2022년 NIPS에서 발표된 segmentation 논문입니다.
Abstract
보통 공간 정보를 인코딩할 때 self-attention의 효과때문에 transformer 기반 모델을 주로 사용해왔습니다. 본 논문에서는 CNN attiontion이 맥락정보 추출에 더 효율적이라는 것을 보여줄 예정입니다. SegNext는 부가기능 없이 성능이 기존 모델보다 좋으며 파라미터도 다른 모델에 비해 정도 수준입니다.
Introduction
이전에 CNN 기반인 FCN, DeepLab series과 Transformer기반인 SETR, SegFormer으로 잘 발전되어 왔습니다. 논문에서는 이전에 나온 기법이나 모델을 통해 성공적인 segmentation을 위한 특성을 정리했습니다.
1. 인코더로서 높은 성능의 백본(CNN 기반 모델과 비교해 성능 향상은 대개 인코더의 성능으로 부터 나왔습니다.)
2. Multi-scale 정보의 상호작용
3. Sparial attention(attention의 우선순위라고 말하는게 영역의 중요도를 의미하는 것 같습니다)
4. 낮은 계산 비용(고해상도 이미지를 segment하는 경우 필수적 요소입니다)
아래 표는 모델의 특성을 비교한 표입니다.

앞의 분석들을 고려해서 본 논문에서는 convolutional attention과 효율적인 encoder-decoder 구조를 제안합니다. 기존의 CNN을 decoder로 사용하는 transforemr-based model과는 다르게 transforemr-convolution encoder-decoder 를 반대로 만듭니다. 즉, convolution을 encoder, transformer를 decoder로 사용하는 구조입니다. encoder에서 각 block은 multi-sacle 구조를 적용하여 spatial 정보를 인코딩합니다. 이런 spatial attention은 기존 convolution과 self-attention 보다 더 효율적입니다. decoder에서는 각 stage에서 뽑아낸 feature를 바탕으로 Hambuger🍔라는 방식을 사용해 global context를 추출합니다. 이러한 방법들을 사용함으로 local에서 global에 걸쳐 multi-scale context를 얻을 수 있고, 공간, 채널 차원에서 적응성 또한 얻을 수 있습니다. 그리고 low에서 high level 정보를 통합할 수 있습니다.
SegNext에서 decoder 부분을 제외하고는 convolution 연산으로 구성되어 있습니다. transformer에 많이 의존하는 이전 segmentation 기법들과는 다르게 효율적입니다. 아래표에서 그 효율성을 확인할 수 있습니다.
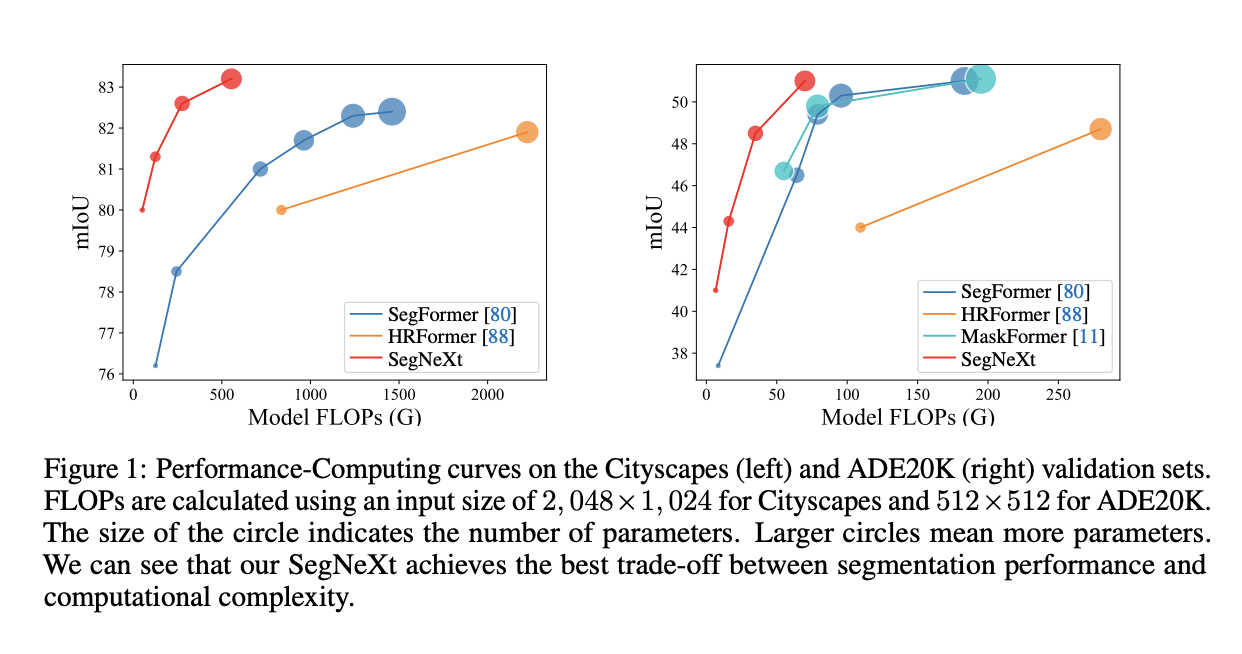
Related Work
semantic segmentation
이전 논문들에 대해 얘기합니다. 중요한 것만 하나 보자면 Large Kernel Matters-Improve Semantic Segmentation by Global Convolutional Network논문입니다. 간단하게 내용만 말하면 k k kernel을 k 1, 1 k 로 쪼개서 적용하는 방법입니다. semantic segmentation에 large kernel에 대한 중요성을 강조하지만 multi-scale의 중요성은 무시하고 이러한 기능에 대해 고려하지 않았습니다. 이 외에도 관련 논문에 더 많은 내용이 있습니다만 본 논문에서는 적은 파라미터로 kernel size를 키우기 위해 convolution 연산을 쪼개는 방법을 가져온 것으로 보입니다.
Multi-Scale Networks
multi-scale방법은 이미 있던 방법들이지만 본 논문은 attention기법을 같이 사용했다는 점을 말하고 있습니다.
Attention Mechanisms
semantic segmentation에서 두가지 타입의 attention이 있습니다. 하나는 spatial attention, 다른 하나는 channel attention입니다. 각각 다른 역할을 합니다. spatial은 공간 정보에 대한 집중, channel은 중요한 객체(channel)에 대한 집중을 합니다. vision transformer는 channel dimension을 보통 무시한다고 합니다.
visual attention network가 이 논문과 가장 관련있습니다. 이 논문은 large kernel, channel attention, spatial attention 모두 사용했지만 multi-scale을 적용하지 않았습니다.
(그럼 결국 VAN에 multi-scale넣어보니 좋았다는 내용인 느낌...)
Method
Convolution Encoder
구조는 아래 그림을 통해 이해하면 편합니다.
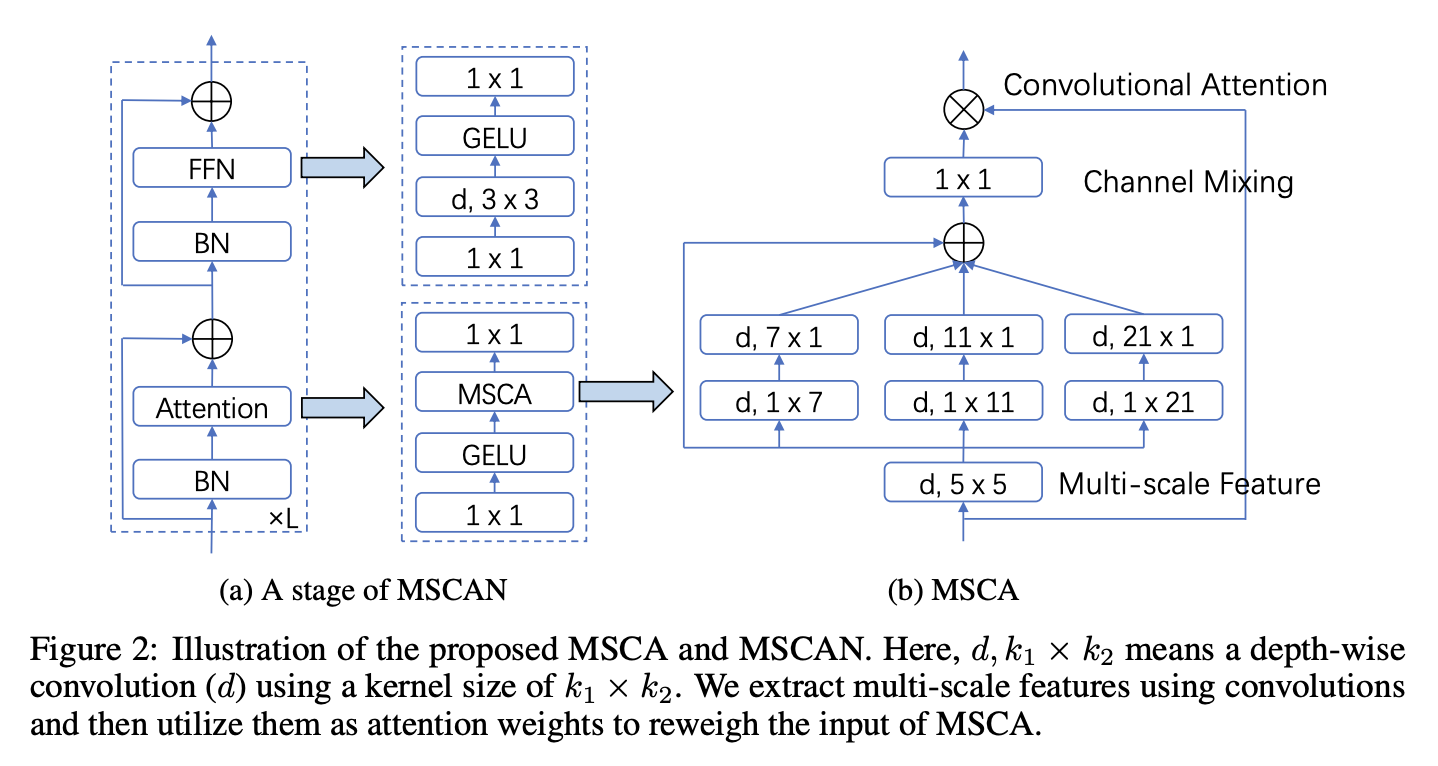
MSCA를 식으로 나타내보면 아래와 같습니다.
kernel 연산을 쪼갠 이유가 Large Kernel Matters-Improve Semantic Segmentation by Global Convolutional Network의 방법을 가져왔기 때문인줄 알았는데 내용이 더 있었습니다.(이 쪼개는 연산은 depth-wise strip convolution이라고 부릅니다.) 이 방법이 메모리를 더 적게 들고 연산도 적게 하며 strip-like objects 탐지에 더 도움이 된다고 합니다.
이 모델은 네 개의 stage로 이루어져 있으며, BN을 사용합니다.
Decoder
a는 Segformer에서 사용하는 pure mlp based decoder, b는 보통 cnn based model에서 채용하는 디코더, 마지막 c가 SegNext에서 사용하는 디코더 모델입니다. 3개의 stage를 통합하고 global context를 추가로 모델링하기 위해 가벼운 Hamburger를 사용합니다.
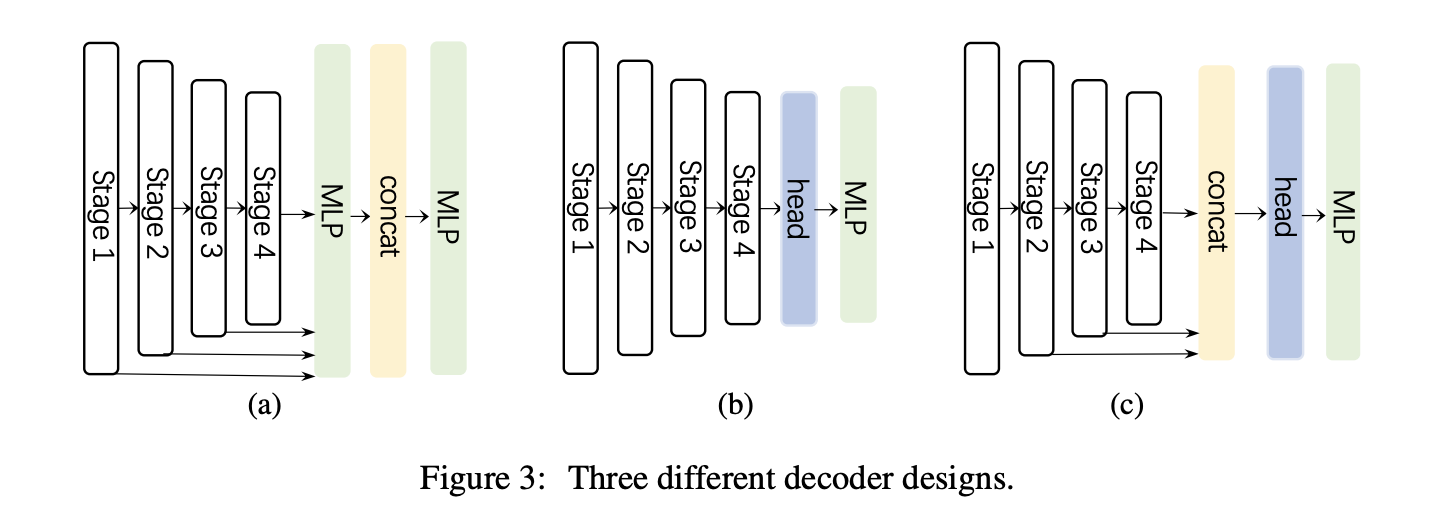
그런데 자세히 보면 c 그림에서 stage1의 feature 정보를 들고오지 않는 것을 알 수 있습니다. 이는 stage1이 너무 많은 low-level 정보를 가지고 있기 때문에 오버헤드가 크고 오히려 성능이 저하된다고 합니다.(실험 부분에 나와있습니다)
Experiments
실험은 Jittor와 PyTorch로 실행하고 구현체는 timm과 mmsegmentation으로 만들었다고 합니다.
augmentation method, traning settings는 DeiT모델과 동일하고, AdamW를 optimizer로 사용합니다.
- 제거 실험

- 위의 디코더 a, b, c + stage1 포함한 모델 실험
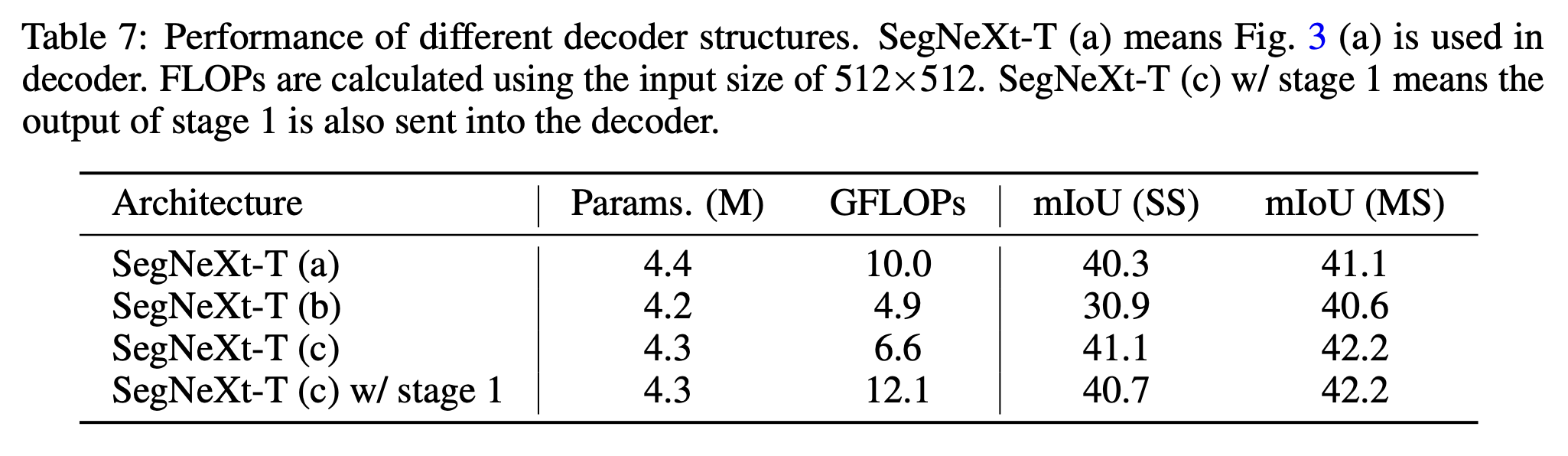
이 외에도 다양한 실험들을 했고 다양한 데이터셋에서의 성능을 비교했습니다.
확실히 모델 파라미터 대비 성능이 잘 나오고 SegFormer와 비교한 사진을 보면 작은 물체에 대한 segmentation도 잘 하는 것 처럼 보입니다.
Conclusions and Discussions
본 논문에서는 가볍고 단순한 convolution attention module인 MSCA를 제시합니다. 실험은 transforemr 기반 모델에 비교해 sota를 기록했습니다.
CNN-based method도 적절한 디자인으로 사용하면 비전 영역에서 transformer-based method보다 더 나은 성능을 가져올 수 있고 앞으로의 논문에서 CNN의 잠재력에 대해 더 조사해주길 바란다고 합니다.
