1. 학습 목표
- RDBMS개념 적립
- SQL 이해
- DB 설계 방법 이해
- 데이터베이스 용어 이해
- AWS RDS 구축
2. 4주차 수업 후기
💡 4주차 수업 듣고 느낀점 이야기, 각자 진행상황 공유🔥 트러블 슈팅(실패한 경험도 성장을 위한 경험!)
- 트러블 슈팅 양식 [ 문제 원인 ] AWS RDS에 구축한 내 서버에 Mysql로 접속이 안됐다. [ 해결 방안 ] 과제를 스타벅스에서 진행하다가 집 와이파이로 바꾸면서 외부ip주소가 바뀌었다. 원래는 0.0.0.0/0 으로 설정해주려하다가 보안에 문제가 될까봐 스타벅스 ip로 인바운드 규칙을 넣어서 집에서는 접속이 안됐던 것이다. 다시 0.0.0.0/0 으로 인바운드 규칙을 바꿔서 접속했다. [ 참고 자료 ]
3. 핵심 키워드
- RDBMS :데이터베이스(테이블)간의 관계를 만들어서 데이터베이스를 관리하는 시스템, RDB를 관리하기 위한 미들웨어 먼저 는? →데이터베이스 관리 시스템

- RDBMS의 장단점
장점
-
정해진 스키마에 따라 데이터를 저장하여야 하므로 명확한 데이터 구조를 보장하고 있습니다.
-
또한 관계는 각 데이터를 중복없이 한 번만 저장할 수 있습니다.
단점
-
테이블간테이블 간 관계를 맺고 있어 시스템이 커질 경우 JOIN문이 많은 복잡한 쿼리가 만들어질 수 있습니다.
-
성능 향상을 위해서는 서버의 성능을 향상 시켜야하는 Scale-up만을 지원합니다. 이로 인해 비용이 기하급수적으로 늘어날 수 있습니다.
-
스키마로 인해 데이터가 유연하지 못합니다. 나중에 스키마가 변경 될 경우 번거롭고 어렵습니다.
-
- RDBMS 종류별 특성

-
Oracle
- Oracle Corporation에서 개발되었으며 현재 가장 널리 사용되는 RDBMS이다.
- 사용자 정의 유형, 상속 및 다형성과 같은 객체 지향 기능을 구현하는 RDBMS를 객체 관계형 데이터베이스 관리 시스템(ORDBMS)이라고 한다.
- Oracle Database는 관계형 모델을 객체 관계형 모델로 확장하여 복잡한 비즈니스 모델을 관계형 데이터베이스에 저장할 수 있다.
- Oracel Database에서 데이터베이스 스키마는 논리 데이터 구조 또는 스키마 객체의 모음이다. 데이터베이스 사용자는 사용자 이름과 이름이 같은 데이터베이스 스키마를 소유한다.
- 스키마 객체는 데이터베이스에서 데이터를 직접 참조하는 사용자 생성 구조이다.
- 데이터베이스는 여러 유형의 스키마 객체를 지원하며 그 중 가장 중요한 것은 테이블과 인덱스이다.
-
MySQL
- MySQL은 오픈 소스이며 무료이고 세계에서 가장 인기있는 DB이다.
- MySQL의 주요 특징은 다음과 같다.
- MySQL은 관계형 데이터베이스이다.
- MySQL소프트웨어는 오픈소스이다.
- MySQL데이터베이스 서버는 매우 빠르고 안정적이며 확장 가능하며 사용하기 쉽다.
- MySQL서버는 클라이언트 / 서버 또는 임베디드 시스템에서 작동한다.
-
SQL Server
- Microsoft에서 개발한 SQL Server는 세계에서 가장 널리 사용되는 데이터베이스 중 하나이다.
- C, C++로 작성되어 있고 SQL Server는 Microsoft Azure Cloud의 일부이다.
-
PostgreSQL
- PostgreSQL은 복잡한 데이터 워크로드를 안전하게 저장하며 SQL 언어를 사용하고 확장하는 오픈 소스 객체 관계형 데이터베이스 시스템이다.
- PostgreSQL은 아키텍처, 안정서으 데이터 무결성, 강력한 기능 세트, 확장성 및 소프트웨어 뒤의 오픈소스 커뮤니티의 헌신으로 성능과 혁신적인 솔루션을 지속적으로 제공하는 것으로 유명하다.
-
IBM DB2
- IBM DB2는 transaction 및 warehousing workload에 고급 데이터 관리 및 분석 기능을 제공하는 관계형 데이터베이스이다.
- 고성능, 데이터 가용성 및 안전성을 제공하도록 설계되었으며 Linux, Unix 및 Windows 운영 체제에서 지원된다.
- DB2 데이터베이스 소프트웨어는 in-memory기술, 고급 관리 및 개발 도구, 스토리지 최적화, 워크로드 관리, 실행 가능한 압축 및 지속적인 데이터 가용성과 같은 고급 기능이 포함되어 있다.
- Ver11.5에서는 AI기능이 추가되어 데이터 과학 및 AI기술을 채택하여 경쟁 차별화를 가질 수 있다.
-
Microsoft Access
- 원격 또는 중앙 스토리지에서는 일반적으로 액세스가 사용되지 않는다.
- 로컬 소규모 데이터베이스에 사용된다.
-
SQLite
- SQLite는 작고 빠르며 독립적이다.
- 신뢰성이 높으며 완전한 기능을 갖춘 SQL 데이터베이스 엔진을 구현하는 C언어 라이브러리이다.
- SQLite는 모든 휴대폰과 대부분의 컴퓨터에 내장되어 있으며 사람들이 매일 사용하는 수많은 다른 응용 프로그램에 번들로 제공된다.
- SQLite 파일 형식은 안정적이고 크로스 플랫폼이다.
- 경우에 따라 SQLite가 direct filesysten I/O보다 빠르다.
- ANSI-C로 작성되었다.
- 크로스 플랫폼으로는 Android, *BSD, iOS, Linux, Mac, Solaris, VxWorks, Windows가 기본적으로 지원되며 다른 시스템으로 쉽게 포팅할 수 있다.
- SQLite를 관리하는데 사용할 수 있는 독립형 CLI클라이언트가 제공된다.
-
MariaDB
- MySQL개발자에 의해 만들어졌으며 오픈 소스를 유지하도록 보장했다.
- 주요 사용자로는 Wikipedia, WordPress.com, Google이 있다.
- MariaDB는 은행에서 웹 사이트에 이르기까지 광범위한 응용 프로그램에서 데이터를 구조화 된 정보로 변환한다.
- MySQL에서 조금의 변화를 가하여 성능을 향상시킬 수 있다.
- MariaDB는 스토리지 엔진, 플러그인 및 기타 여러 도구로 구성된 풍부한 에코 시스템으로 빠르게 확장 가능하며 강력하기 때문에 다양한 용도로 사용될 수 있다.
- MariaDB는 오픈 소스 소프트웨어 및 관계형 데이터베이스로 개발되어 데이터 액세스를 위한 SQL 인터페이스를 제공한다.
- 최신 MariaDB 버전에는 GIS(Geographic Information System)과 JSON(JavaScript Object Notation) 기능도 포함되어 있다.
-
Informix
- IBM Informix는 SQL, NoSQL/JSON, 시계열 및 공간 데이터를 완벽하게 통합 할 수있는 빠르고 유연한 데이터베이스이다.
- 설치 공간이 작고 자체 관리 기능이 있어 Informix는 임베디드 데이터 관리 솔루션에 적합하다.
- Informix의 주요 기능은 다음과 같다.
- Real-time analytics(실시간 분석)
- Fast, always-on transactions(빠른 상시 거래)
- Fewer data management hassless(데이터 관리 번거로움 감소)
- Simplicity(간단함)
-
Azure SQL
- Azure SQL Database는 최신 안정 버전의 Microsoft SQL Server 데이터베이스 엔진을 기반으로하는 범용 관계형 DBaas(Database as a Service)이다.
- SQL Database는 인프라를 관리 할 필요없이 선택한 프로그래밍 언어로 데이터 기반 응용 프로그램 및 웹 사이트를 구추가는 데 사용할 수 있는 고성능의 안정적인 클라우드 데이터베이스이다.
- Azure SQL의 주요 기능은 다음과 같다.
- Fully managed
- 안정적인 최신 버전의 SQL Server 데이터베이스 엔진 및 99.99%의 가용성을 가진 패치된 OS에서 항상 실행되는 PaaS(Platform as a Service) 데이터베이스
- Scalability
- 응용 프로그램의 성능을 향상시켜야 할 필요에 따라 데이터베이스를 쉽게 확장, 축소 또는 분할 할 수 있다.
- Elastic pools, Platform as a Service, Advanced Security, Mornitoring and tuning
- Fully managed
-
- RDBMS의 장단점
- SQL
- DDL
데이터 정의어 (DDL, Data Definition Language)
: DB의 구조를 정의함.- CREATE : 테이블 생성
- ALTER : 테이블 수정
- DROP : 테이블 삭제 (테이블 구조까지 아예 삭제됨, 롤백 불가)
- TRUNCATE : 테이블의 모든 행 삭제 (테이블 구조는 그대로, 데이터만 삭제)
- DML
데이터 조작어 (DML, Data Manipulation Language)
: DB의 레코드를 조작해 조회, 삽입, 수정, 삭제함.- SELECT : 데이터 조회
SELECT 속성명 FROM 릴레이션 [WHERE 조건] [GROUP BY 속성명] [HAVING 그룹조건] [ORDER BY 속성 [ASC | DESC]]; - INSERT : 데이터 삽입
INSERT INTO 릴레이션(속성명) VALUES(데이터) - DELETE : 데이터 삭제 (롤백 가능)
DELETE FROM 릴레이션 [WHERE 조건]; —WHERE이 생략되면 해당 릴레이션 내 모든 튜플 삭제 - UPDATE : 데이터 수정
UPDATE 릴레이션 SET 속성명 =데이터 [WHERE 조건]; —WHERE절 생략되면 해당 릴레이션 내 모든 튜플 수정
- SELECT : 데이터 조회
- DCL
데이터 제어어 (DCL, Data Control Language)
: DB의 접근권한 및 트랜잭션을 제어함.- GRANT : 권한을 부여
GRANT 권한 ON 테이블 TO 사용자 [WITH GRANT OPTION]; —다른 사람과 권한을 나눠가질 수 있는 옵션 - REVOKE : 권한을 회수
REVOKE 권한 ON 테이블 FROM 사용자 [CASCADE CONTRAINTS]; — 연쇄적인 권한 해제(WITH GRANT OPTION으로 부여된 것까지 취소)
- GRANT : 권한을 부여
- DDL
- DataBase 용어

- 필드 Fields 필드 Field는 엑셀에서 열 column에 해당하는 가장 작은 단위의 데이터를 의미합니다. 이 필드는 엔티티의 속성을 표현합니다. 위의 표에서 각 열은 고객의 정보(ID, 이름, 나이, 클래스)를 나타냅니다. 첫번째 행에서 'Lee'라는 값은 NAME 속성을 표현합니다.
- 레코드 Records (튜플 Tuple) 레코드 Record는 논리적으로 연관된 필드의 집합을 의미하며, 엑셀의 행 row에 해당됩니다. 튜플 Tuple 이라고 불리기도 합니다. 여기서 각각의 필드는 특정한 데이터 타입과 크기가 지정되어 있습니다. 즉, 여러 행이 모여 한 열을 이루듯이 여러 필드가 모여 한 레코드를 이루는 것이죠. 위의 테이블은 고객들의 정보들이 모여있습니다. 고객의 ID, 이름, 나이, 등급 데이터가 모여 하나의 레코드를 구성하며, 한 고객 레코드는 4개의 필드(CUSTOMER_ID, NAME, AGE, CLASS)로 이루어져 있다고 할 수 있습니다.
- 테이블 Table (파일 Files) 서로 연관된 레코드의 집합을 테이블 또는 파일이라고 한다.
- 엔티티 Entity 엔티티 entity는 현실 세계에 존재하는 것을 데이터베이스 상에서 표현하기 위해 사용하는 추상적인 개념입니다. 일종의 비유라고 할 수 있죠. 고객을 관리하기 위해 사용하는 위의 데이터베이스 예제에서 ID, 나이, 클래스 라는 정보들을 통해 '고객'이라는 엔티티(객체)를 표현할 수 있고, 동시에 구분할 수 있습니다. 1행의 고객과 2행의 고객을 구분하기 위해 해당 고객의 이름이나 ID를 비교할 수 있죠. 현실 세계에서 사람들(엔티티)을 구분하기 위해 이름, 주민등록번호, 출신지, 성별 등의 특성을 이용하는 것과 마찬가지 입니다.
- 특성 Attribute 엔티티를 설명하는 특성을 Attribute라고 합니다. 이러한 특성들은 각각의 엔티티마다 다를 수 있고, 이를 통해 엔티티를 구별할 수 있습니다.
- 스키마 Schema 스키마 schema 는 전체적인 데이터베이스의 골격 구조를 나타내는 일종의 도면입니다. 스키마는 데이터베이스의 엔티티와 그 엔티티들 간의 관계를 정의합니다. 어떤 타입의 데이터가 어느 위치에 적재되어야 하는지, 다른 테이블이나 엔티티와 어떠한 관계를 맺는지 정의하게 되죠.
- 스키마(Schema) (외부 스키마 / 개념 스키마 / 내부 스키마)


- 외부스키마 : 개인의 입장, '서브스키마'라고도 한다, 사용자 뷰를 가리킨다. 하나의 외부스키마는 여럿이 공유 가능하며, 하나의 DB시스템에 여러 개의 외부스키마가 존재 가능
- 내부스키마 : 시스템 프로그래머나 설계자의 관점에서 바라보는 스키마, 데이터베이스의 물리적 구조를 가리킴(= 실제 저장방법을 기술하는 물리적인 저장장치와 관련됨)
- 개념스키마 : 조직 전체의 입장, 전체적인 뷰를 가리킨다. 개체간의 관계와 제약조건을 나타내고, 데이터베이스의 접근권한/보안/무결성 규칙에 대한 명세를 정의함
- 필드 Fields 필드 Field는 엑셀에서 열 column에 해당하는 가장 작은 단위의 데이터를 의미합니다. 이 필드는 엔티티의 속성을 표현합니다. 위의 표에서 각 열은 고객의 정보(ID, 이름, 나이, 클래스)를 나타냅니다. 첫번째 행에서 'Lee'라는 값은 NAME 속성을 표현합니다.
- 유일성과 최소성 유일성: 하나의 키 값으로 하나의 튜플을 유일하게 식별할 수 있어야 하는 것 최소성: 키를 구성하는 속성 하나를 제거하면 유일하게 식별할 수 없도록 꼭 필요한 최소의 속성으로 구성되어야 한다는 것.
- 키 :키(Key)는 데이터베이스에서 조건에 만족하는 튜플을 찾거나 순서대로 정렬할 때 다른 튜플들과 구별할 수 있는 유일한 기준이 되는 Attribute(속성)입니다. <예시>

-
후보키
-
릴레이션을 구성하는 속성들 중에서 튜플을 유일하게 식별할 수 있는 속성들의 부분집합을 의미
-
모든 릴레이션은 반드시 하나 이상의 후보키를 가져야한다.
-
릴레이션에 있는 모든 튜플에 대해서 유일성과 최소성을 만족시켜야한다.
ex) <학생> 릴레이션에서 '학번'이나 '주민번호'는 다른 레코드를 유일하게 구별할 수 있는 기본키로 사용할 수 있으므로 후보키가 될 수 있습니다. 즉
기본키가 될 수 있는 키들을 후보키라고 합니다.
-
-
기본키
-
후보키 중에서 선택한 주키(Main Key)
-
한 릴레이션에서 특정 튜플을 유일하게 구별할 수 있는 속성
-
Null 값을 가질 수 없습니다. (개체 무결성의 첫번째 조건)
-
기본키로 정의된 속성에는 동일한 값이 중복되어 저장될 수 없습니다.(개체 무결성의 두번째 조건)
ex) <학생> 릴레이션에서 '학번'을 기본키로 정의되면 이미 입력된 학번은 다른 튜플의 '학번' 속성 값으로 입력할 수 없습니다.
-
-
대체키
-
후보키가 둘 이상일 때 기본키를 제외한 나머지 후보키들을 말합니다.
-
보조키라고도 합니다.
ex) <학생> 릴레이션에서 '학번'을 기본키로 정의하면 '주민번호'는 대체키가 됩니다.
-
-
슈퍼키
-
슈퍼키는 한 릴레이션 내에 있는 속성들의 집합으로 구성된 키로서 릴레이션을 구성하는 모든 튜플 중 슈퍼키로 구성된 속성의 집합과 동일한 값은 나타내지 않습니다.
-
릴레이션을 구성하는 모든 튜플에 대해 유일성은 만족하지만, 최소성은 만족시키지 못합니다.
ex) <학생> 릴레이션에서는 '학번', '주민번호', '학번'+'주민번호', '학번'+'주민번호'+'성명' 등으로 슈퍼키를 구성할 수 있습니다. 또한 여기서 최소성을 만족시키지 못한다는 말은 '학번'+'주민번호'+'성명' 가 슈퍼기인 경우 3개의 속성 조합을 통해 다른 튜플과 구별이 가능하지만, '성명' 단독적으로 슈퍼키를 사용했을 때는 구별이 가능하지 않기 때문에 최소성을 만족시키지 못합니다. 즉 뭉쳤을 경우 유일성이 생기고, 흩어지면 몇몇 속성들은 독단적으로 유일성있는 키로 사용할 수 없습니다. 이것을 최소성을 만족하지 못한다고 합니다.
-
-
외래키
- 외래키는 참조되는 릴레이션의 기본키와 대응되어 릴레이션 간에 참조 관계를 표현하는데 중요한 도구로 사용됩니다.
- 외래키로 지정되면 참조 테이블의 기본키에 없는 값은 입력할 수 없습니다. (참조 무결성 조건)ex) <수강> 릴레이션이 <학생> 릴레이션을 참조하고 있으므로 <학생> 릴레이션의 '학번'은 기본키이고, <수강> 릴레이션의 '학번'은 외래키입니다. 즉 각 릴레이션의 입장에서 속성은 기본키가 되기도하고, 외래키가 되기도 합니다. ex) <수강> 릴레이션의 '학번'에는 <학생> 릴레이션의 '학번'에 없는 값은 입력할 수 없습니다. - *** NULL 값 ???? **** - **> 데이터베이스에서 아직 알려지지 않았거나, 모르는 값으로서 "해당 없음" 등의 이유로 정보 부재를 나타내기 위해 사용하는, 이론적으로 아무것도 없는 특수한 데이터를 뜻합니다.**<키 포함관계>

-
- 1:1 관계 / 1:N관계 / N:M관계
1:1 관계(일대일 관계)
1:1 관계란 어느 엔티티 쪽에서 상대 엔티티와 반드시 단 하나의 관계를 가지는 것을 말한다. 예를 들어, 우리나라에서 결혼 제도는 일부일처제로, 한 남자는 한 여자와, 한 여자는 한 남자와 밖에 결혼을 할 수 없다. 남편 또는 부인을 2명 이상 둘 수 없는데, 이러한 관계가1:1 관계다.
1:N 관계(일대다 관계)
1:N 관계는 한 쪽 엔티티가 관계를 맺은 엔티티 쪽의 여러 객체를 가질 수 있는 것을 의미한다. 현실세계에는 1:N관계가 많이 있는데, 실제 DB를 설계할 때 자주 쓰이는 방식이다. 1:N 관계는 N:M 관계처럼 새로운 테이블을 만들지 않는다. 예를 들어, 부모와 자식 관계를 생각해보면, 부모는 자식을 1명, 2명, 3명, 그 이상도 가질 수 있다.이를 부모가 자식을 소유한다고(has a 관계) 표현한다. 반대로 자식 입장에서는 부모(아버지, 어머니의 쌍)를 하나만 가질 수 밖에 없다. 이러한 관계를1:N 관계라고 하며, 계층적인 구조로 이해할 수도 있다. 여러 명의 자식(N)의 입장에서 한 쌍의 부모(1)중 어떤 부모에 속해 있는지 표현해야하므로 부모 테이블의
여러 명의 자식(N)의 입장에서 한 쌍의 부모(1)중 어떤 부모에 속해 있는지 표현해야하므로 부모 테이블의 PK를 자식 테이블에FK로 집어 넣어 관계를 표현한다. *PK(Primary Key): 각 엔티티를 식별할 수 있는 대표키, 테이블에서 중복되지 않는(Unique) 값, Null일 수 없다.* *FK(Foreign Key: 다른 테이블의 기본키를 참조, 모든 필드는 참조하는 기본키와 동일한 도메인(값의 종류&범위)을 갖는다.모든 필드 값은 참조하는 기본키와 동일하거나 null 일 수 있다.* 즉 부모 테이블(1)에서는 내 자식들이 누구인지 정보를 넣을 필요가 없고, 자식 테이블(N)에서만 각각의 자식들이 자신의 부모 정보(FK)를 넣음 으로써 관계를 표현할 수 있다.N:M 관계(다대다 관계)
N:M 관계는 관계를 가진 양쪽 엔티티 모두에서1:N 관계를 가지는 것을 말한다. 즉, 서로가 서로를1:N 관계로 보고 있는 것이다. 예를들어, 학원과 학생의 관계를 생각해보면, 한 학원에는 여러명의 학생이 수강할 수 있으므로1:N 관계를 가진다. 반대로 학생도 여러개의 학원을 수강할 수 있으므로, 이 사이에서도1:M 관계를 가진다. 그러므로 학원과 학생은N:M 관계를 가진다고 할 수 있다.
N:M 관계는 서로가 서로를1:N 관계,1:M 관계로 갖고 있기 때문에, 서로의PK를 자신의 외래키 컬럼으로 갖고 있으면 된다. 일반적으로N:M 관계는 두 테이블의 대표키를 컬럼으로 갖는 또 다른 테이블을 생성해서 관리한다.
4. 알아두면 좋을 SQL 연산자 및 함수 정리
- Built-in functions
- ABS: Returns the absolute value of a number
- AVG: Returns the average value of an expression
- CEILING: Returns the smallest integer value that is greater than or equal to a number
- COUNT: Returns the count of an expression
- FLOOR: Returns the largest integer value that is equal to or less than a number
- MAX: Returns the maximum value of an expression
- MIN: Returns the minimum value of an expression
- RAND: Returns a random number or a random number within a range
- ROUND: Returns a number rounded to a certain number of decimal places
- SIGN: Returns a value indicating the sign of a number
- SUM: Returns the summed value of an expression
- Built-in functions examples
SELECT COUNT(customerID) FROM customers; SELECT (customerID) FROM customers; SELECT sum(UnitPrice) FROM products; SELECT MAX(UnitPrice) FROM products; SELECT MIN(UnitPrice) FROM products; SELECT CEILING(sum(UnitPrice)) FROM products; - Built-in functions 2
- ASCII: Returns the number code that represents the specific character
- CHAR: Retruns the ASCII character based on the number code
- CHARINDEX: Returns the location of a substring in a string
- DATELENGTH: Returns the length of an expression (in bytes)
- LEFT: Extracts a substring from a string (starting from left)
- LOWER: Converts a string to lower-case
- RIGHT: Extracts a substring from a string (starting from right)
- UPPER: Converts a string to upper-case
- SUBSTRING: Extracts a substring from a string
- Built-in functions examples2
SELECT LEFT(CompanyName, 5) FROM customers LIMIT 5; SELECT RIGHT(CompanyName, 5) FROM customers LIMIT 5; SELECT UPPER(CompanyName) FROM customers LIMIT 5; SELECT LOWER(CompanyName) FROM customers LIMIT 5; SELECT CONCAT(LOWER(CompanyName), UPPER(CompanyName)) FROM customers LIMIT 5; - 기능적 Built-in functions
- 중복되지 않는 값을 query
SELECT distinct(country) FROM customers; - Null 값인지를 출력
SELECT companyName, ISNULL(country) FROM customers; 기능적 Built-in Functions WHERE FIELD IS NOT NULL;
- 중복되지 않는 값을 query
- Group by, Alias, Having
- Group by clause: 특정한 조건(Filed의 값을) 기준으로 데이터를 묶음
SELECT Apply함수(`column`) FROM `테이블의 목록` GROUP BY `묶을 Field` - Having clause: Groupby 후 조건 절
SELECT Apply함수(`column`) FROM `테이블의 목록` GROUP BY `묶을 Field1, Field2` HAVING `조건절` - Alias: 특정 Table 또는 Column의 이름을 변경해줌 변경전:
SELECT supplierID, SUM(UnitPrice) FROM products GROUP BY supplierID LIMIT 5; 변경후:
변경후:SELECT supplierID, SUM(UnitPrice) as unitprice FROM products GROUP BY supplierID LIMIT 5;
- Group by clause: 특정한 조건(Filed의 값을) 기준으로 데이터를 묶음
- JOIN :Table 간의 연결 관계를 이용해서 두가지 테이블 이상의 정보를 하나로 합쳐서 표시하는 기법

- Inner JOIN
SELECT `column 목록` FROM `테이블의 목록` INNER JOIN `조인 테이블` ON `기준 Column`SELECT A.column_a, B.column_b FROM TABLE_A as A INNER JOIN TABLE_B as B ON A.key_column = B.forginkey_column
이렇게 INNER JOIN문을 where 조건절로도 Query 가능SELECT A.column_a, B.column_b FROM TABLE_A as A, TABLE_B as B WHERE A.key_column = B.forginkey_column
- Left JOIN
SELECT column_name(s) FROM table1 LEFT JOIN table2 ON table1.column_name = table2.column_name; - Right JOIN
SELECT column_name FROM table1 RIGHT JOIN table2 ON table1.column_name = table2.column_name; - Full Outer JOIN MySQL은 Full Outer JOIN을 제공하지 않는다.
- Inner JOIN
실습
- ERD 모델링 과정
- No.1
-
유저,팔로우/팔로잉, 게시글(게시물), 좋아요, 댓글, DM
유저가 다른 유저를 팔로잉한다.
다른 유저가 나를 팔로우한다.
유저가 다른 유저의 게시물에 좋아요를 누른다. 댓글을 단다.
다른유저가 나의 게시물에 좋아요를 누른다. 댓글을 단다.
유저가 다른 유저와 DM을 주고 받는다.
하나의 게시글에는 여러 개의 게시물이 들어갈 수 있다.
게시글에 태그를 한다(사람언급 및 ‘#’ 다 가능)
한 유저가 게시글에 답글을 단다.
유저가 스토리를 게시한다.
유저가 다른 유저를 검색한다.
-
- No.2
-
user-user_id,이메일(VARCHAR), 아이디(VARCHAR), 비밀번호(VARCHAR), nickname, profile_image_URl TEXT, intro TEXT ,status,createAt,updateAt, name
post- post_id, caption(text), user_id, status,createAt,updateAt
story- story_id, story_caption(text), ,user_id, , status,createAt,updateAt
media- media_id, file_data VARCHAR, status,createAt,updateAt
media_video_view- media_video_view, media_id, view
tag-tagid, caption(text),media_id
reply- replyid, userid, postid, status,createAt,updateAt, content TEXT
likes- liekID, user_ID, post_ID, createAt, Like_status
following- following_ID, from_user, to_user
follower- follower_ID, to_user, from_user
Room-Room_id, sender(user_id), receiver(user_id), message_id, status,createAt,updateAt
message- message_id, content TEXT, status,createAt,updateAt
Searching- searching_id, user_id, createAt
<추가>
Post_media – Post_media_id, post_id, media_id
story에 media_id 추가
-
- No.3
-
한 user가 여러 개의 POST 올리는 것이 가능 1:N
한 post는 여러 개의 MEDIA를 가짐 (1:N or N:M ,여기서는 한 POST에 올린 MEDIA를 다른 POST에 올리지 않는다고 가정하여 1:N으로 가정한다)
한 유저가 여러 개의 댓글을 달 수 있다. 1:N
댓글을 지우면 댓글과 관련된 정보들이 사라지므로 user와 연결테이블을 만들필요없음
마찬가지로 post도 사라지면 post에 연결된 media들도 안보여지기 때문에 연결테이블을 만들필요없음
한 유저가 올린 게시물은 다른 유저와 겹칠일이 없고 태그로 관리되기 때문에 N:M 링킹테이블을 만들어줄 필요가 없다.
인스타 스토리 or 게시글에 올리는건 media다. 태그는 media에 달리는 것
post와 media를 Linking 하는 테이블을 따로 생성 -> 한 포스트에 여러 개의 미디어가 있을 수 있기 때문에( 업데이트에 용이)
-
- No.1
📝실습 체크리스트
- RDS 구축
- RDS 구축

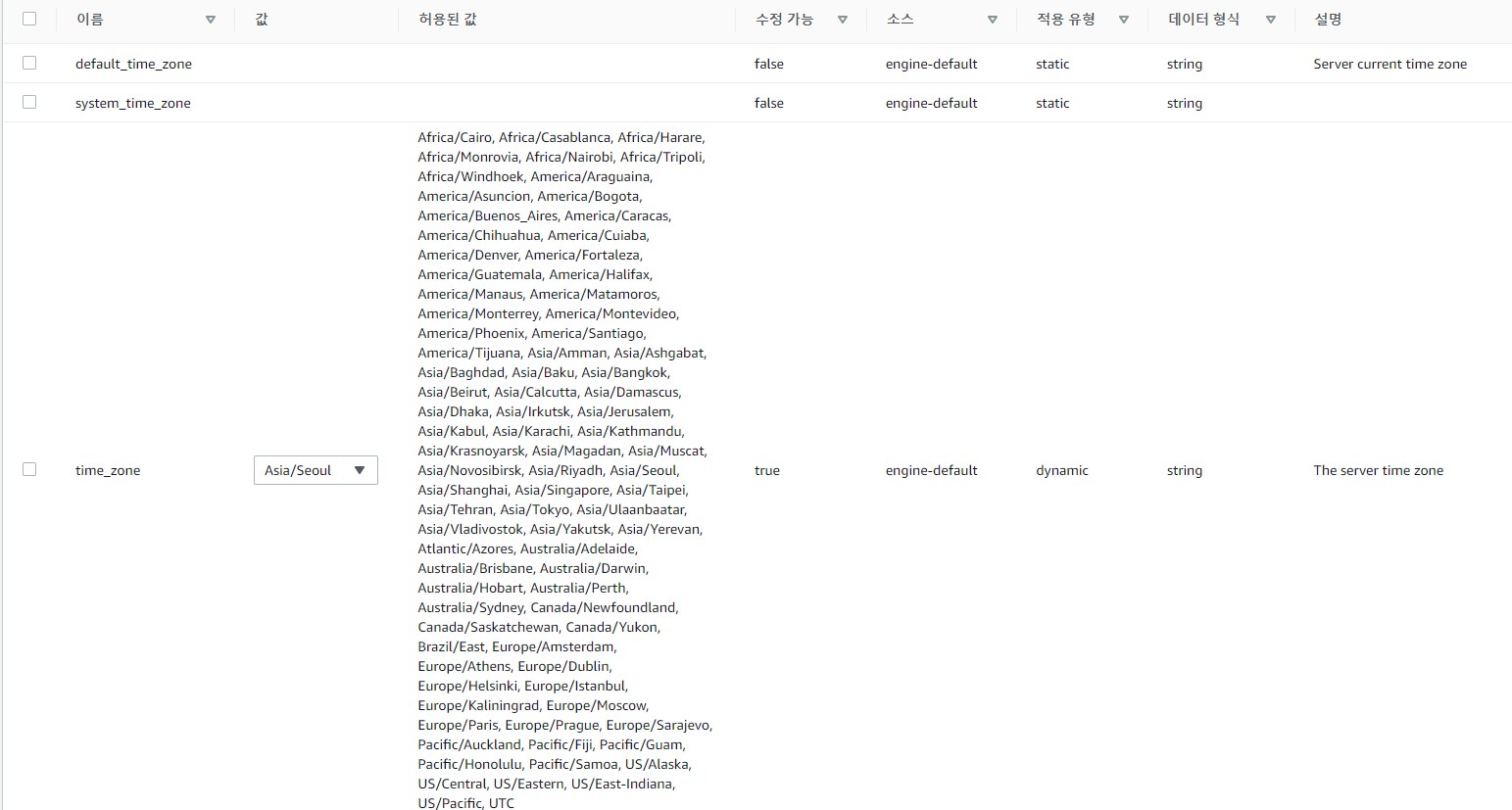
- RDS 인코딩 및 타임존 구축
- RDS 인코딩
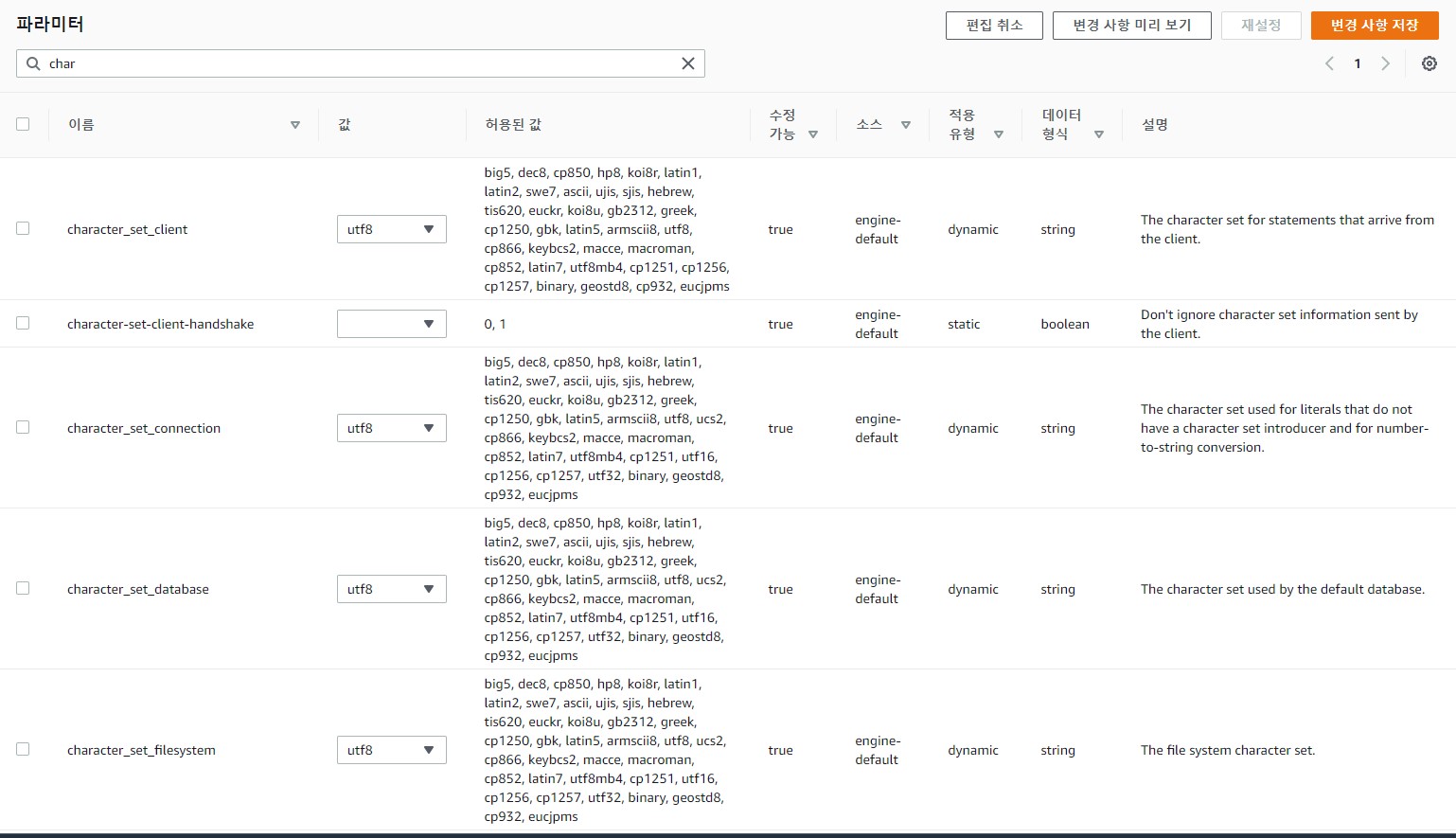
- RDS 타임존
- 당근마켓, 배달의민족, 인스타그램, 야놀자 중 프로젝트를 정해서 DB 설계
- 인스타 DB 설계
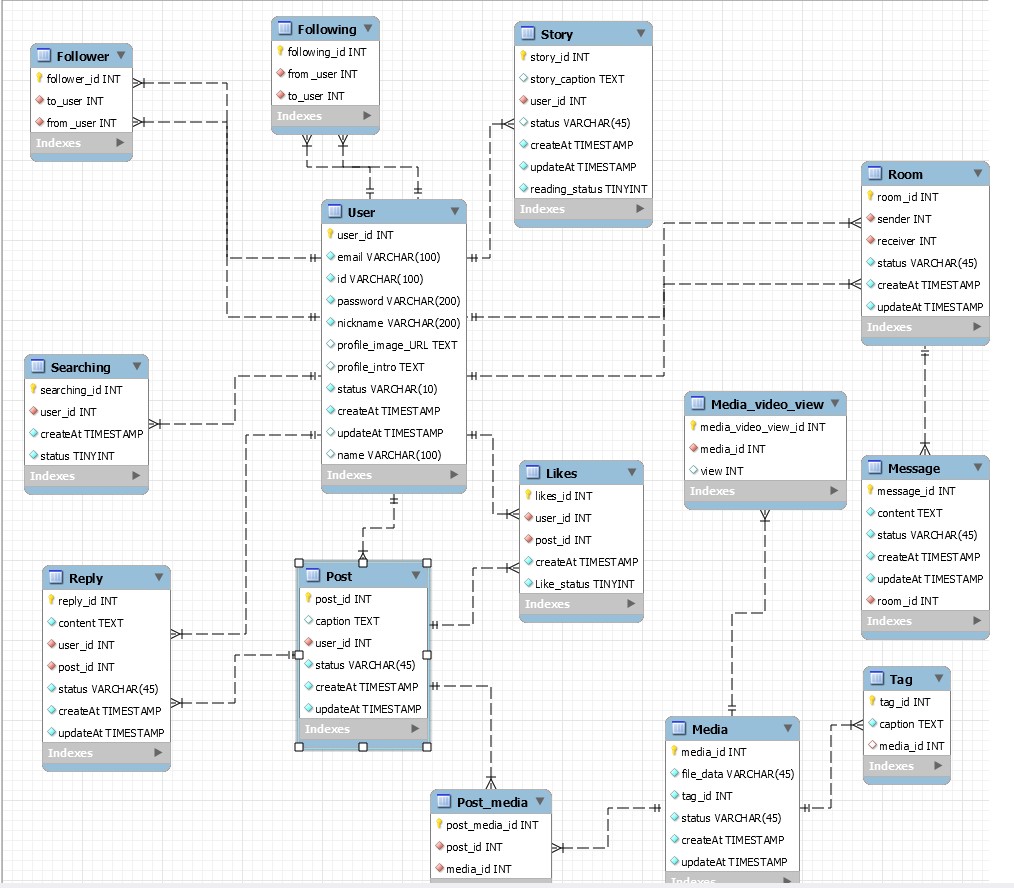
- 엑셀 시트에 앱 화면들을 10개이상 캡처한 후 리소스 추출
- 실제 화면에 연결된 수많은 테이블을 조합한 복잡한 쿼리를 10개이상 만들어오기
출처:
데이터베이스 용어 정리 - 필드, 레코드, 엔티티, 특성
[데이터베이스]릴레이션 키 개념& 종류(기본키, 슈퍼키, 대체키, 복합키, 후보키)&특징, 유일성 최소성이란?
