벡터(Vector)와 스칼라(Scalar)란?
- 스칼라
- 크기만을 가진 값이다.
- 방향이 없고 단순히 크기만을 나타낸다.
- 벡터
- 크기와 방향을 모두 가진다.
- 화살표로 표현한다면, 화살표의 길이는 벡터의 크기, 방향은 벡터의 방향을 나타낸다.
좌표에서 보는 벡터와 스칼라의 비교
- 스칼라는 크기 정보만을 제공해서 방향 정보를 포함하지 않는다.
ex) 온도, 거리, 무게가 스칼라의 예시 - 스칼라는 단순한 수치 값으로 벡터보다 다루기 쉽다. 하지만 방향이나 이동과 같은 정보를 얻을 수는 없다.
- 스칼라는 산술 연산을 수행할 수 있지만 방향에 대한 정보가 없기 때문에 연산과는 다르게 작동한다.
행렬로 표현되는 벡터와 스칼라의 비교
스칼라
- 스칼라는 단일 값으로 0차원이며 스칼라 a는 행렬 [a]로 표현될 수 있다.
[a]는 1차원 벡터를 나타내어 벡터와 스칼라의 연산을 수행할 때 사용된다.
벡터
- 여러 값을 가질 수 있고, 1*n행렬로 표현될 수 있다.
LLM에서 벡터의 역할
단어, 문장 || 문서를 벡터로 표현할 수 있다. 2차원 이상의 좌표에서 특정 단어나 문장을 벡터로 표현 가능하다. 여기서 벡터간의 연산을 통해 의미를 알아내고, 문장 사이의 유사성 및 관계를 계산하는데 사용된다.
- 임베딩: 텍스트를 벡터로 변환하는 과정을 임베딩이라고 한다. 이것은 단어 혹은 문장의 의미를 벡터 공간에서 점으로 나타내기에 특정한 위치 좌표를 가진다.
파이썬에서의 스칼라와 벡터, 행렬 텐서
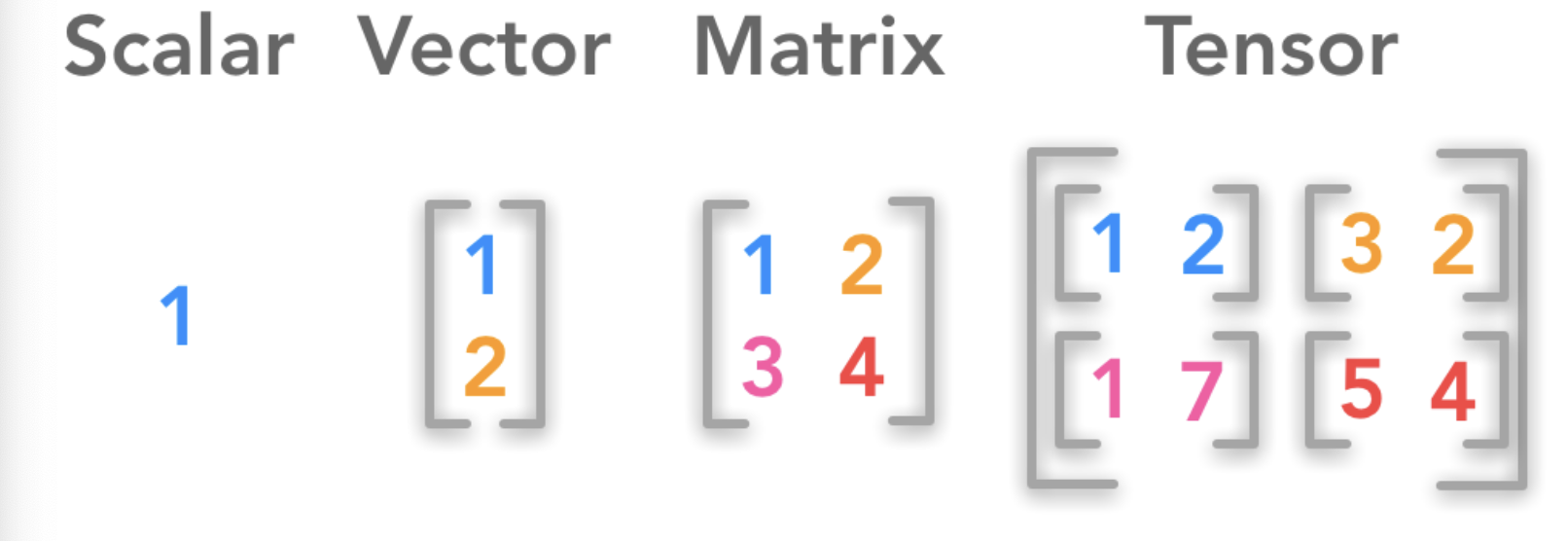
- 스칼라: 한 개의 숫자형을 말한다.
- 벡터: 스칼라를 일직선 상에 나열한 것.
- 행렬: 스칼라를 격자 형태로 나열한 것. 다시 말해 2차원 배열이다.
- 텐서: 스칼라를 여러 개의 차원으로 나열한 것.
Scaled Dot-Product
Scaled dot product attention은 다음 공식으로 표현된다.
- Q: Query값 행렬
- K: Key값 행렬
- V: Value값 행렬
- 는 키 벡터의 차원
주요 단계
- 내적계산: Q, K의 전치행렬을 곱해 원시 어텐션 점수를 얻는다.
- 스케일링: 내적계산한 결과를 로 나눠서 기울기를 안정화시킨다.
- Softmax 적용. 이를 통해 확률 분포로 변환한다.
- softmax 결과를 v와 곱해서 최종 출력을 얻는다.
스케일링을 해줘야 하는 이유는?
Q와 K의 길이가 커질수록 내적값이 커질 가능성이 높아서 softmax의 기울기가 0인 영역에 도달할 가능성이 높기 때문이다.
Softmax의 역할
- 정규화: 어텐션 점수를 0 ~ 1 사이의 값으로 변환하며 모든 점수의 합이 1이 되도록 한다.
- 확률 분포 생성: 각 입력 토큰에 대한 어텐션 가중치를 확률로 해석할 수 있게 한다.
- 빈선형성 도입: 선형 연산인 내적과 스케일링 후, 도입해서 모델의 표현력을 높인다.
- softmax가 역전파 과정에서 원활하게 흐를 수 있게 만든다.
Attention이란?
문맥에 따라 집중할 단어를 결정하는 방식을 의미한다. 문장을 읽을 때 keyword에 집중해서 글을 읽는 것이 문맥을 파악하는 방법이라고 할 수 있는데, 이 방법을 딥러닝 모델에 적용한 것이 attention 매커니즘이라고 할 수 있다.

위의 번역 attention을 예시로 들면 "cafe"와 한국어 "카페"가 강한 연관을 가지고 있고, 다른 단어들과는 attention이 약하다.
Attention 모델의 구조
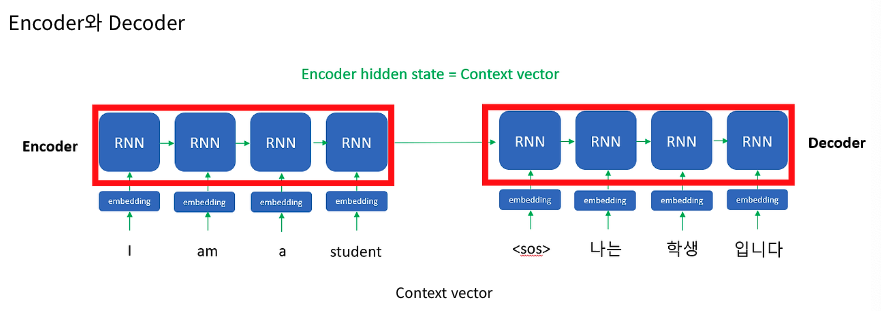
Attention 모델은 크게 Encoder와 Decoder로 구성되어 있다.
Encoder는 input data를 받아서 압축 데이터(context vector)로 변환 및 출력해주는 역할을 한다.
Decoder는 반대로 압축 데이터(context vector)를 입력받아 output data를 출력한다.
정보를 압축해주는 이유는 연산량이 줄어들기 때문. 하지만 정보의 손실이 발생하는 문제점도 발생하기에 Attention이라는 개념이 도입되었다.
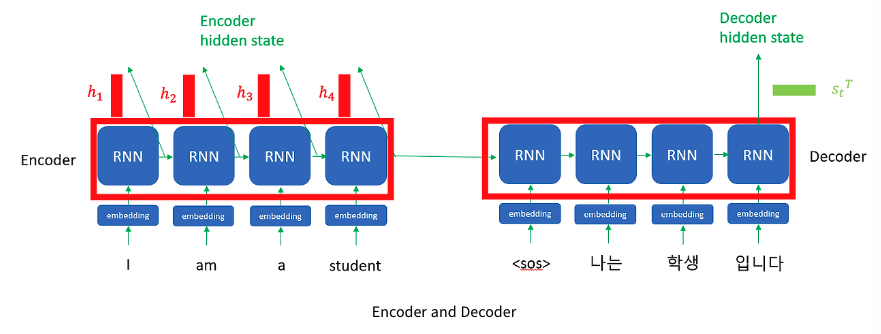
Encoder와 Decoder 모두 output을 hidden state로 출력한다. 하지만 차이점은 Encoder는 모든 RNN 셀의 hidden state을 사용하고, Decoder는 현재 RNN 셀의 hidden state만을 사용한다. 그 이유는 위의 한국어와 영어 번역 문장에서 보면 "cafe"라는 영단어에 모든 한국어 단어들이 매칭하면서 상관관계를 비교한다.
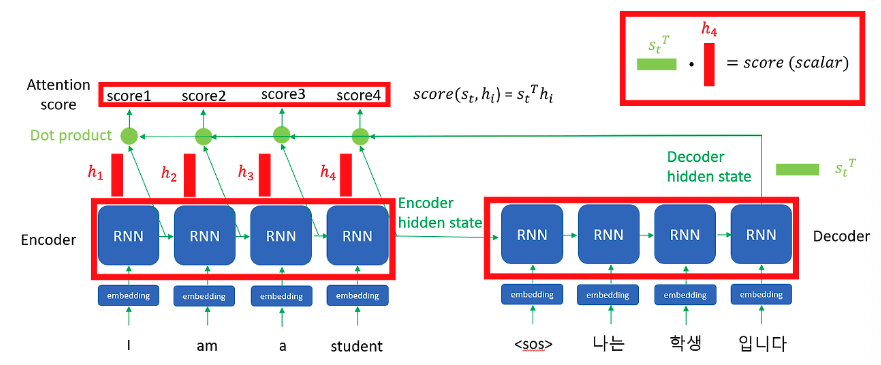
이제 encoder의 hidden state와 전치한 decoder의 hidden state를 내적해주면 상수값이 나오고, Encoder의 RNN 수만큼 나오는 데, 이걸 Attention score라고 부른다.
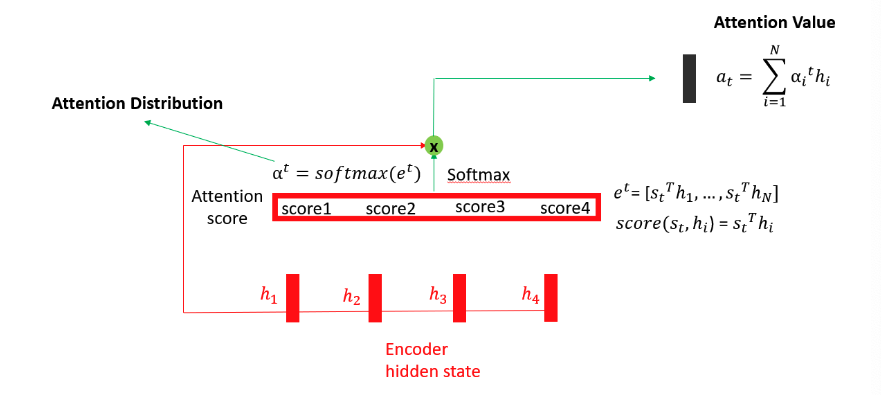
앞에서 구한 attention score를 softmax 활성함수에 대입해서 attention distribution을 만들어준다. 위에서도 설명했지만 softmax는 어떤 변수를 0 ~ 1 사이의 값으로 표준화 시켜주는데, 확률화 해준다는 말이랑 같다. 그리고 encoder hidden state를 attention distribution에 곱하고 합하여 attention value 행렬을 만든다. 그리고 Decoder hidden state를 attention value 아래에 쌓아준다. 이 과정을 concatenate라고 한다. 여기에 추가로 tanh, softmax 활성 함수를 이용해 학습하면 y값이 나온다.
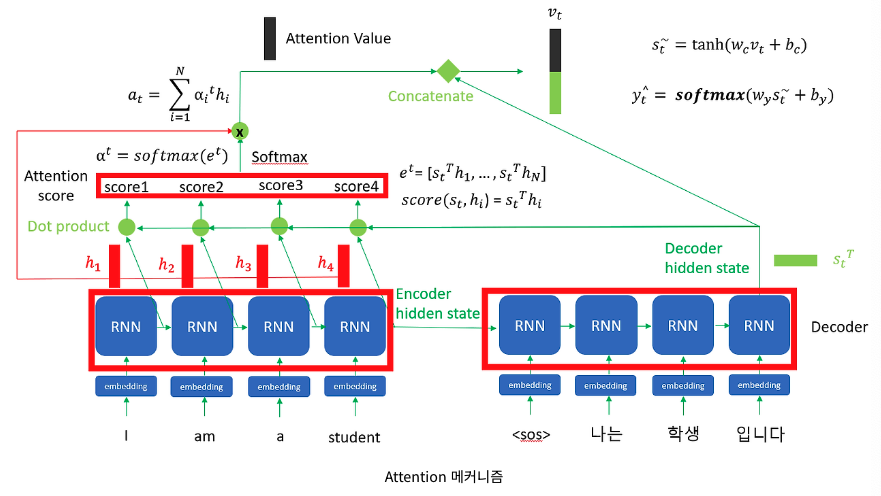
전체적인 매커니즘
self attention이란?
Attention을 자신한테 취한다는 말. 이를 통해서 다너들 관의 연관성을 알 수 있다.
"The animal didn't cross the street. because it was too tired." 여기서 it이 의미하는 것은 animal이라고 사람은 알 수 있지만, 컴퓨터는 알 수 없기에 이를 쉽게 해주는 것이 Self Attention이라고 한다.
Self Attention에서 중요한 개념은 Query, Key, Value의 값이 시작값이 동일하다는 점이다.
하지만 계속 Query, Key, Value가 동일하다는 말이 아니다. 학습을 통해서 값이 달라지기 때문이다.
공식:
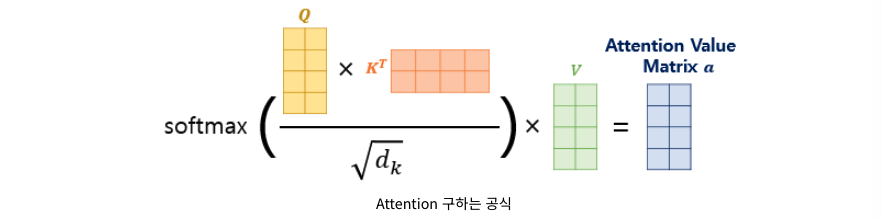
연관성을 구하기 위해 Q와 K를 내적한다. 이를 통해 attention score를 구할 수 있다. 여기서 내적 값이 커지면 모델 학습에 어려움이 생기기 때문에 차원만큼 나눠주는 스케일링을 해야한다.
여기까지 "Scaled Dot-Product Attention"이라고 한다.
스케일 된 값들을 softmax활성 함수를 거쳐 지금까지 계산된 score 행렬과 value 행렬을 내적해주면 attention행렬을 얻을 수 있다.
Drop-out
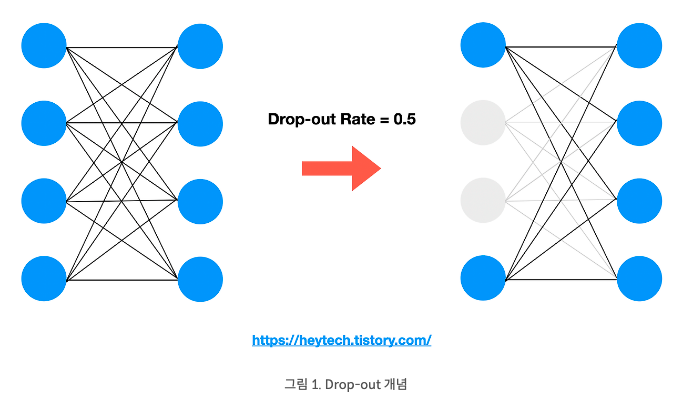
서로 연결된 신경망에서 0 ~ 1 사이의 확률로 뉴런을 제거하는 기법이다. 위의 그림처럼 Drop-out rate = 0.5라면 4개의 뉴런들 중 0.5의 확률로 제거되는 것이다. 그래서 총 2개가 제거되었음을 알 수 있다.
Drop-out을 사용하는 이유는?
Drop-out을 사용하면 어떤 특정한 feature만을 과도하게 집중하여 학습하는 과대적합을 방지할 수 있기 때문이다. Drop-out이 적용된 전결합계층은 하나의 Realization || Instance라고 부른다.
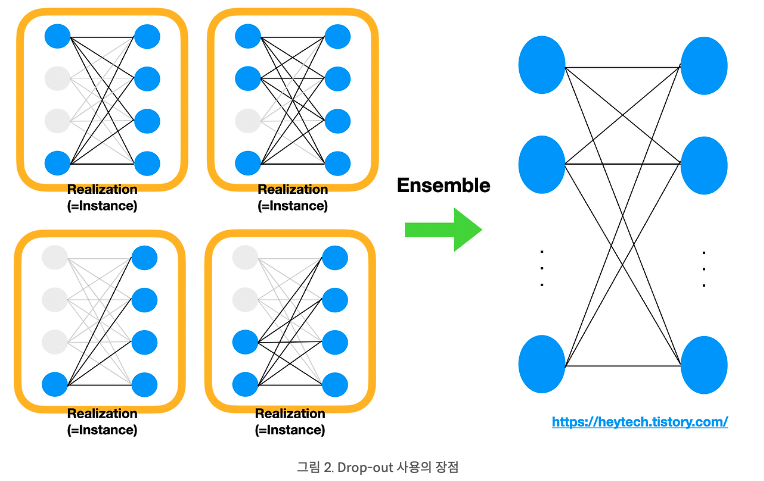
Drop-out이 적용된 계층들의 출력값에 평균을 취하면 모든 뉴런을 사용한 전결합계층의 출력값을 얻을 수 있다. 이 값은 Drop-out을 적용하기 전과 비교했을 때 편향되지 않은 출력값을 얻는데 효과적이다.
편향되지 않은 출력값이란? 어느 feature에 가장 큰 상관관계를 가지고 있다고 가정하고, drop-out을 적용하지 않고 학습하면 해당 feature에 가중치가 가장 크게 설정되어 나머지 feature들은 제대로 학습되지 않을 것이다. 만약 가장 큰 상관관계를 가진 feature를 제외하고 학습해도 좋은 출력값을 얻을 수 있다면, 과대적합을 방지하게 되고, 나머지 feature들도 종합적으로 확인할 수 있게 된다.
Test 시의 Drop-out
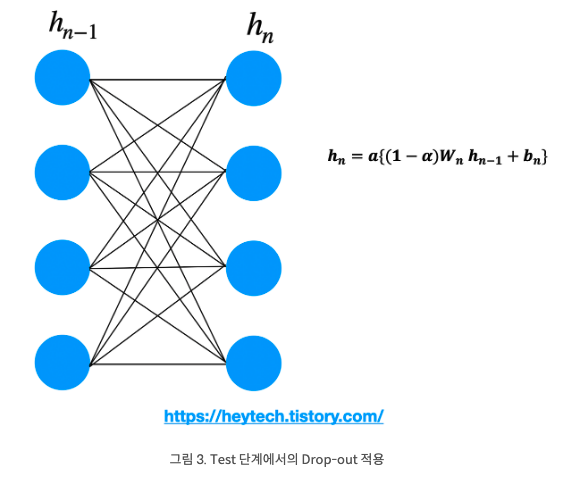
테스트 단계에서는 모든 뉴런에 scaling을 적용하여 동시에 사용한다.
여기서 a: activation function이고, : Drop-out rate를 의미한다. drop-out을 이용해 스케일링을 하는 이유는 같은 출력값을 비교할 때 학습 시 적은 뉴런을 활용했을 때와 여러 뉴런을 활용했을 때와 같은 scale을 갖도록 보정해주기 때문이다.
