들어가며
우아한 테크코스 백엔드 3기 수업 중 조회 성능 개선하기를 정리하고, 개인적으로 보강한 내용입니다~!
shout out to CU 코치
쿼리 최적화의 필요성
-
웹 어플리케이션에서 DB는 뗄레야 뗄 수 없는 사이! DB에 조회하고 저장하는 작업이 주를 이루게 됩니다. 서버 처리시간의 대부분이 SQL을 처리하는 시간에 들어가곤 하는데, 서버의 응답이 느려질수록 유저의 만족도는 떨어져가겠죠..
-
웹사이트 전문가 제이콥 닐슨은 응답 속도에 따른 유저 경험을 다음과 같이 평가합니다. 링크
0.1초 : 즉각적인 응답이라는 느낌을 준다
1초 : 지연을 감지하고 컴퓨터가 결과를 처리하고 있다는 느낌을 받지만, 아직 스스로 제어할 수 있다고 느낀다.
10초 : 사용자가 집중력을 유지할 수 있는 한계. 10초가 지나면 유저의 신경이 돌아오기 쉽지 않다. -
보통 10초의 유저경험은 사이트를 즉시 떠나게 한다고 말합니다. UX의 첨단을 맡고있는 프론트엔드 개발자가 이 악물고 성능최적화 해놨는데, API콜이 지연되서 유저경험이 늦어지면... 팀원을 볼 낯이 없겠죠..
-
항상 모든 것을 고려하며 개발을 할 순 없기에, 모든 쿼리를 최적의 상태로 짜야한다는 부담 밑에서 쿼리를 짤 필요는 없습니다. 그러나 API콜의 지연이 유저경험에 지장을 준다면, 그 땐 쿼리최적화를 고려해볼 수 있겠죠!
튜닝 절차
- 일단 조회합니다.
- 가장 중요한 것은 뭐니뭐니해도 원하는 결과를 조회하는 거겠죠?
- 조회 건수, fetch time / duration time등을 확인합니다.
- 개선 대상을 파악합니다.
- 문제가 되는 조회쿼리를 확인합니다.
- 실행 계획을 확인합니다.
- 조건절 컬럼, 조인/서브쿼리 구조, 정렬 등을 확인합니다.
- 인덱스 현황을 파악합니다.
- 개선합니다.
이번 포스팅에선 개선 대상을 파악하는, 실행 계획을 읽는 법에 대해 다룹니다.
문제되는 쿼리 확인
운영 환경에선 그동안 수행된 쿼리에 대한 통계데이터가 쌓이게 됩니다. 해당 통계 중 문제되는 쿼리를 확인할 때 사용할 수 있는 쿼리 목록입니다.
## 프로세스 목록
SHOW PROCESSLIST;
## 슬로우 쿼리 확인
SELECT query, exec_count, sys.format_time(avg_latency) AS "avg latency", rows_sent_avg, rows_examined_avg, last_seen
FROM sys.x$statement_analysis
ORDER BY avg_latency DESC;
## 성능 개선 대상 식별
SELECT DIGEST_TEXT AS query,
IF(SUM_NO_GOOD_INDEX_USED > 0 OR SUM_NO_INDEX_USED > 0, '*', '') AS full_scan,
COUNT_STAR AS exec_count,
SUM_ERRORS AS err_count,
SUM_WARNINGS AS warn_count,
SEC_TO_TIME(SUM_TIMER_WAIT/1000000000000) AS exec_time_total,
SEC_TO_TIME(MAX_TIMER_WAIT/1000000000000) AS exec_time_max,
SEC_TO_TIME(AVG_TIMER_WAIT/1000000000000) AS exec_time_avg_ms, SUM_ROWS_SENT AS rows_sent,
ROUND(SUM_ROWS_SENT / COUNT_STAR) AS rows_sent_avg, SUM_ROWS_EXAMINED AS rows_scanned,
DIGEST AS digest
FROM performance_schema.events_statements_summary_by_digest ORDER BY SUM_TIMER_WAIT DESC
## I/O 요청이 많은 테이블 목록
SELECT * FROM sys.io_global_by_file_by_bytes WHERE file LIKE '%ibd';
## 테이블별 작업량 통계
SELECT table_schema, table_name, rows_fetched, rows_inserted, rows_updated, rows_deleted, io_read, io_write
FROM sys.schema_table_statistics
WHERE table_schema NOT IN ('mysql', 'performance_schema', 'sys');
## 최근 실행된 쿼리 이력 기능 활성화
UPDATE performance_schema.setup_consumers SET ENABLED = 'yes' WHERE NAME = 'events_statements_history'
UPDATE performance_schema.setup_consumers SET ENABLED = 'yes' WHERE NAME = 'events_statements_history_long'
## 최근 실행된 쿼리 이력 확인
SELECT * FROM performance_schema.events_statements_history어떤 조회쿼리가 느린지 확인했다면, 개선하기 위해 해당 실행쿼리를 분석할 때 입니다. 이때 실행계획을 확인하여 개선방향을 잡을 수 있습니다.
실행계획
실행계획이 뭔가요?
실행계획은 쿼리 옵티마이저가 데이터를 조회하기 위한 계획을 의미합니다.
그럼 쿼리 옵티마이저는 뭔데요??
MySQL 조회시 플로우
아래는 MySQL 서버에 조회를 요청 했을 때 flow chart입니다.
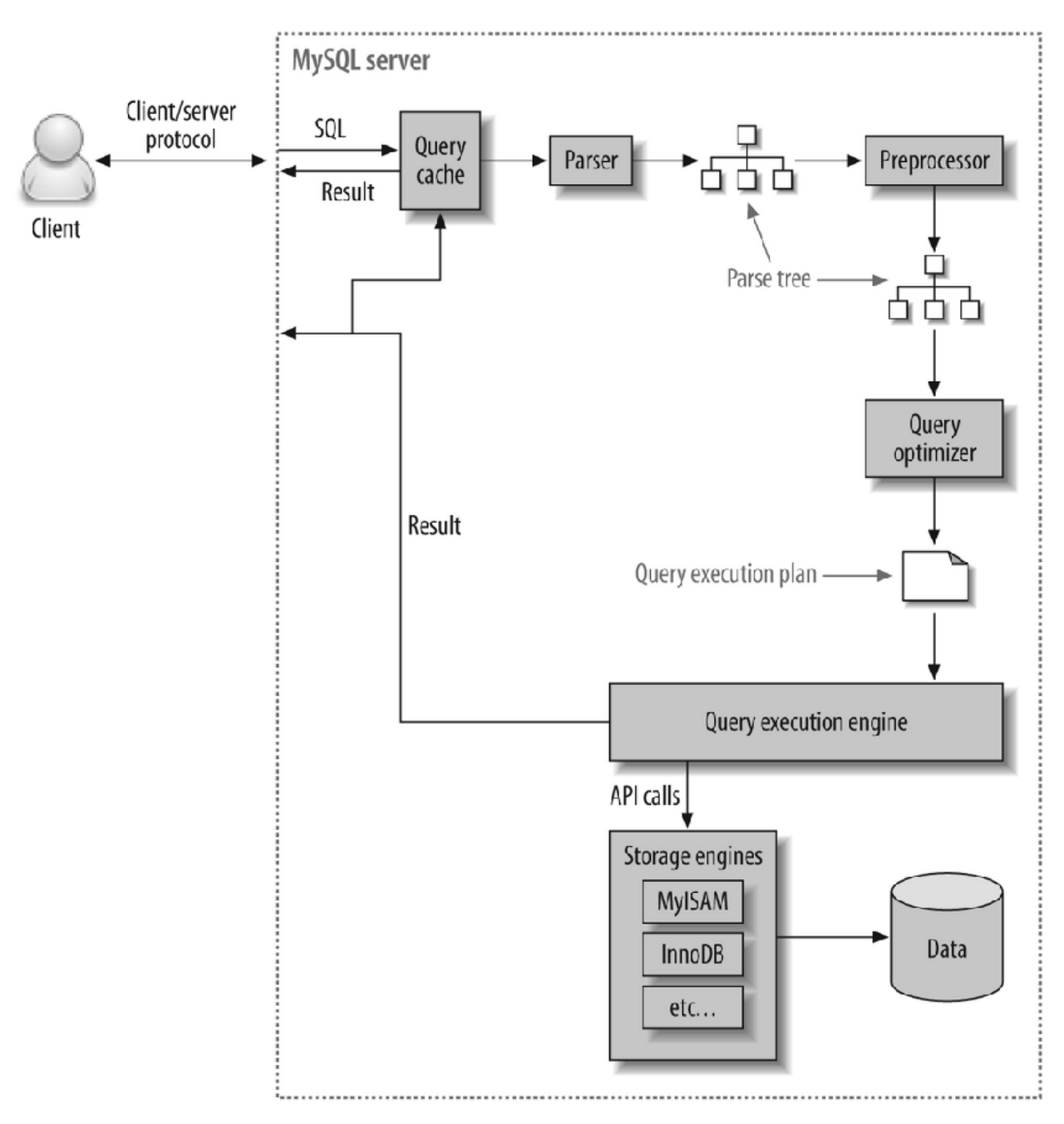
여기서 client는 쿼리를 요청한 클라이언트, 즉 SQL을 입력한 개발자입니다.
- Query Cache
- SQL문이 key, 결과가 value인 맵입니다. 데이터가 변경되었으면 쿼리캐시가 삭제되어야겠죠?(조회 결과가 달라질 것이기 때문에) 이는 동시 처리 성능 저하를 유발하고, 버그의 원인이 되어 MySQL 8.0 버전부터는 삭제되었습니다.
- Parsing
- 사용자가 요청한 SQL을 잘게 쪼개어 서버가 이해할 수 있는 수준으로 분리합니다.
- Preprocessing
- 해당 쿼리가 문법적으로 틀린지 확인하여 부정확하면 처리를 중단합니다. (흔히 만나보는 syntax 에러는 parser와 preprocessor에서 발생합니다.)
- Query Optimization
- 실행계획은 이 단계에서의 출력을 의미합니다.
- 쿼리 분석 : where절의 검색 조건인지, join 조건인지 판단합니다.
- 인덱스 선택 : 각 테이블에 사용된 조건과 인덱스 통계 정보를 이용해 사용할 인덱스를 결정합니다.
- 조인 처리 : 여러 테이블의 조인이 있는 경우, 어떤 순서로 테이블을 읽을지 결정합니다.
- Handler (Storage Engine)
- MySQL Execution engine의 요청에 따라 데이터를 디스크로 저장하고, 디스크로부터 읽어오는 역할을 합니다. 대표적인 스토리지 엔진은 InnoDB, MyISAM 이 있습니다. MySQL 엔진에서는 스토리지 엔진으로부터 받은 레코드를 조인하거나 정렬하는 작업을 수행합니다.
우리가 SQL을 작성 했을 때, parser와 preprocessor에 의해 분해되고, query optimizer에 의해 최상의 실행계획을 수립하여 실행된다는 것을 알게 되었네요!
그럼 실행계획을 읽는 법을 확인해봅시다!
실행계획 확인
워크벤치에서 Visual Optimizer 활용
SQL 워크벤치는 실행계획의 시각화를 제공합니다. 쿼리를 작성한 후, 실행이 아니라 돋보기 버튼을 누르면!
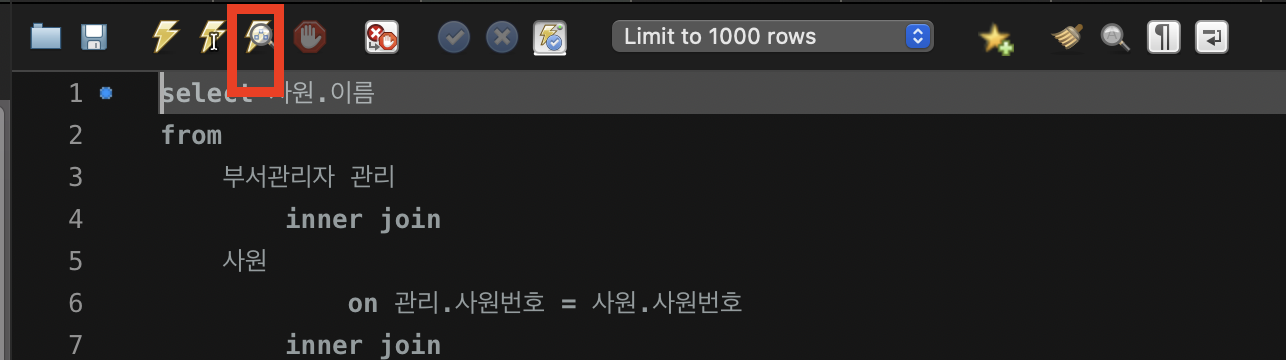
-- 활성화 된 부서 중 월급을 가장 많이 받는 부서관리자 5명의 이름을 구하는 쿼리
select 사원.이름
from
부서관리자 관리
inner join
사원
on 관리.사원번호 = 사원.사원번호
inner join
부서
on 부서.부서번호 = 관리.부서번호
inner join
급여
on 급여.사원번호 = 관리.사원번호
where
부서.비고 = 'ACTIVE'
order by 급여.연봉 desc
limit 0, 5아래와 같이 결과화면이 display 됩니다.
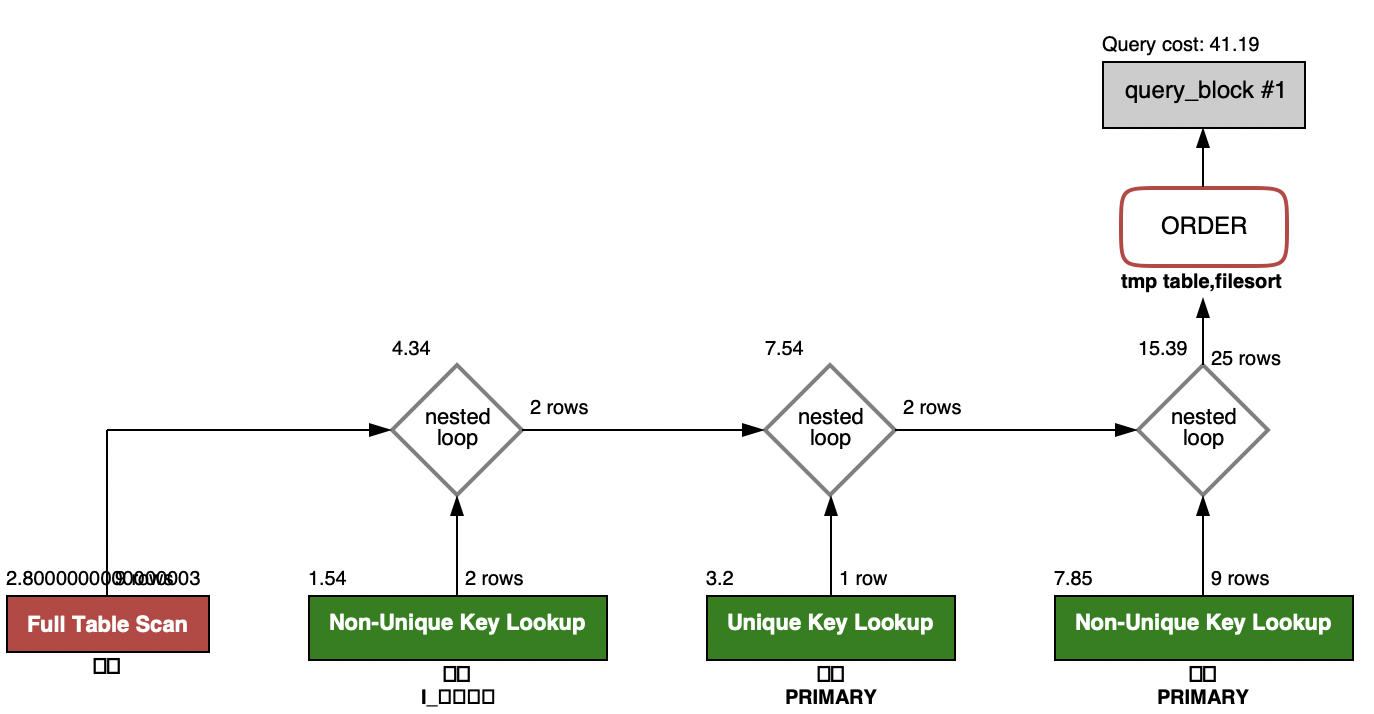
어떤 테이블은 full table scan이고, 어떤 테이블은 index range / full / unique scan인지 시각화 하여 보여줍니다. 어떤 방식으로 조인되었고, 결과 row는 몇 개 이며, group by 및 order by는 어떤 식으로 수행되었는지 확인할 수 있습니다.
(full table scan과 index scan에 대해선 2. index편에서 다루겠습니다!)
한 눈에 실행계획을 확인할 수 있기 때문에, 간단하게 쿼리 수행계획을 진단할 때 활용하기 좋습니다.
SQL로 확인
Explain 명령어를 통해서 실행계획을 확인할 수 도 있습니다.
explain select 사원.이름
from
부서관리자 관리 ...
각 항목에 대해 알아봅시다!
-
id
- 하나의 SELECT 문은 1개 이상의 SUB Select문을 포함할 순 있죠? 위의 쿼리를 서브쿼리로 한번 감쌌다고 생각해보겠습니다.explain select ... <- A from ( select 사원.이름 <- B ... )내부테이블;이와 같은 경우 select 문을 A와 B, 두개로 나누어 생각할 수 있습니다.
하나 하나의 select 쿼리는 실행계획에서 id를 가집니다. 여러 테이블을 조인하면, 조인되는 테이블의 개수만큼 id가 출력되지만 같은 id값이 부여됩니다.
바로 위 쿼리의 실행결과는 다음과 같은데, join된 4개 테이블이2의 id값을 가지고 있음을 볼 수 있습니다.

주의 해야 할 것은 id가 테이블의 실행순서를 의미하지는 않는다는 점입니다. where절에 서브쿼리를 명시하면 서브쿼리에서 읽어온 테이블의 id는 from절의 테이블보다 밀리지만, 실제 실행순서는 서브쿼리가 먼저 실행됩니다. -
select_type
SELECT 문의 유형을 의미합니다. 다음과 같은 종류가 있습니다.
- SIMPLE : 단순한 SELECT 문
- PRIMARY : 서브쿼리를 감싸는 외부 쿼리, UNION이 포함될 경우 첫번째 SELECT 문
- SUBQUERY : 독립적으로 수행되는 서브쿼리(SELECT, WHERE 절에 추가된 서브쿼리)
- DERIVED : FROM 절에 작성된 서브쿼리
- UNION : UNION, UNION ALL로 합쳐진 SELECT 문
- DEPENDENT SUBQUERY : 서브쿼리가 바깥쪽 SELECT 쿼리에 정의된 칼럼을 사용 하는 경우

- DEPENDENT UNION : 외부에 정의된 칼럼을 UNION으로 결합된 쿼리에서 사용하는 경우
- MATERIALZED : IN 절 구문의 서브쿼리를 임시 테이블로 생성한 뒤 조인을 수행
- UNCACHEABLE SUBQUERY : RAND(), UUID() 등 조회마다 결과가 달라지는 경우 -
type
- system : 테이블에 데이터가 없거나 한 개만 있는 경우
- const : 조회되는 데이터가 단 1건일 때
- eq_ref : 조인이 수행될 때 드리븐 테이블의 데이터에 PK 혹은 고유 인덱스로 단 1건의 데이터를 조회할 때
- ref : eq_ref와 같으나 데이터가 2건 이상일 경우
- index : 인덱스 풀 스캔
- range : 인덱스 레인지 스캔
- all : 테이블 풀 스캔
-
key
옵티마이저가 실제로 선택한 인덱스 -
rows
SQL문을 수행하기 위해 접근하는 데이터의 모든 행 수 -
extra
- Distinct : 중복 제거시
- Using where : WHERE 절로 필터시
- Using temporary : 데이터의 중간 결과를 저장하고자 임시 테이블을 생성, 보통 DISTINCT, GROUP BY, ORDER BY 구문이 포함된 경우 임시 테이블을 생성
- Using index : 물리적인 데이터 파일을 읽지 않고 인덱스만 읽어서 처리, 커버링 인덱스
- Using Filesort : 정렬 시
실행계획 개선방향
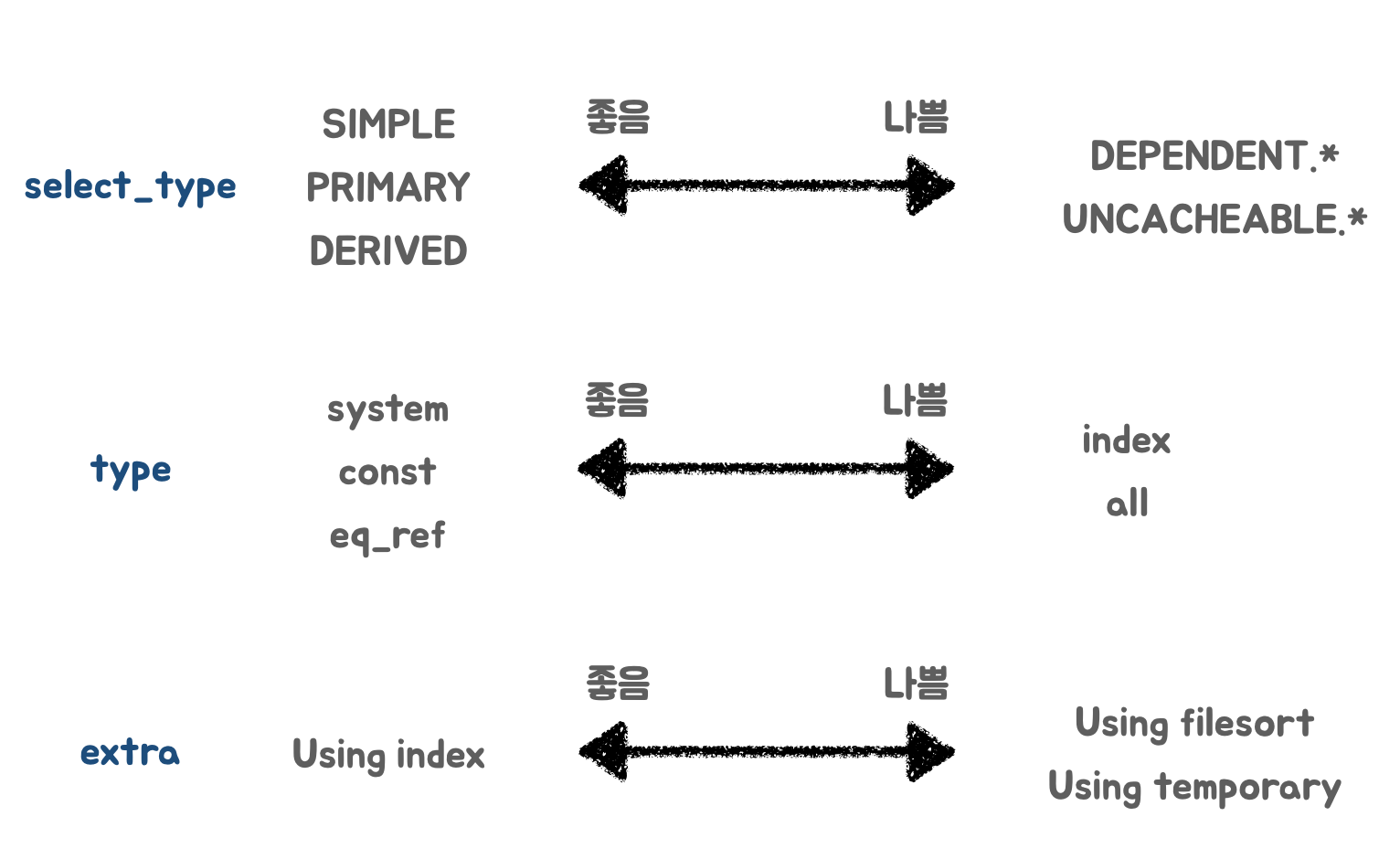
- 출처 : 강의자료
select_type : dependent. type은 조회시마다, 외부 테이블에 access하게 되므로 성능에 악역향을 미칩니다. Rand함수들을 활용하면 uncacheable.이 나오는데, 이 또한 마찬가지고요.
type : 인덱스 레인지 풀 스캔, 혹은 테이블 풀 스캔을 줄일 수 있는 방향으로 개선해야 합니다.
extra : filesort나 group by를 위한 temp 테이블 생성보다 인덱스를 활용하여 sorting/group by를 수행할 수 있다면 성능을 개선할 수 있습니다.
마치며
실행 계획을 개선할 때 full table scan, index scan 이야기를 빼놓을 수 없을 것 같아요! 2편 글은 인덱스와 테이블 스캔에 대해 알아보고, 조회쿼리를 개선하기 위한 인덱싱 방법과 주의사항에 대해 다루겠습니다~~!
