2022년에 나온 논문입니다. SegNext를 읽다가 내용이 궁금해서 읽어보게 되었습니다.
Abstract
transformer의 self-attention 매커니즘이 최근 화두이지만 2D이미지를 다루기에는 세가지 챌린지가 있습니다.
1. 2D 구조 무시
2. 제곱 연산 때문에 고해상도에 높은 연산 비용
3. 채널 적응성(channel adaptability) 무시
본 논문에서는 Large Kernel Attention(LKA)를 사용한 VAN을 제시합니다. ViT와 기존 CNN계열 모델을 능가하는 성능을 가지며 여러 Task 실험에서 높은성능을 달성했습니다.
Introduction
CNN의 성능을 높이기 위한 돌파구로 네트워크 깊이 쌓기, 효율적인 구조 만들기, multi-scale ability, attention mechanisms, shared sliding-window 전략 등 다양한 시도들이 있었습니다. 인지 심리학과 신경과학분야에서 사람의 시각 인지는 자극의 일부만 세부적으로 처리하고 나머지는 거의 처리되지 않은 상태로 남겨진다고 믿습니다. 논문의 저자가 attention 매커니즘을 선택한 이유도 이러한 이유 때문인 것 같습니다. attention mechanism은 adaptive selecting process로 볼 수 있습니다.
ViT가 나오고 CNN을 능가하는 성능이 나와 transformer-based model이 object detection, semantic segmentation 리더보드를 거의 다 차지했지만, self-attention에는 단점이 존재했습니다.
- 2D 구조를 파괴
- 고해상도 이미지 처리에 오버헤드가 너무 큼
- channel dimension을 고려하지 않음
이어서 CNN의 단점도 보겠습니다.
- 정적 가중치를 채택(layer에서 parameter sharing을 의미하는 것 같습니다.)
- 적응성(adaptability) 부족
본 논문에서는 LKA(Large Kernel Attention)라고 불리는 새로운 linear attention mechanism을 제시합니다.
Related Work
CNN
논문은 MobileNet에서 사용하는 메서드와 유사합니다. 본 논문에서는 convolution 연산을 세 단계로 분해하는 방법을 사용합니다. depth-wise convolution, depthwise dilated convolution, potinwise convolution 세 단계로 쪼갭니다.
Visual Attention Methods
RAM에서 소개된 attention 매커니즘은 input feature에 대한 adaptive selection process로 볼 수 있습니다. 컴퓨터 비전에서의 attention은 네 개의 카테고리로 나누어집니다.
1. channel attention
2. spatial attention
3. temporal attention
4. branch attention
각 attention은 각가 다른 효과를 가지고 있습니다.
트랜스포머 기반 모델에서는 위에서 말한 단점 3개를 가지고 있습니다. LKA는 이 단점을 보완하고 self-attention에서의 장점인 적응성(adaptability)와 장거리 픽셀의 의존성을 가져갑니다. 추가적으로 CNN의 이점인 local 정보 활용도 가져올 수 있습니다.
Vision MLPs
요약하면 논문의 방법은 gMLP와 비슷한데 이 방법은 두가지 단점을 가지고 있지만 단점을 피하면서 VAN의 장점을 사용한다는 내용입니다.
Method
Large Kernel Attention
반복된 내용이지만 논문에서 언급하니 한번더 적도록 하겠습니다.
attention mechanism은 adaptive selection process로 불립니다. adaptive selection process은 구별되는 특징들을 선택할 수 있고, 자동으로 input feature에 대한 noisy한 반응을 무시한다고 합니다.(이게 바로 딥러닝의 신기함...그냥 커다란 함수일 뿐인데 저절로 이렇게 학습한다는 자체가 신기하네요)
attention mechanism에서 서로 다른 feature간의 관계를 학습하기 위해 두가지 알려진 방법이 있습니다. 하나는 self-attention이고 다른 하나는 large kernel convolution 사용입니다. large kernel에는 파라미터 와 계산 비용이 너무 크다는 문제가 있는데 본 논문에서는 self-attention의 장점을 가져오고 large kernel분해를 통해 이를 극복합니다.
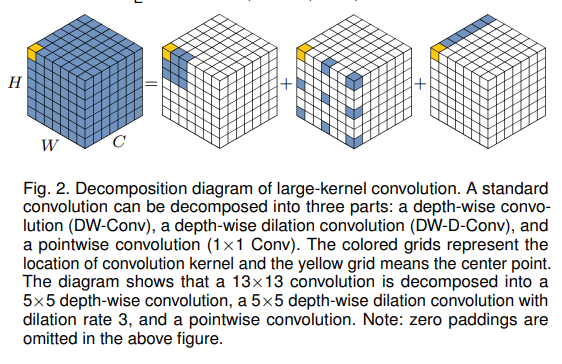
위의 그림을 보면 논문에서 large kernel convolution을 어떻게 쪼갰는지 알 수 있습니다. 하나씩 보면 a spatial local convolution(depth-wise convolution), a spatial long-range convolution(depth-wise dilation convolution), a channel convolution(1 1 convolution)입니다.
조금 더 자세하게 보면 conv를 d만큼 dilation을 준 depth-wise conv로 거치고 depth-wise연산과 1 1 convolution을 거쳐 연산이 됩니다. 식으로 간단히 나타내면 아래와 같습니다.
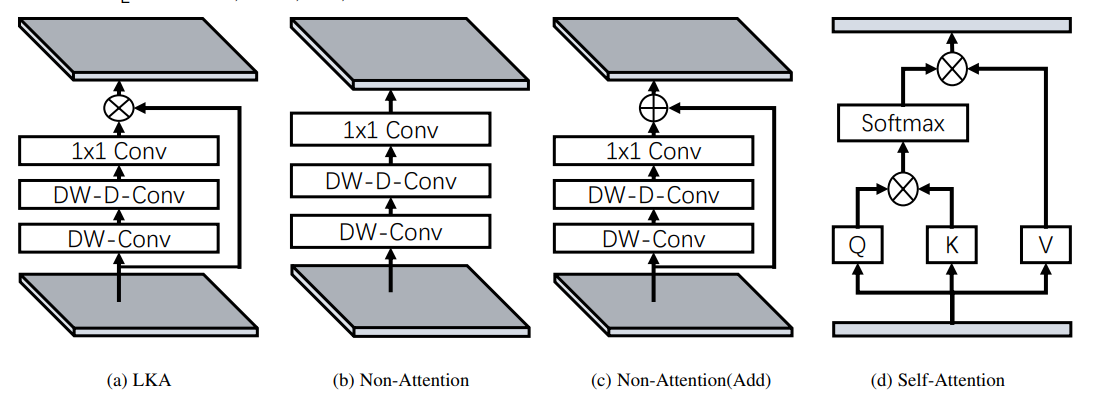
또 LKA는 일반 attention과 다르게 시그모이드나 소프트맥스같은 추가 정규화 함수가 필요하지 않습니다. 오히려 Sigmoid를 쓰면 성능이 낮아집니다..
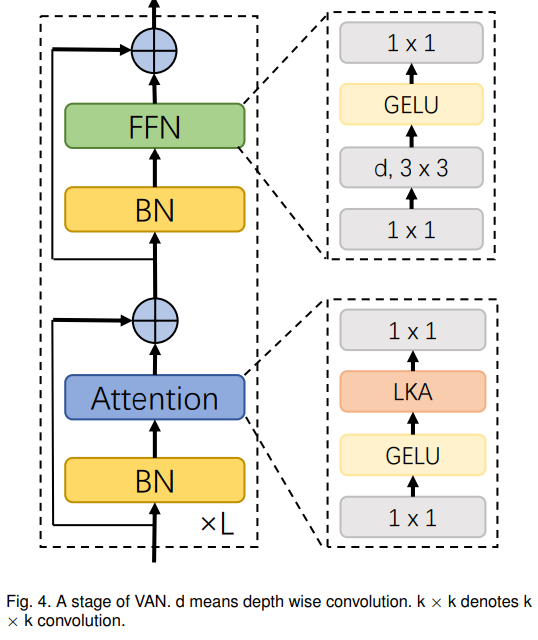
Visual Attention Network(VAN)
글로 길게 설명되어있지만 그림을 통해 쉽게 이해할 수 있습니다.
Complexity analysis
input shape이 일때 파라미터 수와 FLOPs 표현식입니다.(bias는 생략, d는 dilation rate)
논문에는 위의 식으로 나와있는데 로 포현해야 할 것 같은데 계산식이 좀 잘못 된 것 같습니다.
찾아보니 zhihu에는
로 나와있습니다.
Experiments
관련 실험을 여러개 했지만 조금 생략하고 중요하다고 생각되는 것만 가져와봤습니다.
k를 21로 사용한 이유가 궁금했는데 일정 범위를 넘어가면 파라미터만 증가하고 성능이 오르지않아 21로 정한 것 같습니다.
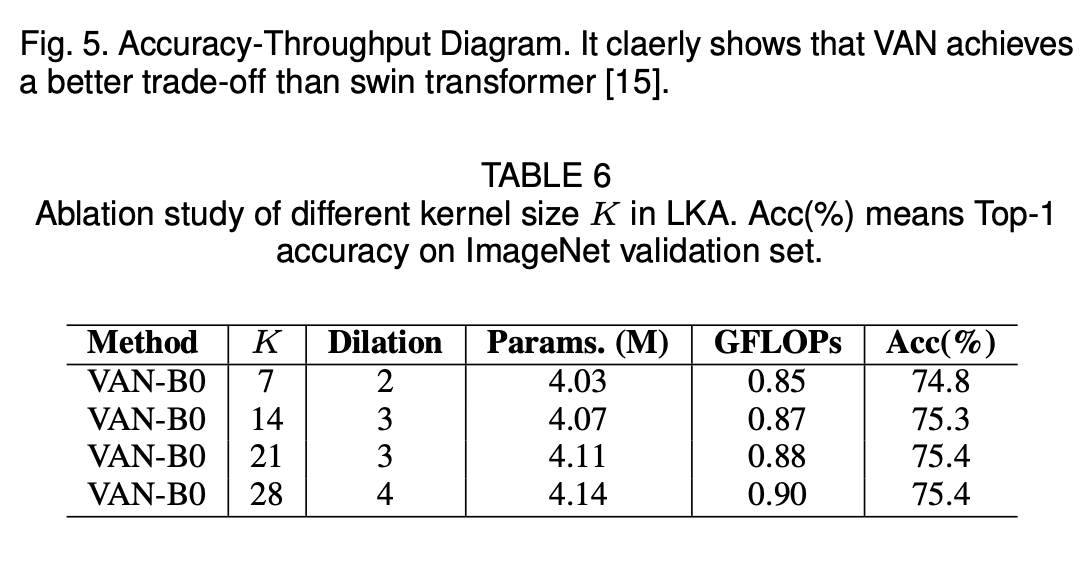
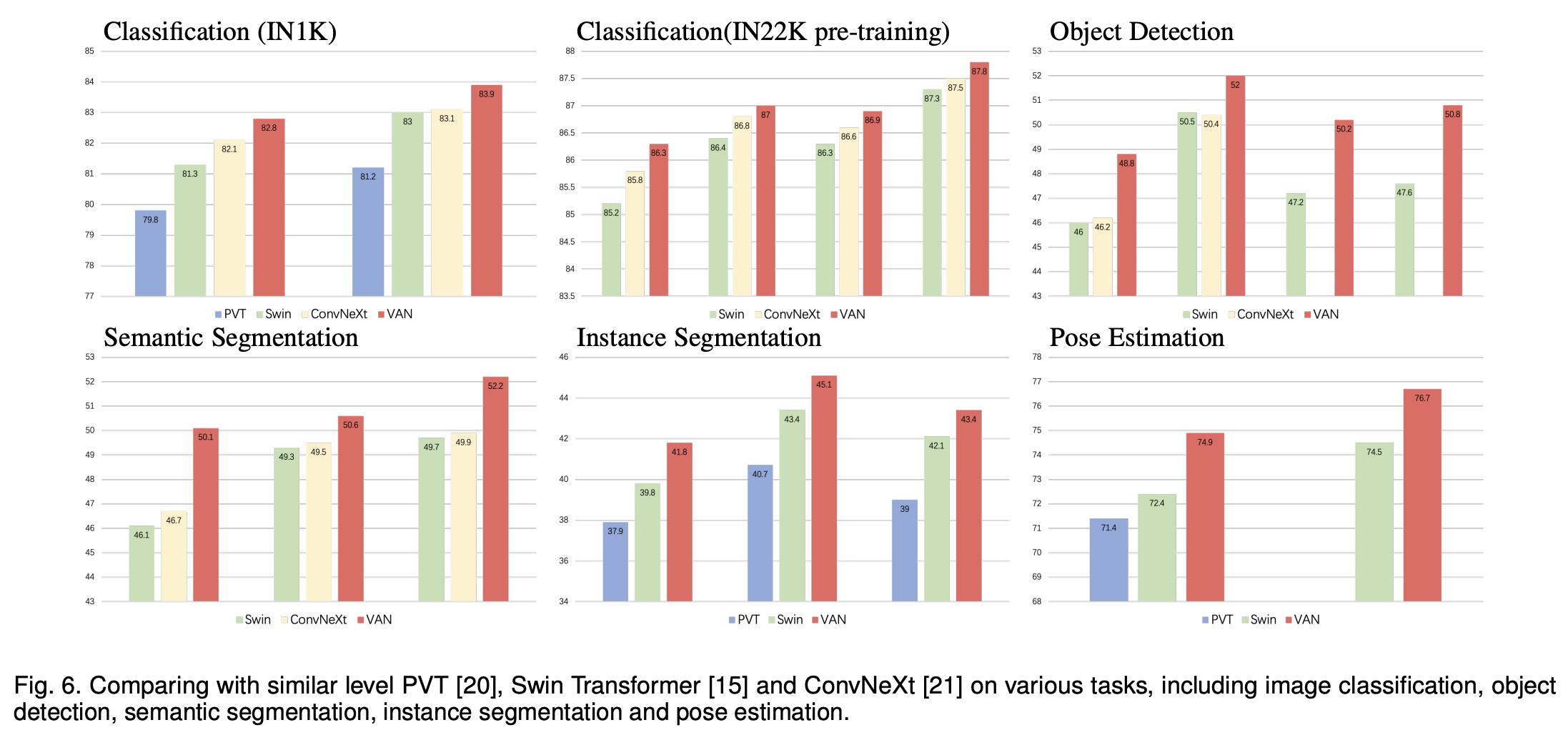
아래는 여러 image 관련 데이터 Task의 결과들입니다. VAN의 결과가 가장 좋은 것을 볼 수 있습니다.
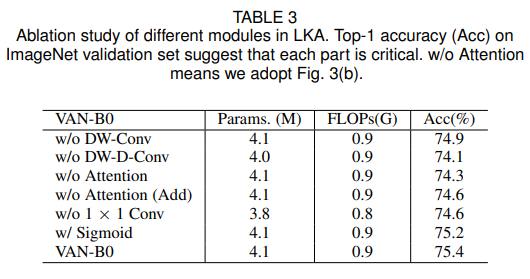
Sigmoid제거는 위에서 얘기했으니 넘어가겠습니다. 이 외에도 ablation study 내용도 table3에 나와있습니다.
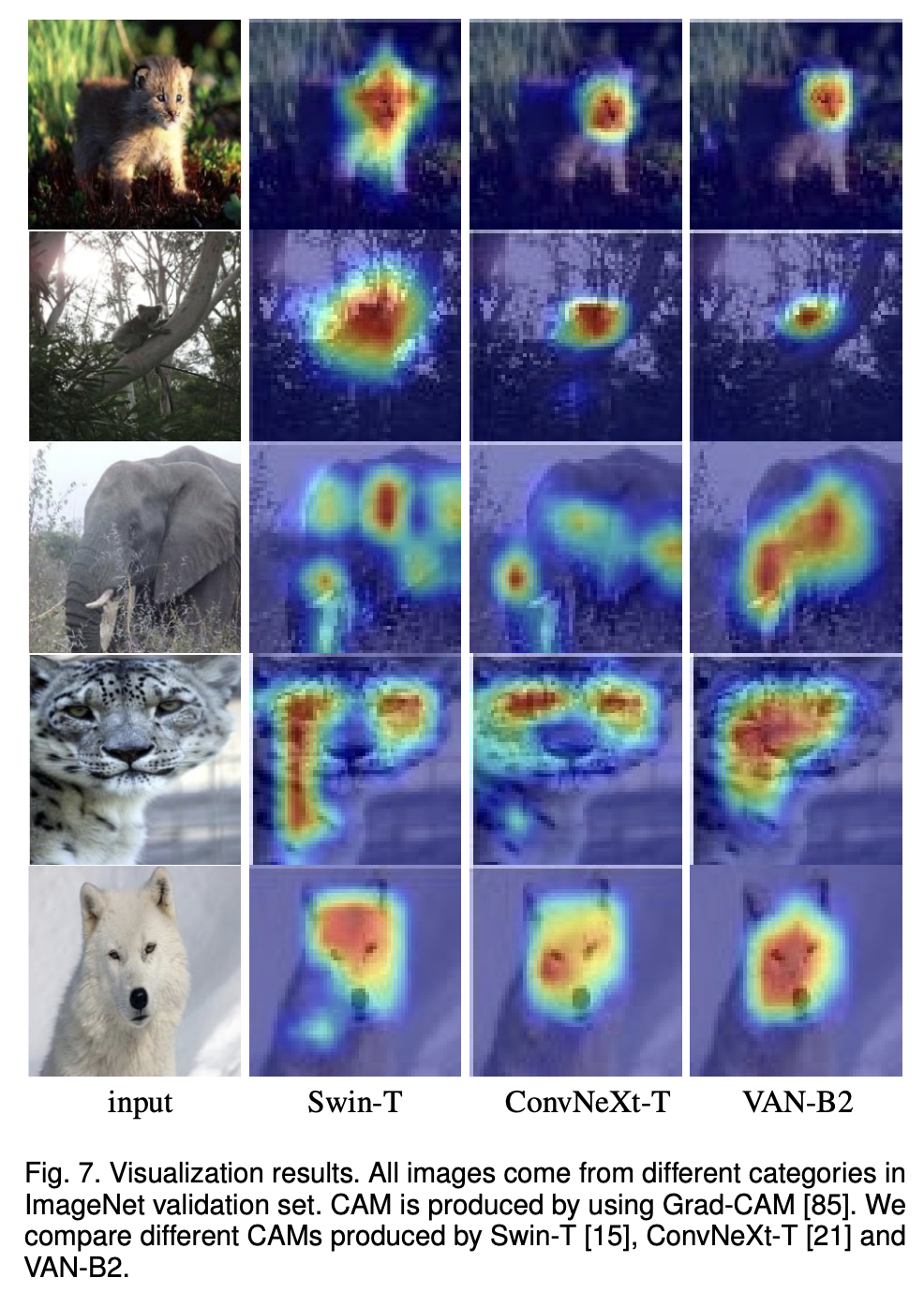
grad-CAM으로 시각화한 자료도 있습니다. 사실 이걸 보고 더 잘했다고 판단할 수 있을지는 모르겠네요.
학습 불안정
생각보다 배치 수가 중요하다는 것을 공식 repo issue인 Issue about traning를 보고 느꼈습니다.
학습 불안정 관련 이슈는 backbone 학습 불안정에 나와있는데 답변을 보니 어느정도 해결책이 있는 것 같습니다.
Why Sigmoid isn't used in the LKA module? 이슈도 sigmoid관련 학습 불안정에 대해 얘기하는데 한번 생각해볼만한 이슈인 것 같습니다.
Discussion & Conclusion
최근 self-attention을 사용하는 transformer-based 모델이 빠르게 발전하고 리더보드를 점령하고 있는데 본 논문에서는 LKA를 제시하며 self-attention을 대체할 수 없다는 사람들의 생각을 바꾸고 어떤 attention이 visual task에 더 적합할지 고민해보게 합니다.
Future Work
- multi scale 구조 혹은 multi branch 구조 적용
- self-supervised learning, transfer learning 적용
- 다른 분야에 적용
