1. 학습 목표
- API에 대한 이해
- 벡엔드 랭기지
- API test툴 활용 (Postman)
- Api sheet 작성
2. 5주차 수업 후기
💡 5주차 수업 듣고 느낀점 이야기, 각자 진행상황 공유가장 중요한 파트이면서 어려운 파트,,
🔥 트러블 슈팅(실패한 경험도 성장을 위한 경험!)
- 트러블 슈팅 양식 [ 문제 원인 ] post로 user를 추가하려면 addUser가 작동이 돼야하는데 getid [ 해결 방안 ] lombok을 사용하면 getter에서 첫글자만 대문자로 만들어준다. getId로 변경 [ 참고 자료 ]
- 대문자, 소문자 구분 및 테이블명 컬럼명 잘 확인
3. 핵심 키워드
- API API는 응용 프로그램에서 사용할 수 있도록, 운영체제나 프로그래밍 언어가 제공하는 기능을 제어할 수 있게 만든 인터페이스를 뜻한다.
-
API의 역할
1. API는 서버와 데이터베이스에 대한 출입구 역할을 한다. 2. API는 애플리케이션과 기기가 원활하게 통신할 수 있도록 한다. 3. API는 모든 접속을 표준화한다.- API 유형
1) private API**: private API는 내부 API로, 회사 개발자가 자체 제품과 서비스를 개선하기 위해 내부적으로 발행합니다. 따라서 제 3자에게 노출되지 않습니다.
2) public API**: public API는 개방형 API로, 모두에게 공개됩니다. 누구나 제한 없이 API를 사용할 수 있는 게 특징입니다.
3) partner API**:partner API는 기업이 데이터 공유에 동의하는 특정인들만 사용할 수 있습니다. 비즈니스 관계에서 사용되는 편이며, 종종 파트너 회사 간에 소프트웨어를 통합하기 위해 사용됩니다.
- SOAP API, REST API 차이
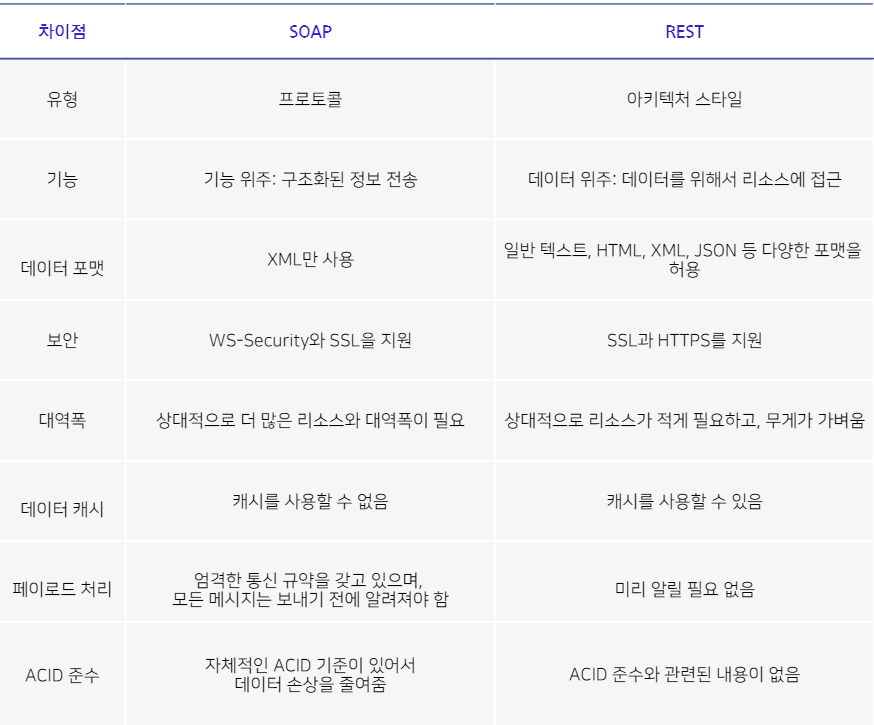
- API 유형
-
Http 패킷
:클라이언트가 서버로 요청 할 때, 보내는 데이터를 HTTP 패킷이라 표현
HTTP 패킷의 구조는 크게 '헤더'와 '바디'로 나뉘어진다.
-
헤더에는 HTTP 메서드 방식중 무엇을 썻는지, 클라이언트의 정보, 브라우저 정보, 접속할 URL 등등 과 같은 클라이언트 정보를 담습니다.
-
바디는 보통 비어있다가, 특정 데이터를 담아서 서버에게 요청을 보낼 수 있습니다.
⇒ 구체적으로
-
요청헤더 (Request Header) : 요청하는 페이지의 주소와 현재 컴퓨터의 정보가 전송되는 부분입니다.
-
요청바디 (Request Body) : POST 요청시 전송되는 데이터가 들어가는 부분입니다. GET 요청 때는 빈칸 입니다.
-
응답헤더 (Response Header) : 응답 페이지의 상태와 서버에 관한 정보가 전송되는 부분입니다.
-
응답바디 (Response Body) : 페이지의 HTML 소스가 전송되는 부분입니다.
-
-
Http 메소드
- GET :서버로부터 정보를 조회하기 위해 설계된 메소드 GET은 요청을 전송할 때 필요한 데이터를 Body에 담지 않고, 쿼리스트링을 통해 전송합니다.
- 쿼리스트링 :사용자가 입력 데이터를 전달하는 방법중의 하나로, url 주소에 미리 협의된 데이터를 파라미터를 통해 넘기는 것을 말한다. query parameters( 물음표 뒤에 = 로 연결된 key value pair 부분)을 url 뒤에 덧붙여서 추가적인 정보를 서버 측에 전달하는 것이다. 클라이언트가 어떤 특정 리소스에 접근하고 싶어하는지 정보를 담는다.
형식
- 정해진 엔드포인트 주소 이후에 ?를 쓰는것으로 쿼리스트링이 시작함을 알린다
- parameter=value로 필요한 파라미터의 값을 적는다
- 파라미터가 여러개일 경우 &를 붙여 여러개의 파라미터를 넘길 수 있다.
엔드포인트주소/엔드포인트주소?파라미터=값&파라미터=값 - = 로 key 와 value 가 구분된다.

- 쿼리스트링 :사용자가 입력 데이터를 전달하는 방법중의 하나로, url 주소에 미리 협의된 데이터를 파라미터를 통해 넘기는 것을 말한다. query parameters( 물음표 뒤에 = 로 연결된 key value pair 부분)을 url 뒤에 덧붙여서 추가적인 정보를 서버 측에 전달하는 것이다. 클라이언트가 어떤 특정 리소스에 접근하고 싶어하는지 정보를 담는다.
- POST :POST는 리소스를 생성/변경하기 위해 설계되었기 때문에 GET과 달리 전송해야될 데이터를 HTTP 메세지의 Body에 담아서 전송합니다.
- HTTP 메세지의 Body는 길이의 제한없이 데이터를 전송
- POST는 데이터가 Body로 전송되고 내용이 URL을 통해 보이지 않아 GET 보다 보안적인 면에서 안전
- GET :서버로부터 정보를 조회하기 위해 설계된 메소드 GET은 요청을 전송할 때 필요한 데이터를 Body에 담지 않고, 쿼리스트링을 통해 전송합니다.
-
데이터 포맷
- 포맷 유형 1. 일반 Text 데이터
-
비정형 데이터
2. CSV
(comma separated value)
-
별도의 구분 기호로 데이터를 구분하여 표시
-
다른 사람이 데이터를 구분하기 쉽지 않다.
3. XML
(extensible markup language)
-
인터넷 웹페이지를 만드는 HTML을 획기적으로 개선하여 만든 언어.
-
1996년 W3C(World Wide Web Consortium)에서 제안하였다.
-
서로 다른 기종간의 데이터 교환을 위해 등장
-
HTML보다 강화된 태그로 표현
-
인코딩 방식은 utf-8
4. JSON
(JavaScript Object Notaio)
-
속성, 값으로 데이터 표현
-
경량 데이터 표현, 많은 양의 데이터 표현에 유리
-
- JSON과 XML의 차이점
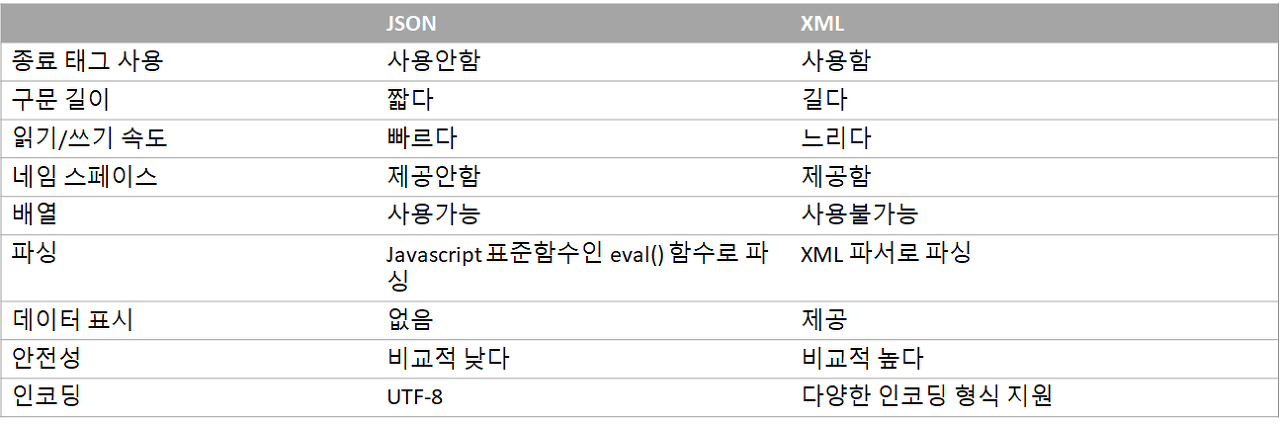
- JSON 예제
JSON 예제 {"employees":[ { "firstName":"John", "lastName":"Doe" }, { "firstName":"Anna", "lastName":"Smith" }, { "firstName":"Peter", "lastName":"Jones" } ]} - XML 예제
XML 예제 <employees> <employee> <firstName>John</firstName> <lastName>Doe</lastName> </employee> <employee> <firstName>Anna</firstName> <lastName>Smith</lastName> </employee> <employee> <firstName>Peter</firstName> <lastName>Jones</lastName> </employee> </employees> - JSON, XML
JSON의 사용 범위
-
XML 문서는 XML DOM(Document Object Model)을 이용하여 해당 문서에 접근한다. JSON은 문자열을 전송받은 후에 해당 문자열을 바로 파싱하므로, XML보다 더욱 빠른 처리 속도를 보여준다
-
따라서 HTML과 자바스크립트가 연동되어 빠른 응답이 필요한 웹 환경에서 많이 사용된다
-
JSON은 전송받은 데이터의 무결성을 사용자가 직접 검증해야한다
-
데이터의 검증이 필요한 곳에서는 스키마를 사용하여 데이터의 무결성을 검증할 수 있는 XML이 아직도 사용된다.
JSON의 특징
-
사용하기 쉽다
-
적은 메모리 공간을 사용하기 때문에 빠르다
-
맵핑을 생성하지 않아도된다
- Jackson API가 직렬화 할 여러 개체에 대한 기본 매핑을 제공한다
-
종속성
- JSON을 처리하기 위해 다른 라이브러리가 필요하지 않다XML의 특징
-
XML 태그는 미리 정의되어 있지 않다. 사용자 정의 태그를 정의해야한다
-
사람이 이해하기 쉽다
-
구조화 된 형식은 프로그램에서 읽고 쓰기가 쉽다
-
XML은 HTML과 같은 확장 가능한 마크업 언어이다
-
데이터를 전달하도록 설계 되어있고 데이터를 표시할 수 없다
JSON 장점
-
모든 브라우저에 대한 지원 제공
-
생성, 조작, 읽기 , 쓰기가 쉽다
-
구문이 간단
-
javascript에서 기본적으로 인식되고 javascript 함수인 eval() 로 구문 분석이 가능하다
-
직렬화가 가능하다
-
JavaScript 의 모든 객체를 JSON으로 변환하여 JSON을 서버로 보낼 수 있는 텍스트이다
XML 장점
-
시스템 및 애플리케이션간에 문서 전송이 가능하다.
-
서로 다른 플랫폼 간에 데이터 교환이 가능하다
-
HTML에서 데이터를 분리한다
-
플랫폼 변경 프로세스를 단순화한다
JSON의 단점
-
네임 스페이스 지원이 없다. ( 확장성이 부족)
-
형식적인 문법 정의 지원( 문법을 지켜야한다)
-
제한된 개발 도구 지원
XML의 단점
-
처리 응용 프로그램이 필요하다
-
내장 데이터 유형 지원이 없다
-
XML 구문이 중복된다
-
사용자가 자신의 태그를 생성하는 것을 허용하지 않는다
-
텍스트 기반 데이터 전송 형식과 유사하다
-
- 포맷 유형 1. 일반 Text 데이터
-
API Sheet
API 명세서란 뭘까? 레스토랑에 가서 주문한다고 가정해보자. 종업원에게 메뉴판을 받아 메뉴를 고를 것이다. 메뉴판에는 사장님이 정한 규칙 하에 여러 메뉴들이 있다. 이 메뉴판을 API 명세서
에, 메뉴를 API에 비유해보면 이해하기 수월하다.
단순히 여러 API를 나열하기 위해서 API 명세서를 작성하는 것이 아니다. 그 속에는 나름대로의 규칙이 있으며 궁극적으로 API 명세서를 통해 클라이언트와 서버가 소통할 수 있다.
-
path variable과 Query Parameter
1. Path Variable과 Query Parameter
이 글은 When Should You Use Path Variable and Query Parameter?란 영문글을 한글로 요약 정리한 것입니다. 자세한 내용은 원문을 참고해 주세요.
웹에서 특정 데이터를 전송하고 받기 위해서는 어디(End-point)에 요청할 것인가는 중요한 문제이다. 우리는 데이터를 전송하기 위해 GET, 전송 받기 위해 POST 방식을 쓰는데 이 때 각각의 경로(End-point)를 어떻게 정하는 것이 좋을까.
이에 대한 아이디어는 REST API라는 개념을 통해서 알 수 있다. 하지만 그 이전에 중요하게 알아둬야 할 개념이 Path Variable과 Query Parameter이다. 이 각각의 개념은 무엇이고, 어떤 경우에 써야 되는 것일까 알아보자.
1) Query string
/users?id=123 # Fetch a user who has id of 123위에서 보는 것처럼 ? 뒤에 id란 변수에 값을 담아 백엔드에 전달하는 방식이 Query string이다. users에 담긴 정보 중 id 123번의 자료를 달라는 요청이다.
2) Path Variable
/users/123 # Fetch a user who has id 123위와 동일한 요청을 경로를 지정하여 요청할 수도 있는데 이것을 Path Variable이라고 한다.
3) Query string과 Path variable은 각각 언제 쓰면 좋은가?
일반적으로 우리가 어떤 자원(데이터)의 위치를 특정해서 보여줘야 할 경우 Path variable을 쓰고, 정렬하거나 필터해서 보여줘야 할 경우에 Query parameter를 쓴다. 아래가 바로 그렇게 적용한 사례이다.
/users # Fetch a list of users /users?occupation=programer # Fetch a list of programer user /users/123 # Fetch a user who has id 123위의 방식으로 우리는 어디에 어떤 데이터(명사)를 요청하는 것인지 명확하게 정의할 수 있다. 하지만, 그 데이터를 가지고 뭘 하자는 것인지 동사는 빠져있다. 그 동사 역할을 하는 것이 GET, POST, PUT, DELETE 메소드이다.
즉, Query string과 Path variable이 이들 메소드와 결합함으로써 "특정 데이터"에 대한 CRUD 프로세스를 추가의 엔드포인트 없이 완결 지울 수 있게 되는 것인다.(가령,
users/create혹은users?action=create를 굳이 명시해 줄 필요가 없다.)/users [GET] # Fetch a list of users /users [POST] # Create new user /users/123 [PUT] # Update user /users/123 [DELETE] # remove user물론 위와 같은 규칙을 지키지 않더라도 잘 돌아가는 API를 만들 수 있다. 하지만 지키지 않을 경우 서비스 엔드포인트는 복잡해 지고, 개발자간/외부와 커뮤니케이션 코스트가 높아져 큰 잠재적 손실을 초래할 수 있으니 이 규칙은 잘 지켜서 사용하는 것이 필수라 하겠다.
2. 코드와 테스트로 이해하기
1) Query string
장고는 HTTP request 안에 request.GET 그리고 request.POST 객체로 쿼리 딕셔너리를 가져올 수 있다.
[views.py]
class CategoryView(View): def get(self, request): category = request.GET.get('category_id', None)View 클래스에서 위와 같이 작성하면 category_id란 값을 가져올 수 있다.
테스트를 위해 httpie에서
http -v url category_id==4를 입력하면, 장고의 request.GET에서는<QueryDict: {'category_id': 4}가 들어가게 되고, request 헤더에 엔드포인트 url로/product?category=4가 찍히게 된다.만약 테스트를 포스트맨을 통해서 한다면, 파라미터 탭에 키와 밸류를 넣어주면 됩니다.
2) Path variable
[views.py]
class ProductView(View): def get(self, request, product_id): product = Product.objects.filter(id=product_id).values()[urls.py]
urlpatterns = [ path('product/<int:product_id>', ProductView.as_view()) ]Path variable는 뷰클래스 함수에서 self, request 외에 별도의 인자를 가지게 되고, 그 인자값이 엔드포인트가 된다. 따라서 path variable은 인자값이 확실하게 부여가 되는 경우(특정 상품의 정보 등)에 주로 사용되며, urls파일에 반드시 반영을 해 줘야 된다.
테스트를 할 때는 간단하게 url에 해당되는 path variable을 추가해 주면 된다. httpie에서는
http -v url/product/4로 하면 된다.
실습
📝실습 체크리스트
- 개발환경 구축
- 사진
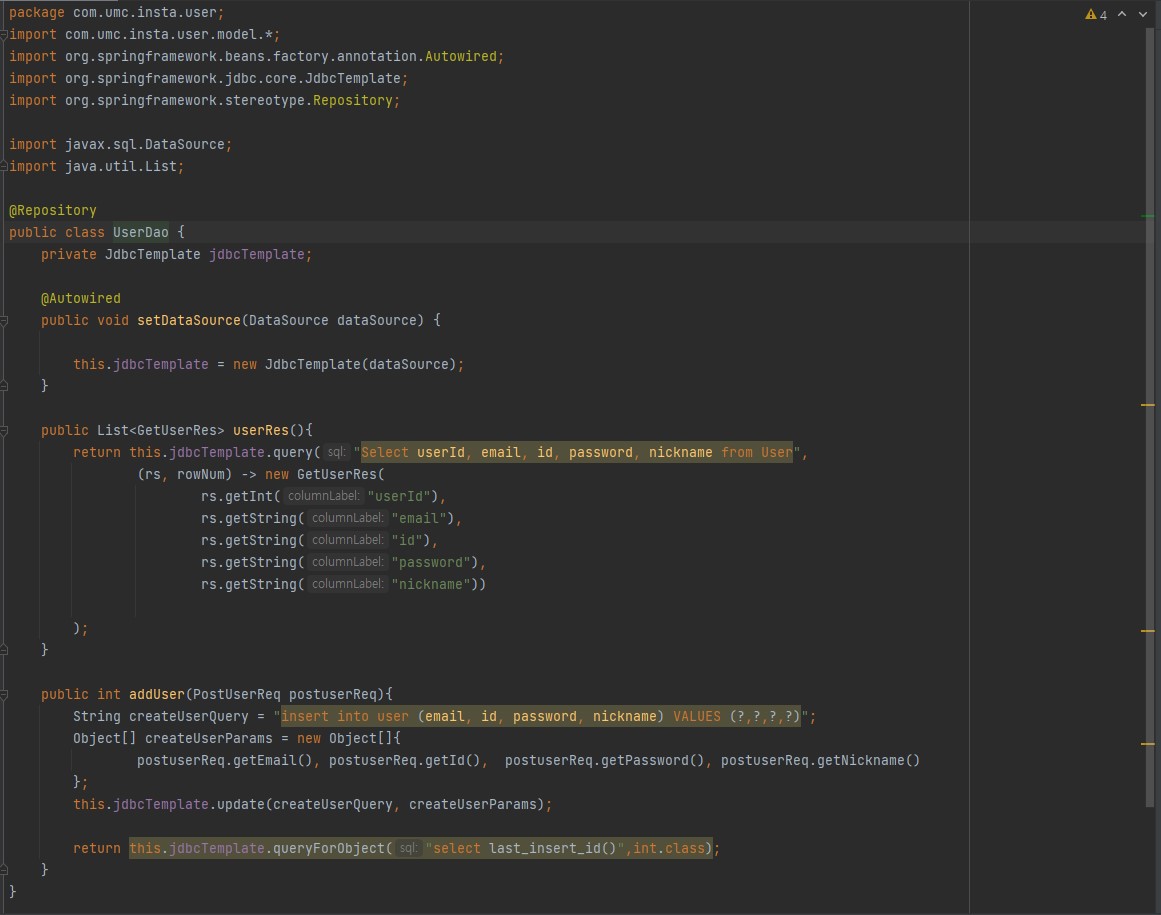
- 자신이 설계한 DB와 연동해서 API설계 (CRUD)
- 사진
- Postman으로 API테스트
- 사진
- API Sheet 작성
출처:
http://blog.wishket.com/api란-쉽게-설명-그린클라이언트/
http://blog.wishket.com/soap-api-vs-rest-api-두-방식의-가장-큰-차이점은/
https://velog.io/@pear/Query-String-쿼리스트링이란
https://free-eunb.tistory.com/41
https://stack07142.tistory.com/11
https://velog.io/@jcinsh/Query-string-path-variable
