Exploratory Data Analysis
탐색적 데이터 분석
데이터셋을 다양한 관점에서 살펴보고 탐색하면서 인사이트를 찾는 것
- 각 row는 무엇을 의미하는가?
- 각 column은 무엇을 의미하는가?
- 각 column은 어떤 분포를 보이는가?
- 두 column은 어떤 연관성이 있는가?
jupyter notebook 에서 실습 진행
문자열 필터링
문자열 boolean 인덱싱이 아니라 단어 필터링
df.str.contains('컬럼') # boolean
df[df.str.contains('컬럼')] # dataframe앞에 글자가 필터링 단어와 일치하는 값만 추출
df[df.str.startswith('컬럼')] # 예제. 박물관이 살아있다 I
한국에서 잘나가는 동양예술전문가 솔희는 최근 “박물관이 살아 있다” 프로젝트를 시작했습니다.
“박물관이 살아 있다” 프로젝트는 점점 떨어져가는 문화예술공간의 방문율을 높이기 위해 시작되었습니다.
김솔희씨는 먼저 예술의 흥행을 위해선 젊은이들의 참여가 시급하다고 판단하여, 대학교 박물관을 먼저 개선하기로 하였습니다.
대학 박물관을 개선하기 위해 다음과 같이 박물관을 분류하기로 하였습니다.
- 박물관은 대학/일반 박물관으로 나뉜다.
- 시설명에 '대학'이 포함되어 있으면 '대학', 그렇지 않으면 '일반'으로 나누어 '분류' column에 입력한다.
'분류' column을 만들어서 솔희를 도와주세요!
import pandas as pd
df = pd.read_csv('data/museum_1.csv')
# 코드를 작성하세요.
# df['분류'] = df[df['시설명'].str_contains('대학')]
is_university = df['시설명'].str.contains('대학')
df.loc[is_university == True, '분류'] = '대학'
df.loc[is_university == False, '분류'] = '일반'
df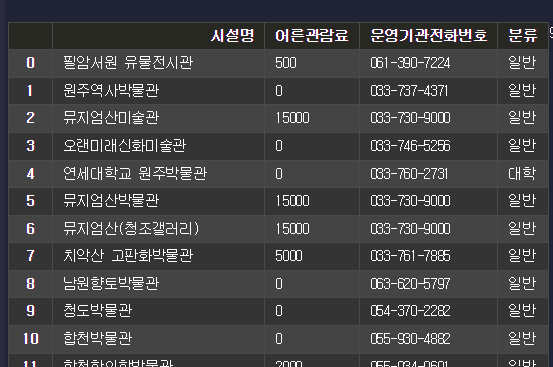
문자열 분리
data.str.split()띄어쓰기 기준으로 단어들을 나눠서 리스트로 만들어준다.
- 파라미터
n=1- 첫번째 공백으로 나뉘어진다.
- 파라미터 `expand=True'
-
새로운 dataframe이 리턴된다.
-
예제. 박물관이 살아있다 II
솔희는 어느 지역에 박물관이 많은지 분석해보려고 합니다.
하지만 주어진 데이터에는 주소가 없네요.
그러던 도중, 전화번호 앞자리가 지역을 나타낸다는 것을 깨달았습니다.
솔희가 박물관의 위치를 파악할 수 있게 '운영기관전화번호' column의 맨 앞 3자리를 추출하고, '지역번호' column에 넣어주세요.
import pandas as pd
df = pd.read_csv('data/museum_2.csv')
# 코드를 작성하세요.
area_num = df['운영기관전화번호'].str.split('-', n=1, expand=True)
df['지역번호'] = area_num[0]
df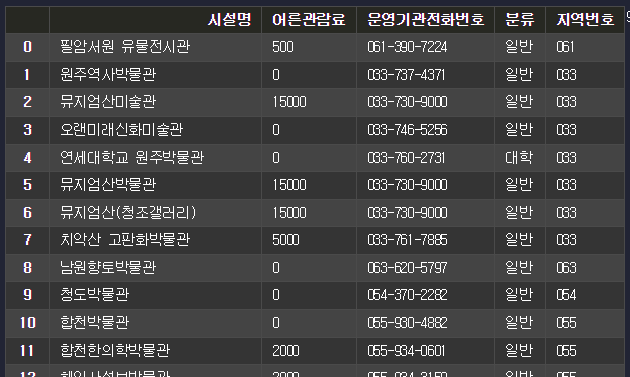
카테고리로 분류
dic = {'a' : '1' , 'b' : '2'}
data.map(dic)- dic의 key에 해당하는 값을 value로 변경
박물관이 살아 있다 III
솔희는 지역번호를 이용해서 지역 정보를 알아내고자 합니다.
지역번호가 02이면 '서울시'이고, 지역번호가 064라면 '제주도'입니다.
'지역번호' column을 '지역명' 으로 변경하고, 아래 규칙에 따라 지역을 넣어주세요.
- 지역명 전화번호
- 서울시 02
- 경기도 031, 032
- 강원도 033
- 충청도 041, 042, 043, 044
- 부산시 051
- 경상도 052, 053, 054, 055
- 전라도 061, 062, 063
- 제주도 064
- 기타 1577, 070
파이썬 사전(dictionary)을 만드는 과정이 번거로울 수 있지만, 실제 분석 상황을 가정한 과제입니다. 직접 작성해 보세요!
숫자로 이루어진 지역번호 column을 String type으로 바꿔주기 위해, read_csv() 메소드에 dtype={'지역번호': str} 옵션을 템플릿에 추가해 두었습니다. 참고하세요.
import pandas as pd
df = pd.read_csv("data/museum_3.csv", dtype={'지역번호': str})
# 코드를 작성하세요.
area = {'02' : '서울시',
'031' : '경기도',
'032' : '경기도',
'033' : '강원도',
'041' : '충청도',
'042' : '충청도',
'043' : '충청도',
'044' : '충청도',
'051' : '부산시',
'052' : '경상도',
'053' : '경상도',
'054' : '경상도',
'055' : '경상도',
'061' : '전라도',
'062' : '전라도',
'063' : '전라도',
'064' : '제주도',
'1577' : '기타',
'070' : '기타',
}
df['지역번호'] = df['지역번호'].map(area)
df.rename(columns={'지역번호' : '지역명'}, inplace=True)
df
group by
df.groupby('컬럼명')
# type = DataFrameGroupBy - sum, mean
- first, last
- 그래프 시각화
예제, 직업 탐구하기 I
직업과 나이, 성별 등에 대한 데이터가 data/occupations.csv에 있습니다.
각 직업의 평균 나이가 궁금한데요.
groupby 문법을 사용해서 '평균 나이'가 어린 순으로 직업을 나열해 보세요.
import pandas as pd
df = pd.read_csv('data/occupations.csv')
# 코드를 작성하세요.
df.groupby('occupation').mean().sort_values(by='age')
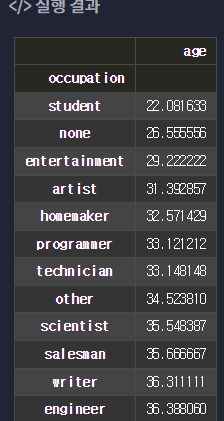
예제, 직업 탐구하기 II
이번에는 여자 비율이 높은 직업과, 남자 비율이 높은 직업이 무엇인지 궁금한데요.
groupby 문법을 사용해서 '여성 비율'이 높은 순으로 직업을 나열해 보세요.
DataFrame이 아닌 Series로, 'gender'에 대한 값만 아래와 같이 출력되어야 합니다.
import pandas as pd
df = pd.read_csv('data/occupations.csv')
occupation_group = df.groupby('occupation')
df.loc[df['gender'] == 'M', 'gender'] = 0
df.loc[df['gender'] == 'F', 'gender'] = 1
occupation_group.mean()['gender'].sort_values(ascending=False)남자가 숫자 0, 여자가 숫자 1이기 때문에, 평균이 0에 가까울 수록 남자가 많고, 1에 가까울 수록 여자가 많다는 뜻.
즉, 평균값이 0.250000이라면 25퍼센트가 여성이고, 75퍼센트가 남성.
데이터 합치기
- inner join
- 두 데이터 중 중복된 값만 병합
- left outer join
- 왼쪽 데이터에 있는 값만 병합
- 오른쪽 데이터에 없으면 NaN으로 표시됨
- right outer join
- 오른쪽 데이터에 있는 값만 병합
- 왼쪽 데이터에 없으면 NaN으로 표시됨
- full outer join
- 양쪽 데이터 모두 병합
- 없는 데이터는 NaN으로 표시됨
# inner join
pd.merge(data1, data2, on='기준열'
# left outer join
pd.merge(data1, data2, on='기준열', how='left')
# right outer join
pd.merge(data1, data2, on='기준열', how='right')
# full outer join
pd.merge(data1, data2, on='기준열', how='outer')예제. 박물관이 살아 있다 IV
파이썬 사전과 .map()을 사용해서 지역명을 알아낸 솔희는, 조금 더 편한 방법을 고민하고 있습니다.
고민하던 중, '지역번호와 지역명에 대한 데이터는 누군가 이미 만들어두지 않았을까'라는 생각을 하게 되는데요.
인터넷에서 지역번호와 지역명이 있는 데이터region_number.csv를 구했습니다!
이 데이터를 먼저 살펴보고,.merge()메소드를 활용해서museum_3.csv에 '지역명' column을 추가해 보세요.
단,museum_3.csv의 박물관 순서가 유지되어야 합니다.
import pandas as pd
museum = pd.read_csv("data/museum_3.csv", dtype={'지역번호': str})
number = pd.read_csv("data/region_number.csv", dtype={'지역번호': str})
# 코드를 작성하세요.
combined = pd.merge(museum, number, on='지역번호', how='left')
combined
- inner join으로 병합시 '지역번호'기준으로 바뀌게되어 순서가 유지되지 않음
museum데이터 순서대로 나열이 되어야 하므로 왼쪽 data기준으로 병합 (how='left')
코드잇에서 무료 수강하며 학습한 내용을 정리한 글입니다.
