Attention is All You Need
FACTORIZATION TRICKS FOR LSTM NETWORKS
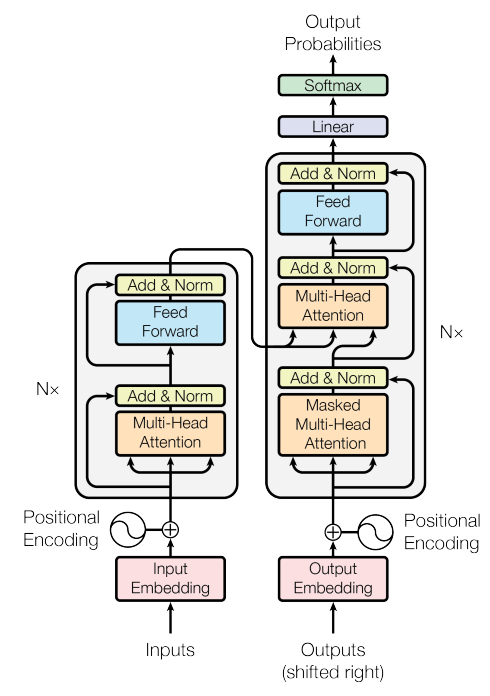
다른 언어를 번역할 때 문법적으로 위치도 다르고 길이도 다르기 때문에 이를 개선하기 위해 Seq2Seq구조가 제안되었다.
Encoder - Decoder구조로 알려져 있는데, encoder에서 입력된 단어의 흐름을 순차적으로 입력받아 정보를 하나의 벡터로 압축하는데 이것은 Context Vector라고 한다. 이를 decoder로 전송해서 순차적으로 출력하는 구조를 Seq2Seq라고 한다.
Context Vector의 크기는 가변적이여야 하는데, 고정된 크기라서 압축하는 과정 중 병목현상이 발생해서 성능 하락의 원인이다.
Transfomer로 이 구조를 파악해 문제를 해결했다.
아 너무 어려우니까 용어 정리부터 하자
- Attention의 아이디어
decoder로 출력 단어를 예측하는 매 시점마다 인코더에서 전체 입력 문장을 다시 한번 참고한다는 점. 전체를 동일하게 참고하는게 아닌, 예측해야할 단어 부분을 집중해서 보게된다.
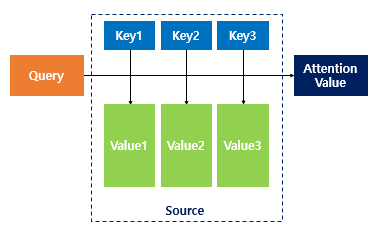
Attention(Q, K, V) = Attention Value
주어진 query에 대해서 모든 key와 유사도를 각각 구한다. 그리고 각 키와 맵핑되어있는 value를 반영해서 모두 더해 리턴한 것을 attention value라고 한다.
과제
- 벡터와 스칼라 조사하기 -> 딥러닝 + 수학적인 관점에 대해서
딥러닝에서는 대부분 tensor라는 단위를 사용하니까 거기서 vector, scalar라는 단위에 대해 알기
- Scaled Dot Product -> softmax 조사하기
- Attention이 뭔지 알고, self attention이 뭔지 알기
- drop out에 대해 조사하기
트랜스포머 시각화 자료 보기:
1. https://www.youtube.com/watch?v=6s69XY025MU&t=1s
2. https://www.youtube.com/watch?v=wjZofJX0v4M
이걸 보고 다시 논문에 대해 알아오기

잘하는 건 노력