- Image Classification: input image가 어떤 label에 해당하는지, 즉 해당 이미지가 어떤 분류에 속하는지 파악하는 것
- 컴퓨터는 0부터 255까지의 정수의 배열로 이미지를 인식함.
ex) 8006003 (3 channels RGB)컴퓨터가 이미지를 처리할 때 주로 사용하는 형식은 디지털 이미지 형식.
디지털 이미지는 픽셀(pixel)이라는 작은 단위로 구성되어 있으며, 각 픽셀은 색상 정보를 담고 있음.
이 색상 정보는 일반적으로 0부터 255까지의 값을 가짐. 이는 8비트(8 bits)로 표현되는데, 8비트는 2^8, 즉 256가지 서로 다른 값을 나타낼 수 있음. 따라서 각 픽셀의 색상을 표현하기 위해 0부터 255까지의 값을 사용함.
이러한 8비트는 색상의 강도(intensity)를 나타냄. 0은 흰색에 가까운 값이고, 255는 검은색에 가까운 값임. 중간값인 128은 회색에 가까운 값이 됨.
이러한 8비트의 색상 정보는 각각 빨강, 초록, 파랑(RGB) 세 가지 색상 채널에 대해 나뉘어 표현될 수 있음. 따라서 컴퓨터는 각 픽셀마다 빨강, 초록, 파랑의 강도를 나타내는 세 개의 값을 사용하여 색상을 표현함.
- Challenges in Image Classification
- viewpoint variation (관점 변화): 카메라 또는 대상이 움직이면 모든 픽셀이 바뀜.
- illumination (광원): 조명을 받는지 유무와 그 정도에 따라 이미지가 다르게 보일 수 있음.
- Deformation (변형): 대상이 형태가 변형되는 경우
- Occlusion (폐색): 대상이 다른 물체에 의해 가려지거나 일부분만 보이는 경우
- Background Clutter: 대상이 배경에 섞여들어가 구분이 어려운 경우
- Intraclass variation (클래스 간 구별): 대상이 속하는 레이블(클래스)의 범위가 너무 포괄적이어서 그 대상을 특정짓기 어려운 경우
- Data-Driven Approach
1) input: collect a dataset of images and labels
2) train: use machine learning to train a classifier (모델 배우기, 분류자 훈련시키기)
3) evaluate: evaluate the classifier on new images
Classfier
1. Nearest Neighbor Classifier (최근접 분류자)
-
이미지 분류 예시 데이터셋: CIFAR-10
-
Nearest Neighbor Classifier: 하나의 test image를 input으로 입력받으면, 모든 train data image와 비교하여 input이 속해있을 것 같은 label을 예측해냄.
-
L1 Distance
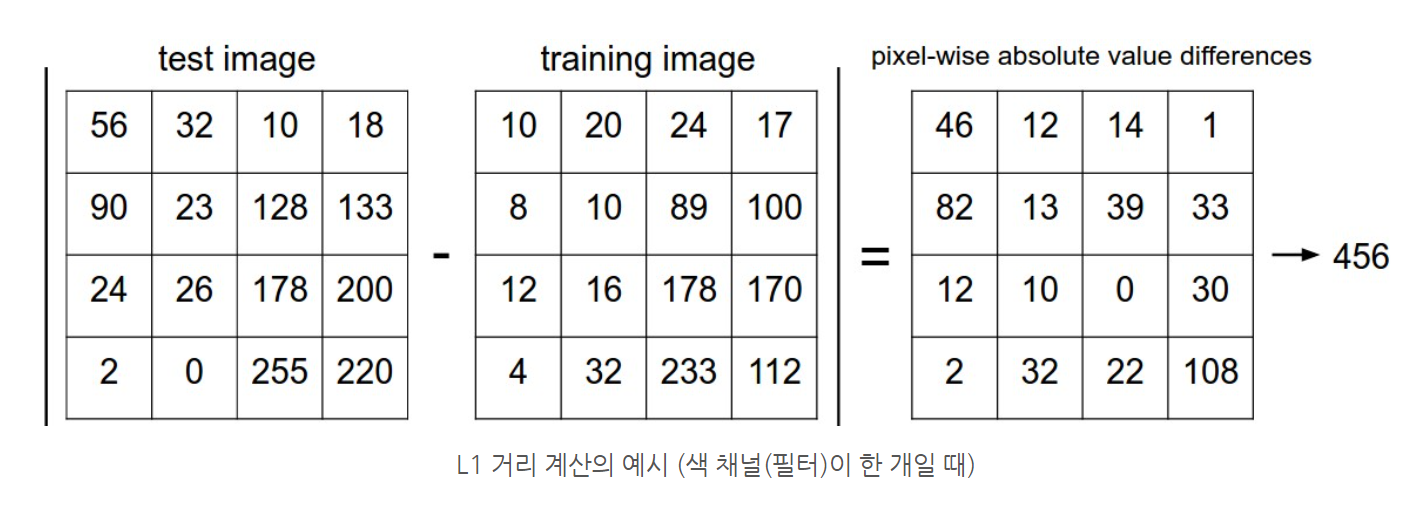
이미지 데이터는 숫자의 배열로 나타냄. 예를 들어 사이즈가 32x32인 컬러 이미지는 32x32x3(RGB)개의 숫자로 이루어진 배열임.
두 이미지를 비교하려면 각 픽셀 별로 차를 구한 후 전부 더한 값을 거리라고 설정할 수 있으며, 이를 L1 Distance라고 함.
Nearest Neighbor Algorithm은 input 이미지와 train dataset 내의 모든 이미지들 사이의 L1 거리를 측정한 후 그 값이 가장 작은 (가까운) 데이터가 속한 class를 output으로 예측하는 알고리즘임.
L1 Distance
-
정확도: 훈련시킨 알고리즘이 얼마나 효과적인지 검증하는 척도로, output 중 올바르게 예측한 결과값의 비율임.
-
L2 Distance: 모든 픽셀 간의 차의 제곱합으로 거리를 계산함.
L2 Distance
실제로 알고리즘을 작성할 떄는 루트를 제외한 제곱합만 사용함. 제곱합만 고려하더라도 거리의 순서는 보존되므로 input 데이터와 가까운 train data를 골라내는 데는 문제가 없기 때문임. L1,L2 Distance는 p-norm 일반식 중 흔히 사용되는 특수한 경우임.
- K-Nearest Neighbor Classifier (K-최근접 분류기)
- Nearest Neighbor Classifier를 개선시킨 분류기
- 입력된 이미지와 가장 가까운 이미지 1개를 찾아내어 output을 결정하는 Nearest Neighbor Classifier와 달리, k개를 선택하여 그 중 가장 많은 비중을 차지하는 클래스를 결과로 출력함.
*Nearest Neighbor Classifier는 k=1인 K-Nearest Neighbor Classifier임.
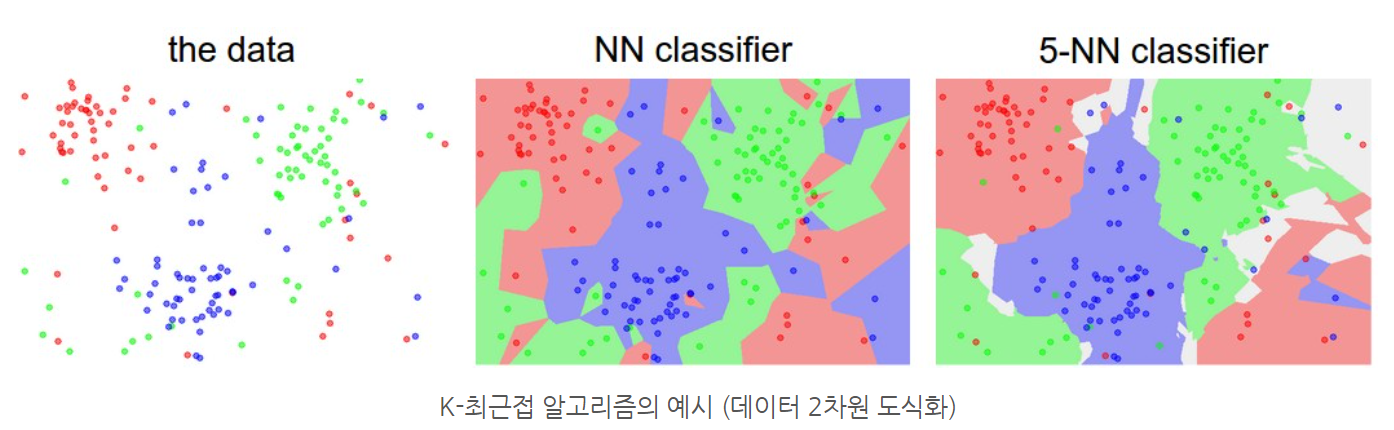
- K의 값이 클 수록 이상치에 유연하게 반응하여 decision boundary가 부드러운 형태를 띔. 위 이미지에서 k=1인 NN classifier에서는 분류한 3개의 클래스들이 서로 섞여있지만, k=5인 5-NN classifier에서는 decision boundary가 훨씬 부드러운 형태이고 각 class 정의가 쉬움.
Q. k 값은 클 수록 좋은가? 어떻게 k 값을 선정하나?
A. k를 한 번에 지정할 수 있는 공식은 존재하지 않음.
-
Hyperparameter: ML algorithm을 실행하기 전에 미리 값을 설정해야 하는 변수
*K-NN classifier의 k 값과 Distance Metric(L1/L2)은 알고리즘을 작동하기 전에 미리 지정해야 하는 hyperparameter임. -
Hyperparameter Tuning: hyperparameter 값을 조금씩 변형시키면서 알고리즘을 작동하여 가장 높은 정확도를 가지는 hyperparameter를 찾아내는 방식
-
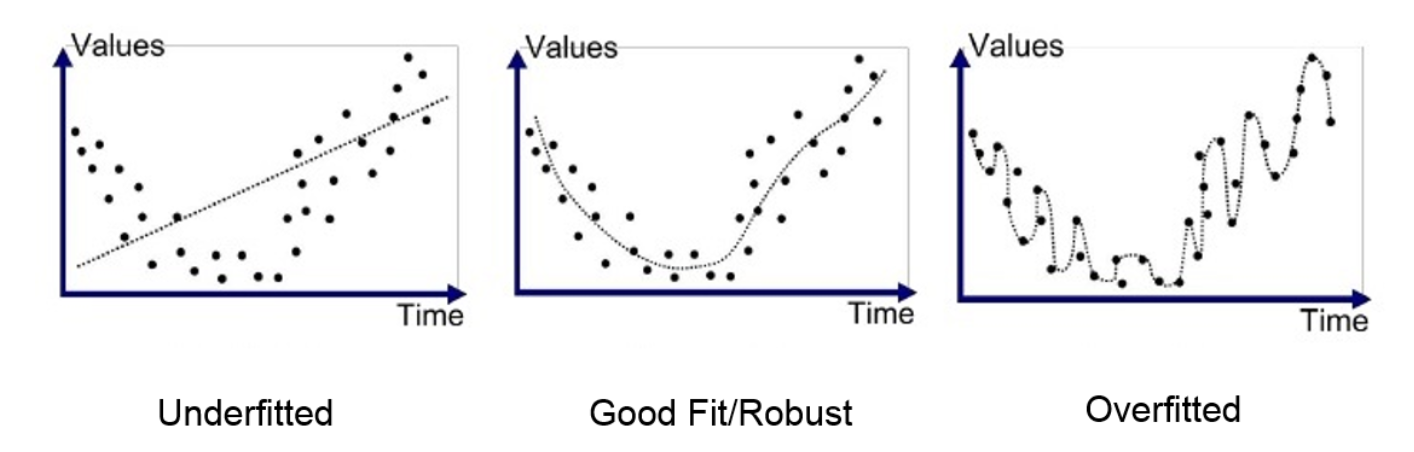
Hyperparameter Tuning 시 주의사항: test dataset을 사용해서 tuning을 하면 hyperparameter가 test dataset에만 최적화된 Overfitting 상태가 됨. 즉, 해당 hyperparameter 값으로는 test dataset에서만 높은 성능을 갖게 되고 새로운 데이터셋이 주어지면 정확도가 급격히 낮아짐.
-
Robust 알고리즘: 어떠한 데이터셋에서도 정확도가 일정 수준 이상 유지되는 알고리즘.
-
Hyperparameter tuning 하는 법: dataset을 train dataset/test dataset/validation dataset 3개로 나눔. validation dataset으로 hyperparameter tuning을 하면 test dataset을 사용하지 않고도 적합한 k값을 찾을 수 있음.
*train dataset은 label에 접근권한이 있으나, validaiton dataset은 label 접근권한이 없으며 정확도 측정용으로 사용됨. test dataset은 모델 훈련 및 검증이 모두 끝나고 맨 마지막에 딱 한 번만 사용되어야 함. -
Cross validation (교차검증): train dataset을 2개 이상의 그룹으로 나누어서 차례대로 train과 validation을 진행하는 것.
train dataset의 크기가 작으면 cross validation으로 hyperparameter tuning을 할 수 있음.
예를 들어, 5 fold cross validation은 train dataset을 동일한 크기의 5개 그룹으로 나눈 후, 그 중 4개는 train에 사용하고 나머지 하나는 validation에 사용함. 이 과정을 다섯 개 그룹 전부를 돌아가며 차례대로 진행함.
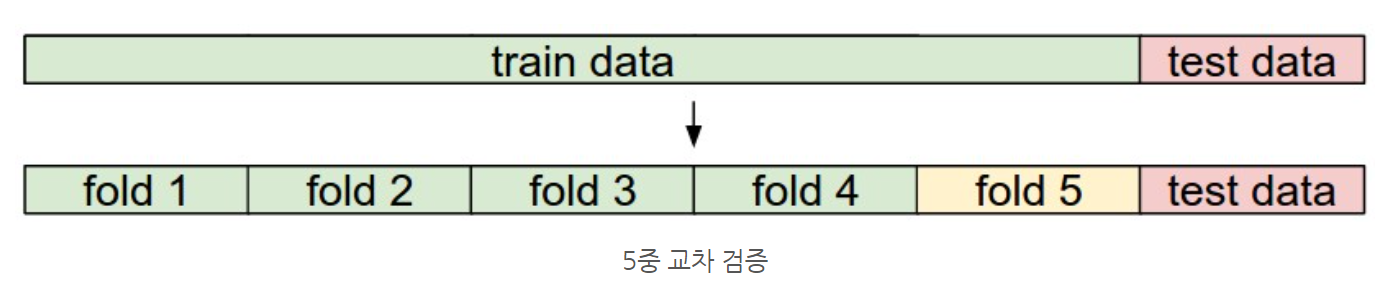
교차검증은 계산량이 많아 잘 사용하지 않으며, 실전에서는 train dataset의 50~90%를 train 용으로 사용하고 나머지를 validation에 사용함. Hyperparameter 종류가 많으면 train data의 비율을 늘리고, validation dataset의 수가 너무 적다면 cross validation을 진행함. -
K-Nearest Neigbor Classifier의 장단점
K-Nearest Neigbor Classifier는 이미지 데이터를 다룰 때 절대 사용되지 않음.
1) 장점
구조가 간단하고 이해하기 쉬움.
input과 train dataset의 모든 이미지를 비교하는 것뿐이므로 별도로 train이 필요하지 않음.
2) 단점
Test 시간이 매우 오래 걸림 (모든 이미지를 input과 비교)
픽셀이 많아질 수록 L1,L2 Distance와 같은 픽셀 간의 차이로 이미지를 비교하는 것은 부적절함. 이미지는 색상, 배경, 공간 정보 등의 다양한 요소로 이루어져 있는데, Distance를 사용해서 이미지를 분류하는 것은 Semantic Gap을 해결할 수 없음.
- Linear Classification
- Linear Classifier: Score 함수 중 가장 간단한 형태 (일차함수)
f(x,W) = Wx + b where x = input(image), W = weight(가중치), b = bias term - Linear Classifier는 Neural Network의 기본 단위임.
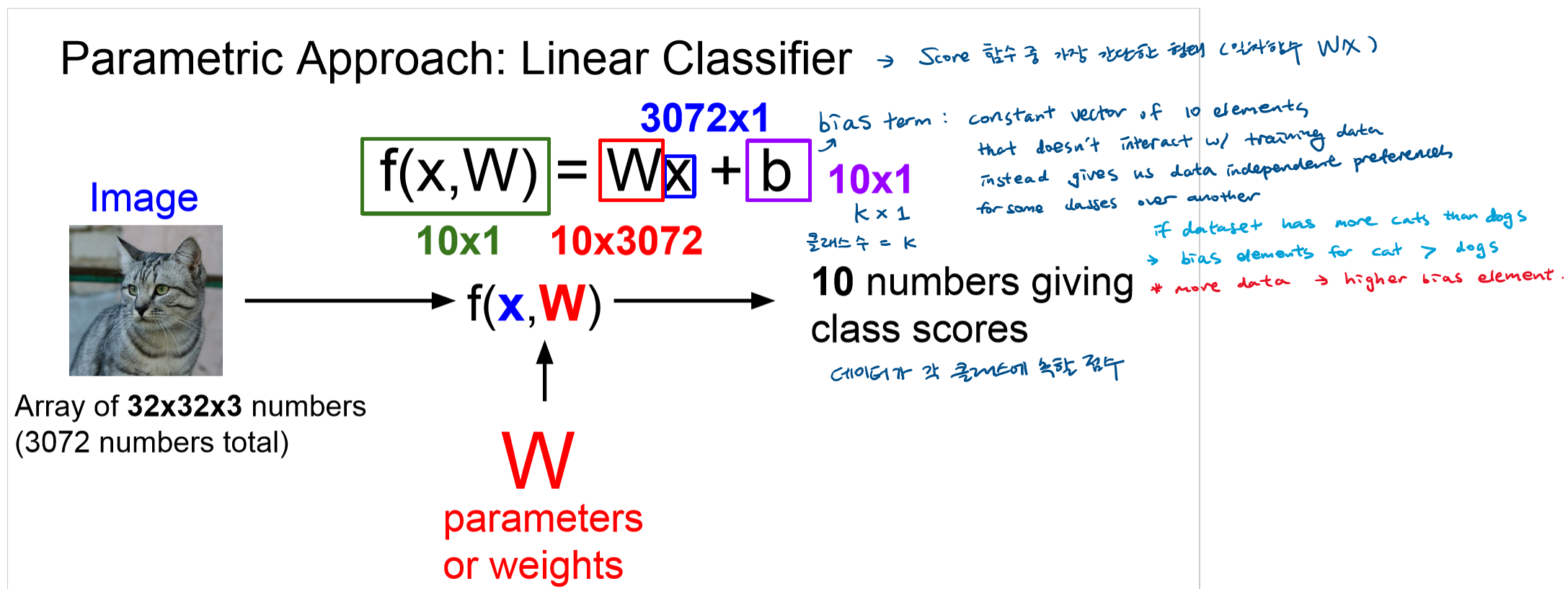
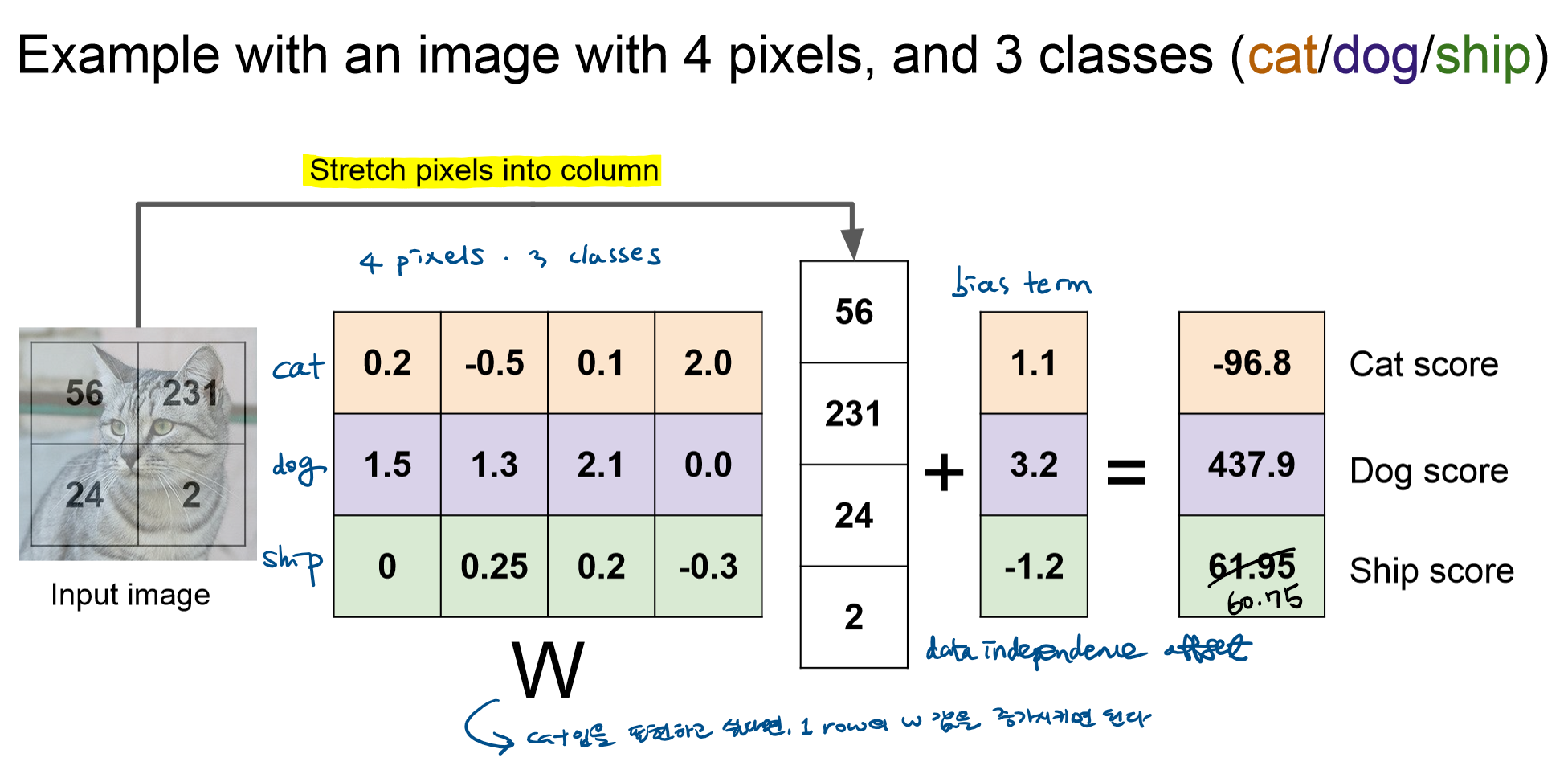
- 픽셀이 2x2이며 class가 3개인 고양이 사진이 있음.
- 이미지 데이터를 1차원 array 형태로 바꾸어 input으로 사용함.
- 각 픽셀과 클래스마다 가중치 w가 배정됨. 해당 가중치를 이미지 데이터 배열과 곱(convolution)한 뒤, bias값을 더해주어 class별 결과값을 도출함.
- 이미지는 가장 높은 점수의 class로 분류됨.
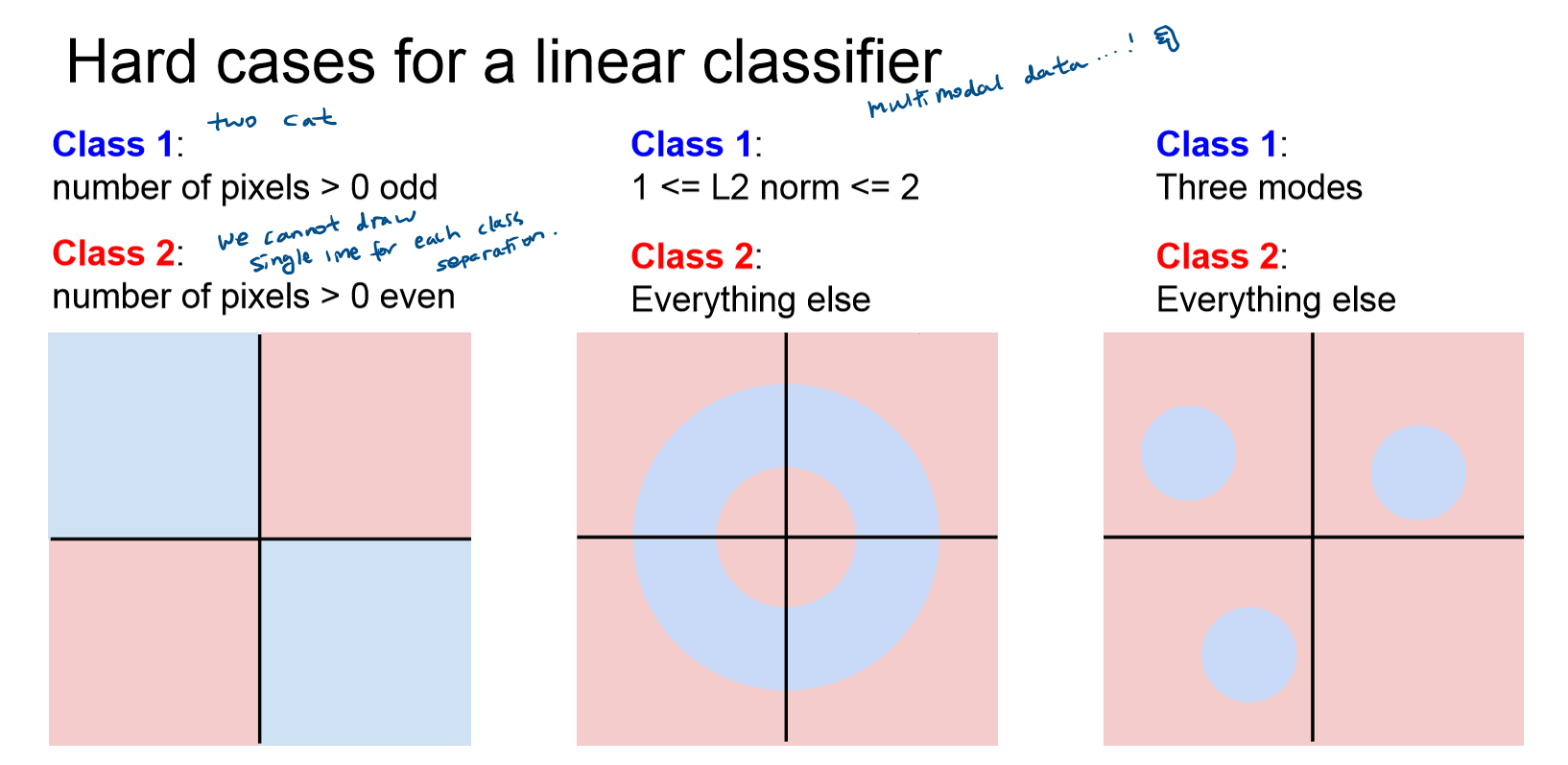
- 각각의 class 별로 단 하나의 template만 학습됨. 즉, 클래스 별로 하나의 선을 그어서 구분해야 함. (variation X)
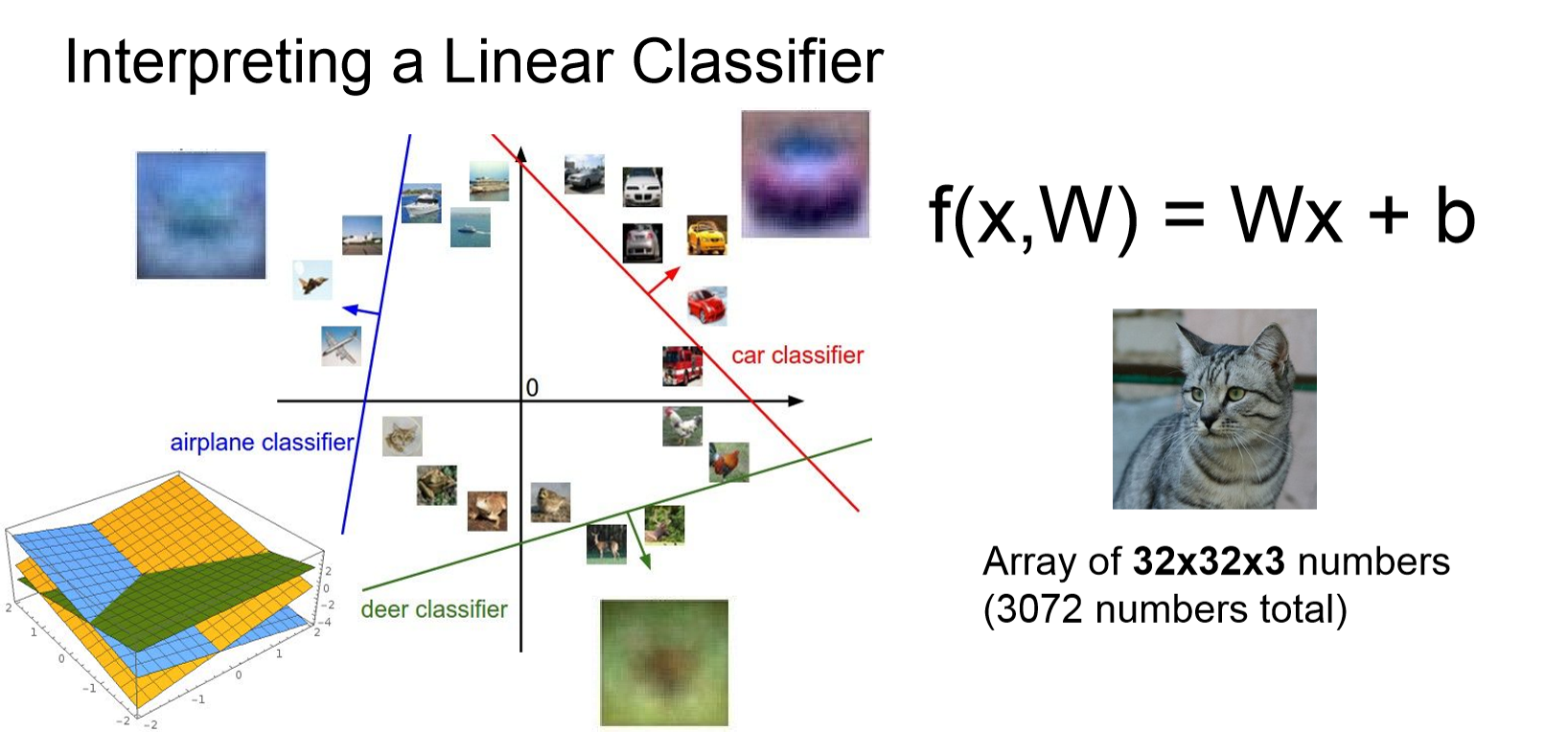
- Linear Classifier로 해결할 수 없는 문제들