시각화
- 시각화는 분석에 도움을 준다
데이터셋이 커지면 커질수록 시각화를 통해 패턴을 찾아낼 수 있다. - 리포팅에 도움이 된다.
이해하기 쉽고, 커뮤니케이션이나
선 그래프
- 수치적 데이터 비교
%matplotlib inline
df.plot()
df.plot(kind='line') # 기본값막대 그래프
- 카테고리 비교
%matplotlib inline
df.plot(kind='bar') # 세로 막대
df.plot(kind='barh') # 가로 막대
df.plot(kind='bar', stacked=True) # 누적막대파이 그래프
- 절대적인 수치보다 비율을 나타냄
%matplotlib inline
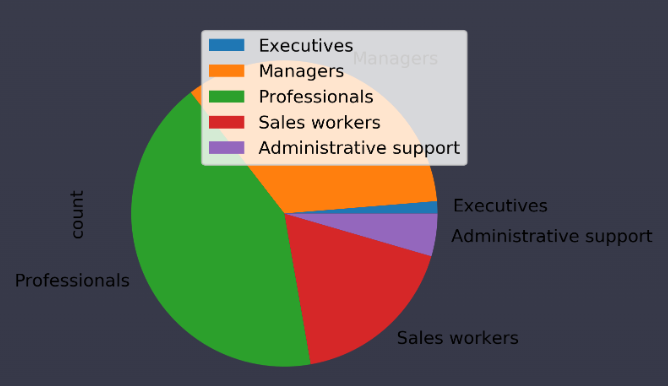
df.plot(kind='pie') 예제. 실리콘 밸리에는 누가 일할까?
이번에는 어도비 (Adobe)의 직원 분포를 한번 살펴봅시다.
어도비 전체 직원들의 직군 분포를 파이 그래프로 그려보세요.
(인원이 0인 직군은 그래프에 표시되지 않아야 합니다.)
%matplotlib inline
import pandas as pd
df = pd.read_csv('data/silicon_valley_details.csv')
# 코드를 작성하세요.
count_zero = df['count'] != 0
adobe = df['company'] == 'Adobe'
all_races = df['race'] == 'Overall_totals'
job_category = (df['job_category'] != 'Totals') & (df['job_category'] != 'Previous_totals')
df_adobe = df[count_zero & adobe & all_races & job_category]
df_adobe.set_index('job_category', inplace=True)
df_adobe.plot(kind='pie', y= 'count')- 'count'가 0인 데이터는 제외
- 회사 'company'는 'Adobe', 인종 'race' 는 'Overall_totals'인 데이터만 추출
- 'job_category'가 'Totals' 혹은 'Previous_totals' 인 데이터도 제외
- 추출한
df_adobe데이터에set_index를 활용해서index변경
히스토그램
- 범위별 분포
%matplotlib inline
df.plot(kind='hist')
df.plot(kind='hist', bins=10) # 범위 설정박스 플롯
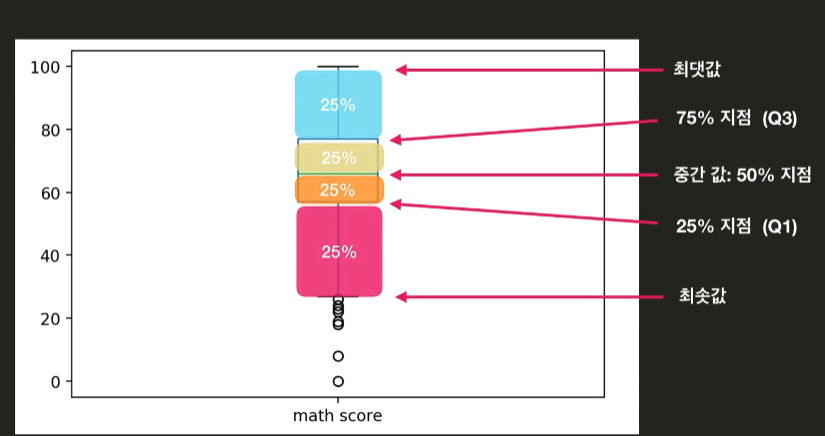
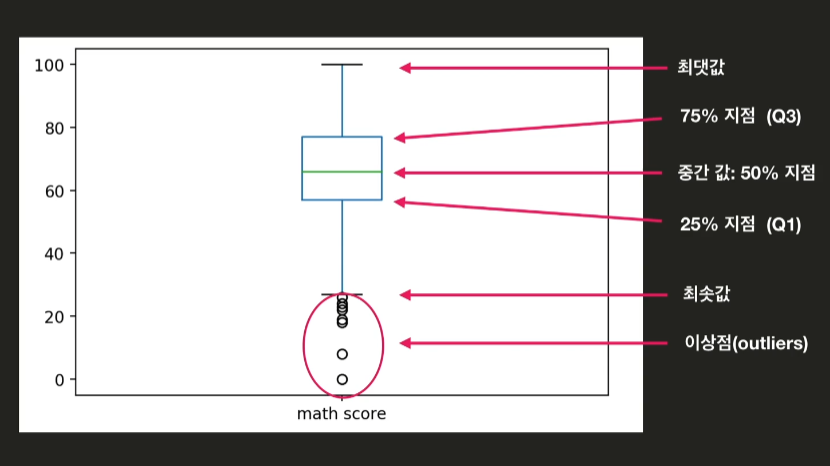
- 통계 정보
%matplotlib inline
df.plot(kind='box') 산점도
- 상관관계
%matplotlib inline
df.plot(kind='scatter') Seaborn
seaborn 라이브러리는 다양한 그래프나 더 근사한 그래프를 그릴 수 있다.
라이브러리 소개를 보면 통계를 기반으로한 시각화로 소개되어있다.
확률 밀도 함수(PDF)
PDF(Probability Density Function) = 확률 밀도 함수
확률 밀도 함수는 데이터셋의 분포를 나타낸다.
특정 구간의 확률은 그래프 아래 그 구간의 면적과 동일하다.
그래프 아래의 모든 면적을 더하면 1이 된다.
KDE Plot
KDE(Kernel Density Estimation)
import seaborn as sns
sns.kdeplot(df)
sns.kdeplot(df, bw=0.5) # 그래프 조절- 히스토그램 위에 KDE 올릴 수 있다.
import seaborn as sns
sns.distplot(df)
sns.distplot(df, bins=15)- 박스플롯
import seaborn as sns
sns.violinplot(y=data)분포 전체를 보여주는 장점이 있다.
- 산점도
import seaborn as sns
sns.kdeplot(data1, data2)등고선처럼 표현할 수 있다.
LM Plot
- 예측
import seaborn as sns
sns.lmplot(data='', x='', y='')카테고리별 시각화
import seaborn as sns
sns.catplot(data='', x='', y='', kind='box')
sns.catplot(data='', x='', y='', kind='violin')
sns.catplot(data='', x='', y='', kind='strip')
sns.catplot(data='', x='', y='', kind='strip', hue='') # 색상
sns.catplot(data='', x='', y='', kind='swarm', hue='') # 점들이 겹쳐있지않고 펼쳐짐통계
평균값
모든 데이터들의 합을 데이터 개수로 나눈 값
중간값
데이터에서 중간에 있는 값
데이터분석에서는 중간값이 더 유용할 수 있다. 평균값은 잘못됐거나 큰 데이터의 값으로 인해 평균값이 크게 달라질 수 있다.
상관계수
상관계수는 데이터에서 두 변수가 얼마나 연관성이 있는지 보여주는 값이다.
상관계수도 여러가지 있는데 널리 쓰이는게 피어슨 상관계수이다.
피어슨은 -1 부터 1까지 값을 가질 수 있다.
DataFrame의 corr() 메소드를 사용하면, 숫자 데이터 사이의 상관 계수를 보여 준다.
%matplotlib inline
import pandas as pd
df = pd.read_csv('data/exam.csv')
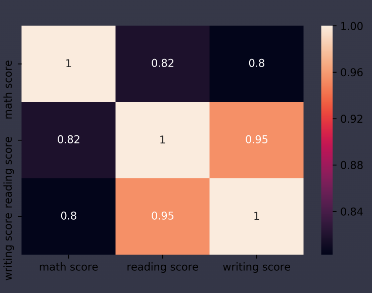
df.corr()상관 계수도 DataFrame 형태로 출력되지만 숫자가 많으면 한눈에 잘 들어오지 않기 때문에 히트맵을 사용한다.
히트맵은 상관 계수를 시각화하는 대표적인 방법이다.
Seaborn을 이용하면 히트맵을 그릴 수 있다.
%matplotlib inline
import pandas as pd
import seaborn as sns
df = pd.read_csv('data/exam.csv')
sns.heatmap(df.corr())
색이 밝을수록 상관 계수가 더 높다는 의미이고,.
읽기 점수(reading score)와 쓰기 점수(writing score) 사이의 상관 관계가 가장 강하다는 것을 알 수 있다.
annot=True 옵션을 추가해주면, 색상 뿐 아니라 숫자도 함께 보여준다.
%matplotlib inline
import pandas as pd
import seaborn as sns
df = pd.read_csv('data/exam.csv')
sns.heatmap(df.corr(), annot=True)