그래프(graph)란?
컴퓨터 과학이나 이산수학에서 사용되는 그래프는 다음과 같다.
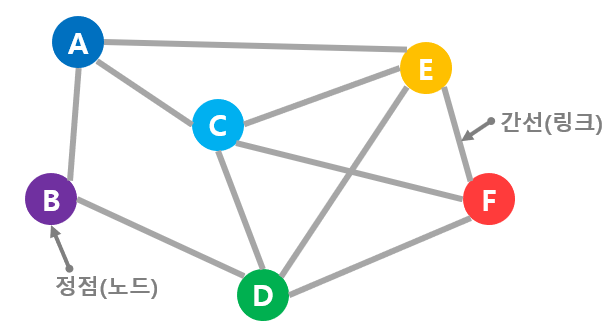
그래프는 정점과 정점이 간선으로 연결된 것이다.
그래프는 다양한 것들을 표현할 수 있다.
세상에 존재하는 다양한 것들을 표현할 수 있어서 편리하다.
예를 들어, 파티를 열었는데 참가자를 정점으로 하고 서로 아는 두 사람을 간선으로 연결하면 파티 참가자간의 관계를 나타내는 그래프가 만들어진다.
또 다른 예로, 역을 정점으로 하고 경로상에 인접해 있는 두 개의 역을 선으로 연결하면 노선도를 나타내는 그래프가 만들어진다.
컴퓨터 네트워크에서 라우터를 정점으로 하고 링크로 연결된 두 개의 라우터를 간선으로 이으면 네트워크 접속 관계를 나타내는 그래프가 만들어진다.
가중 그래프
간선에 부여된 값을 간선의 '가중치' 또는 '코스트(cost)라고 부른다.
이런 그래프를 '가중 그래프(weighted graph)'라고 한다.
간선에 가중치가 없을 때는 두 개의 정점은 '연결돼 있거나','연결돼 있지 않거나' 둘 중 하나지만, 가중치가 있을 때는 '연결(관계)의 정도'를 표현할 수 있다.
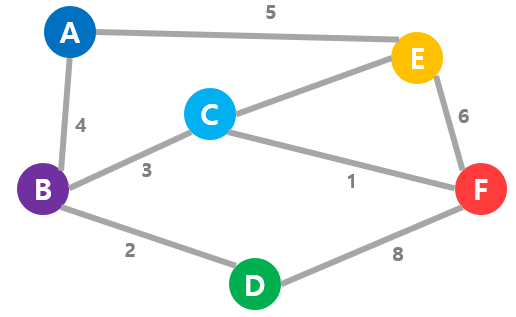
이 '정도'가 무엇을 의미하는 지는 무엇으로 그래프로 표현하는가에 따라 달라진다.
예를 들어, 컴퓨터 네트워크 그래프에서는 간선의 가중치로 네트워크의 통신 시간을 그래프로 표현할 수 있고, 노선도 그래프에서는 두 역간의 운임을 간선의 가중치로 하면 이동에 걸리는 운임을 나타낸 그래프를 얻을 수 있다.
정점에도 가중치가 붙는 경우가 있다.
방향성 그래프
간선에 방향을 부여할 수도 있다. 이런 그래프를 "방향성 그래프(directed graph)"라고 한다.
웹페이지의 링크도 방향성이 있으므로 방향성 그래프로 표현할 수 있다.
반대로, 간선에 방향이 없는 경우는 "비방향성 그래프(undirected graph)"라고 한다.
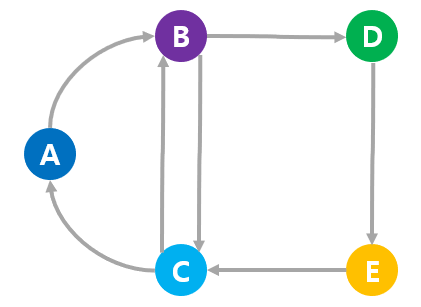
정점 A에서 B로 이동할 수 있지만, B에서 A로 직접 이동할수 없다.
또한 B와 C는 양방향으로 간선이 있으므로 어느 방향이로든 이동할 수 있다.
방향성 그래프에도 비방향성 그래프처럼 간선에 가중치를 부여할 수 있다.
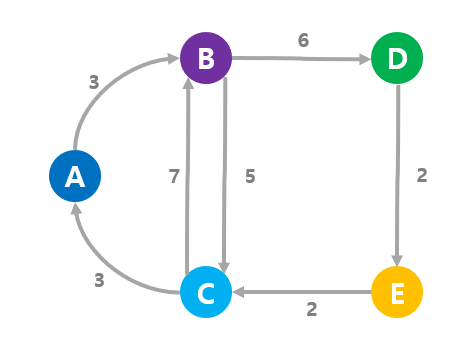
이동시간을 나타내는 그래프를 만드는 경우라면 B가 C보다 높은 곳에 있어서 시간이 더 걸린다는 것을 표현할 수 있다. 이처럼 방향성 그래프를 사용하면 가중치도 표현할 수 있다.
그래프 사용 장점
그래프상에 지정한 두 정점 s와 t를 연결하는 간선들 중 s에서 출발해서 t에 도착할 때까지 가중치 합이 가장 작은 경로를 찾는 알고리즘이 있다고 가정해보면,
이 알고리즘은 컴퓨터 네트워크 상에서 통신시간이 가장 짧은 경로를 찾거나 노선도에서 이동 시간이 가장 짧거나 운임이 가장 싼 경로를 찾을 때 등 다양한 곳에 적용할 수 있다.(실제는 여러 문제를 고려해야하므로 현실과는 차이 있다)
다양한 대상을 그래프라는 하나의 도구로 나타내므로 그래프상의 문제를 해결하는 알고리즘을 찾을 수 있고, 이 알고리즘을 형태가 다른 다양한 문제에 적용할 수 있다.
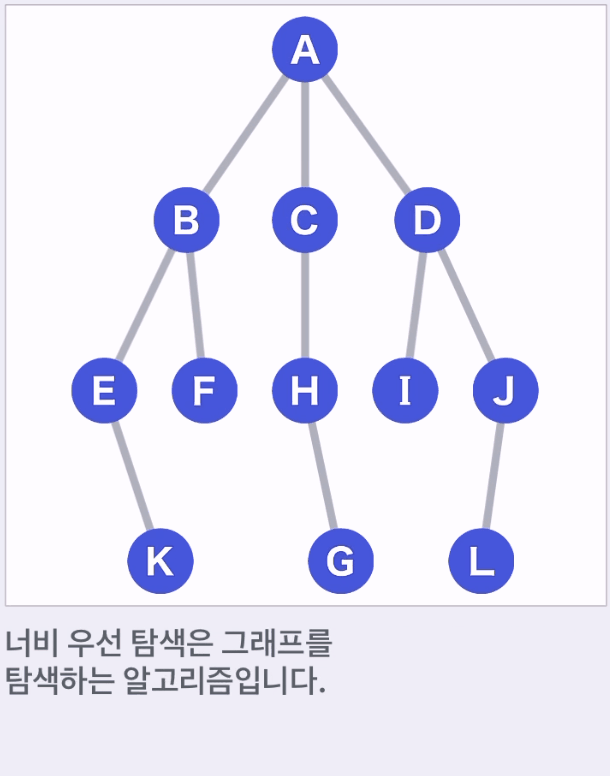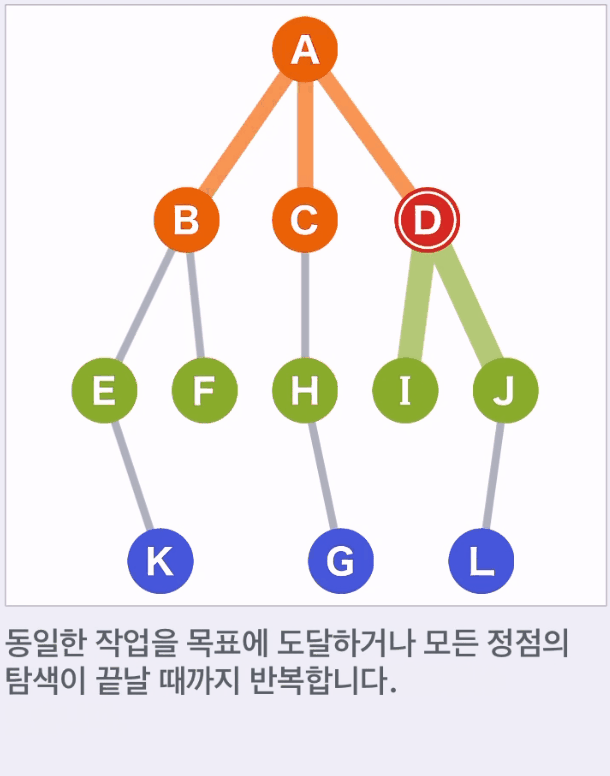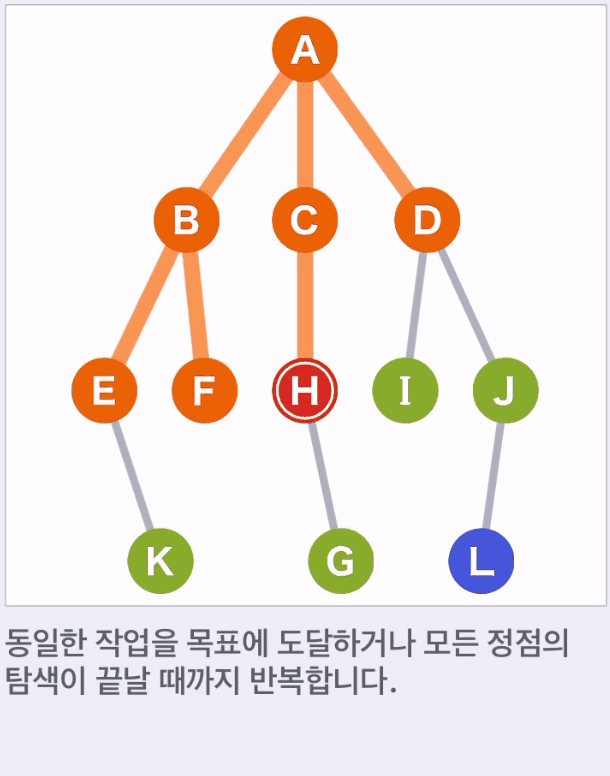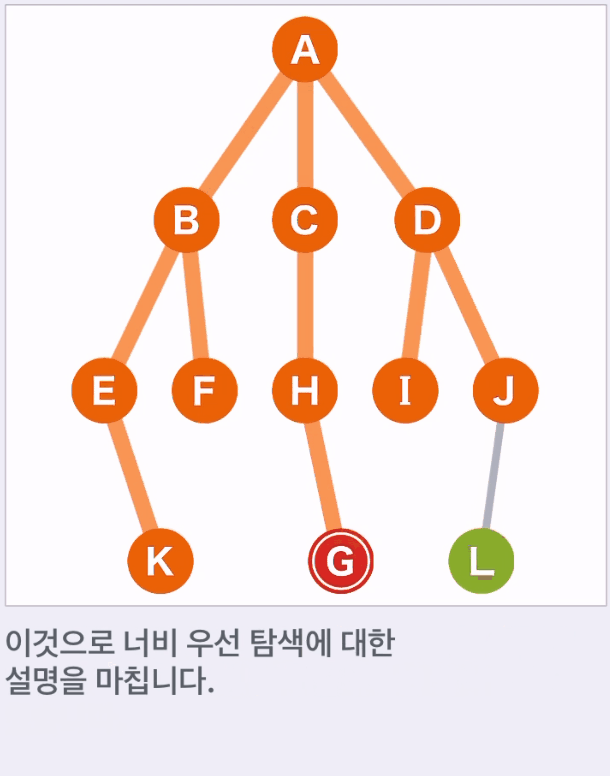
너비 우선 탐색
그래프 탐색 알고리즘
너비 우선 탐색: 정점을 탐색할 때 시작점에 가까운 정점부터 탐색하는 방식
최초 시점에 자신이 특정 정점(시작점)상에 있다. 단, 그래프 전체 구조는 모름.
목적은 시작점에서 간선을 따라가며 정점을 탐색하고 지정한 정점(목표)에 도달하는 것이다.
정점에 도착하면 해당 정점이 목표인지를 판단할 수 있다.
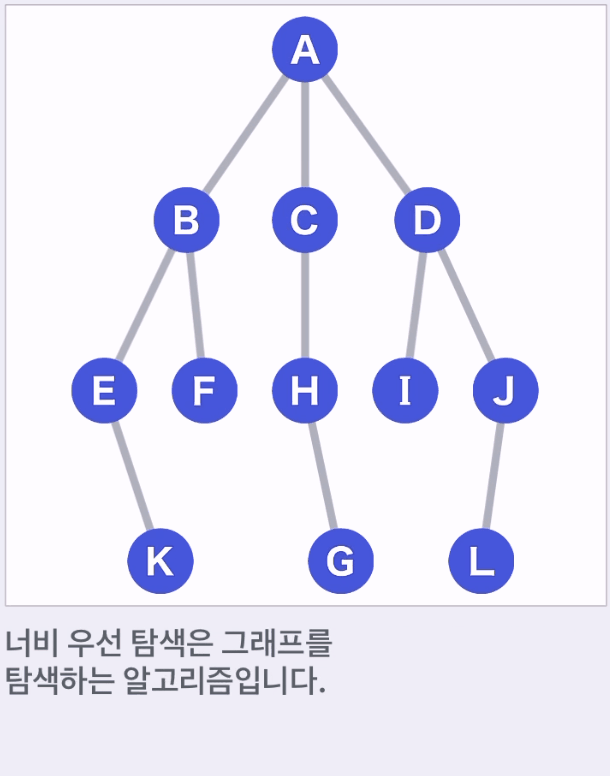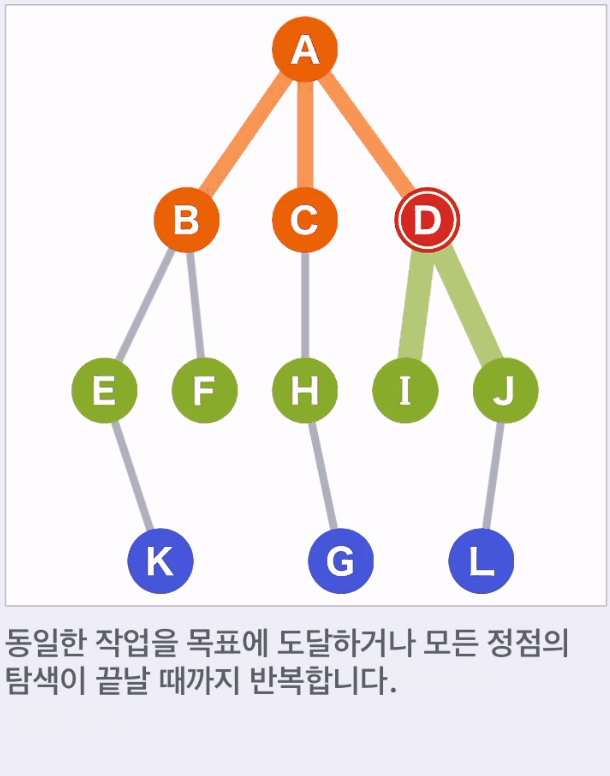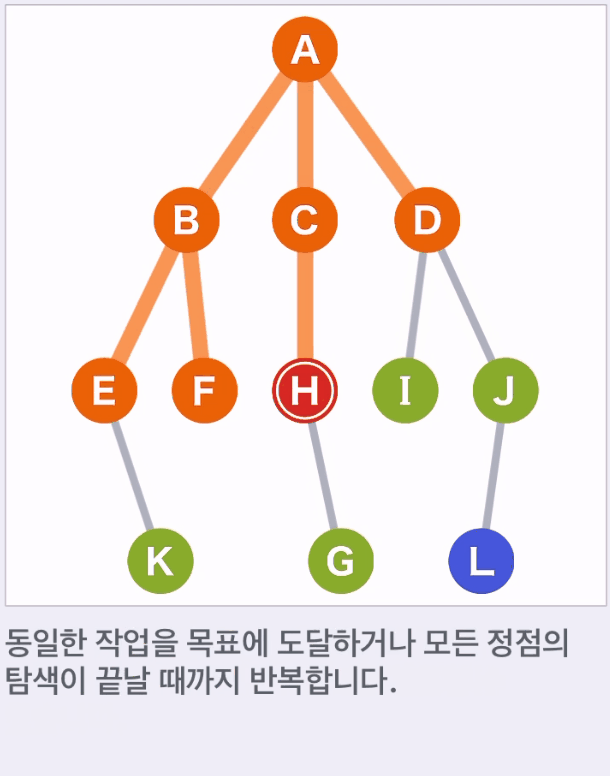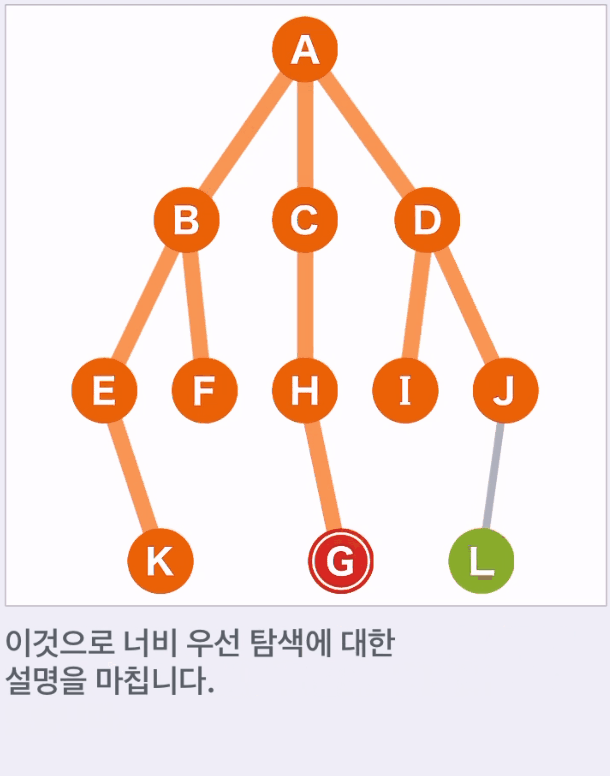
- A를 시작점, G가 목표이고, G가 어디 있는지 모른다
- A에서 도달할 수 있는 정점 B,C,D가 다음 이동 대상 후보가 된다.
- 후보 중 가장 먼저 후보에 추가된 것을 선택한다.
- 후보 정점은 '큐(Queue)' 데이터 구조를 이용할 수 있다.
- 후보에서 도달할 수 있는 다음 새로운 후보를 추가하고 이 중 가장 먼저 후보가 된 것을 선택하며 이동한다.
- 위 예에서는 A,B,C,D,E,F,H,I,J,K 순으로 선택된다.
- 목표 G에 도착하면 탐색을 종료한다.
너비 우선 탐색은 시작점부터 가까운 순으로 너비를 넓혀 가며 탐색하는 방식이다.
목표가 시작점에 가까이 있으면 탐색이 빨리 종료된다.
'트리(tree)'에서도 너비 우선 탐색을 할 수 있다.
깊이 우선 탐색
그래프 탐색 알고리즘
깊이 우선 탐색: 정점을 탐색할 때 하나의 길을 끝까지 따라가며 탐색하는 방식
- A를 시작점, G가 목표이고, G가 어디 있는지 모른다
- A에서 도달할 수 있는 정점 B,C,D가 다음 이동 대상 후보가 된다.
- 후보 중 가장 최근에 추가된 것을 선택한다.
- 후보 정점은 '스택(stack)' 데이터 구조를 이용할 수 있다.
- 후보에서 도달할 수 있는 다음 새로운 후보를 추가하고 이 중 가장 최근에 추가된 후보를 선택하며 이동한다.
- 위 예에서는 A,B,E,K,F,C,H 순으로 선택된다.
- 목표 G에 도착하면 탐색을 종료한다.
깊이 우선 탐색은 하나의 길을 깊이 있게(수직) 찾아가는 방식이다.
너비 우선 탐색과 깊이 우선 탐색의 탐색 순서는 크게 다르지만, 처리상 차이점 하나이다.
후보 정점 중 다음에 어떤 정점을 선택하는가만 다를 뿐이다.
너비 우선 탐색은 가장 먼저 후보가 된 정점을 선택하며 시작점에 가까운 정점이 빨리 후보가 되므로 시작점에 가까운 것부터 탐색한다.
깊이 우선 탐색은 가장 최근에(늦게) 후보가 된 정점을 선택하므로 이 정점을 따라 새로운 길을 찾아나간다.
벨먼-포드(Bellman-Ford) 알고리즘
그래프 최단 경로 문제 해결하기 위한 알고리즘
최단 경로 문제에서는 간선에 가중치가 부여된 '가중 그래프'가 주어지며, '시작점'과 '종점'이 지정된다.
시작점부터 종점까지의 경로 중 간선의 가중치의 합이 가장 작은 것을 구하는 문제
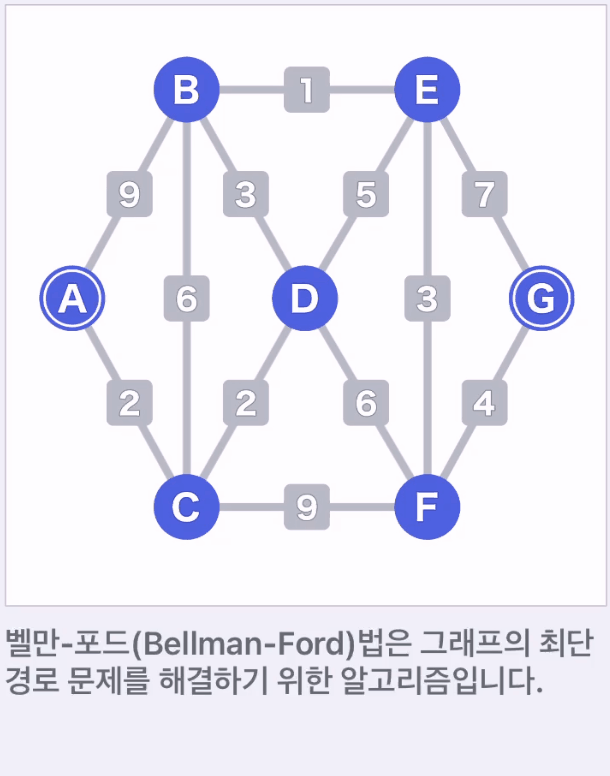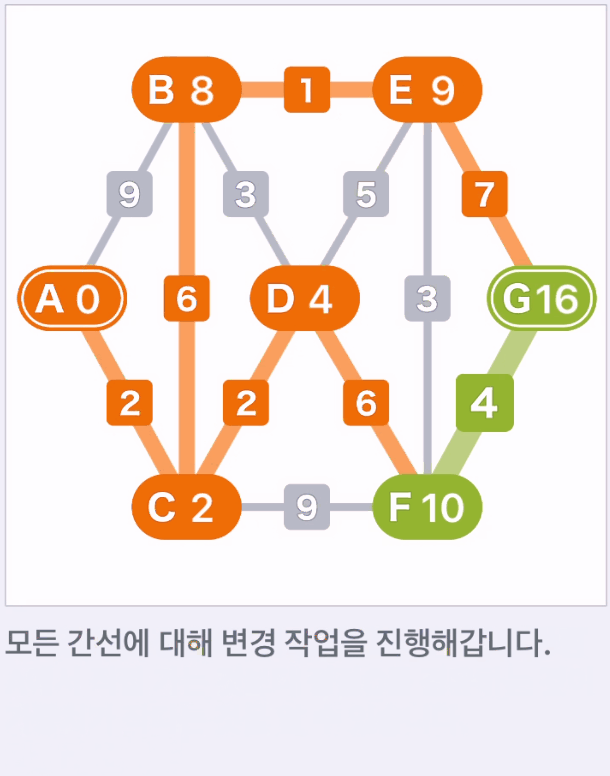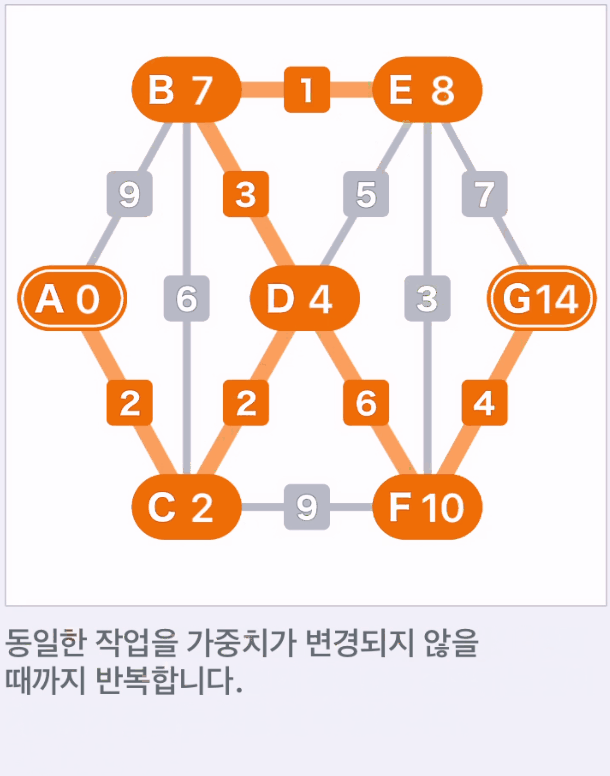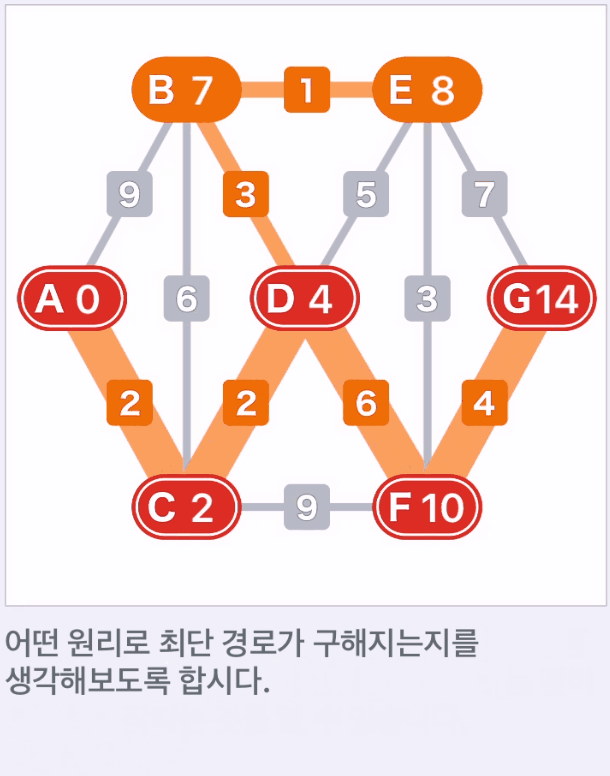
- A를 시작점, G가 종점
- 각 정점의 초기 가중치를 설정한다. 시작점은 0, 그 외의 정점은 무한대()로 설정한다. 이 가중치는 임시 가중치이다.
- 처음에는 언제 도착할 수 있을지 모르므로 무한대로 설정
- 간선을 하나 선택한다. 선택한 간선의 한쪽 정점에서 다른 정점으로 이동하기 위한 가중치를 계산한다. 계산은 한 방향씩 하지만, 어느 쪽을 먼저 하든 상관없다.
- 계산방법 "시간 정점의 가중치 + 간선의 가중치"
- 정점 B보다 A가 현재 가중치가 작으므로 정점 A에서 정점 B로 가는 경우를 먼저 계산한다. 정점 A에서 B로 가는 가중치는 0+9 = 9가 된다.
- 계산한 결과가 현재 값보다 작으면 가중치를 새로운 값으로 변경한다. 정점 B의 현재 값은 무한대로 9가 작다. 따라서 가중치를 9로 변경한다.
- 간선의 가중치가 마이너스가 아닌 이상 현재 값이 더 작은 경우는 가중치를 변경하지 않는다.
- (2)~(4) 작업을 모든 간선에 적용한다. 순서는 임의
- 같은 작업을 가중치가 변경되지 않을 때까지 반복한다.
- 가중치가 변경되지 않는 시점에 알고리즘에 의한 탐색이 완료되며, 시작점에서 모든 정점까지의 최단 경로가 나온다.
- 따라서 탐색에 의해 시작점 A에서 종점 G까지의 최단 경로는 A-C-D-F-G로 가중치 합이 14라는 것을 알 수 있다.
입력 그래프의 정점 수를 n, 간선 수를 m이라고 할 때 계산시간을 알아보면,
벨먼-포드 알고리즘은 가중치 변경 작업을 n회 순회하면 마무리된다.
도한 1라운드의 변경 작업에서는 각 간선을 1회씩 조사하므로 1라운드에 걸리는 계산 시간은 (Om)이 된다.
전체 계산시간 = (Onm)
방향성 그래프의 경우도 최단 경로를 찾을 수 있다.
벨먼-포드 알고리즘에서는 가중치가 음수라도 제대로 동작한다.
단, 간선의 가중치의 합이 음수가 되는 폐로인 경우에는 그 폐로를 계속 순회하면 경로의 가중치를 작게 만들 수 있다.
즉, 정점의 가중치 변경 작업을 n라운드 진행해도 정점의 가중치가 계속 변경되므로 '최단 경로가 존재하지 않는다'는 판단을 할 수 있다.
이 알고리즘의 명칭은 개발자인 Richard E. bellman(리처드 E. 벨먼)과 lestor Ford Junior(레스터 포드 주니어)의 이름에서 가져온 것.
벨먼은 알고리즘 분야의 중요 분야 중 하나인 '동적 계획법'을 고안한 사람이다.
다익스트라(Dijkstra) 알고리즘
그래프의 최단 경로 문제를 해결하기 위한 알고리즘
시작점부터 종점까지의 경로 중 간선의 가중치의 합이 가장 작은 것을 구하는 문제
- A를 시작점, G가 종점
- 각 정점의 초기 임시가중치를 설정한다. 시작점은 0, 그 외의 정점은 무한대로 설정
- 현재 있는 정점에서 갈 수 있는 탐색하지 않은 정점을 찾는다. 발견한 정점은 다음에 진행할 후보로 설정한다.
- 후보인 각 정점의 가중치를 계산한다. 계산한 결과가 현재 가중치보다 작으면 가중치를 새로운 값으로 변경한다.
- 후보 저점 중 가중치가 작은 정점을 선택한다. 그리고 이동한 정점에서 (2)~(3)작업을 종점 G에 도착할 때까지 반복한다.
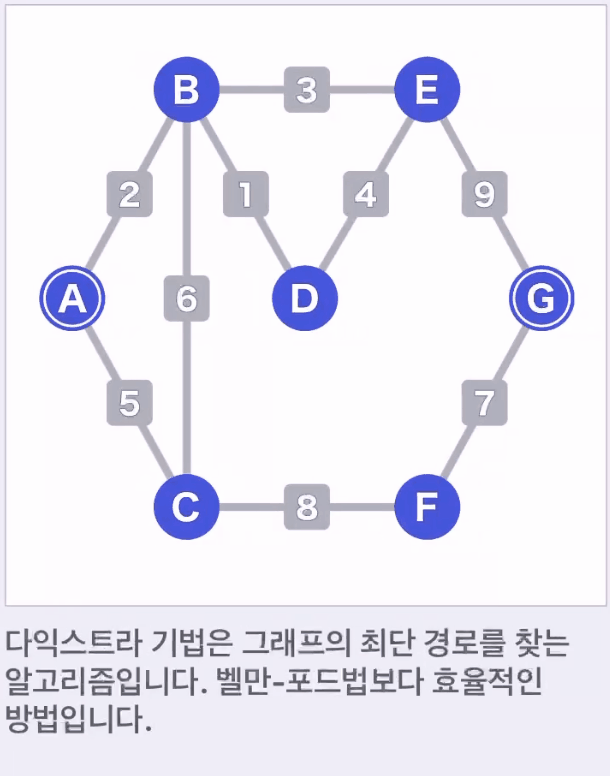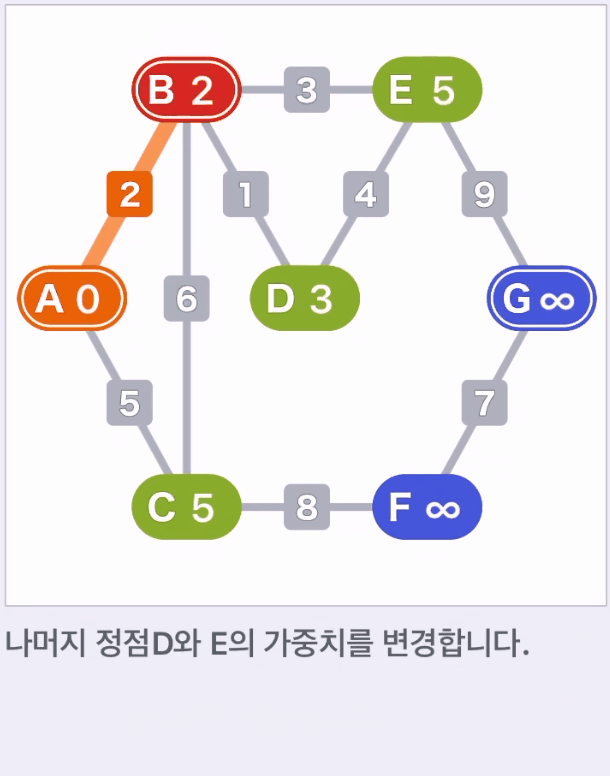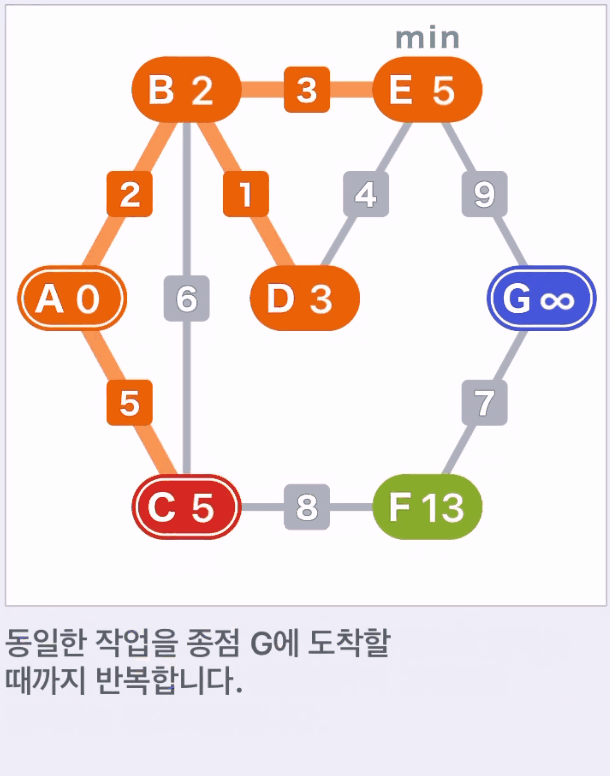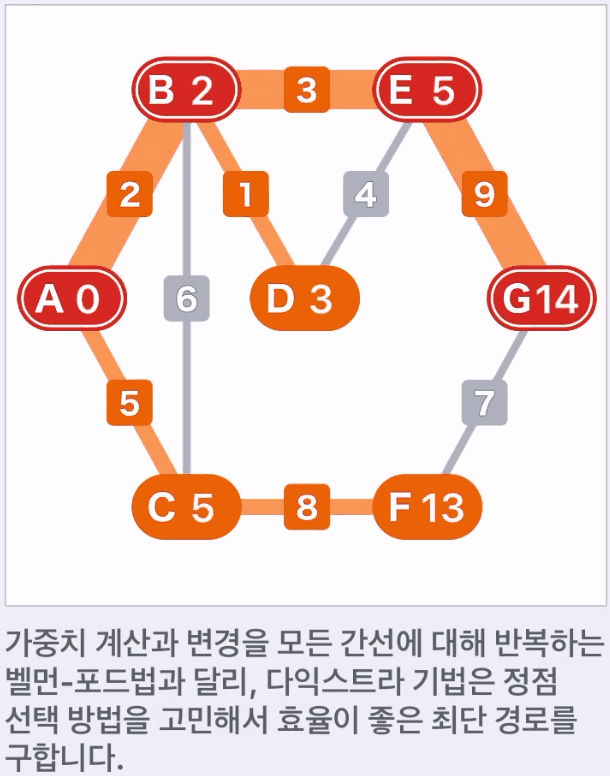
- 다익스트라 알고리즘은 각 정점으로 향하는 최단 경로를 하나씩 정해가며 그래프를 탐색하는 알고리즘이다.
다익스트라 알고리즘은 정점 선택 방법을 고민해서 효율이 좋은 최단 경로를 구한다.
입력 그래프의 정점 수를 n, 간선 수를 m이라고 하면 계산 결과는 아무런 고민을 하지 않은 경우O(n)가 되지만, 데이터 구조를 고민하면 O(m+n log n)이 된다.
다익스트라 알고리즘도 벨먼-포드 알고리즘과 마찬가지로 방향성 그래프를 대상으로 최단 경로를 구할 수 있다.
다만, 마이너스 가중치를 포함하는 그래프에서는 사용할 수 없다.
틀린 최단 경로를 도출할 수 있다는 점 때문이다.
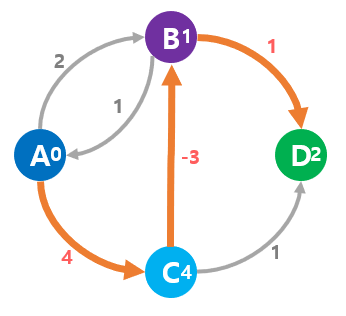
벨먼-포드 알고리즘에서 최단 경로는 A-C-B-G이고, 가중치는 2이다.
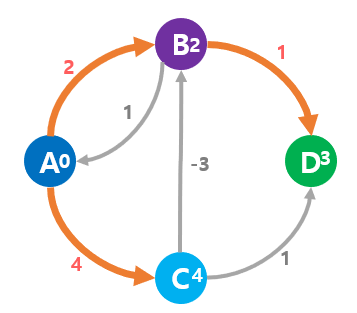
다익스트라 알고리즘을 적용하면 최단 경로는 A-B-G이며, 가중치는 3이라는 결론을 내리고 있다.
실제로 A-C-B로 돌아가는 것이 마이너스 가중치의 영향으로 짧은 경로가 되지만, 다익스트라 알고리즘에서는 C-B 존재를 모르므로 틀린 결과가 나오게 된다.
마이너스 가중치가 존재하지 않는다면 계산 시간이 적은 다익스트라 알고리즘을 사용하는 것이 좋지만 마이너스 가중치가 존재한다면 계산 시간이 오래 걸리더라도 올바른 답을 도출하는 벨먼-포드 알고리즘을 사용하는 것이 좋다.
A*
그래프의 최단 경로를 찾는 알고리즘
'에이 스타'라고 읽는다. 다익스트라 알고리즘을 발전시킨 것이다.
A*는 미리 추정 가중치를 설정해서 불필요한 탐색을 방지하도록 개선한 기법이다.
미로는 각 칸을 정점으로 간주하고 각 정점 사이의 가중치가 1인 그래프라고 해석할수 있다.
다익스트라 알고리즘으로 미로의 최단경로 구하기
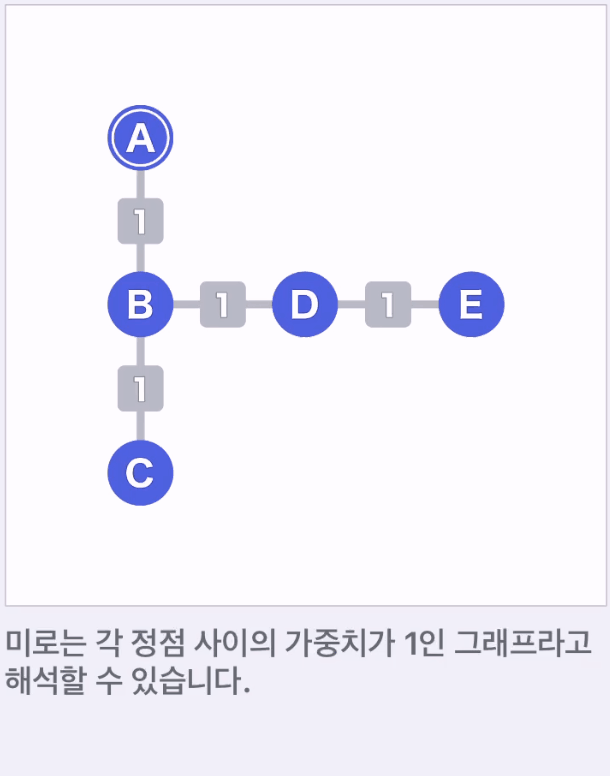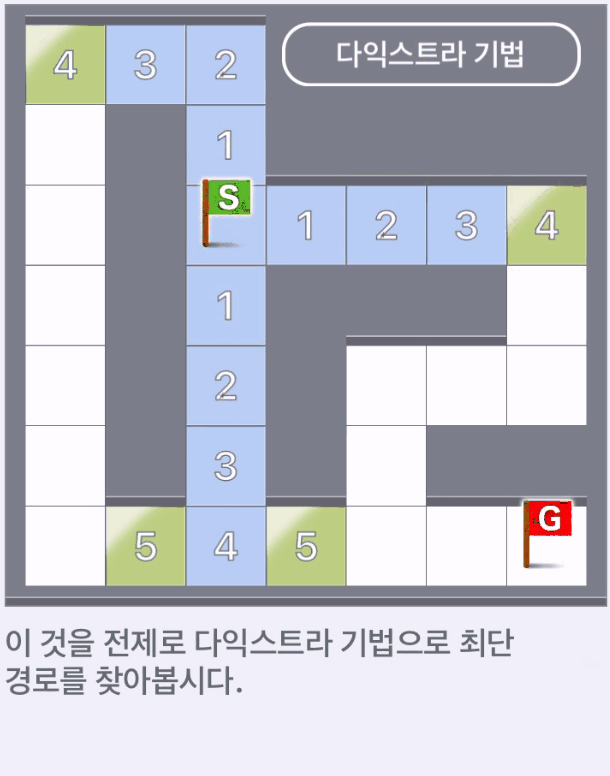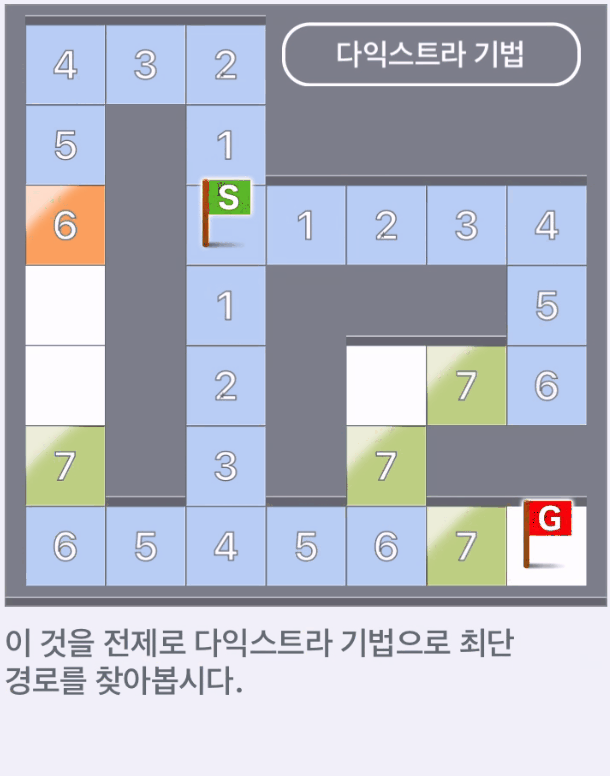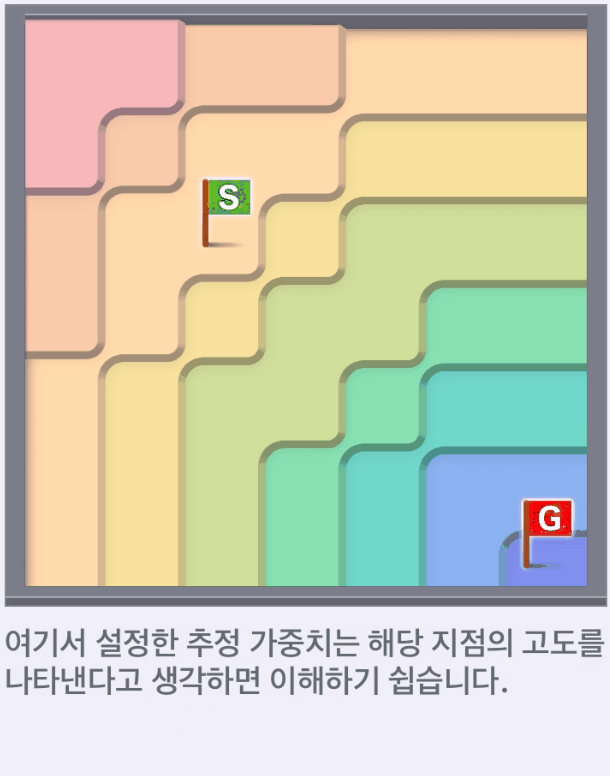
위 그림에서 하늘색과 주황색의 칸은 탐색을 종료한 위치이다.
흰색 칸 이외, 즉 미로의 대부분의 길을 따라가게 된다.
그 중 주황색 칸은 S에서 G까지의 최단 경로이다.
다익스트라 알고리즘에서는 시작점부터의 가중치를 고려해서 다음으로 갈 정점을 결정한다.
목표로부터 멀어지는 것도 고려하지않고 탐색할 수 있다.
이처럼 다익스트라 알고리즘은 각 정점으로 향하는 최단 경로를 하나씩 결정해가며 그래프를 탐색하는 알고리즘이다.
추정치는 자유롭게 설정할 수 있으며, 사람이 미리 설정하는 추정 가중치를 '발견적 가중치(heuristic weight)'라고 한다.
사전 정보를 가지고 최적의 추정 가중치를 설정하고 그것을 힌트로 사용하므로 더 효율적인 탐색이 가능해진다.
왼쪽 아래에 있는 목표로부터 직선 경로를 반올림한 값을 이용해서 A*의 최단경로를 구하는 방법을 알아본다.
A*
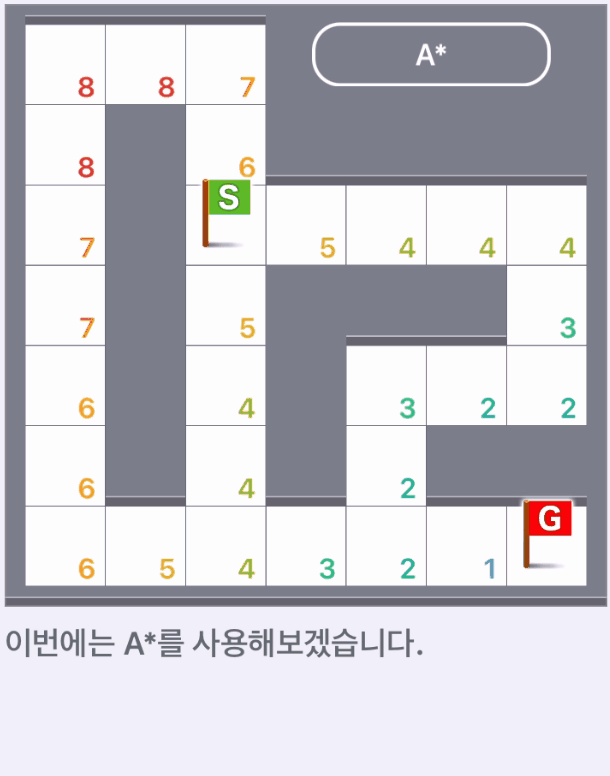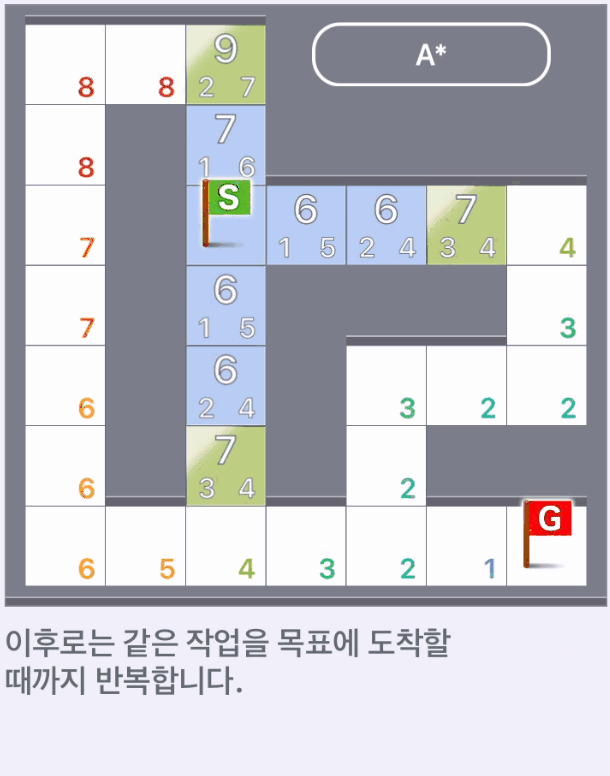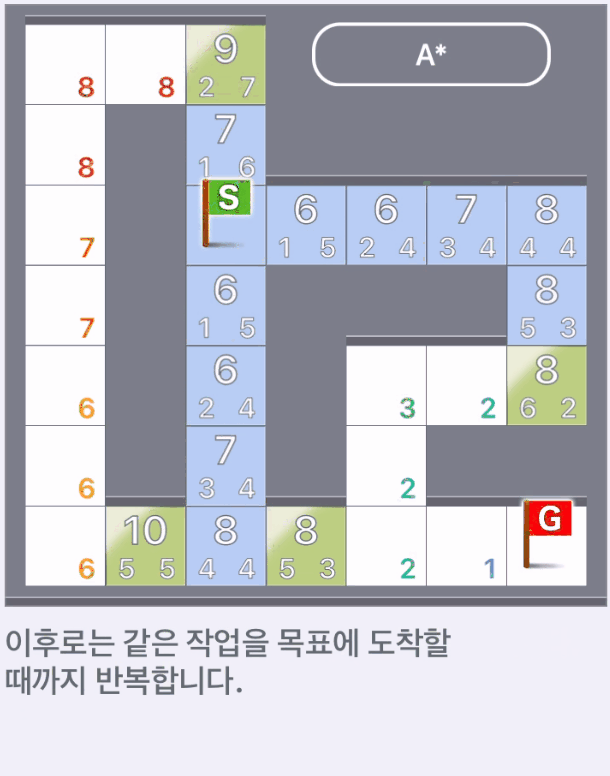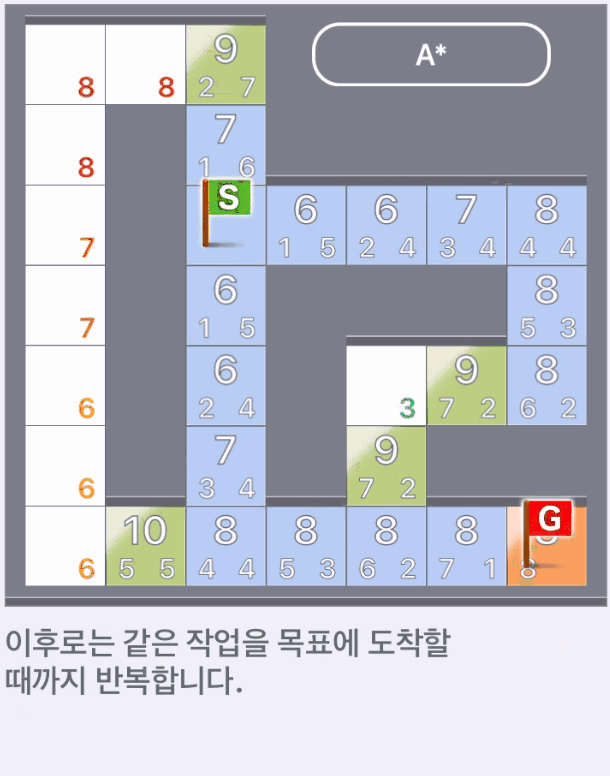
- 먼저 시작 지점을 탐색 완료했고, 시작점으로부터 갈 수 있는 칸의 가중치를 각각 계산한다.
- 가중치는 '해당 위치에 도달할 때까지의 가중치'와 '발견적 가중치'의 합계로 계산한다.
- 가중치가 가장 낮은 칸을 선택하고 선택한 칸은 탐색 완료 상태로 표시한다.
- 탐색 완료 칸에서 갈 수 있는 칸의 가중치를 계산하고 가중치가 가장 낮은 칸을 선택한다.
- 이하, 같은 작업을 목표에 도착할 때까지 반복한다.
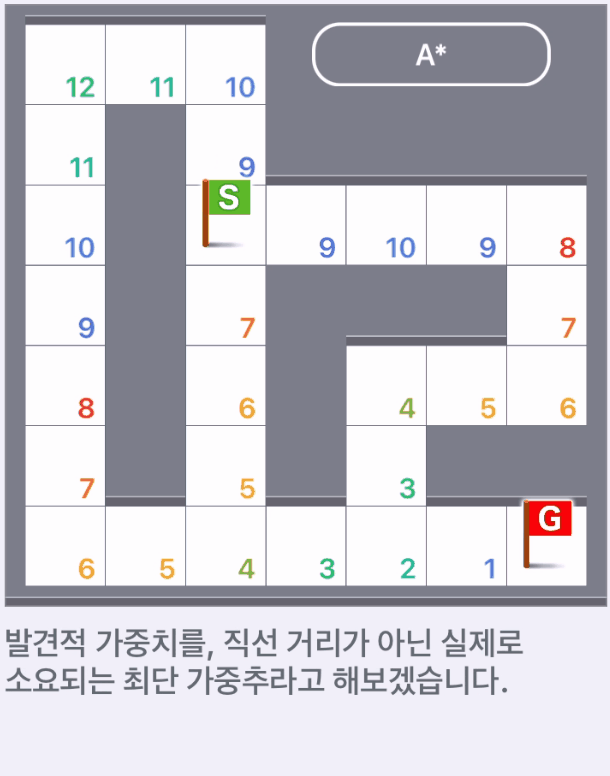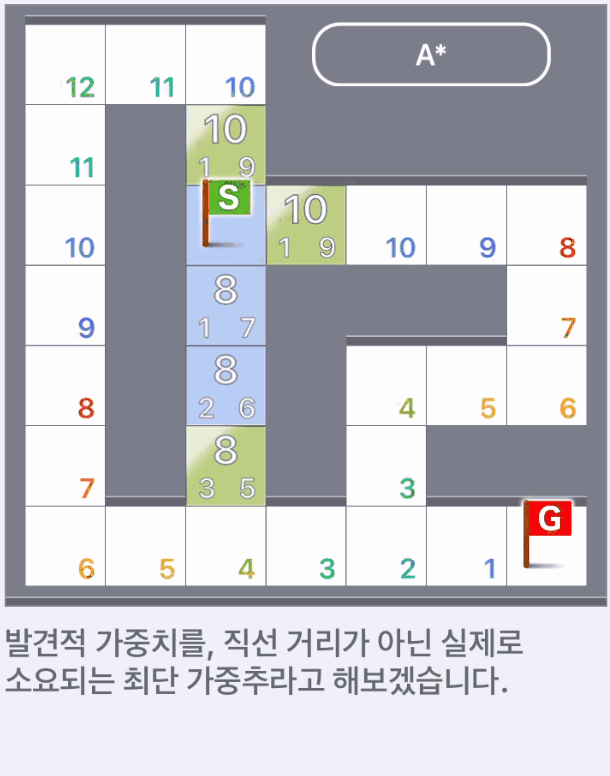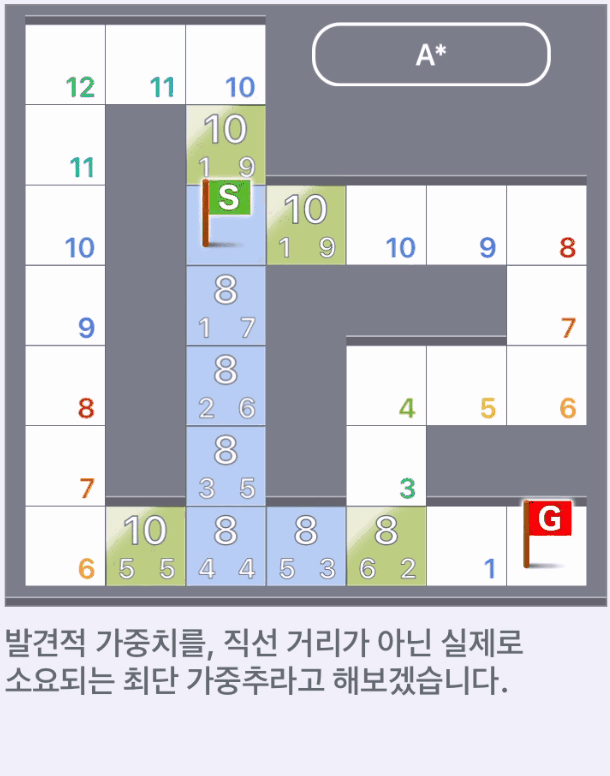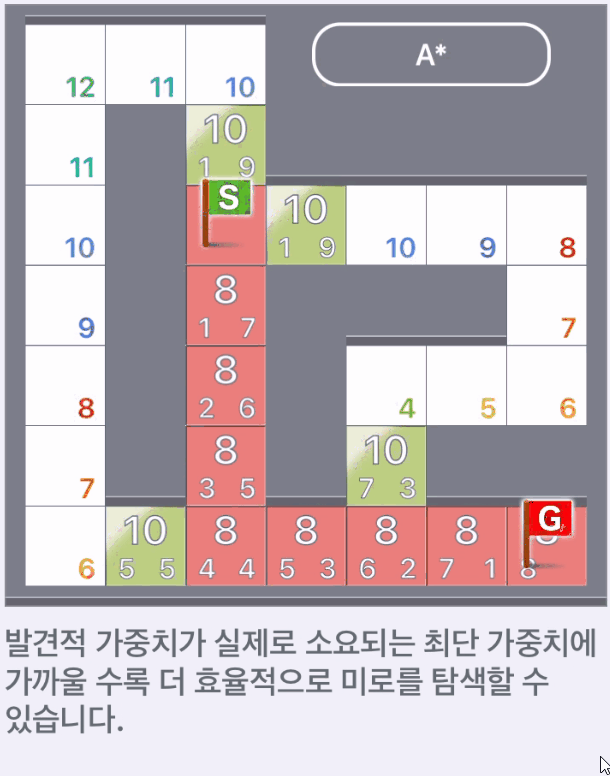
발견적 가중치가 아닌 실제 소요되는 최단 가중추일 때,
현실적으로 실제로 소요되는 최단 가중치를 알고 있는 경우는 탐색할 필요없다.
하지만 위에서 탐색한 것과 다르게 다른 길로 빠지지 않고 최단 경로를 따라 목표에 도착했다.
A*에선 발견적 가중치를 어떻게 설정하는지가 중요한 요소가 된다.
발견적 가중치가 실제 소요되는 최단 가중치에 가까울 수록 더 효율적으로 미로를 탐색할 수 있다.
A*는 다익스트라 알고리즘보다 효율적으로 미로를 탐색할 수 있다.
목표로부터 멀어지는 방향의 칸은 대부분 탐색되지 않는 것을 알 수 있다.
A*는 각 지점에서 목표까지의 거리에 대한 어떤 힌트(정확하지 않아도 됨)를 얻을 수 있는 경우에 유용하다.
물론, 그런 정보가 전혀 없는 상황에서는 A*를 사용할 수 없다.
발견적 가중치는 현재 위치에서 목표까지의 실제 가중치에 가까우면 가까울수록 탐색 효율이 좋아진다. 반대로, 실제 가중치와 동떨어진 가중치를 발견적 가중치로 사용해버리면 다익스트라 알고리즘보다 더 효율이 나빠지는 경우가 있다.
동떨어진 정도가 심한 경우에는 바른 답을 구하지 못할 수도 있다.
참고로 발견적 가중치가 실제 가중치 이하로 설정돼 있으면 바른 답을 찾는 것이 보장된다.
- 활용 예
- A*는 게임 프로그래밍에서 플레이어를 쫓는 적의 움직임을 계산할 때와 같은 경우에 자주 사용되지만 계산량이 많아지므로 게임 전체의 진행 속도에 악영향을 끼칠 수 있으므로 다른 알고리즘과 조합해서 제한적인 상황에 사용하는 등 고민이 필요하다.
Reference
- 『알고리즘 도감』, 이시다 모리테루, 미야자키 쇼이치 - 제이펍
- 『알고리즘 도감』 어플
