Learning Rate
- Large Learning Rate: Overshooting
- Small Learning Rate: takes too long, stops at local minimum
- How to set the learning rate?
- try several learning rates, observe cost function
Data Preprocessing for Gradient Descent
- 차이가 크게 나는 데이터가 있는지 확인 / normalization 시도
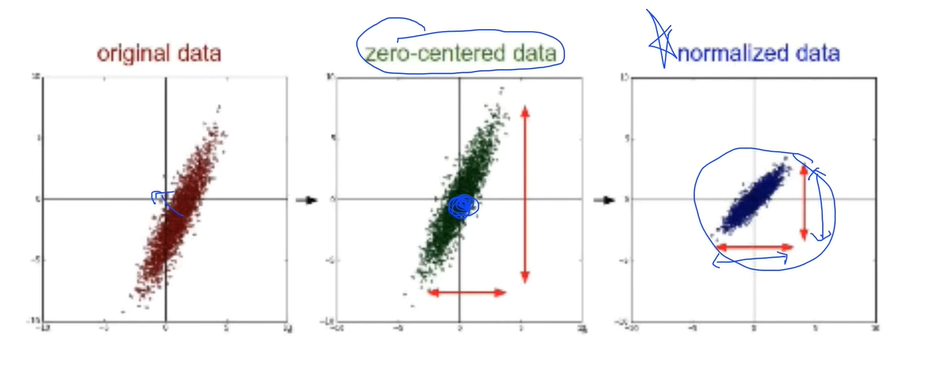
- Standardization - normalization 중 하나

Overfitting
- overfitting 줄이는 방법
- training data 개수 늘리기
- feature의 개수 줄이기
- Regularization (일반화)
- Regularization: weight를 작게 만들기 - 구불구불하지 않게 만들기
regularization strength의 크기를 0부터 1까지 조절하여 regularization 정도 조절 (람다)
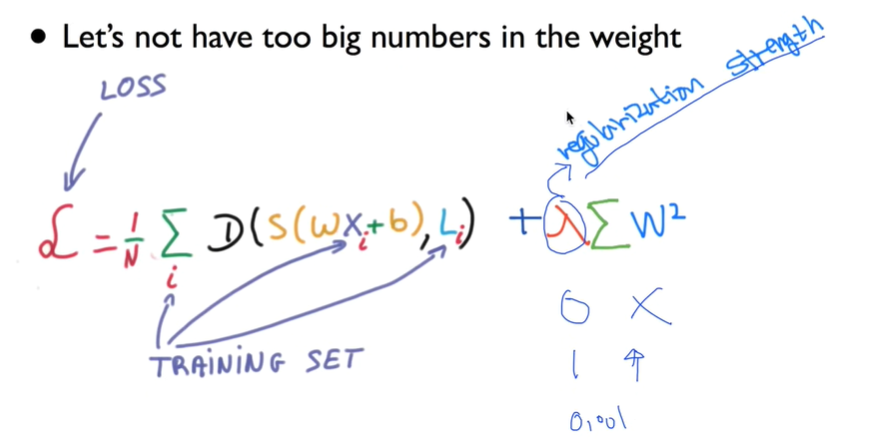

Training set & Test set
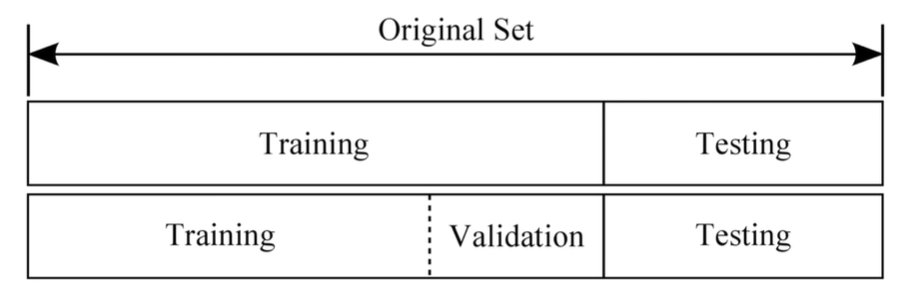
Training set: 교과서 연습문제!
Validation set: 모의고사!
Testing set: 실전 시험!
Online Learning
- 큰 데이터셋을 작게 나눠서 순차적으로 학습시키는 방법. model이 이전 학습 결과를 기억하고 있어야 함. 나중에 데이터가 추가되었을 때 처음부터 다시 학습시킬 필요없이 추가로 학습시키면 됨.
MNIST Dataset
- MNIST는 60,000개의 트레이닝 셋과 10,000개의 테스트 셋으로 이루어져 있음
- MNIST는 간단한 컴퓨터 비전 데이터 세트로, 손으로 쓰여진 이미지들로 구성되어 있습니다. 숫자는 0에서 1까지의 값을 갖는 고정 크기 이미지 (28x28 픽셀)로 크기 표준화되고 중심에 배치되었음. 간단히 하기 위해 각 이미지는 평평하게되어 784 피쳐의 1-D numpy 배열로 변환되었음 (28 * 28).
- MNIST 데이터는 Yann LeCun의 웹사이트에서 제공됨.
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("./samples/MNIST_data/", one_hot=True)
출처
https://sdc-james.gitbook.io/onebook/4.-and/5.1./5.1.3.-mnist-dataset

Studying AI/ML with a focus on Multimodal Learning 👩🏻💻