
[대량 데이터 저장하기 ②] rabbitMQ을 통한 비동기 처리
Flutter 로컬 스토리지에서 5초마다 저장한 실시간 등산 데이터 (심박수, 시간, 거리)를 등산 종료 시 한번에 저장해야 하는 상황이 생겼다. 2시간 동안 등산할 경우 총 1,440 건의 데이터를 저장해야 하는 것이다. 따라서 이 기회에 JPA Batch Size에 대해 알아보기로 했다.
참고하기 좋은 게시글은 이것이다. Hibernate가 Batch Size를 캐싱하는 방식에 대한 글인데, 개발하기 전 알 수 있어서 다행이었다.
1. 일반적인 저장 방식
@Transactional
public void saveTrackingRecords(List<HikingLiveRecords> records) {
for (HikingLiveRecords record : records) {
hikingLiveRecordsRepository.save(record); // 1,440번의 개별 INSERT
}
}위와 같이 insert할 경우 저장해야 하는 실시간 등산 데이터가 1,440건이라고 했을 때, 1,440개의 개별 insert 쿼리가 필요하다는 문제가 있다. 이 경우 각 insert 마다 DB 왕복 통신이 발생해서 DB 커넥션 비용이 증가할 것이다.
2. JPA Batch Size 최적화 전략
🔍 JPA Batch Size란?
Hibernate가 데이터베이스에 INSERT, UPDATE, DELETE 작업을 수행할 때 한 번에 몇 개의 쿼리를 묶어서 실행할지 결정하는 설정이다.
예를 들어 1,000건의 데이터 저장 시 Batch Size를 설정하지 않은 경우 DB 왕복을 1,000번 해야 하지만, Batch Size = 100으로 설정하면 10번(1,000 ÷ 100)의 DB 왕복만 하면 된다.
내 경우 아래와 같이 설정했다.
spring:
jpa:
properties:
hibernate:
jdbc:
batch_size: 120🔍 JPA Batch Size의 동작 원리
1) Statement 준비
-- Batch Size = 120일 때 Hibernate가 준비하는 Statement
INSERT INTO hiking_live_records (user_id, mountain_id, path_id, total_time, ...)
VALUES (?, ?, ?, ?, ...)2) Parameter Binding
// 120개의 엔티티에 대해 파라미터 바인딩
for (int i = 0; i < 120; i++) {
preparedStatement.setInt(1, entities.get(i).getUserId());
preparedStatement.setInt(2, entities.get(i).getMountainId());
// ... 다른 파라미터들
preparedStatement.addBatch(); // 배치에 추가
}3) 배치 실행
preparedStatement.executeBatch(); // 120개를 한 번에 실행실제 SQL은 아래와 같이 나온다.
-- Batch Size 미설정 시 (N번 실행)
INSERT INTO hiking_live_records VALUES (1, 1, 1, 100, ...)
INSERT INTO hiking_live_records VALUES (1, 1, 1, 105, ...)
INSERT INTO hiking_live_records VALUES (1, 1, 1, 110, ...)
-- Batch Size = 120 설정 시 (1번 실행)
INSERT INTO hiking_live_records VALUES
(1, 1, 1, 100, ...),
(1, 1, 1, 105, ...),
(1, 1, 1, 110, ...),
-- ... 120개까지🔍 SEQUENCE 전략과 배치 사이즈 통합
설정 파일에 batch_size만 지정하면 될 것 같지만 막상 테스트해보면 요청한 데이터 개수만큼 insert 쿼리가 발생한다. 어째서일까? 실시간 등산 기록을 저장하는 엔티티는 아래와 같다.
@Entity
public class HikingLiveRecords extends BaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "hiking_live_records_id")
private Integer id;
// 다른 필드들
}IDENTITY 전략은 DB에서 PK 값을 자동 생성하기 때문에 Hibernate는 각 insert 후에 즉시 DB에서 PK를 가져와야 한다. 따라서 다음과 같은 문제를 발생시킨다.
- 즉시 flush 필요 : insert 후 즉시 생성된 ID를 알아야 함
- 배치 처리 불가 : addBatch() 호출 전에 이미 DB로 전송됨
- N+1 문제 : N개 엔티티 저장 시 N번의 개별 insert 발생
즉, insert를 한 번에 보내지 못하고 하나씩 전송하게 된다. 위에서 설명한 동작 원리 중 Paramete Binding 부분에 있는 PreparedStatement.addBatch()를 실행할 수 없는 것이다.
따라서 Hibernate의 batch insert를 제대로 사용하려면 SEQUENCE 또는 TABLE 전략으로 변경해야 한다. TABLE 전략은 생소해서 SEQUENCE 전략을 선택했다.
@Entity
public class HikingLiveRecords extends BaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "hiking_seq")
@SequenceGenerator(
name = "hiking_seq",
sequenceName = "hiking_live_records_seq",
allocationSize = 100
)
private Integer id;
// 다른 필드들
}이때 allocationSize는 batch_size와 맞추는 게 효율적이다. SEQUENCE 값을 120개씩 미리 할당받아 메모리에서 관리하고, DB에서 PK를 조회하는 추가 쿼리를 최소화할 수 있다.
예를 들어 allocation = 1이라고 지정할 경우 batch_size = 120이어도 엔티티를 저장할 때마다 DB에서 SEQUENCE를 조회하는 쿼리가 매번 발생한다. 따라서 총 데이터 저장 쿼리 1개 + 저장할 엔티티 개수 N만큼의 SEQUENCE 조회 쿼리 N개 만큼 DB를 왕복해야 한다. 따라서 배치 효과가 반감되기 때문에 batch_size와 allocationSize는 잘 맞춰주도록 하자.
내 경우 5초마다 실시간 등산 데이터를 저장하기 때문에 10분치의 데이터 개수인 120으로 allocationSize와 batch_size를 지정했다.
🔍 실행 결과
배치 insert가 실제로 동작했는지 확인해보자.
Hibernate의 StatementInspector를 활용해서 실제로 어떤 SQL이 JDBC에 전송되고 있는지를 직접 볼 수 있다.
import org.hibernate.resource.jdbc.spi.StatementInspector;
public class SQLInspector implements StatementInspector {
@Override
public String inspect(String sql) {
System.out.println("📝 [Hibernate SQL] " + sql);
return sql;
}
}
먼저 StatementInspector 클래스를 생성한다.
spring:
jpa:
properties:
hibernate:
session_factory:
statement_inspector: com.ssafy.ollana.tracking.config.SQLInspector
그 후 설정 파일에 생성한 클래스 전체 패키지 경로를 포함하여 등록한다.
아래의 콘솔은 StatementInspector를 활용하여 Batch Size로 최적화하기 전과 후를 비교한 결과이다.
최적화 전
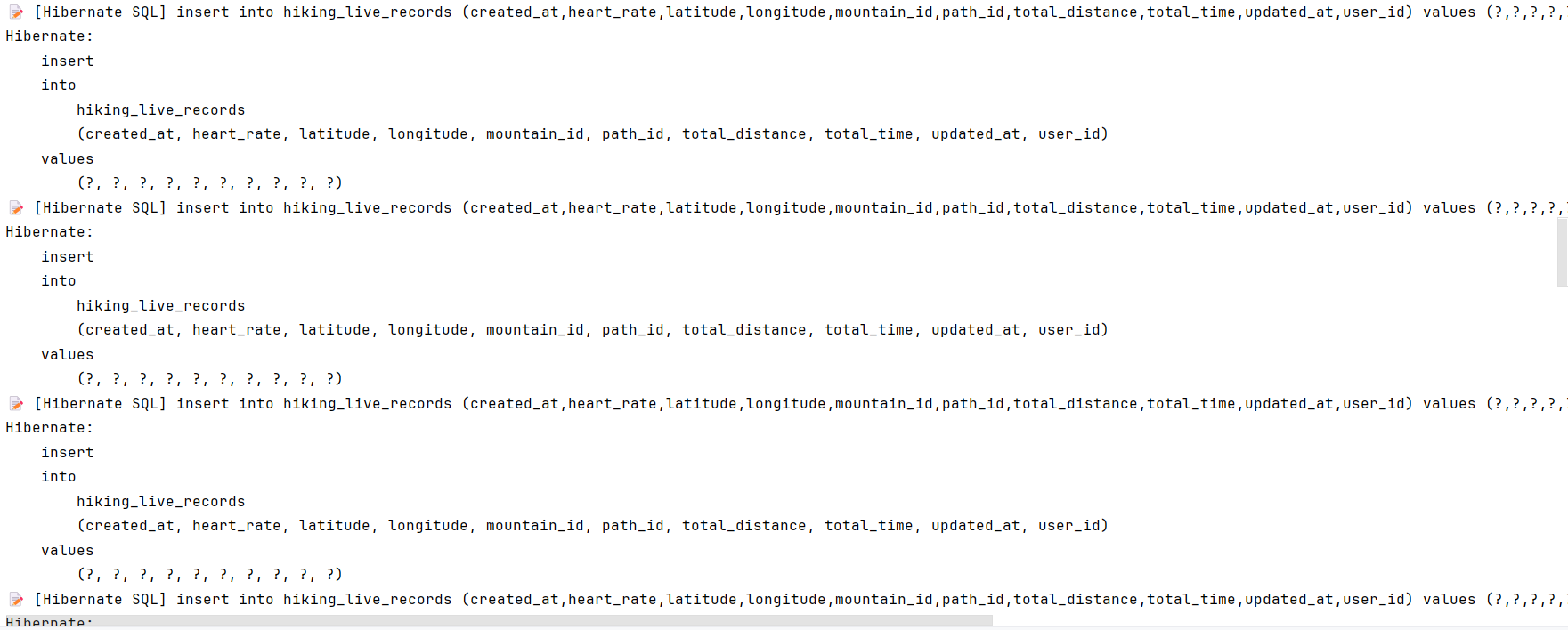
최적화 후

최적화 전에는 요청 보낸 데이터만큼 insert 쿼리가 발생하지만, 최적화 후에는 SEQUENCE 조회 쿼리 하나와 insert 쿼리 하나만 생성되는 것을 직접 확인할 수 있다.
쿼리 직접 나가는거 확인 안 했으면 대충 batch size만 설정하고 끝낼 뻔.....데이터 저장 로직 자체는 개선했지만 아직 부족한 부분이 있다고 느껴서 다음 글에서 이어서 작성해보도록 하겠다...🙃
