
Mutation-Based Fuzzing
목차
- Synopsis
- Fuzzing with Mutations
- Fuzzing a URL Parser
- Mutating Inputs
- Mutating URLs
- Multiple Mutations
- Guiding by Coverage
- Lessons Learned
- Exercises
- Exercise 1: Fuzzing CGI decode with Mutations
- Exercise 2: Fuzzing bc with Mutations
- Exercise 3
- Exercise 4
- Exercise 5
Synopsis
이번 챕터에서는 이 코드를 사용합니다.
from fuzzingbook.MutationFuzzer import *이 챕터에서는 MutationFuzzer를 소개합니다.
>>> seed_input = "http://www.google.com/search?q=fuzzing"
>>> mutation_fuzzer = MutationFuzzer(seed=[seed_input])
>>> [mutation_fuzzer.fuzz() for i in range(10)]
['http://www.google.com/search?q=fuzzing',
'http://wwBw.google.com/searh?q=fuzzing',
'http8//wswgoRogle.am/secch?qU=fuzzing',
'ittp://www.googLe.com/serch?q=fuzzingZ',
'httP://wgw.google.com/seasch?Q=fuxzanmgY',
'http://www.google.cxcom/search?q=fuzzing',
'hFttp://ww.-g\x7fog+le.com/s%arch?q=f-uzz#ing',
'http://www\x0egoogle.com/seaNrch?q=fuZzing',
'http//www.Ygooge.comsarch?q=fuz~Ijg',
'http8//ww.goog5le.com/sezarc?q=fuzzing']TheMutationCoverageFuzzer
>>> mutation_fuzzer = MutationCoverageFuzzer(seed=[seed_input])
>>> mutation_fuzzer.runs(http_runner, trials=10000)
>>> mutation_fuzzer.population[:5]
['http://www.google.com/search?q=fuzzing',
'http://wwv.oogle>co/search7Eq=fuzing',
'http://wwv\x0eOogleb>co/seakh7Eq\x1d;fuzing',
'http://wwv\x0eoglebkooqeakh7Eq\x1d;fuzing',
'http://wwv\x0eoglekol=oekh7Eq\x1d\x1bf~ing']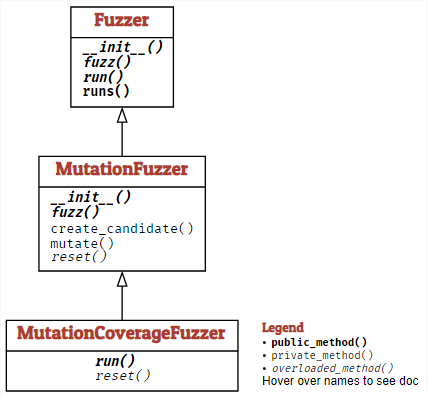
Fuzzing with Mutations
2013년 11월에, American Fuzzy Lop (AFL)의 첫번째 버전이 출시되었습니다. 그 이후로 AFL은 가장 성공적인 퍼징 도구 중 하나가 되었습니다. AFL은 퍼징을 자동 취약점 탐색을 위한 가장 좋은 도구로 만들었습니다. 리얼 월드 애플리케이션에서 대규모 취약점이 자동으로 탐지될 수 있다는 것을 처음으로 증명했습니다.
이 챕터에서는 mutational fuzz testing의 기초를 소개하고, 다음 챕터에서는 특정 코드를 목표로 어떻게 퍼징하는지를 보여줄 것입니다.
Fuzzing a URL Parser
많은 프로그램들은 입력을 처리하기 전에 입력이 매우 구체적인 형식으로 오기를 기대합니다. 예를 들어, URL을 처리하는 프로그램을 생각해보세요. 프로그램이 URL을 처리하기 위해서는 URL 형식에 맞는 입력이 들어 와야합니다.
문제를 더 깊이 이해하기 위해 URL이 무엇으로 구성되어 있는지 살펴보겠습니다. URL은 여러 요소로 구성됩니다.
scheme://netloc/path?query#fragmentscheme은 프로토콜입니다.(http, https, ftp, file ...)netloc은 호스트 이름입니다.(www.google.com)path는 호스트에서의 경로입니다.(search)query는key/value쌍입니다.(q=fuzzing)fragment는 검색된 문서의 위치에 대한 마커입니다.(#result)
파이썬에서는 urlparse() 함수를 사용하여 URL을 구문 분석하고 부분으로 분해할 수 있습니다.
import fuzzingbook.bookutils
from typing import *
from urllib.parse import *result = urlparse("http://www.google.com/search?q=fuzzing")
print(result)ParseResult(scheme='http', netloc='www.google.com', path='/search', params='', query='q=fuzzing', fragment='')이제 URL을 입력으로 사용하는 프로그램이 있다고 가정하겠습니다. 이 프로그램은 URL이 유효하면 True를 반환하고, 그렇지 않으면 예외를 발생시킵니다.
def http_program(url: str) -> bool:
supported_schemes = ["http", "https"]
result = urlparse(url)
if result.scheme not in supported_schemes:
raise ValueError("Scheme must be one of " +
repr(supported_schemes))
if result.netloc == '':
raise ValueError("Host must be non-empty")
# Do something with the URL
return Truehttp_program() 함수를 퍼징해봅시다. 우리는 퍼징할 때 출력 가능한 모든 범위의
아스키코드 문자를 사용할 것입니다.
from fuzzingbook.Fuzzer import fuzzerresult = fuzzer(char_start=32, char_range=96)
print(result)"N&+slk%hyp5o'@[3(rW*M5W]tMFPU4\P@tz%[X?uo\1?b4T;1bDeYtHx #UJ5w}pMmPodJM,_1000개의 랜덤한 입력값으로 퍼징을 해봅시다.
for i in range(1000):
try:
url = fuzzer()
result = http_program(url)
print("Success!")
except ValueError:
pass실제로 유효한 URL을 얻을 가능성은 얼마나 될까요? 먼저 "http://" 사례를 들어보겠습니다. "http://" 는 매우 구체적인 7개의 문자로 이루어져 있습니다. 이 7개의 문자를 무작위로 생성할 확률은 1:96⁷ 입니다.
기본적인 퍼징을 하면 urlparse()의 기능을 잘 테스트할 수 있습니다. 하지만 유효한 입력을 만들어내지 못하면, 내부 기능을 테스트할 수 없습니다.
Mutating Inputs
랜덤 문자열을 생성하는 것의 대안으로 주어진 유효한 입력을 시작으로 그 값을 계속 변형시키는 것입니다. 이 컨텍스트에서 변형은 간단한 문자열 조작입니다. 예를 들어 (랜덤) 문자를 삽입하거나, 문자를 삭제하거나, 문자의 비트를 뒤집습니다.
이것은 mutational fuzzing이라고 합니다.
다음은 몇 가지 mutation입니다.
import randomdef delete_random_character(s: str) -> str:
"""Returns s with a random character deleted"""
if s == "":
return s
pos = random.randint(0, len(s) - 1)
# print("Deleting", repr(s[pos]), "at", pos)
return s[:pos] + s[pos + 1:]seed_input = "A quick brown fox"
for i in range(10):
x = delete_random_character(seed_input)
print(repr(x))' quick brown fox'
'A quick bron fox'
'Aquick brown fox'
'A uick brown fox'
'Aquick brown fox'
'A quik brown fox'
'Aquick brown fox'
'A quick rown fox'
'A quick brown ox'
'A quck brown fox'def insert_random_character(s: str) -> str:
"""Returns s with a random character inserted"""
pos = random.randint(0, len(s))
random_character = chr(random.randrange(32, 127))
# print("Inserting", repr(random_character), "at", pos)
return s[:pos] + random_character + s[pos:]for i in range(10):
print(repr(insert_random_character(seed_input)))'NA quick brown fox'
'A+ quick brown fox'
'Ah quick brown fox'
'A quiock brown fox'
'A@ quick brown fox'
'A quick brown 3fox'
'A rquick brown fox'
'A quick brown* fox'
'A quick bro5wn fox'
'A quick brown] fox'def flip_random_character(s):
"""Returns s with a random bit flipped in a random position"""
if s == "":
return s
pos = random.randint(0, len(s) - 1)
c = s[pos]
bit = 1 << random.randint(0, 6)
new_c = chr(ord(c) ^ bit)
# print("Flipping", bit, "in", repr(c) + ", giving", repr(new_c))
return s[:pos] + new_c + s[pos + 1:]for i in range(10):
print(repr(flip_random_character(seed_input)))'E quick brown fox'
'A!quick brown fox'
'A0quick brown fox'
'A quisk brown fox'
'A$quick brown fox'
'A quick brown dox'
'A Quick brown fox'
'A quick brown!fox'
'A quick broun fox'
'A quick brown(fox'이제 적용할 mutation을 무작위로 선택하는 random mutator를 만들어봅시다.
def mutate(s: str) -> str:
"""Return s with a random mutation applied"""
mutators = [
delete_random_character,
insert_random_character,
flip_random_character
]
mutator = random.choice(mutators)
# print(mutator)
return mutator(s)for i in range(10):
print(repr(mutate("A quick brown fox")))'E quick brown fox'
'A uick brown fox'
'A0quick brown fox'
'A quisk brown fox'
'A quick rown fox'
'A qu(ick brown fox'
'A quick brown!fox'
'A quiWck brown fox'
'A quick broFwn fox'
'A quick brown4 fox'mutation fuzzing의 아이디어는 초기값으로 넣을 수 있는 유효한 입력이 있다면 위의 mutation중 하나를 적용하여 더 많은 유효한 입력 값을 만들 수 있다는 것입니다.
Mutating URLs
URL 파싱 문제로 돌아가 보겠습니다. http_program() 함수가 입력을 처리할 수 있는지 없는지 체크하기 위해서 is_valid_url() 함수를 만들어봅시다.
def is_valid_url(url: str) -> bool:
try:
result = http_program(url)
return True
except ValueError:
return Falseassert is_valid_url("http://www.google.com/search?q=fuzzing")
assert not is_valid_url("xyzzy")이제 주어진 URL에 mutate() 함수를 적용하여 유효한 입력을 얼마나 얻었는지 알아보겠습니다.
seed_input = "http://www.google.com/search?q=fuzzing"
valid_inputs = set()
trials = 20
for i in range(trials):
inp = mutate(seed_input)
if is_valid_url(inp):
valid_inputs.add(inp)우리는 이제 원래의 입력을 변형시켜서 높은 비율의 유효한 입력을 얻을 수 있음을 관찰할 수 있습니다.
result = len(valid_inputs) / trials
print(result)0.8http: 가 시드인 입력을 변형시켰을 때 https: 를 생성할 확률이 얼마나 될까요?
trials = 3 * 96 * len(seed_input)
print(trials)1094410944번 값을 생성해야 합니다.
from fuzzingbook.Timer import Timertrials = 0
with Timer() as t:
while True:
trials += 1
inp = mutate(seed_input)
if inp.startswith("https://"):
print(
"Success after",
trials,
"trials in",
t.elapsed_time(),
"seconds")
breakSuccess after 18395 trials in 0.03750379999837605 seconds만약, 우리가 "ftp://" 로 시작하는 URL을 얻고 싶다면, 훨씬 더 많은 값을 생성해야 합니다. 그러나 가장 중요한 것은, multiple mutations를 적용해야 한다는 것입니다.
Multiple Mutations
지금까지, 우리는 샘플 문자열에 한번의 mutation만 적용했습니다. 하지만 이 문자열에 여러번의 mutation을 적용한다면 훨씬 더 큰 변화를 줄 수 있습니다. 예를 들어, 샘플 문자열에 20번의 mutations을 적용해보면?
seed_input = "http://www.google.com/search?q=fuzzing"
mutations = 50inp = seed_input
for i in range(mutations):
if i % 5 == 0:
print(i, "mutations:", repr(inp))
inp = mutate(inp)0 mutations: 'http://www.google.com/search?q=fuzzing'
5 mutations: 'hpdp:/www.wooglecom/search?q=fuzzing'
10 mutations: 'hpdp:/www(W.wooglecom/Fsea4rch>q=fuzzing'
15 mutations: 'hplp:/www(W.woouglecom/Fs@ea4rah>=fuzzing'
20 mutations: 'hlp:/ww(W.woouglesoxm/Fs@a4rah>=fuzzing'
25 mutations: 'hl%p:/ww(W.woouglesoxm5,?Fs@a4rah>=fuzzindg'
30 mutations: 'hl%p:ww(W.woougl~esoxm5,?FsD`4rah>=fuzzind9g'
35 mutations: 'hl%p:ww(W.o/Pgl~esoxm5,?FsD`4rah>=fuzind9g'
40 mutations: 'hlp:ww(W.o/Pgl~esoxm5<?FsD`4ah<fuzind9g'
45 mutations: 'xlp:ww(W.o/Pgl~esoxm5?BsD`4ah<fuznd9!g'보시다시피, 원래 시드 입력값은 더 이상 찾기 힘듭니다. 우리는 입력을 계속해서 변형시킴으로써, 더 높은 입력의 다양성을 얻을 수 있습니다.
단일 패키지에서 이러한 여러 mutations을 구현하기 위해 MutationFuzzer 클래스를 소개합니다. 입력 시드, 최대 및 최소 mutations 수가 필요합니다.
from fuzzingbook.Fuzzing import Fuzzerclass MutationFuzzer(Fuzzer):
"""Base class for mutational fuzzing"""
def __init__(self, seed: List[str],
min_mutations: int = 2,
max_mutations: int = 10) -> None:
"""Constructor.
`seed` - a list of (input) strings to mutate.
`min_mutations` - the minimum number of mutations to apply.
`max_mutations` - the maximum number of mutations to apply.
"""
self.seed = seed
self.min_mutations = min_mutations
self.max_mutations = max_mutations
self.reset()
def reset(self) -> None:
"""Set population to initial seed.
To be overloaded in subclasses."""
self.population = self.seed
self.seed_index = 0다음은 MutationFuzer에 더 많은 방법을 추가하여 MutationFuzer를 추가로 개발합니다. Python 언어는 모든 메소드를 포함하는 전체 클래스를 하나의 연속적인 단위로 정의해야 합니다. 하지만 우리는 메소드를 하나씩 차례로 소개하고 싶습니다. 이 문제를 방지하기 위해 특별한 트릭을 사용합니다: 우리가 몇몇의 class C에 새로운 메서드를 추가하고 싶을 때마다, 우리는 생성자를 사용합니다.
class C(C):
def new_method(self, args):
pass이것은 C 그 자체를 하위 클래스로 정의하는 것처럼 보입니다. 하지만 실제로는 새로운 C 클래스를 이전 C 클래스의 하위 클래스로 도입한 다음 이전 C 클래스의 정의를 가립니다. 이렇게 하면 new_method()를 메서드로 사용하는 C 클래스를 얻을 수 있습니다. 이것이 바로 우리가 원하는 것입니다.
이 트릭을 사용해서 우리는 위의 mutate() 메서드를 실제로 호출하는 mutate() 메서드를 추가할 수 있습니다. 나중에 MutationFuzzer를 확장하고 싶을때, mutation() 메서드를 갖는 것이 유용할 수 있습니다.
class MutationFuzzer(MutationFuzzer):
def mutate(self, inp: str) -> str:
return mutate(inp)다시 우리의 전략으로 돌아가서, 커버리지의 다양성을 극대화해 보겠습니다. 먼저 create_candidate() 메서드를 생성합니다. 이 메서드는 현재 모집단에서 임의로 입력을 선택한 다음 min_mutations 와 max_mutations 사이의 mutations을 적용하여 최종 결과를 반환합니다.
class MutationFuzzer(MutationFuzzer):
def create_candidate(self) -> str:
"""Create a new candidate by mutating a population member"""
candidate = random.choice(self.population)
trials = random.randint(self.min_mutations, self.max_mutations)
for i in range(trials):
candidate = self.mutate(candidate)
return candidatefuzz() 메서드는 먼저 시드를 선택하도록 되어 있고 시드가 사라지면 무작위 값을 생성합니다.
class MutationFuzzer(MutationFuzzer):
def fuzz(self) -> str:
if self.seed_index < len(self.seed):
# Still seeding
self.inp = self.seed[self.seed_index]
self.seed_index += 1
else:
# Mutating
self.inp = self.create_candidate()
return self.inp여기에 fuzz() 메서드가 있습니다. fuzz() 의 새로운 호출이 있을 때마다, 우리는 여러 mutation이 적용된 또 다른 변형을 얻습니다.
seed_input = "http://www.google.com/search?q=fuzzing"
mutation_fuzzer = MutationFuzzer(seed=[seed_input])
result = mutation_fuzzer.fuzz()
print(result)http://www.google.com/search?q=fuzzingresult = mutation_fuzzer.fuzz()
print(result)htdp:/www(W.wooglecom/search>q=fuzzingresult = mutation_fuzzer.fuzz()
print(result)ht|p://www.googulte.com/seUarcj?=uzzing그러나 입력의 다양성이 높을수록 잘못된 입력을 가질 위험이 증가합니다. 성공의 열쇠는 이러한 mutation을 가이드하는 아이디어입니다. 즉 가치 있는 변이 값을 유지하는 것에 있습니다.
Guiding by Coverage
가능한 한 많은 기능을 다루려면 "Coverage" 장에서 설명한 대로 지정된 기능이나 구현된 기능 중 하나에 의존할 수 있습니다. 현재로서는 프로그램 동작에 대한 세부 명세가 있다고 가정하지는 않을 것입니다(물론 있으면 좋을 것입니다!). 그러나 우리는 테스트할 프로그램이 존재하고 그 구조를 활용하여 테스트 생성을 가이드할 수 있다고 가정할 것입니다.
테스트는 항상 프로그램을 실행하므로 항상 실행에 대한 정보를 수집할 수 있습니다. 최소한의 정보는 테스트의 통과 또는 실패를 결정하는데 필요합니다. 커버리지는 테스트 품질을 결정하기 위해 측정되는 경우가 많기 때문에, 테스트 실행의 커버리지도 검색할 수 있다고 가정합니다. 문제는 다음과 같습니다: 커버리지를 활용하여 테스트 생성을 가이드하는 방법은 무엇입니까?
한 가지 성공적인 아이디어는 American Fuzzy lop, 줄여서 AFL라는 인기 있는 퍼저에서 구현됩니다. 위의 예와 마찬가지로 AFL은 성공적인 테스트 케이스를 발전시킵니다. 그러나 AFL의 경우 "성공"은 프로그램 실행을 통해 새로운 경로를 찾는 것을 의미합니다. 이러한 방식으로 AFL은 지금까지 새로운 경로를 찾은 입력을 계속 변환할 수 있으며, 입력이 다른 경로를 찾으면 해당 입력도 유지됩니다.
전략을 세워보겠습니다. 우리는 주어진 함수에 대한 커버리지를 캡처하는 FunctionRunner 클래스를 소개하는 것으로 시작합니다. 첫째, FunctionRunner 클래스:
from fuzzingbook.Fuzzer import Runnerclass FunctionRunner(Runner):
def __init__(self, function: Callable) -> None:
"""Initialize. `function` is a function to be executed"""
self.function = function
def run_function(self, inp: str) -> Any:
return self.function(inp)
def run(self, inp: str) -> Tuple[Any, str]:
try:
result = self.run_function(inp)
outcome = self.PASS
except Exception:
result = None
outcome = self.FAIL
return result, outcomehttp_runner = FunctionRunner(http_program)
result = http_runner.run("https://foo.bar/")
print(result)(True, 'PASS')이제 FunctionRunner 클래스를 확장하여 커버리지도 측정할 수 있습니다. run()을 호출한 후 coverage() 메서드는 마지막 실행에서 흭득한 coverage를 반환합니다.
from fuzzingbook.Coverage import Coverage, population_coverage, Locationclass FunctionCoverageRunner(FunctionRunner):
def run_function(self, inp: str) -> Any:
with Coverage() as cov:
try:
result = super().run_function(inp)
except Exception as exc:
self._coverage = cov.coverage()
raise exc
self._coverage = cov.coverage()
return result
def coverage(self) -> Set[Location]:
return self._coveragehttp_runner = FunctionCoverageRunner(http_program)
result = http_runner.run("https://foo.bar/")
print(result)(True, 'PASS')다음은 처음 5개 커버된 위치입니다:
print(list(http_runner.coverage())[:5])[('urlsplit', 465), ('urlsplit', 471), ('_checknetloc', 414), ('urlsplit', 480), ('urlsplit', 477)]이제 메인 수업을 시작하겠습니다. 우리는 모집단과 이미 흭득한 커버리지 세트를 유지합니다(coverage_seeen). fuzz() helper 함수는 입력을 받아 주어진 function() 을 실행합니다. 커버리지가 새로운 경우 (예: coverages+seen에 없음), 입력은 population 에 추가되고 커버리지는 coverage_seeen 에 추가됩니다.
class MutationCoverageFuzzer(MutationFuzzer):
"""Fuzz with mutated inputs based on coverage"""
def reset(self) -> None:
super().reset()
self.coverages_seen: Set[frozenset] = set()
# Now empty; we fill this with seed in the first fuzz runs
self.population = []
def run(self, runner: FunctionCoverageRunner) -> Any:
"""Run function(inp) while tracking coverage.
If we reach new coverage,
add inp to population and its coverage to population_coverage
"""
result, outcome = super().run(runner)
new_coverage = frozenset(runner.coverage())
if outcome == Runner.PASS and new_coverage not in self.coverages_seen:
# We have new coverage
self.population.append(self.inp)
self.coverages_seen.add(new_coverage)
return result이제 이 기능을 사용해 보겠습니다:
seed_input = "http://www.google.com/search?q=fuzzing"
mutation_fuzzer = MutationCoverageFuzzer(seed=[seed_input])
mutation_fuzzer.runs(http_runner, trials=10000)
result = mutation_fuzzer.population
print(result)['http://www.google.com/search?q=fuzzing',
'http://www.gIoogle.com/sarch>q=fuzzing',
'http://swww.og|e.com/searh&ch?u=fu#zzing',
'http://wwwP.google.com/sear#h?q=fuzzing*',
'http://www.gIoaogle.cm3ar7ch>qV=fuzzing',
'http://\x7fwww*og|e.com/searh&chu=Fuzzange;',
'http://swww.og|e.koomq/{earh&ch;u=fu#zzilg',
'http://swIww.og|e.kio/mq/{earh&ch;u=fie?#Zzilg',
'http://s\x7fIw7.og|e.kkn/jmBqkearh&ch;u=fie?Zzilg',
'http://swIw&wf.og|e8.kio/mq/{eah&ch;u=fie/#Zzilg',
'http://swIw%&wog|e8.kio/mq/{ah&Och;u=fie/Zzilg']성공! 우리의 모집단에서, 이제 각각의 모든 입력은 유효하고 다양한 schemes, paths, querys 및 fragment 조합에서 나오는 서로 다른 커버리지를 가지고 있습니다.
all_coverage, cumulative_coverage = population_coverage(
mutation_fuzzer.population, http_program)import matplotlib.pyplot as pltplt.plot(cumulative_coverage)
plt.title('Coverage of urlparse() with random inputs')
plt.xlabel('# of inputs')
plt.ylabel('lines covered');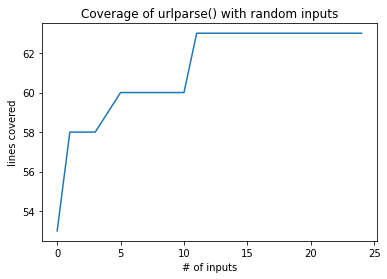
이 전략의 좋은 점은 더 큰 프로그램에 적용하면 하나의 경로를 차례로 탐색합니다. 필요한 것은 커버리지를 포착할 수 있는 수단뿐입니다.
Lessons Learned
- 무작위로 생성된 입력은 종종 유효한 값이 아닙니다.
- 유효한 값을 변형시킨 값은 훨씬 더 유효한 값일 가능성이 높습니다.
[ The Fuzzing Book ]
Mutation-Based Fuzzing
