서비스 아키텍처에서 Application과 DB는 필수 구성 요소다. Application으로 요청이 들어오면, 대부분의 경우 SQL이 DB로 전달된다.
그렇다면 DB는 이 SQL을 어떻게 실행할지 어떻게 결정할까? 이 질문의 핵심은 "옵티마이저가 실행 계획을 어떻게 세우는가?" 에 있다.
1. SQL이 DB에 도착했을 때의 처리 흐름
MySQL 8 기준으로 쿼리가 DB에 도착하면 아래와 같은 순서로 처리된다.
- 네트워크 수신 & 세션 할당
- SQL 파싱
- 문법 분석 (Syntax Check)
- 의미 분석 (테이블/컬럼 존재 여부, 권한 확인)
- 실행 계획 캐시 확인
- MySQL 8부터는 Query Cache가 제거되었고, Prepared Statement Plan Cache를 사용
- 동일한 쿼리 패턴에 대해 재사용 가능한 실행 계획을 캐싱
- 옵티마이징 단계
- 논리적 쿼리 변환 (Logical Optimization)
- 실행 계획 후보 생성 및 비용 비교 (Physical Optimization)
- 실행 계획 선택 및 저장
- 쿼리 실행
- 스토리지 엔진(InnoDB 등) 접근
- 실제 연산 수행
- 트랜잭션 & 락 처리
- 결과 반환
이 중 가장 핵심적인 단계가 바로 "옵티마이징 단계" 다. 옵티마이저는 미리 정의된 비용 모델(Cost Model) 을 기반으로 여러 실행 계획 후보 중 가장 비용이 낮다고 판단되는 계획을 선택한다.
2. 실행 계획의 구조
실행 계획(EXPLAIN)을 보면 트리(Tree) 구조를 가진다.
- 가장 아래(Leaf): 테이블 접근 (Table Scan, Index Scan)
- 중간 노드: JOIN, FILTER, GROUP BY, SORT
- 최상위(Root): SELECT 결과 반환
실제 실행은 Leaf → Root 방향으로 진행된다. 자식 노드에서 만들어진 결과가 부모 노드로 전달되는 상향식(Bottom-Up) 구조다.
연산 노드는 크게 세 가지 형태로 나뉜다:
- Single Child: 정렬(ORDER BY), 집계(GROUP BY), 필터(WHERE)
- Multi Child: UNION, UNION ALL
- JOIN: 두 개의 입력을 결합 (Nested Loop, Hash Join, Merge Join)
| 실행계획 | leaf 부터 올라오는 데이터 |
|---|---|
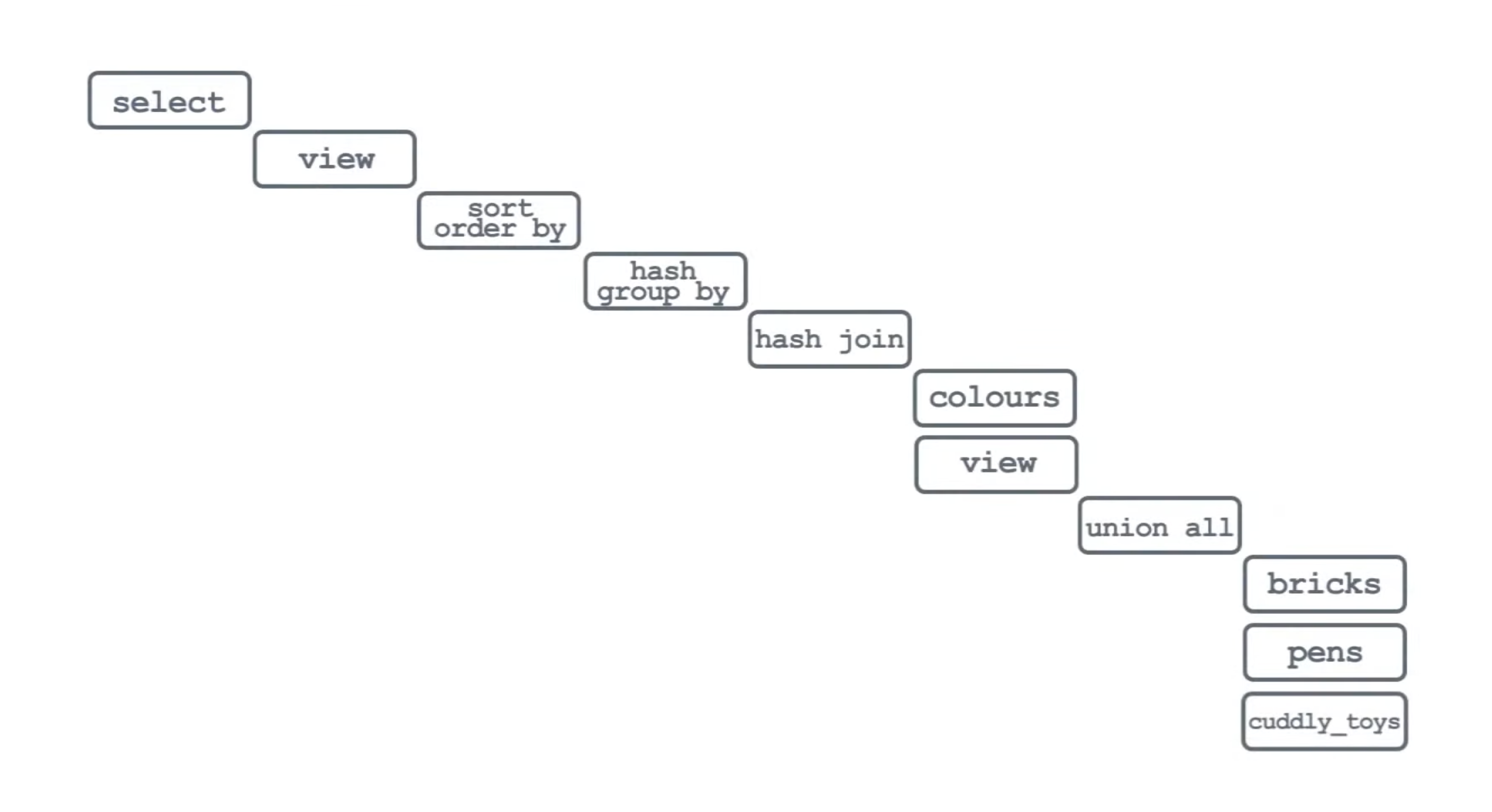 | 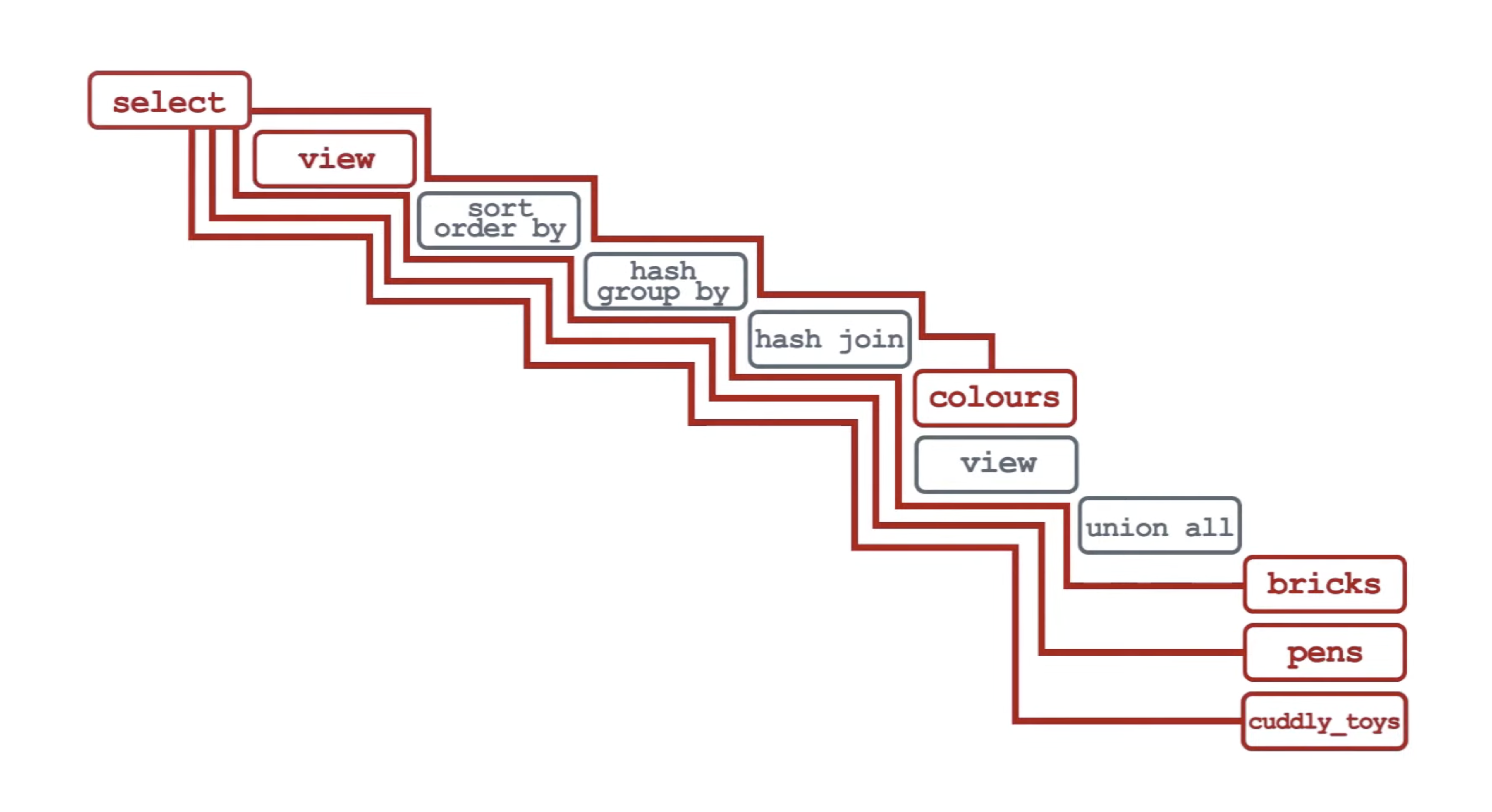 |
3. JOIN 순서는 어떻게 결정될까?
예를 들어, 아래와 같이 4개의 테이블이 있다고 가정해보자.
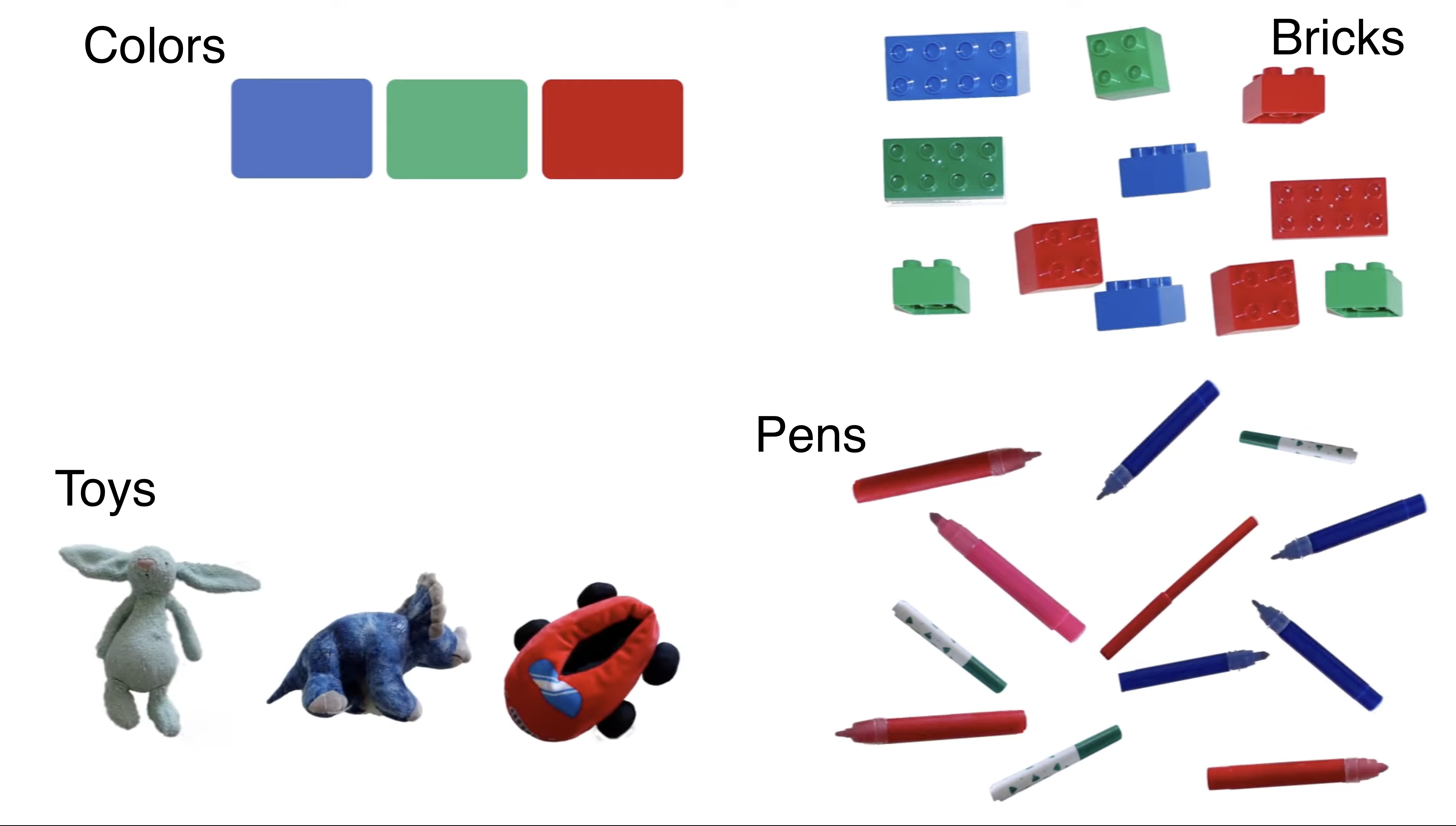
모든 테이블을 색깔(color) 기준으로 JOIN 한다면, 수학적으로는 다양한 조합이 가능하다:
Bricks JOIN (Toys JOIN (Colors JOIN Pens))(Colors JOIN Bricks) JOIN (Toys JOIN Pens)- 기타 등등...
4개의 테이블을 JOIN 하는 경우의 수는 매우 많아진다. 그렇다면 MySQL 옵티마이저는 어떻게 순서를 정할까?
Left-Deep Tree 방식
대부분의 비용 기반 옵티마이저(MySQL, Oracle, PostgreSQL 등)는 Left-Deep Tree 형태를 선호한다. 이는 JOIN 결과를 점진적으로 만들어가는 구조로, 각 JOIN의 왼쪽(Outer) 입력은 이전 JOIN의 결과이고, 오른쪽(Inner) 입력은 단일 테이블이거나 단순 연산의 결과다.

위 그림처럼 (((Colors JOIN Bricks) JOIN Pens) JOIN Toys) 형태로 순차적으로 JOIN이 진행된다.
핵심 원칙은 간단하다:
조건을 적용한 후 결과 row 수가 가장 적을 것으로 "추정되는" 테이블부터 시작한다
이 "추정"을 가능하게 해주는 것이 바로 통계 정보(Statistics) 다.
위 예제에서 통계 정보를 기반으로 각 테이블의 예상 row 수를 계산한 결과, 최종 JOIN 순서는:
Colors → Bricks → Pens → Toys 로 결정된다.
4. 옵티마이저는 row 수를 어떻게 추정할까?
실행 계획에서 가장 오른쪽(Leaf)에 있는 첫 테이블이 시작점이 된다. 옵티마이저는 다음과 같이 동작한다:
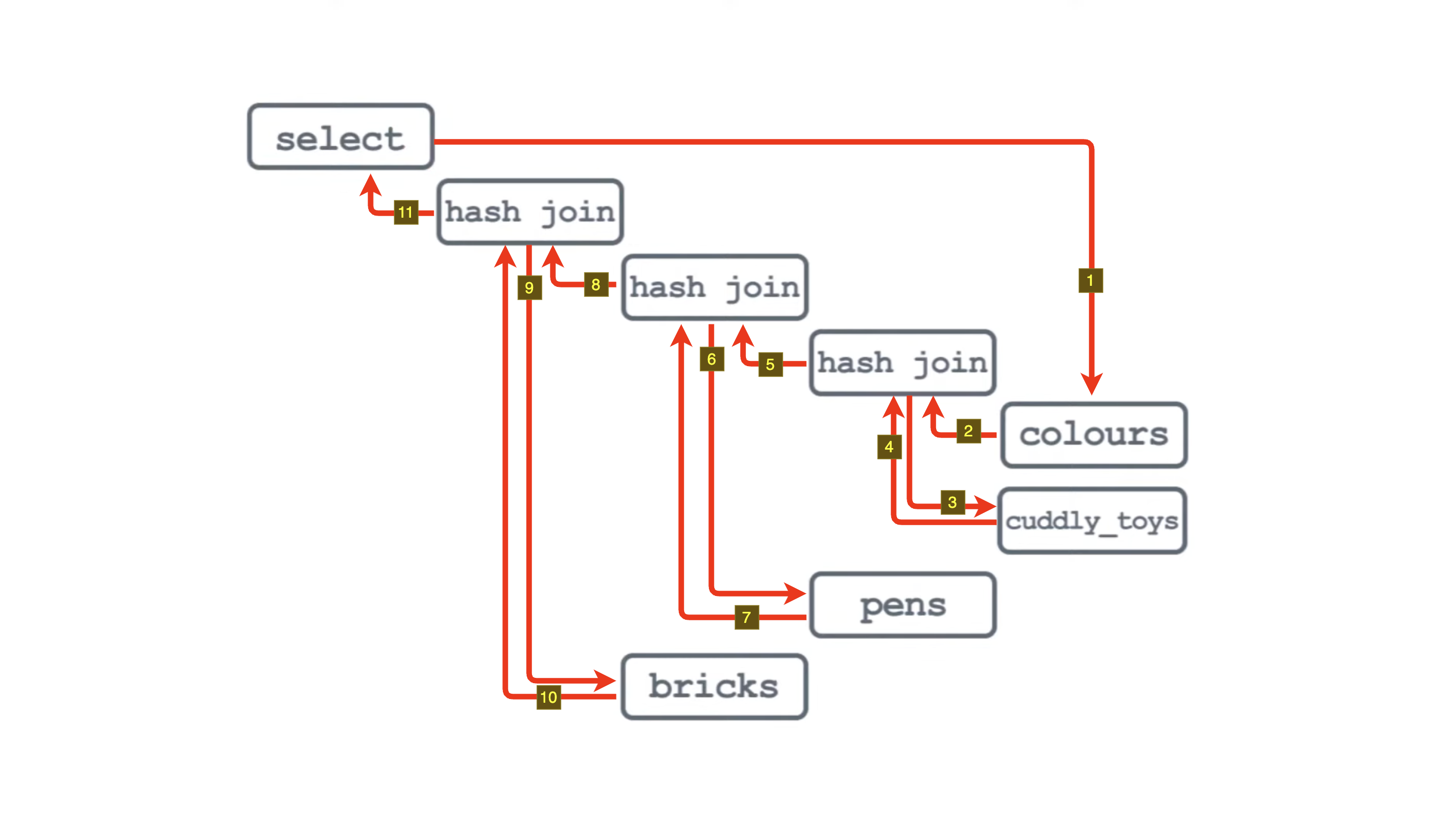
각 단계에서 결과 row 수를 예측하기 위해, 테이블의 모든 row를 실제로 세는 것은 매우 비효율적이다. 따라서 옵티마이저는 통계 정보(Statistics)를 기반으로 row 수를 추정한다.
통계 정보 수집
MySQL에서는 ANALYZE TABLE 명령으로 통계 정보를 수집한다:
ANALYZE TABLE Bricks;이 명령은 다음 정보를 수집하고 갱신한다:
- 테이블의 총 row 수
- 인덱스별 Cardinality (고유값 개수)
- 인덱스 트리의 페이지 수
이 통계 정보가 정확할수록 옵티마이저가 최적의 실행 계획을 세울 가능성이 높아진다.
Cardinality: 핵심 지표
Cardinality (또는 NDV, Number of Distinct Values) 는 특정 컬럼의 고유값 개수를 의미한다.
예제: Bricks 테이블
| id | color | shape |
|---|---|---|
| 1 | green | square |
| 2 | blue | square |
| 3 | red | circle |
| 4 | red | triangle |
| ... | ... | ... |
위 테이블에서:
color컬럼의 Cardinality: 3 (green, blue, red)shape컬럼의 Cardinality: 3 (square, circle, triangle)- 총 row 수: 30개
다음 두 쿼리를 비교해보자:
-- 1번 쿼리
SELECT *
FROM Bricks;
-- 2번 쿼리
SELECT *
FROM Bricks
WHERE color = 'red';MySQL 옵티마이저의 추정 방식:
MySQL은 기본적으로 균등 분포(Uniform Distribution) 를 가정한다.
Selectivity ≈ 1 / Cardinality = 1 / 3
Estimated Rows ≈ Total Rows × Selectivity = 30 × 1/3 = 10따라서 WHERE color = 'red' 조건에서 약 10개의 row가 반환될 것으로 추정한다.
이 추정치를 바탕으로 인덱스 스캔 vs 테이블 풀 스캔의 비용을 비교하여 실행 계획을 선택한다.
Cost Model: 비용 계산 방식
MySQL 8의 Cost Model은 다음 요소들을 고려한다:
- I/O Cost: 디스크 읽기 비용
- CPU Cost: 행 비교, 정렬 등의 연산 비용
- Memory Cost: 메모리 사용량
-- Cost Model 파라미터 확인
SELECT * FROM mysql.server_cost;
SELECT * FROM mysql.engine_cost;예를 들어:
row_evaluate_cost: 행 하나를 처리하는 비용 (기본값: 0.1)key_compare_cost: 인덱스 키 비교 비용 (기본값: 0.05)disk_temptable_create_cost: 임시 테이블 생성 비용
실제 비용 계산 예시:
Index Scan Cost = (Index Pages × IO Cost) + (Estimated Rows × Row Evaluate Cost)
Table Scan Cost = (Table Pages × IO Cost) + (Total Rows × Row Evaluate Cost)5. Cardinality만 믿으면 생기는 문제
Cardinality에만 의존하면 잘못된 추정으로 이어질 수 있다.
실제 데이터 분포:
- blue: 15개
- green: 12개
- red: 3개
MySQL 옵티마이저의 추정 (균등 분포 가정):
- 각 색상: 약 10개
이로 인해 다음과 같은 문제가 발생할 수 있다:
-
인덱스를 타야 할 쿼리가 풀 스캔으로 실행
WHERE color = 'red'(실제 3개)를 10개로 추정- 인덱스 스캔의 random I/O 10번 vs 테이블 스캔의 sequential I/O 30번을 비교
- 잘못된 추정으로 비효율적인 실행 계획 선택
-
복합 조건의 독립성 가정 문제
WHERE 조건이 여러 개인 경우, 옵티마이저는 각 컬럼이 서로 독립적이라고 가정하고 selectivity를 곱셈으로 계산한다:
SELECT * FROM Bricks WHERE color = 'red' AND shape = 'square';Combined Selectivity = (1/3) × (1/3) = 1/9 Estimated Rows = 30 × 1/9 ≈ 3.3하지만 실제로
red와square의 조합이 전혀 없다면, 실제 결과는 0개다. 컬럼 간 상관관계를 반영하지 못하는 한계가 있다.
6. Histogram: 더 정확한 분포 정보
MySQL 8.0부터는 히스토그램(Histogram) 을 지원하여 균등 분포 가정의 한계를 보완할 수 있다.
히스토그램 생성
ANALYZE TABLE Bricks
UPDATE HISTOGRAM ON color WITH 256 BUCKETS;히스토그램이 있으면:
- red: 3개
- blue: 15개
- green: 12개
처럼 값별 분포를 정확하게 반영할 수 있다.
히스토그램 확인
SELECT * FROM information_schema.COLUMN_STATISTICS
WHERE SCHEMA_NAME = 'your_database' AND TABLE_NAME = 'Bricks';히스토그램의 한계
히스토그램은 완벽한 해결책이 아니며, 다음과 같은 한계가 있다:
- 단일 컬럼만 관리 가능
- 컬럼 간 상관관계(
color + shape)는 여전히 해결 불가
- 컬럼 간 상관관계(
- 자동 갱신 안 됨
INSERT,UPDATE,DELETE시 자동으로 갱신되지 않음- 주기적으로
ANALYZE TABLE ... UPDATE HISTOGRAM을 실행해야 함
- 통계 수집 비용
- 히스토그램 재생성 시 컬럼 전체를 스캔해야 함
- 대용량 테이블에서는 부담이 될 수 있음
- 메모리 사용
- 히스토그램 정보가 메모리에 로드되어 유지됨
히스토그램 사용 권장 상황
다음 조건을 모두 만족하는 경우 히스토그램 도입을 고려할 만하다:
- Cardinality는 낮지만 (고유값이 적음)
- 값의 분포가 심하게 치우쳐 있고 (skewed distribution)
- 해당 컬럼을 사용하는 쿼리가 성능에 중요한 영향을 미치는 경우
예시:
-- 상태 컬럼: active(95%), inactive(4%), deleted(1%)
ANALYZE TABLE users UPDATE HISTOGRAM ON status;
-- 지역 컬럼: 서울(60%), 기타(40%)
ANALYZE TABLE orders UPDATE HISTOGRAM ON region;7. 실전 팁: EXPLAIN ANALYZE로 검증하기
MySQL 8.0.18부터는 EXPLAIN ANALYZE를 통해 실제 실행 결과와 옵티마이저의 추정을 비교할 수 있다:
EXPLAIN ANALYZE
SELECT *
FROM Bricks
WHERE color = 'red';결과 예시:
-> Filter: (bricks.color = 'red') (cost=3.25 rows=10) (actual time=0.123..0.456 rows=3 loops=1)
-> Table scan on Bricks (cost=3.25 rows=30) (actual time=0.089..0.432 rows=30 loops=1)rows=10: 옵티마이저가 추정한 row 수actual rows=3: 실제 반환된 row 수- 추정과 실제의 차이가 크면 통계 정보 갱신 또는 히스토그램 생성 고려
마무리
옵티마이저는 통계 정보를 기반으로 한 비용 계산을 통해 실행 계획을 수립한다. 이 과정을 이해하면서, 인덱스와 복합 인덱스의 역할이 단순히 "검색을 빠르게 하는 방법"이 아니라 옵티마이저가 올바른 판단을 내리도록 돕는 핵심 요소임을 깨달았다.
핵심 요약:
- MySQL 옵티마이저는 Cost Model을 기반으로 실행 계획을 선택한다
- 통계 정보(Cardinality) 가 row 수 추정의 기초가 된다
- 기본적으로 균등 분포를 가정하여 추정하므로 실제와 차이가 발생할 수 있다
- 히스토그램으로 분포 정보를 보완할 수 있지만, 한계도 존재한다
ANALYZE TABLE로 통계를 주기적으로 갱신하고,EXPLAIN ANALYZE로 추정의 정확도를 검증하는 것이 중요하다
처음에는 이 영상을 통해 옵티마이저의 동작 방식을 이해하기 시작했고, Oracle 기반 DB와 MySQL의 옵티마이저 및 통계 정보 관리 방식의 차이를 학습하면서 더 깊이 있게 정리할 수 있었다.
참고 자료:
- MySQL 8.0 공식 문서 - Optimizer Statistics
- MySQL 8.0 공식 문서 - Cost Model
- MySQL 8.0 공식 문서 - Histogram Statistics
