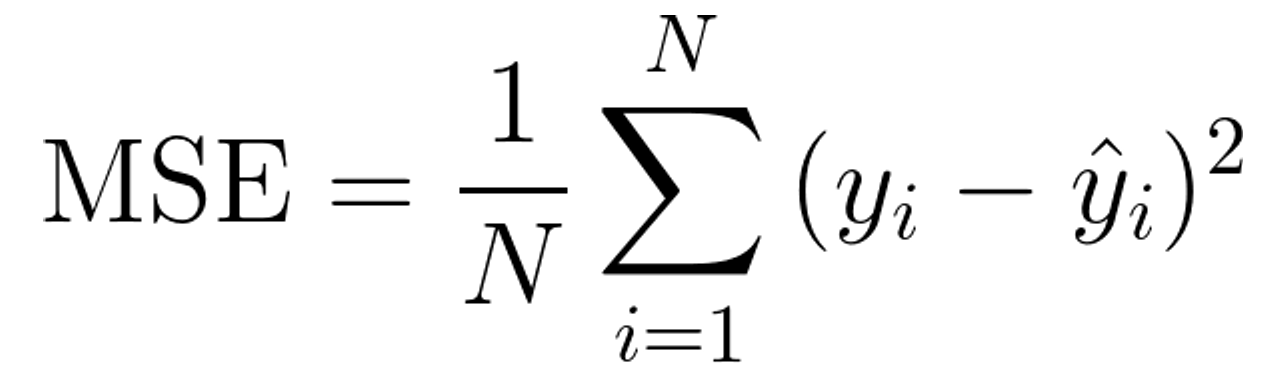
((y_train - y_predict)**2).mean()MSE는 실제 값과 예측 값의 차이를 제곱한 값들의 평균을 구한 것이다.
큰 오차에 대해 더 큰 가중치를 부여하기 때문에 이상치에 민감하다.
MSE는 모델이 얼마나 큰 오차를 자주 만들어내는지 확인하는데 유용하다.
RMSE (Root Mean Squared Error) 평균 제곱근 오차
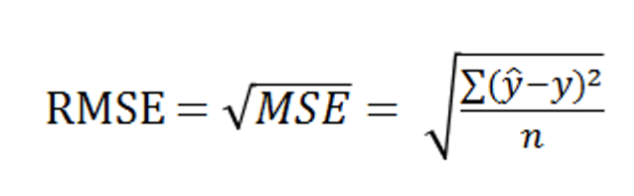
((y_train - y_predict)**2).mean() ** (1/2)
MAE ** (1/2)RMSE는 MSE에 제곱근을 취한 값이다.
MSE와 마찬가지로 이상치에 민감하지만, 오차단위가 원래 데이터 단위와 일치하기 때문에 해석하기 쉽다는 장점이 있다.
MAE (Mean Absolute Error) 평균 절대 오차
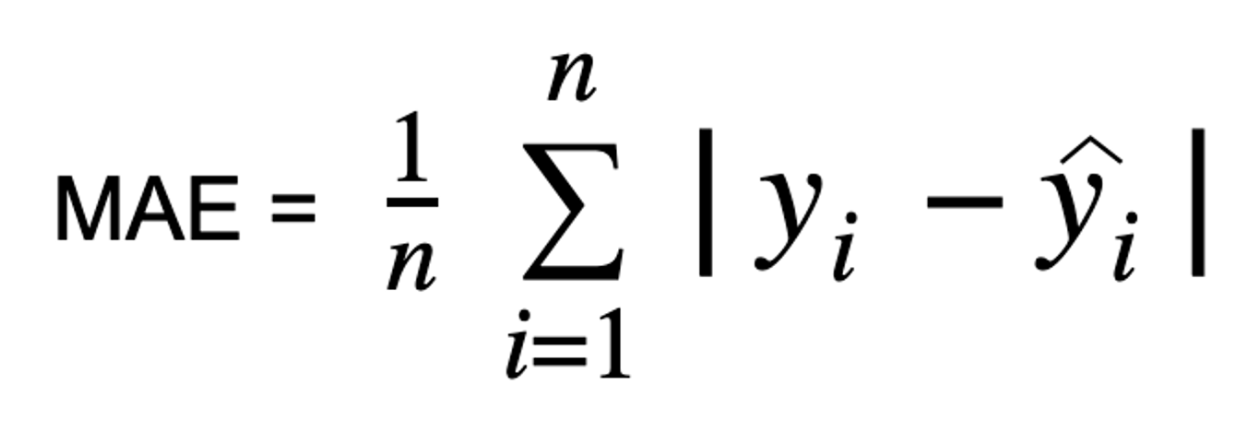
abs(y_train - y_predict).mean()MAE는 실제 값과 예측 값을 평균한 것.
이상치의 영향을 덜 받고 원래 데이터와 단위가 일치해 해석하기 쉽다.
MAE는 이상치가 중요하지 않은 경우에 적합하다.
MAPE (Mean Absolute Percentage Error) 평균 절대 비율 오차
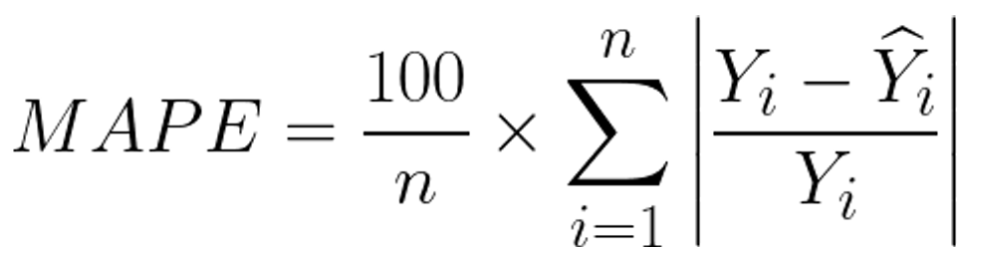
abs((y_train - y_predict)/y_train).mean()MAPE는 실제값에 대해 예측값의 오차비율을 평균낸 것이다.
오차를 백분율로 표현하기 때문에 결과를 해석하기 쉽다.
MAPE는 실제 값이 0에 가까우면 해당 식에서 분모가 매우작아져 문제가 될 수 있다.
MAPE는 실제 값의 크기에 따라 오차가 달라지므로 상대적인 오차가 중요할 때 사용한다.
R2 Score(결정 계수)
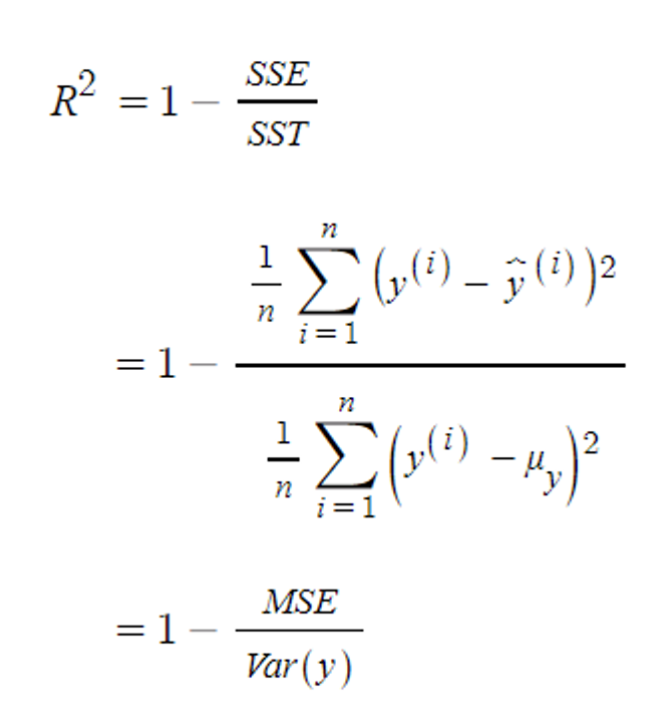
from sklearn.metrics import r2_score
r2_score(y_test, y_predict)R2 스코어는 결정계수로서 예측모델과 실제모델이 얼마나 강한 상관관계를 갖고 있는지를 알 수 있다.
결정계수가 1에 가까울수록 좋고, 0에 가까울수록 안좋다
3. 분류 모델 성능 평가
분류 모델의 성능을 평가할 때는 회귀와 다르게 좀 더 명확하게 모델의 성능을 평가할 수 있다.
실제로 모델이 올바르게 분류를 했는지 여부를 판단 할 수 있기 때문이다.
여러 분류모델의 성능 평가지표에 대해 알아보기 전에 혼동행렬에 대해 알아보자
혼동행렬(Confusion Matrix)
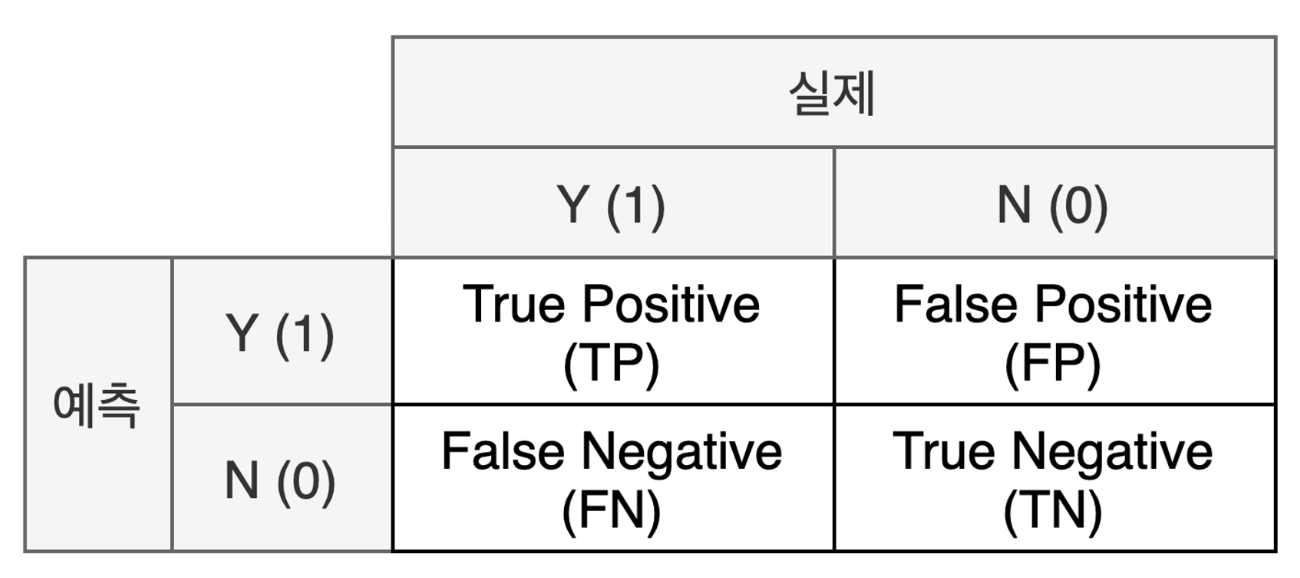
혼동 행렬은 분류의 예측 범주와 실제 데이터의 분류 범주를 교차표로 정리한 형태의 행렬이다.
실제 값에 비해, 모델이 어떻게 분류했는지를 한눈에 파악 가능하다.
혼동행렬은 2X2 행렬의 형태로만 나타나는게 아닌 nXn 형태로 존재 할 수 있다.
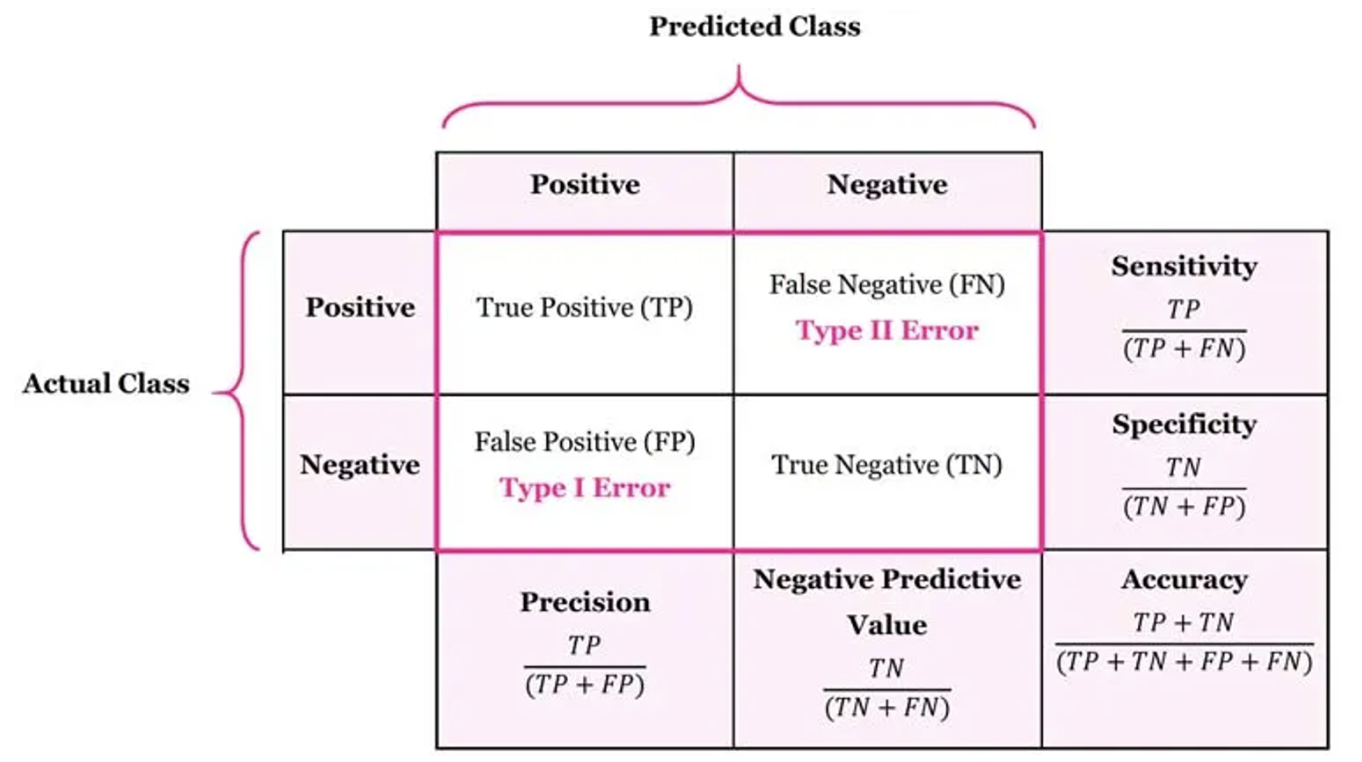
혼동행렬에서 위 사진과같이 여러 평가 지표들이 존재한다.
이때 FP를 제 1종 오류, FN을 제 2종 오류라고 한다.
정확도(Accuracy : ACC)
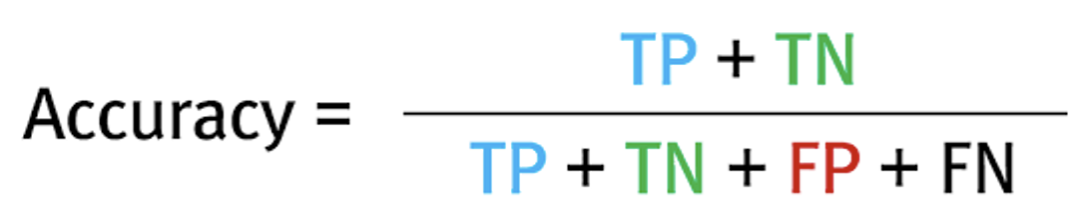
예측이 현실에 부합할 확률이다. 예측 결과 전체를 분모에 넣고, 예측에 성공한 빈도를 분자에 넣어 계산한다.
정확도가 높다는 것은 예측이 모델이 예측을 잘한다고 볼 수 있고,
가장 간단히 생각해볼 수 있는 지표이기때문에 여러 머신러닝 예제에서 평가할 때 자주 사용된다.
특이도(Specificity : S)

현실이 실제로 부정일 때 예측 결과도 부정일 확률이다. 참부정률이라고도 한다.
특이도를 뒤집어서 1 - specificity 계산을 하면, 실제로 부정일때 예측 결과는 긍정일 확률이 구해진다.
이를 거짓부정률이라고 하며, 거짓긍정률은 재현율과 함께 ROC 곡선을 산출하는데 사용한다.
정밀도(Precision : P)
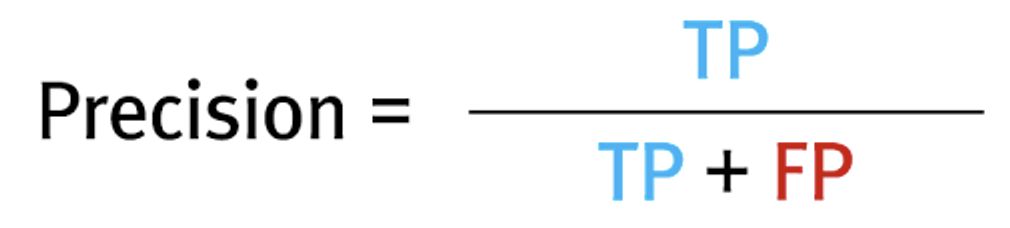
예측 결과가 긍정일때 실제로 긍정일 확률이다.
일반적으로 F1 스코어를 산출할때 사용된다.
민감도(Sensitivity) or 재현율(Recall : R)

현실에서 실제로 긍정일때, 실제로 예측 결과가 긍정일 확률이다.
민감도 또한 F1 스코어를 계산하거나 ROC 곡선을 산출하는데 사용된다.
정밀도와 재현율 사이의 trade off
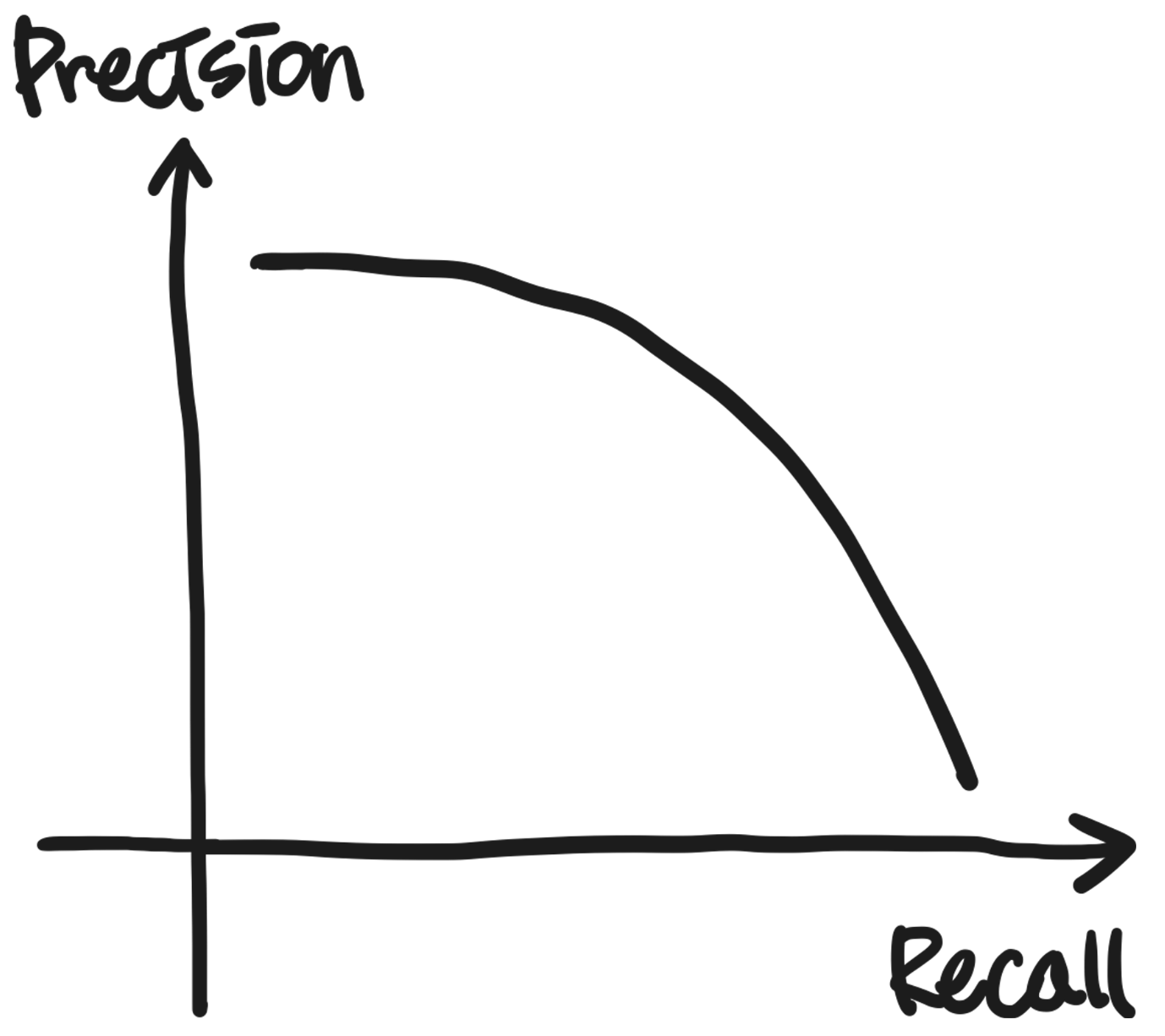
정밀도와 재현율을 모두 고려하려고 하다보면, 서로가 상충된다는걸 알 수 있다.
그렇기 때문에 좋은 Tradeoff에서 최적의 지점을 찾기 위해 F1-score라는 평가지표를 사용하게 된다.
F1 - score
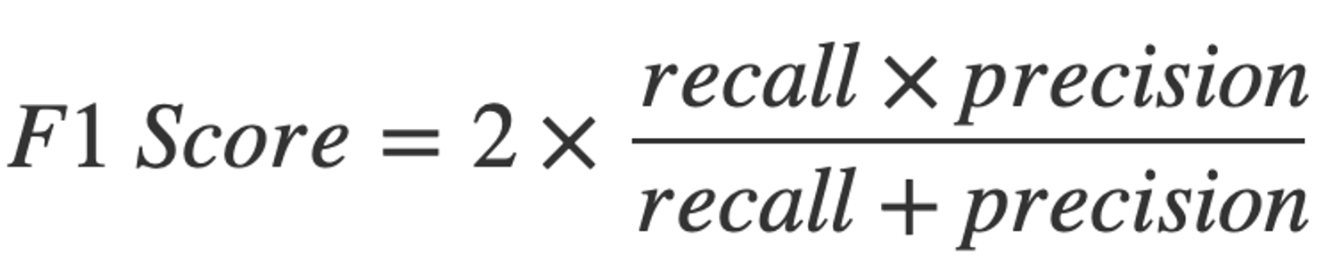
F1 - score은 정밀도와 재현율을 모두 고려하는 평가지표이다.
이는 정밀도와 재현율 사이의 균형을 중시할때 많이 사용한다.
계산 결과는 0과 1사이로 나타나고, 1에 가까울 수록 성능이 뛰어나다고 할 수 있다.
캐글이나 데이콘과 같은 사이트에서 모델을 평가할때 F1 스코어를 사용하는 경우가 많다.
ROC-Curve(Receiver Operating Characteristic Curve)
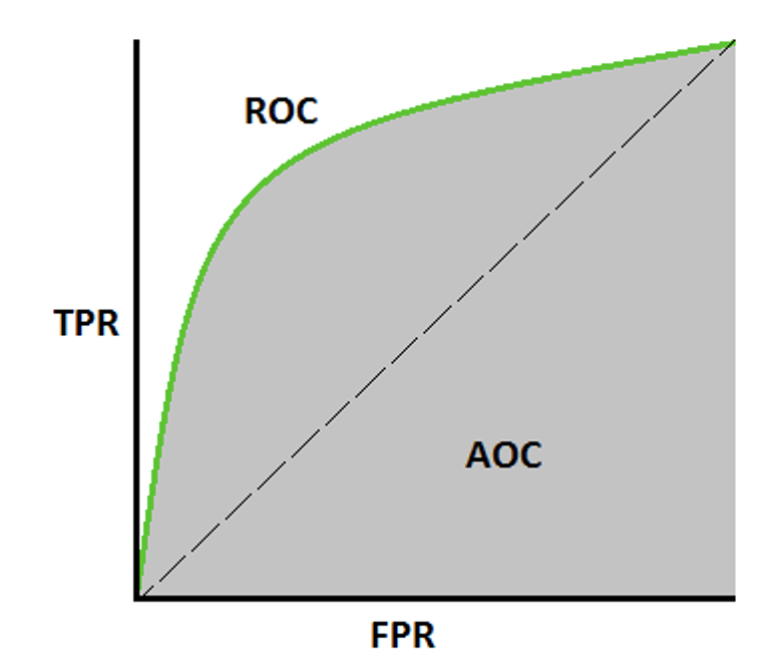
ROC-Curve는 분류모델의 성능을 보여주는 그래프로 x축이 FPR(1-특이도), y축이 TPR(민감도)인 그래프이다.
이 커브에서는 AUC(Area Under Cureve, 그래프 아래 면적)을 이용해 성능을 평가한다.
AUC가 클수록 정확히 분류함을 뜻한다.
AUC는 반드시 0.5보다 크며, y=x 직선을 참조선이라 하는데 이보다 위에 그려져야한다.
AUC = 0.9 이면 90%의 확률로 재대로 분류함을 의미한다.
