네이버 기프트샵과 텐바이텐의 상품 데이터를 크롤링해 검색/추천용 통합 DB를 구축하는 것을 목표로 한다. 그러나 두 사이트의 데이터 제공 방식과 스키마는 크게 다르다.
- 네이버 기프트샵
- 공식 검색 API 또는 HTML에서 JSON 형태의 응답 제공
- 상품 ID, 가격, 옵션, 리뷰 수, 별점, 판매량 등 구조화된 데이터 제공
- 순위 정보(
ranking) 등 마케팅 데이터도 포함 - 비교적 크롤링/정제가 용이
- 텐바이텐(10x10)
- 공식 API 제공 X → HTML 파싱 필요
- 가격·할인율·배송·옵션 정보가 HTML에 섞여 있음
- 리뷰 수, 판매량 같은 지표 제공이 제한적
- 찜(
wish_count) 같은 간접적인 인기도 지표만 존재
이처럼 한쪽은 JSON API 기반으로 구조화되어 있지만 다른 한쪽은 HTML 파싱 중심의 비정형 데이터이기 때문에 단일 테이블에 바로 넣으면 NULL 필드가 많아지고 유지보수가 어렵다는 문제가 있다. 또한, 신규 쇼핑몰을 추가할 경우 스키마 확장이나 ETL 로직 수정이 불가피하기 때문에 원본 → 정제 → 통합 구조로 설계하는 것이 필요하다.
Extract (추출) : 원본 데이터 소스에서 데이터를 가져오는 단계
Transform (변환): 가져온 데이터를 정제하고 변환하는 단계
Load (적재) : 정제된 데이터를 최종 저장소(DB, Data Warehouse 등)에 넣는 단계
설계 목표
1, 사이트별 데이터 차이를 흡수할 수 있는 구조 설계
2. 검색/추천에 필요한 핵심 필드만 통합
3. 원본 데이터 보존으로 재처리 가능하게 설계
4. 신규 쇼핑몰 추가 시 확장성 확보
크롤링 데이터 정의
네이버 기프트샵
| 컬럼 | HTML 경로/속성 |
|---|---|
product_id | <li id="12102609019"> |
title | <strong class="productCardResponsive_title__cBB5e"> |
brand | <a class="productCardResponsive_store_link__ZpmfV"> |
image_url | <img src="...jpg?type=f480_480"> |
product_url | <a class="productCardResponsive_link__mS28Q" href="..."> |
ranking | <span class="rankingResponsive_number_area__C58qY">1</span> |
original_price | <span class="productCardResponsive_original_price__nif5z">100,000원</span> |
sale_price | <span class="productCardResponsive_price__0BAAR"><span>98,000</span>원</span> |
discount_rate | <em class="productCardResponsive_discount__Ho17a">2%</em> |
rating | <span class="productCardResponsive_score__uL_in">5.0</span> |
review_count | <span class="productCardResponsive_number__4tF51">13</span> |
sold_count | <div class="productCardResponsive_wrap_view__XuRnR">125명이 어제 샀어요</div> |
텐바이텐
| 컬럼 | HTML 경로/속성 |
|---|---|
product_id | <a href="/shopping/category_prd.asp?itemid=6932603"> → itemid |
title | <p class="pdtName"> |
brand | <p class="pdtBrand"> |
image_url | <div class="pdtPhoto"><img src="...jpg"> |
product_url | <div class="pdtPhoto"><a href="..."> |
original_price | <p class="pdtPrice"><span class="txtML">1,400원</span></p> |
sale_price | <p class="pdtPrice"><span class="finalP">1,260원</span></p> |
discount_rate | <strong class="cRd0V15">[10%]</strong> |
wish_count | <li class="wishView"><a><span>29</span></a></li> |
DB 설계
원본 데이터 테이블 (raw_product)
raw_product {
BIGINT id PK AUTO_INCREMENT
VARCHAR(255) source -- NAVER_GIFT, TENBYTEN
VARCHAR(255) product_id -- 사이트별 상품 ID
JSON raw_data -- HTML 파싱/JSON 응답 그대로 저장
DATETIME created_at
}raw_data 예시
네이버 기프트샵
{
"product_id": "12102609019",
"title": "애플 에어팟 프로 2세대",
"brand": "Apple",
"image_url": "https://.../airpods.jpg",
"product_url": "https://gift.naver.com/product/12102609019",
"ranking": 1,
"original_price": 329000,
"sale_price": 299000,
"discount_rate": 9,
"rating": 4.9,
"review_count": 251,
"sold_count": 125
}텐바이텐
{
"product_id": "6932603",
"title": "무드등 미니 가습기",
"brand": "텐바이텐",
"image_url": "https://.../humidifier.jpg",
"product_url": "https://www.10x10.co.kr/shopping/category_prd.asp?itemid=6932603",
"original_price": 14000,
"sale_price": 12600,
"discount_rate": 10,
"wish_count": 29
}상품 통합 테이블 (product)
product {
BIGINT id PK,
VARCHAR(255) source, -- NAVER_GIFT / TENBYTEN
VARCHAR(255) product_id, -- 사이트별 상품 ID
VARCHAR(255) title, -- 상품명
VARCHAR(255) brand, -- 브랜드
VARCHAR(500) image_url, -- 대표 이미지
VARCHAR(500) product_url, -- 상세 페이지 링크
VARCHAR(255) category, -- 카테고리(없으면 NULL)
INT ranking, -- 노출 순위(없으면 NULL)
INT price, -- 최종 판매가 (원 단위)
FLOAT rating, -- 별점(없으면 NULL)
INT review_count, -- 리뷰 수(없으면 NULL)
INT sold_count, -- 판매량(없으면 NULL)
DATETIME created_at,
DATETIME updated_at
}source로 어떤 사이트에서 크롤링한 데이터인지 식별- 네이버만 제공하는
ranking,rating,review_count,sold_count는 텐바이텐일 경우NULL가능 - 텐바이텐은
wishCount같은 찜 개수도sold_count컬럼에 활용 가능
설계 시 고려사항 및 개선 전략
현재 설계에서는 product 테이블에 두 사이트의 데이터를 최대한 통합해 관리하고 있지만 실제 운영 과정에서는 다음과 같은 고민이 생길 수 있다.
첫째, 사이트별 데이터 스키마 차이로 인해 크롤링/정제 단계에서 변환 로직이 복잡해진다. 예를 들어 네이버는 rating, review_count, sold_count를 제공하지만 텐바이텐은 제공하지 않는다. 이 경우 통합 테이블에서 NULL 처리를 반복하게 되고 신규 쇼핑몰을 추가할 때마다 컬럼을 늘리거나 NULL 필드가 늘어나 복잡성이 증가한다.
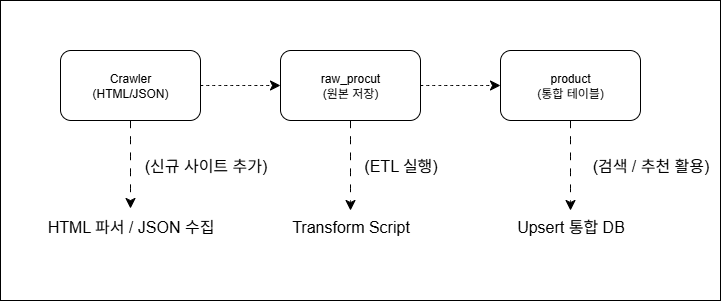
둘째, 원본 데이터 유지가 중요하다. 지금 구조에서는 product 테이블만 존재하므로 HTML/JSON 파싱 과정에서 필드 손실이 발생하면 재처리가 어렵다. 따라서 사이트별로 raw_product 테이블을 두어 크롤링 직후의 데이터를 JSON/BLOB 형태로 저장하고, 정제 스크립트에서 이를 변환해 product테이블에 insert/upsert하는 구조가 안정적이다.
셋째, 자동화와 확장성을 위해 ETL 파이프라인을 설계해야 한다. 예를 들어
- 크롤러에서
raw_product테이블에 JSON 단위로 저장 - ETL 스크립트에서 JSON → 표준화된 DTO 변환 →
product테이블 upsert - 정기적으로 가격 변동이나 품절 여부 업데이트
이런 단계적 설계를 적용하면 사이트 구조 변경에도 빠르게 대응할 수 있고 신규 쇼핑몰을 추가할 때도 ETL 단계만 구현하면 된다. 또한 할인율, 판매량 등의 값은 데이터 정제 시 자동 계산되도록 처리해두면 크롤링 코드가 단순해지고 유지보수가 편리해진다. 예를 들어 original_price와 sale_price만 확보하면 할인율을 스크립트에서 자동 계산하는 식이다.
전체 ETL 흐름도
📝 느낀점
이번 설계를 진행하며 느낀 점은 초기에 데이터 통합만 고려하면 유지보수가 힘들다는 것이다. 네이버와 텐바이텐처럼 데이터 구조가 다른 사이트를 묶다 보면 필드 누락, NULL 처리, 신규 사이트 추가 시 코드 수정 범위가 커지는 문제가 생긴다. 그래서 원본 데이터 보존 + 정제 후 통합이라는 2단계 구조가 필수적임을 깨달았다. 또 자동화 관점에서 보면 크롤링-정제-적재를 분리해두면 어느 한 단계만 수정해도 전체 파이프라인은 안정적으로 유지된다. 향후 로그와 변경 이력을 쌓으면 가격 변동 추적이나 추천 알고리즘 개선에도 활용할 수 있어 설계 단계에서 확장성과 재처리 가능성을 충분히 고려하는 게 중요하다는 걸 느꼈다.
참고
