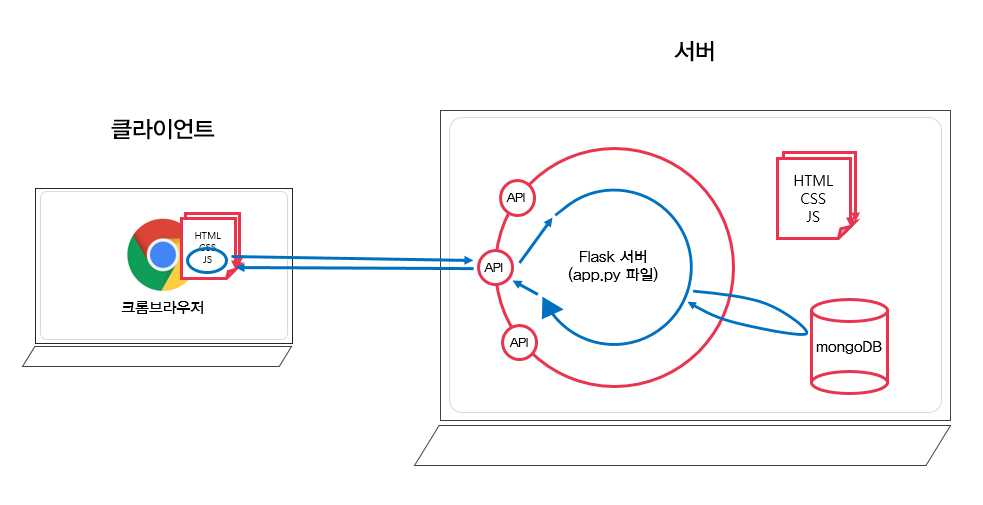
▶ 웹브라우저 작동 원리
크롬 창에서 보이는 웹 페이지는 어떤 원리로 보여지는 것일까? 한번 알아보자!
▷ 서버/클라이언트
- 네이버에 접속한 후 "메일" 라고 적혀있는 부분을 오른쪽 클릭해서 검사를 눌러 개발자 도구에 들어가 바꾸고 싶은 단어를 입력해보자!
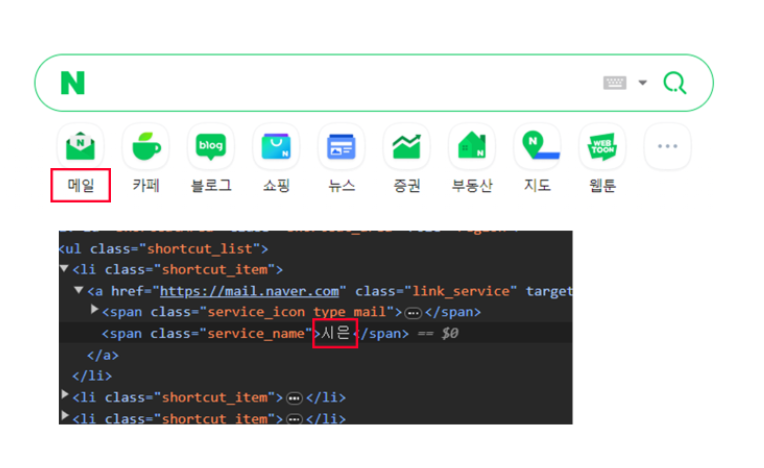
- 짜잔!🎇 아래와 같이 바뀐 것을 확인할 수 있다.
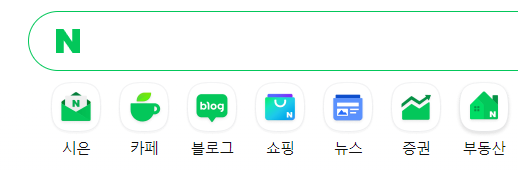
- 그럼 우리가 네이버를 해킹한 것일까?! 아니다.
내 마음대로 텍스트를 바꿀 수 있는 이유는 이미 내 컴퓨터에 가져왔기 때문이다.
- 브라우저의 역할은 1. 요청을 보내고, 2. 받은 HTML 파일을 그려주는 것이다.
- 우리가 보는 웹 페이지는 서버에서 준비해두었던 것을 “받아서” 브라우저에서 우리가 볼 수 있도록 “그려주는” 역할을 수행한다.
- 이때, 요청하는 쪽을 클라이언트(=사용자, 브라우저), 응답을 주는 쪽을 서버라고 부른다.
- 브라우저가 HTML 파일을 해석(parsing 파싱)하는 과정을 거친다.
- 서버가 클라이언트에게 준 HTML 문서를 "렌더링" 한다.
- 랜더링 엔진이 HTML문서에 코드 한줄, 한줄 보면서 ‘해석'하는 것이다.
- javascript가 알아들을 수 있는 방식으로 해석한 내용을 토대로 DOM Tree를 구성한다.
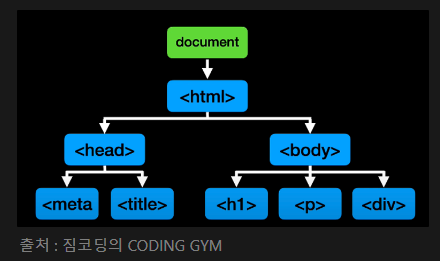
▷ 웹의 동작 개념
요청은 어디에 보내는건데?
- 서버가 만들어 놓은 API 라는 창구에 미리 정해진 약속대로 요청을 보낸다.
- 주소 창에 주소를 입력하고 엔터를 입력하는 행위가 요청을 보내는 것이다!
즉, 우리는 하루에 몇 번이고 요청을 보내고 있다. - 예) https://naver.com/
- 이것은 “naver.com”이라는 이름의 서버에 있는 “/”라는 주소 창구에 요청을 보낸 것이다.
- 그럼 네이버는 네이버 홈에 해당하는 HTML 파일을 주게된다.
- 즉, 위와 같은 과정을 통해 우리가 보는 브라우저는 주소를 통해 API로 요청을 보내고, API는 요청에 맞는 HTML파일 돌려주고 브라우저는 받은 것을 화면에 그려준다.
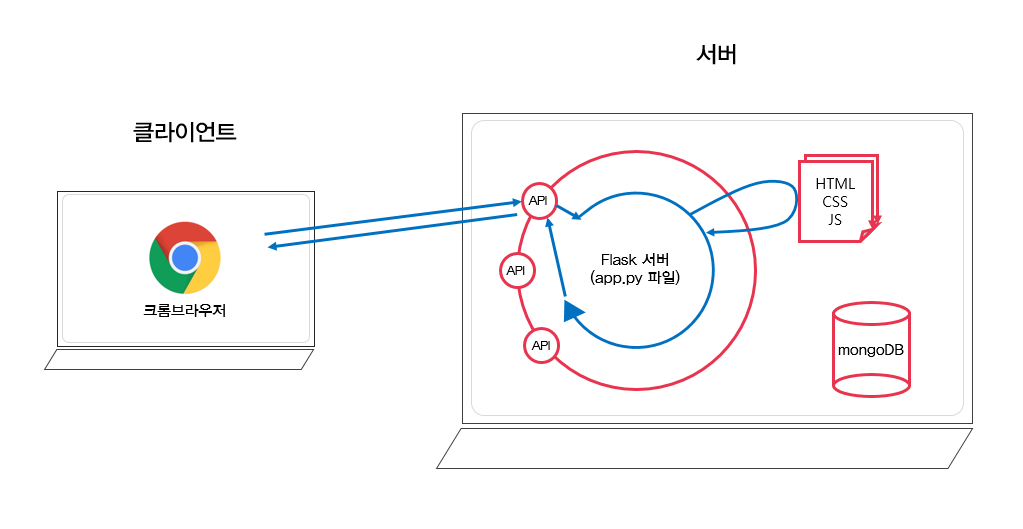
그럼 항상 HTML 파일로 돌려줄까? ❌
데이터만 내려 줄 때가 훨씬 많다. (이를 JSON 형식이라고 한다.)
- 방금 봤던 개발자 도구에서 보인 HTML 파일의 코드도 결국 데이터이다.
- 만약 우리가 공연 티켓을 예매하고 있는 상황에서 좌석이 실시간으로 매진 될 때마다 보던 페이지가 새로고침 되면 예약하기 너무 어려울 것이다.
- 그렇기 때문에 데이터만 받아서 갈아 끼우는 식으로 작동하게 된다.
- 실제로 많은 웹 서비스에서는 API로 요청을 보내면 서버의 데이터베이스에서 데이터를 돌려주고, 브라우저에서 Javascript라는 언어에서 갈아 끼워준다고 한다.
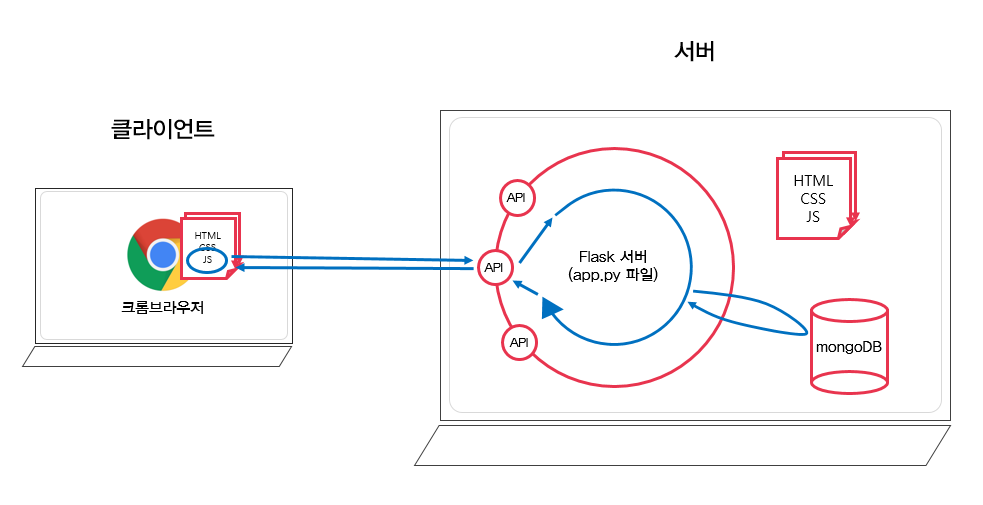
- 실제로 많은 웹 서비스에서는 API로 요청을 보내면 서버의 데이터베이스에서 데이터를 돌려주고, 브라우저에서 Javascript라는 언어에서 갈아 끼워준다고 한다.

블로그 이전했습니다!