
Ensemble
- 단일 모델을 학습시키는 대신, 독립적인 여러개의 모델을 학습시켜서 test time 때 이들 결과의 평균을 내면 성능이 2% 정도 향상됨.
- 단일 모델을 사용할 때보다 항상 더 성능이 2% 정도 좋아지기 때문에, 되도록이면 사용하는 게 좋지만, 여러 개의 학습 모델을 관리해야 하며 test 시에도 모델의 개수에 대해 linear하게 테스트 속도가 느려진다는 단점이 있음.
Tips!
- 여러 개의 모델이 아니라, 단일 모델 내에서 epoch를 돌 때마다 생성하는 checkpoint 간의 ensemble을 하더라도 성능 향상이 발생함.
- parameter vector들 간의 ensemble도 성능 향상을 가져옴.

Regularization (Dropout)
-
항상 성능을 높이는 역할을 한다!
-
batch norm 쓰는 경우에는 dropout 안 쓰는 경우가 많이 있음.
-
FNN에 dropout을 적용하면, 일부 node들을 random하게 0으로 설정하여 node간 connection을 일부 끊어줌.
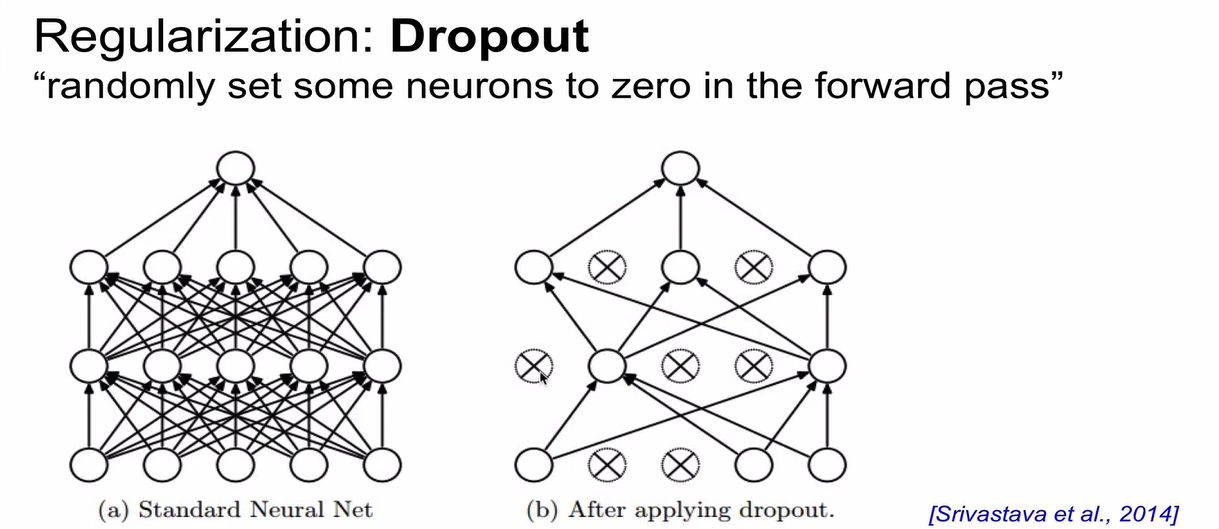
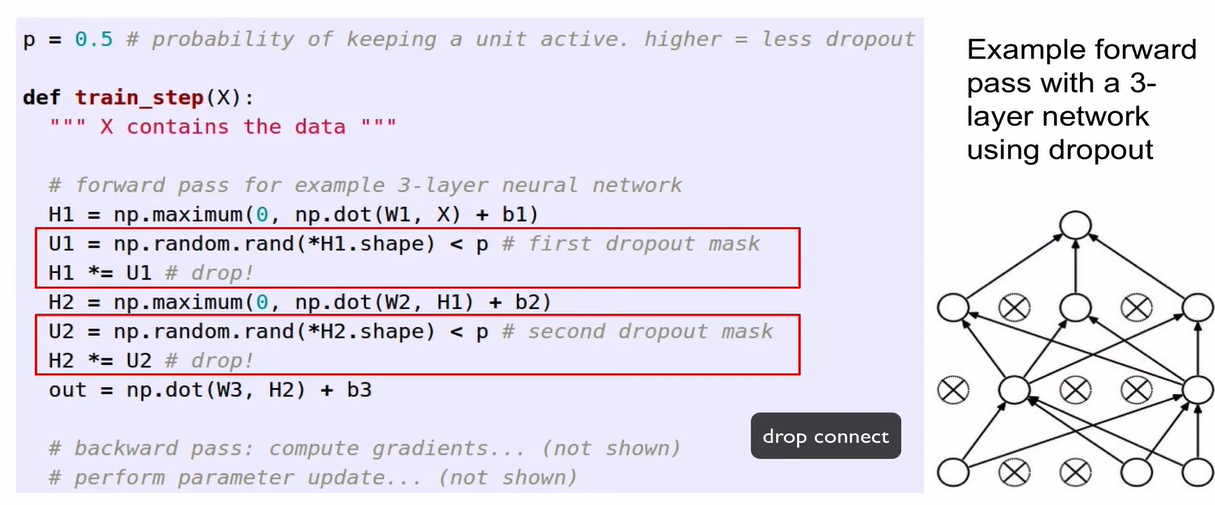
- binary mask를 설정하여 random으로 일부를 drop해줌. (0.5보다 작으면 drop, 크면 그대로 유지)
- 위 코드에서 H2.shape mask 앞에 가 붙어 있는 이유는, rand 함수는 항상 정수만 받을 수 있는데 H2.shape는 항상 tuple이라서 unpack하기 위해 사용하는 것임.
- forward pass 시 dropout 적용하고, 이 때 적용된 dropping이 backward 패스에도 0으로 적용이 되어야 함. weight 값은 update가 되면 안됨.
+) drop connect: unit, neuron을 drop하지 않고 weight를 drop 하는 방식
그래서 dropping을 왜 해?
(1) Network가 redundancy를 가지게 하기 위해서. Redundant representation을 갖게 함. 하나의 노드가 중복을 가지면서 모든 것을 관찰하게 됨. (tail만 보는 것이 아니라 ear도 봄)
(2) dropout을 하나의 ensemble 기법으로 봄. dropout은 parameter(weight)를 공유하는 큰 앙상블 모델을 학습시키는 것으로 해석할 수 있음.
Test time에서의 dropout
- training 때 여러가지 noise를 만들었는데, 이를 다 통합해주는 것이 이상적임.
- Monte Carlo Approximation: test 시에도 dropout을 평균내서 사용하자는 방법인데, 매우 비효율적인 안 좋은 방법임.
- test 때는 모든 neuron을 turn on 해야함. 즉, dropout을 사용하지 않음.

- 주의 사항: p=0.5인 경우, test 때의 activation이 train 때보다 2배 이상 inflate 됨.
- Test time 때 모든 neuron에 대해서 activation이
test time에서의 output = training time에서의 예상 output을 만족하도록 scaling 해줘야 함.

- 주로 사용되는 방법은 test time 때 p를 곱해서 scaling 해주는 방법보다도, training time 때 p로 나누어서 미리 scaling을 하는 것임.


Studying AI/ML with a focus on Multimodal Learning 👩🏻💻
멋져요~