
Fuzzing with Grammars
목차
- Synopsis
- Input Languages
- Grammars
- Representing Grammars in Python
- Some Definitions
- A Simple Grammar Fuzzer
- Visualizing Grammars as Railroad Diagrams
- Some Grammars
- Grammars as Mutation Seeds
- A Grammar Toolbox
- Checking Grammars
- Lessons Learned
Synopsis
이 챕터에서 제공된 코드를 사용하기 위해서, 코드에 추가하세요
>>> from fuzzingbook.Grammars import <identifier>그리고 다음 기능을 사용하세요.
이 챕터는 입력 언어를 구체화하고 구문적으로 유효한 입력이 있는(정해진 입력 형식이 있는) 프로그램을 테스트하기 위한 간단한 방법으로 문법을 소개합니다. 문법은 다음과 같이 비단말 기호를 alternative expansions 리스트에 매핑하는 것으로 정의됩니다.
>>> US_PHONE_GRAMMAR: Grammar = {
>>> "<start>": ["<phone-number>"],
>>> "<phone-number>": ["(<area>)<exchange>-<line>"],
>>> "<area>": ["<lead-digit><digit><digit>"],
>>> "<exchange>": ["<lead-digit><digit><digit>"],
>>> "<line>": ["<digit><digit><digit><digit>"],
>>> "<lead-digit>": ["2", "3", "4", "5", "6", "7", "8", "9"],
>>> "<digit>": ["0", "1", "2", "3", "4", "5", "6", "7", "8", "9"]
>>> }
>>>
>>> assert is_valid_grammar(US_PHONE_GRAMMAR)-
비단말 기호는 < >로 묶습니다. (Ex. <digit>)
-
문법에서 입력 문자열을 생성하기 위해서 생산자는 시작 기호(<start>)로 시작하고 이 기호에 대해 랜덤 확장을 선택합니다.
(<start>로 시작해서 <phone-number>, (<area>)<exchange>-<line>, ...., 062-530-3421 까지 확장을 해가며 입력값을 생성) -
모든 비단말 기호가 확장될 때 까지 위 과정은 계속됩니다.
(모든 비단말자 기호가 숫자로 바껴서 숫자로 된 전화번호가 나올때 까지 계속 확장합니다.) -
simple_grammar_fuzzer() 함수는 다음을 수행합니다.
>>> [simple_grammar_fuzzer(US_PHONE_GRAMMAR) for i in range(5)]
['(692)449-5179',
'(519)230-7422',
'(613)761-0853',
'(979)881-3858',
'(810)914-5475']그러나 실제로는 simple_grammar_fuzzer() 대신 GrammarFuzzer 클래스 또는 coverage 기반, probabilistic 기반 generator 기반 프로그램중 하나를 사용해야 합니다.
이러한 기능은 보다 효율적이고 무한 확장으로 부터 보호되며 몇 가지 추가 기능을 제공합니다.
이챕터는 또한 Character 클래스와 반복, 또는 확장 문법 등을 쉽게 쓰기 위한 도우미 함수인 grammar toolbox를 소개합니다.
Input Languages
프로그램의 모든 가능한 동작은 입력에 의해 트리거될 수 있습니다. 여기서 입력은 다양한 이용 가능한 자원이 될 수 있습니다: 즉 파일, 환경 또는 네트워크를 통해 읽는 데이터, 사용자가 입력한 데이터 또는 다른 리소스와의 상호 작용에서 얻은 데이터가 될 수 있습니다. 이러한 모든 입력은 실패를 포함하여 어떻게 프로그램이 동작할지 결정합니다. 따라서 테스트할 때 가능한 입력 소스, 어떻게 입력을 제어할지, 어떻게 체계적으로 테스트할지 생각하는 것은 매우 유용합니다.
단순하게 하기 위해서, 지금 프로그램에 입력 소스가 한개만 있다고 가정합시다. 이 가정은 우리가 전 챕터에서 했던 것입니다. 프로그램에서 유효한 입력 집합을 언어라고 합니다. 언어는 단순한 것부터 복잡한 것까지 다양합니다: CSV 언어는 쉼표로 구분된 유효한 입력 집합을 나타내는 반면에 파이썬 언어는 유효한 파이썬 프로그램 집합을 나타냅니다. 우리는 일반적으로 데이터 언어와 프로그래밍 언어를 분리하지만 어떤 프로그램도 입력 데이터(예: 컴파일러)로 취급할 수 있습니다.
언어를 형식적으로 설명하기 위해서 형식 언어 분야에서는 언어를 설명하는 여러 언어 세부 사항을 고안했습니다. 예를 들어 정규 표현식 [a-z]*는 소문자의 (비어 있을 수 있음) 시퀀스를 나타냅니다. 오토마타 이론은 이러한 언어를 이러한 입력을 처리하는 오토마타와 연결합니다. 예를 들어 유한 상태 기계는 정규 표현식의 언어를 지정하는 데 사용할 수 있습니다.
정규식은 그다지 복잡하지 않은 입력 형식에 적합하며 연결된 유한 상태 기계에는 추론하기에 좋은 많은 속성이 있습니다. 그러나 더 복잡한 입력을 구체화할 때 빠르게 한계에 부딪힙니다. 언어 스펙트럼의 반대편에는 튜링 머신이 허용하는 언어를 나타내는 보편 문법이 있습니다. 튜링 머신은 계산할 수 있는 모든 것을 계산할 수 있습니다. 파이썬이 튜링 완전하기 때문에 파이썬 프로그램을 사용하여 정상적인 입력을 구체화하거나 열거할 수도 있습니다.
그러나 때때로 테스트할 프로그램 별로 테스트 프로그램을 직접 작성해야 할 수도 있습니다.
Grammars
정규 표현식과 튜링 머신 사이의 중간 지점은 문법으로 다룹니다. 문법은 입력 언어를 구체화하는 가장 인기 있고 가장 잘 이해되는 형식 중 하나입니다. 문법을 사용하여 입력 언어의 광범위한 속성을 표현할 수 있습니다. 문법은 특히 입력 구문 구조를 표현하는 데 유용하며 반복 또는 재귀 입력을 표현하기 위해서 선택하는 형식입니다. 우리가 사용하는 문법은 가장 쉽고 대중적인 문법 형식 중 하나인 문맥 자유 문법입니다.
Rules and Expansions
문법은 시작 기호와 시작 기호(및 기타 기호)를 확장할 수 있는 방법을 나타내는 확장 규칙(또는 단순히 규칙) 세트로 구성됩니다. 예를 들어, 두 자리 숫자의 시퀀스를 나타내는 다음 문법을 고려하세요.
<start> ::= <digit><digit>
<digit> ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9이 문법을 읽으려면 시작기호(<start>)로 시작하세요. 확장규칙 <A> ::= <B>는 왼쪽에 있는 기호 (<A>)를 오른쪽에 있는 문자열(<B>)로 대체할 수 있습니다. 위의 문법에서, <start>는 <digit><digit>로 대체됩니다.
이 문자열에서 <digit>은 다시 <digit> 규칙 오른쪽에 있는 문자열로 변경됩니다. 특수 연산자 | 는 또는 이라는 의미로 확장을 위해 임의의 숫자를 선택할 수 있습니다. 따라서 각 <digit>은 주어진 숫자 중 하나로 확장되어 결국 0~9 사이의 문자열이 됩니다. 0 부터 9까지는 더 이상 확장하지 않기 때문에 우리는 모든 준비가 되었습니다.
문법에 대한 흥미러운 점은 그것들이 재귀적일 수 있다는 것입니다. 즉 확장을 통해 더 먼저 확장한 기호를 사용할 수 있으며, 그 후 다시 확장됩니다. 예를 들어 정수를 기술하는 문법을 생각해봅시다.
<start> ::= <integer>
<integer> ::= <digit> | <digit><integer>
<digit> ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9여기서 <integer>는 한 자리수이거나 다른 정수 뒤에 오는 숫자입니다. 따라서 숫자 1234는 하나의 숫자 1에 이어 정수 234가 따라오고 숫자 2에 이어 정수 34가 따라옵니다.
만약 정수가 + 또는 - 기호를 가질수 있기를 바란다면 문법을 다음과 같이 작성할 수 있습니다.
<start> ::= <number>
<number> ::= <integer> | +<integer> | -<integer>
<integer> ::= <digit> | <digit><integer>
<digit> ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9이 규칙들은 공식적으로 언어를 정의합니다: 시작 기호에서 파생될 수 있는 모든 것은 언어의 일부이고, 그렇지 않은 것은 언어의 일부가 아닙니다.
Quiz
다음중 <start>기호로 부터 생성할 수 없는 문자열은 무엇입니까?
- 007
- -42
- ++1
- 3.14
Arithmetic Expressions
문법을 확장하여 산술식을 다뤄봅시다. 우리는 식(<expr>)이 <term> + <term> 또는 <term> - <term> 또는 <term>중 하나임을 알 수 있습니다. <term>은 <term> <factor> 또는 <term> / <factor> 또는 <factor> 중 하나 입니다. 그리고 <factor>는 숫자 또는 괄호로 묶인 식입니다. 거의 모든 규칙이 재귀성을 가질 수 있으므로 (1 + 2) (3.4 / 5.6 - 789)와 같은 임의의 복잡한 식을 허용합니다.
<start> ::= <expr>
<expr> ::= <term> + <expr> | <term> - <expr> | <term>
<term> ::= <term> * <factor> | <term> / <factor> | <factor>
<factor> ::= +<factor> | -<factor> | (<expr>) | <integer> | <integer>.<integer>
<integer> ::= <digit><integer> | <digit>
<digit> ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9이 문법에서, <start>로 시작해서 무작위로 선택을 하며 하나의 기호를 차례대로 확장해나가면, 우리는 빠르게 하나의 유효한 산술식을 만들어낼 수 있습니다. 이러한 grammar fuzzing은 복잡한 입력을 생성하기 때문에 매우 효과적이며, 이 grammar fuzzing은 이번장에서 구현될 것입니다.
Quiz
다음중 <start>기호로 부터 생성할 수 없는 문자열은 무엇입니까?
- 1 + 1
- 1+1
- +1
- +(1)
Representing Grammars in Python
grammar fuzzer를 만드는 첫번째 단계는 문법에 적합한 형식을 찾는 것입니다. 문법을 최대한 간단하게 쓰기 위해 문자열과 리스트를 기반으로 하는 형식을 사용합니다. 파이썬에서 우리의 문법은 기호 이름과 확장 사이의 매핑 형식을 취하며, 여기서 확장은 alternative list에 대한 것입니다. 따라서 숫자에 대한 단일 규칙 문법은 다음과 같은 형태를 취합니다.
DIGIT_GRAMMAR = {
"<start>":
["0", "1", "2", "3", "4", "5", "6", "7", "8", "9"]
}A Grammar Type
문법 타입을 정적으로 확인할 수 있도록 문법의 타입을 정의해 봅시다.
문법 타입 정의의 첫 번재 시도는 각 기호(문자열)를 expansions(문자열) 리스트에 매핑하는 것입니다.
SimpleGrammar = Dict[str, List[str]]그러나 옵션 속성을 추가하기 위한 opts() 기능은 또한 문자열과 옵션으로 구성된 쌍으로 확장될 수 있게 합니다. 여기서 옵션은 문자열과 값으로 매핑됩니다.
Option = Dict[str, Any]따라서 확장자는 문자열 또는 문자열과 옵션의 쌍입니다.
Expansion = Union[str, Tuple[str, Option]]이를 통해 Expansion 리스트에 대한 문자열 매핑으로 문법을 정의할 수 있습니다.
각 기호는(문자열) Expansion(문자열) 리스트에 매핑되는 문법 유형을 확인할 수 있습니다.
Grammar = Dict[str, List[Expansion]]이 문법 타입에서 산술식에 대한 전체 문법은 다음과 같습니다.
EXPR_GRAMMAR: Grammar = {
"<start>":
["<expr>"],
"<expr>":
["<term> + <expr>", "<term> - <expr>", "<term>"],
"<term>":
["<factor> * <term>", "<factor> / <term>", "<factor>"],
"<factor>":
["+<factor>",
"-<factor>",
"(<expr>)",
"<integer>.<integer>",
"<integer>"],
"<integer>":
["<digit><integer>", "<digit>"],
"<digit>":
["0", "1", "2", "3", "4", "5", "6", "7", "8", "9"]
}문법에서, 모든 기호는 정확하게 한번 정의되어 질 수 있습니다. 어떤 규칙이든 기호로 접근할 수 있습니다.
EXPR_GRAMMAR["<digit>"]['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']... 문법에 기호가 있는지 확인할 수 있습니다.
<identifier>" in EXPR_GRAMMARFalse규칙의 왼쪽(즉, 매핑 키)은 항상 단일 기호라고 가정합니다. 이것은 문법에 문맥 자유 특성을 부여하는 속성입니다.
Some Definitions
우리는 표준 시작 기호가 <start>라고 가정합니다.
START_SYMBOL = "<start>"편리한 nonterminals() 함수는 expansion에서 비단말 기호를 추출합니다.
import reRE_NONTERMINAL = re.compile(r'(<[^<> ]*>)')def nonterminals(expansion):
# In later chapters, we allow expansions to be tuples,
# with the expansion being the first element
if isinstance(expansion, tuple):
expansion = expansion[0]
return RE_NONTERMINAL.findall(expansion)assert nonterminals("<term> * <factor>") == ["<term>", "<factor>"]
assert nonterminals("<digit><integer>") == ["<digit>", "<integer>"]
assert nonterminals("1 < 3 > 2") == []
assert nonterminals("1 <3> 2") == ["<3>"]
assert nonterminals("1 + 2") == []
assert nonterminals(("<1>", {'option': 'value'})) == ["<1>"]마찬가지로, is_nonterminal() 함수는 기호가 비단말인지 아닌지 검사합니다.
def is_nonterminal(s):
return RE_NONTERMINAL.match(s)assert is_nonterminal("<abc>")
assert is_nonterminal("<symbol-1>")
assert not is_nonterminal("+")A Simple Grammar Fuzzer
이제 위의 문법을 사용해 봅시다. 우리는 시작 기호(<start>)로 시작해서 계속 확장하는 매우 간단한 grammar fuzzer를 만들 것입니다. 무한 입력으로 확장되는 것을 피하기 위해서, 우리는 비단말 숫자에 제한(max_nonterminals)을 둘 것입니다. 또한 기호의 수를 더 이상 줄일 수 없는 상황에 처하지 않도록 전체 확장 단계 수도 제한합니다.
import randomclass ExpansionError(Exception):
passdef simple_grammar_fuzzer(grammar: Grammar,
start_symbol: str = START_SYMBOL,
max_nonterminals: int = 10,
max_expansion_trials: int = 100,
log: bool = False) -> str:
"""Produce a string from `grammar`.
`start_symbol`: use a start symbol other than `<start>` (default).
`max_nonterminals`: the maximum number of nonterminals
still left for expansion
`max_expansion_trials`: maximum # of attempts to produce a string
`log`: print expansion progress if True"""
term = start_symbol
expansion_trials = 0
while len(nonterminals(term)) > 0:
symbol_to_expand = random.choice(nonterminals(term))
expansions = grammar[symbol_to_expand]
expansion = random.choice(expansions)
# In later chapters, we allow expansions to be tuples,
# with the expansion being the first element
if isinstance(expansion, tuple):
expansion = expansion[0]
new_term = term.replace(symbol_to_expand, expansion, 1)
if len(nonterminals(new_term)) < max_nonterminals:
term = new_term
if log:
print("%-40s" % (symbol_to_expand + " -> " + expansion), term)
expansion_trials = 0
else:
expansion_trials += 1
if expansion_trials >= max_expansion_trials:
raise ExpansionError("Cannot expand " + repr(term))
return term이 간단한 grammar fuzzer가 어떻게 시작 기호로 부터 산술식을 얻는지 봐봅시다.
simple_grammar_fuzzer(grammar=EXPR_GRAMMAR, max_nonterminals=3, log=True)<start> -> <expr> <expr>
<expr> -> <term> + <expr> <term> + <expr>
<term> -> <factor> <factor> + <expr>
<factor> -> <integer> <integer> + <expr>
<integer> -> <digit> <digit> + <expr>
<digit> -> 6 6 + <expr>
<expr> -> <term> - <expr> 6 + <term> - <expr>
<expr> -> <term> 6 + <term> - <term>
<term> -> <factor> 6 + <factor> - <term>
<factor> -> -<factor> 6 + -<factor> - <term>
<term> -> <factor> 6 + -<factor> - <factor>
<factor> -> (<expr>) 6 + -(<expr>) - <factor>
<factor> -> (<expr>) 6 + -(<expr>) - (<expr>)
<expr> -> <term> 6 + -(<term>) - (<expr>)
<expr> -> <term> 6 + -(<term>) - (<term>)
<term> -> <factor> 6 + -(<factor>) - (<term>)
<factor> -> +<factor> 6 + -(+<factor>) - (<term>)
<factor> -> +<factor> 6 + -(++<factor>) - (<term>)
<term> -> <factor> 6 + -(++<factor>) - (<factor>)
<factor> -> (<expr>) 6 + -(++(<expr>)) - (<factor>)
<factor> -> <integer> 6 + -(++(<expr>)) - (<integer>)
<expr> -> <term> 6 + -(++(<term>)) - (<integer>)
<integer> -> <digit> 6 + -(++(<term>)) - (<digit>)
<digit> -> 9 6 + -(++(<term>)) - (9)
<term> -> <factor> * <term> 6 + -(++(<factor> * <term>)) - (9)
<term> -> <factor> 6 + -(++(<factor> * <factor>)) - (9)
<factor> -> <integer> 6 + -(++(<integer> * <factor>)) - (9)
<integer> -> <digit> 6 + -(++(<digit> * <factor>)) - (9)
<digit> -> 2 6 + -(++(2 * <factor>)) - (9)
<factor> -> +<factor> 6 + -(++(2 * +<factor>)) - (9)
<factor> -> -<factor> 6 + -(++(2 * +-<factor>)) - (9)
<factor> -> -<factor> 6 + -(++(2 * +--<factor>)) - (9)
<factor> -> -<factor> 6 + -(++(2 * +---<factor>)) - (9)
<factor> -> -<factor> 6 + -(++(2 * +----<factor>)) - (9)
<factor> -> <integer>.<integer> 6 + -(++(2 * +----<integer>.<integer>)) - (9)
<integer> -> <digit> 6 + -(++(2 * +----<digit>.<integer>)) - (9)
<integer> -> <digit> 6 + -(++(2 * +----<digit>.<digit>)) - (9)
<digit> -> 1 6 + -(++(2 * +----1.<digit>)) - (9)
<digit> -> 7 6 + -(++(2 * +----1.7)) - (9)
'6 + -(++(2 * +----1.7)) - (9)'비단말의 한도를 늘림으로써, 우리는 훨씬 더 오랫동안 생성할 수 있습니다.
for i in range(10):
print(simple_grammar_fuzzer(grammar=EXPR_GRAMMAR, max_nonterminals=5))7 / +48.5
-5.9 / 9 - 4 * +-(-+++((1 + (+7 - (-1 * (++-+7.7 - -+-4.0))))) * +--4 - -(6) + 64)
8.2 - 27 - -9 / +((+9 * --2 + --+-+-((-1 * +(8 - 5 - 6)) * (-((-+(((+(4))))) - ++4) / +(-+---((5.6 - --(3 * -1.8 * +(6 * +-(((-(-6) * ---+6)) / +--(+-+-7 * (-0 * (+(((((2)) + 8 - 3 - ++9.0 + ---(--+7 / (1 / +++6.37) + (1) / 482) / +++-+0)))) * -+5 + 7.513)))) - (+1 / ++((-84)))))))) * ++5 / +-(--2 - -++-9.0)))) / 5 * --++090
1 - -3 * 7 - 28 / 9
(+9) * +-5 * ++-926.2 - (+9.03 / -+(-(-6) / 2 * +(-+--(8) / -(+1.0) - 5 + 4)) * 3.5)
8 + -(9.6 - 3 - -+-4 * +77)
-(((((++((((+((++++-((+-37))))))))))))) / ++(-(+++(+6)) * -++-(+(++(---6 * (((7)) * (1) / (-7.6 * 535338) + +256) * 0) * 0))) - 4 + +1
5.43
(9 / -405 / -23 - +-((+-(2 * (13))))) + +6 - +8 - 934
-++2 - (--+715769550) / 8 / (1)대부분의 경우 fuzzer가 이 작업을 수행하지만 몇 가지 단점이 있습니다.
Quiz.
simple_grammar_fuzzer() 함수의 단점은 무엇입니까?
- 많은 수의 문자열 검색 및 교체 작업이 있습니다.
- 문자열을 생성하지 못할 수 있습니다. (ExpansionError)
- 문자열에서 발생하지도 않은 확장 기호를 선택하는 경우가 많습니다.
- 위 사항 모두.
실제로 simple_grammar_fuzzer() 함수는 검색 및 교체 작업의 수가 너무 많아서 비효율적이며 문자열을 생성하지 못할 수도 있습니다. 반면에 구현은 간단하며 대부분의 경우 작업을 수행합니다. 이 챕터에서는 이 방법을 사용하고 다음 챕터에서는 보다 효율적인 fuzzer를 만드는 방법을 보여드리겠습니다.
Visualizing Grammars as Railroad Diagrams
문법을 사용하면 앞에서 논의한 몇 가지 예제의 형식을 쉽게 지정할 수 있습니다. 예를 들어 위의 산술 식은 bc(또는 산술 식을 계산하는 다른 프로그램)로 직접 보낼 수 있습니다. 몇 가지 추가 문법을 소개하기 전에, 이해를 돕기 위해서 시각화할 수 있는 방법을 제공하겠습니다.
구문 다이어그램 이라고 불리는 Railroad 다이어그램은 문맥 자유 문법을 그래픽으로 표현한 것입니다. Railroad 다이어그램은 "Rail" 트랙을 따라 왼쪽에서 오른쪽으로 읽힙니다. 트랙에서 마주치는 기호들의 순서가 언어를 정의합니다. railroad 다이어그램을 생성하기 위해 함수 syntax_diagram()을 구현하겠습니다.
syntax_diagram() 함수 구현
우리는 시각화를 위한 외부 라이브러리인 RailroadDiagrams를 사용합니다.
from RailroadDiagrams import NonTerminal, Terminal, Choice, HorizontalChoice, Sequence
from RailroadDiagrams import show_diagramfrom IPython.display import SVG우리는 첫번째로 주어진 기호를 시각화하기 위해 syntax_diagram_symbol() 메서드를 정의합니다. 단말 기호는 타원형으로 표시되고 비단말 기호(예: <term>는 직사각형으로 표시됩니다.
def syntax_diagram_symbol(symbol: str) -> Any:
if is_nonterminal(symbol):
return NonTerminal(symbol[1:-1])
else:
return Terminal(symbol)SVG(show_diagram(syntax_diagram_symbol('<term>')))
expansion alternatives를 시각화 하기 위해서 syntax_diagram_expr() 함수를 정의합시다.
def syntax_diagram_expr(expansion: Expansion) -> Any:
# In later chapters, we allow expansions to be tuples,
# with the expansion being the first element
if isinstance(expansion, tuple):
expansion = expansion[0]
symbols = [sym for sym in re.split(RE_NONTERMINAL, expansion) if sym != ""]
if len(symbols) == 0:
symbols = [""] # special case: empty expansion
return Sequence(*[syntax_diagram_symbol(sym) for sym in symbols])SVG(show_diagram(syntax_diagram_expr(EXPR_GRAMMAR['<term>'][0])))
이것은 <term>-a<factor> 에 *와 <term>이 온 첫번째 alternative입니다.
다음으로, alternate expressions을 표시하기 위한 syntax_diagram_alt() 함수를 정의합니다.
from itertools import zip_longestdef syntax_diagram_alt(alt: List[Expansion]) -> Any:
max_len = 5
alt_len = len(alt)
if alt_len > max_len:
iter_len = alt_len // max_len
alts = list(zip_longest(*[alt[i::iter_len] for i in range(iter_len)]))
exprs = [[syntax_diagram_expr(expr) for expr in alt
if expr is not None] for alt in alts]
choices = [Choice(len(expr) // 2, *expr) for expr in exprs]
return HorizontalChoice(*choices)
else:
return Choice(alt_len // 2, *[syntax_diagram_expr(expr) for expr in alt])SVG(show_diagram(syntax_diagram_alt(EXPR_GRAMMAR['<digit>'])))
우리는 <digit>이 0~9까지의 어떤 한 자리수도 될 수 있다는 것을 알 수 있습니다.
마지막으로, 우리는 문법을 제공하고 규칙의 문법 다이어그램을 표시하는 syntax_diagram() 함수를 정의합니다.
def syntax_diagram(grammar: Grammar) -> None:
from IPython.display import SVG, display
for key in grammar:
print("%s" % key[1:-1])
display(SVG(show_diagram(syntax_diagram_alt(grammar[key]))))syntax_diagram() 함수를 이용해서 표현 문법의 railroad 다이어그램을 생성합시다.
syntax_diagram(EXPR_GRAMMAR)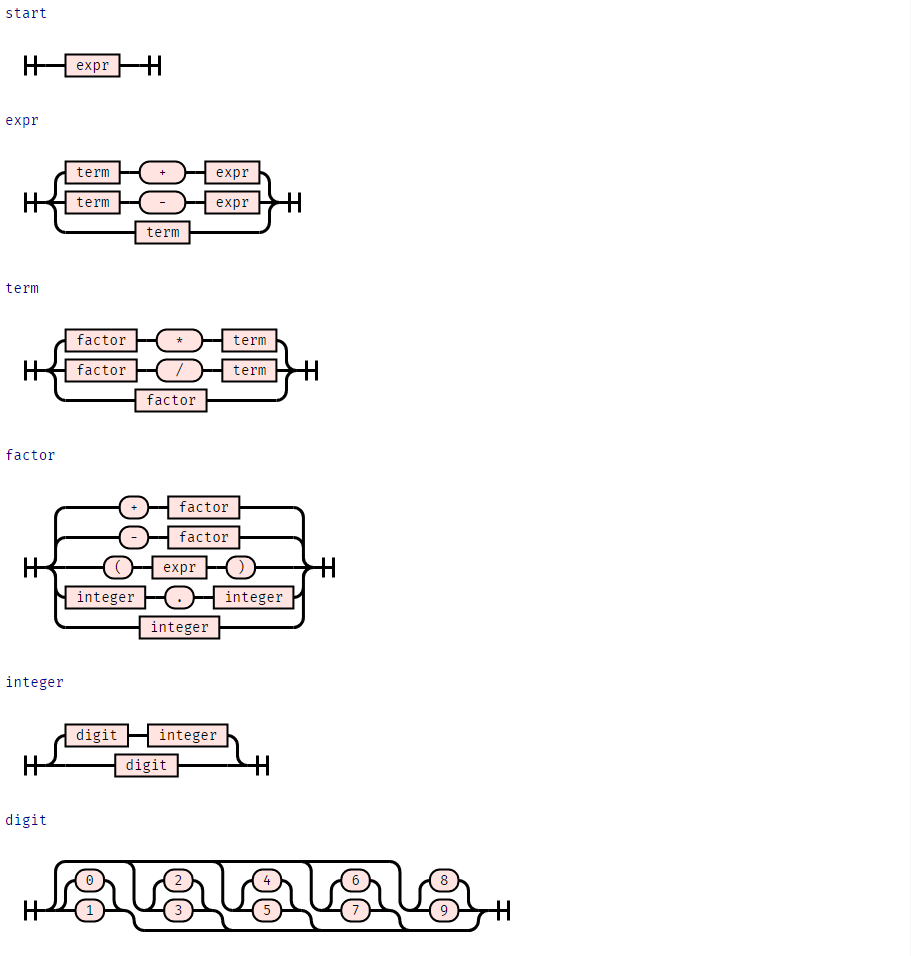
이 railroad 표현은 특히 더 복잡한 문법의 경우 문법의 구조를 시각화하는 데 도움이 될 것입니다.
Some Grammars
몇 가지 문법을 더 만들어서 fuzzing에 쓰도록 합시다.
A CGI Grammar
여기 chapter on coverage 에서 소개된 cgi_decode()의 문법이 있습니다.
CGI_GRAMMAR: Grammar = {
"<start>":
["<string>"],
"<string>":
["<letter>", "<letter><string>"],
"<letter>":
["<plus>", "<percent>", "<other>"],
"<plus>":
["+"],
"<percent>":
["%<hexdigit><hexdigit>"],
"<hexdigit>":
["0", "1", "2", "3", "4", "5", "6", "7",
"8", "9", "a", "b", "c", "d", "e", "f"],
"<other>": # Actually, could be _all_ letters
["0", "1", "2", "3", "4", "5", "a", "b", "c", "d", "e", "-", "_"],
}syntax_diagram(CGI_GRAMMAR)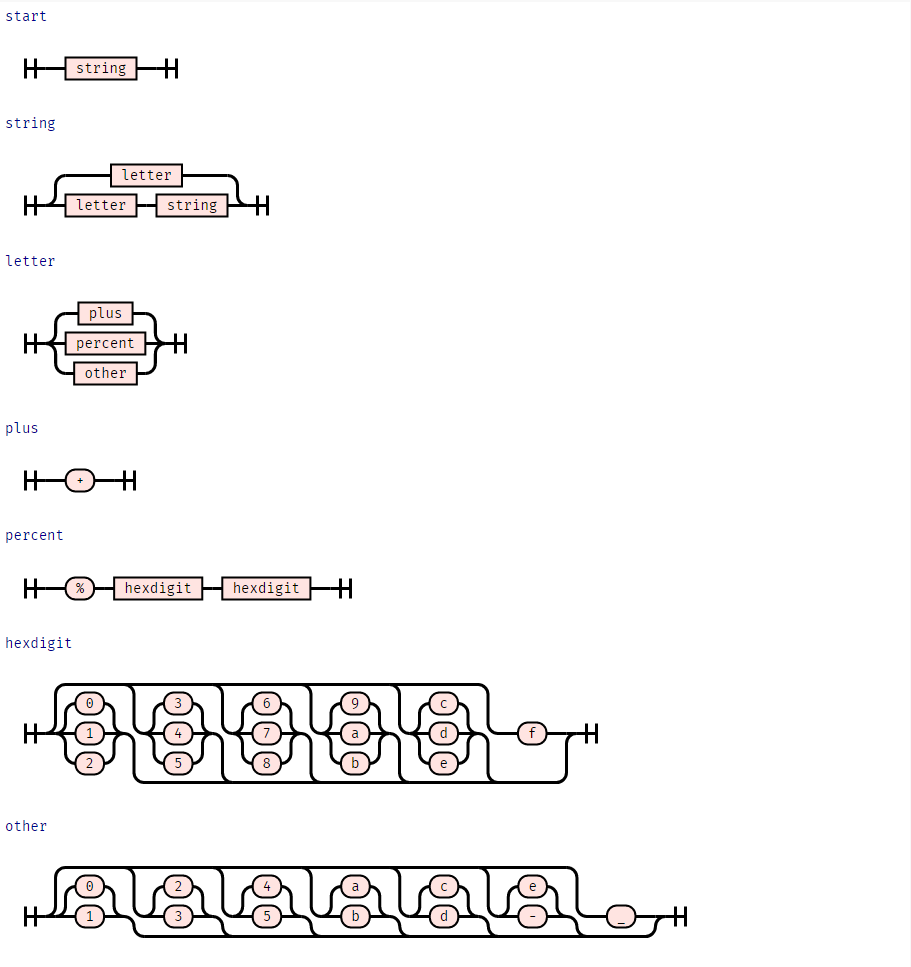
basic fuzzing이나 mutation-based fuzzing과는 대조적으로, 문법은 모든 종류의 조합을 빠르게 생성합니다.
for i in range(10):
print(simple_grammar_fuzzer(grammar=CGI_GRAMMAR, max_nonterminals=10))+%9a
+++%ce+
+_
+%c6c
++
+%cd+5
1%ee
%b9%d5
%96
%57d%42A URL Grammar
CGI 입력에 대해 살펴본 것과 동일한 속성은 더 복잡한 입력에도 적용됩니다. 문법을 사용하여 많은 유효한 URL을 생성해 봅시다.
URL_GRAMMAR: Grammar = {
"<start>":
["<url>"],
"<url>":
["<scheme>://<authority><path><query>"],
"<scheme>":
["http", "https", "ftp", "ftps"],
"<authority>":
["<host>", "<host>:<port>", "<userinfo>@<host>", "<userinfo>@<host>:<port>"],
"<host>": # Just a few
["cispa.saarland", "www.google.com", "fuzzingbook.com"],
"<port>":
["80", "8080", "<nat>"],
"<nat>":
["<digit>", "<digit><digit>"],
"<digit>":
["0", "1", "2", "3", "4", "5", "6", "7", "8", "9"],
"<userinfo>": # Just one
["user:password"],
"<path>": # Just a few
["", "/", "/<id>"],
"<id>": # Just a few
["abc", "def", "x<digit><digit>"],
"<query>":
["", "?<params>"],
"<params>":
["<param>", "<param>&<params>"],
"<param>": # Just a few
["<id>=<id>", "<id>=<nat>"],
}syntax_diagram(URL_GRAMMAR)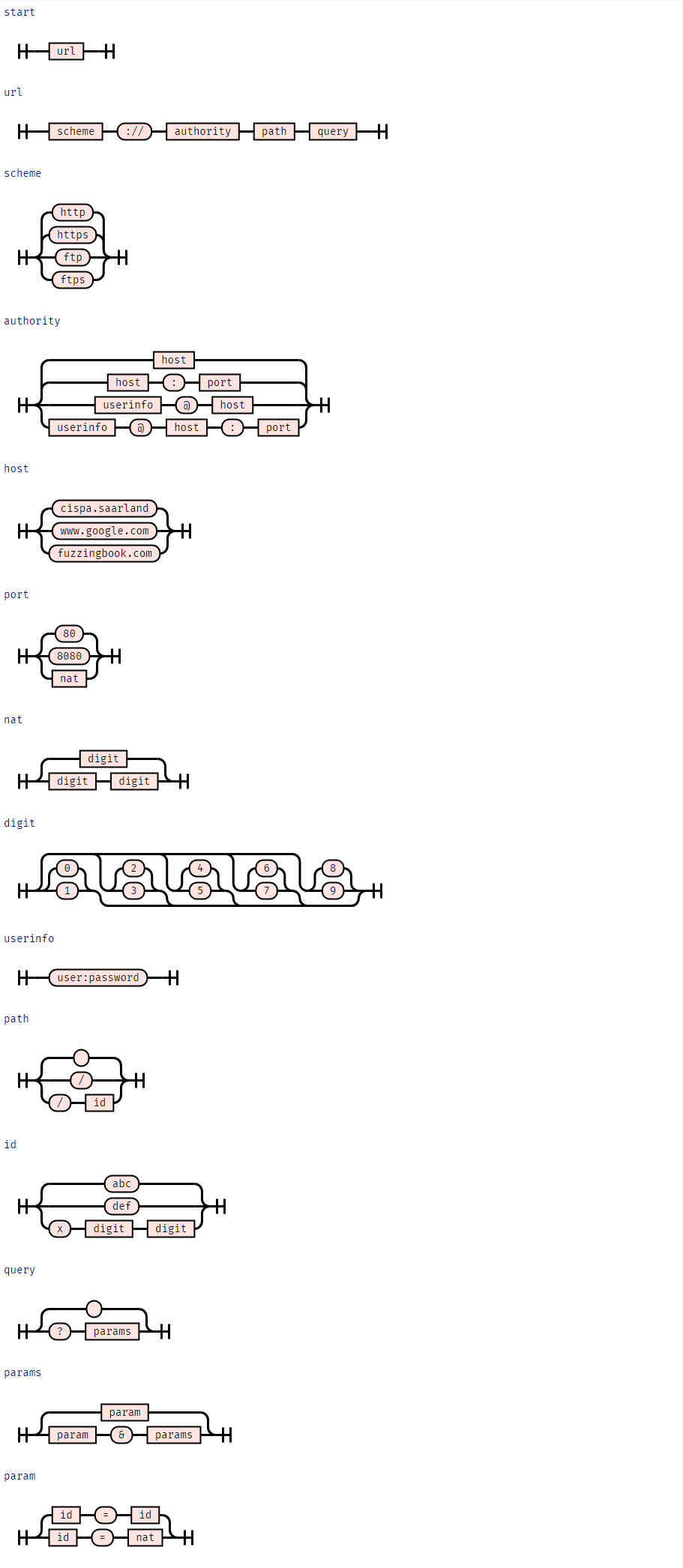
다시 말하지만, 몇 밀리초 안에 우리는 많은 유효한 입력을 생성할 수 있습니다.
for i in range(10):
print(simple_grammar_fuzzer(grammar=URL_GRAMMAR, max_nonterminals=10))https://user:password@cispa.saarland:80/
http://fuzzingbook.com?def=56&x89=3&x46=48&def=def
ftp://cispa.saarland/?x71=5&x35=90&def=abc
https://cispa.saarland:80/def?def=7&x23=abc
https://fuzzingbook.com:80/
https://fuzzingbook.com:80/abc?def=abc&abc=x14&def=abc&abc=2&def=38
ftps://fuzzingbook.com/x87
https://user:password@fuzzingbook.com:6?def=54&x44=abc
http://fuzzingbook.com:80?x33=25&def=8
http://fuzzingbook.com:8080/defA Natural Language Grammar
마지막으로, 문법은 컴퓨터 입력과 같이 형식적인 언어에만 국한되지 않고, 자연어를 생산하기 위해서도 사용될 수 있습니다. 우리가 이 책의 제목을 정할 때 사용한 문법은 다음과 같습니다.
TITLE_GRAMMAR: Grammar = {
"<start>": ["<title>"],
"<title>": ["<topic>: <subtopic>"],
"<topic>": ["Generating Software Tests", "<fuzzing-prefix>Fuzzing", "The Fuzzing Book"],
"<fuzzing-prefix>": ["", "The Art of ", "The Joy of "],
"<subtopic>": ["<subtopic-main>",
"<subtopic-prefix><subtopic-main>",
"<subtopic-main><subtopic-suffix>"],
"<subtopic-main>": ["Breaking Software",
"Generating Software Tests",
"Principles, Techniques and Tools"],
"<subtopic-prefix>": ["", "Tools and Techniques for "],
"<subtopic-suffix>": [" for <reader-property> and <reader-property>",
" for <software-property> and <software-property>"],
"<reader-property>": ["Fun", "Profit"],
"<software-property>": ["Robustness", "Reliability", "Security"],
}syntax_diagram(TITLE_GRAMMAR)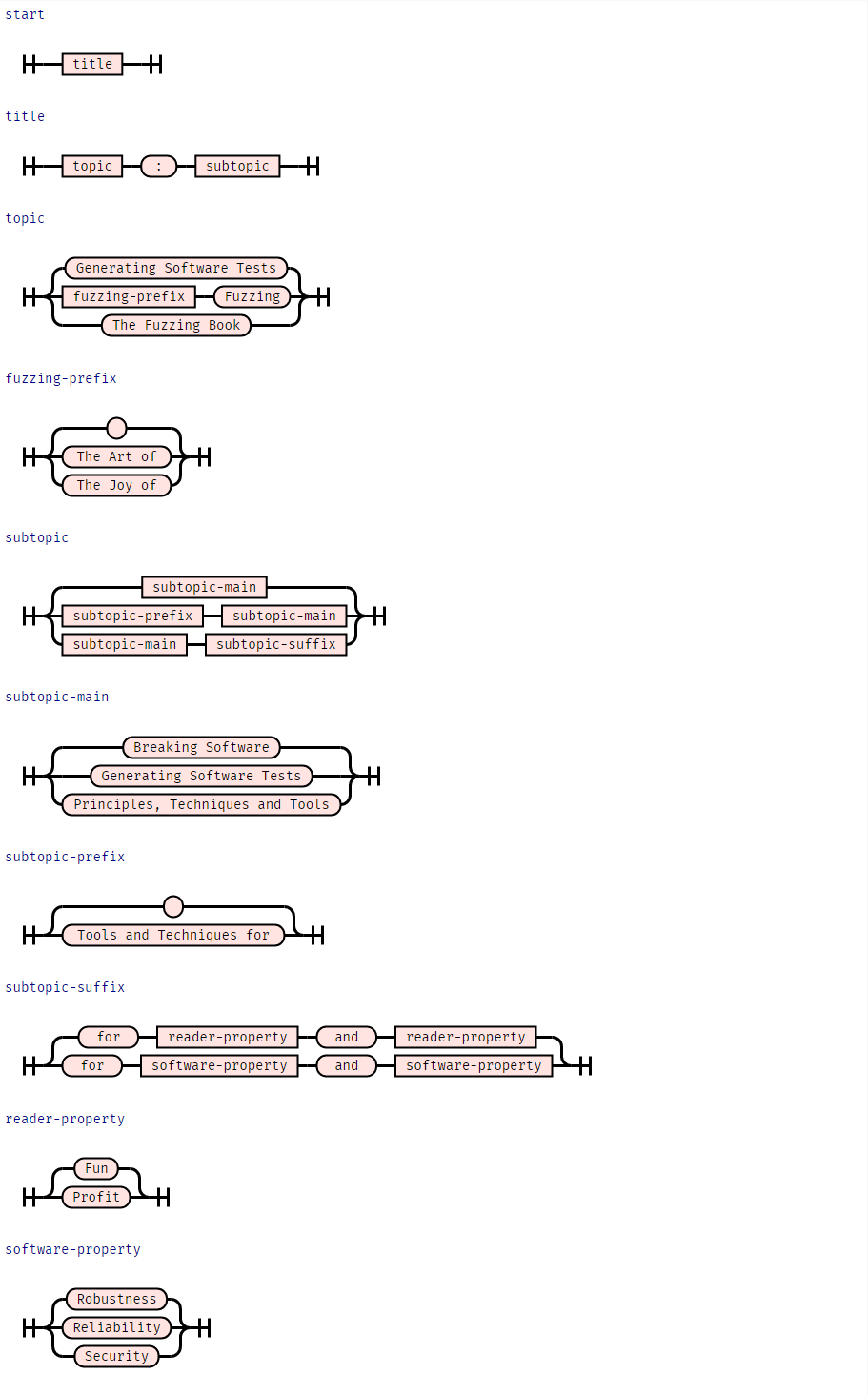
from typing import Settitles: Set[str] = set()
while len(titles) < 10:
titles.add(simple_grammar_fuzzer(
grammar=TITLE_GRAMMAR, max_nonterminals=10))
titles{'Fuzzing: Generating Software Tests',
'Fuzzing: Principles, Techniques and Tools',
'Generating Software Tests: Breaking Software',
'Generating Software Tests: Breaking Software for Robustness and Robustness',
'Generating Software Tests: Principles, Techniques and Tools',
'Generating Software Tests: Principles, Techniques and Tools for Profit and Fun',
'Generating Software Tests: Tools and Techniques for Principles, Techniques and Tools',
'The Fuzzing Book: Breaking Software',
'The Fuzzing Book: Generating Software Tests for Profit and Profit',
'The Fuzzing Book: Generating Software Tests for Robustness and Robustness'}Grammars as Mutation Seeds
문법의 매우 유용한 특성 중 하나는 대부분 유효한 입력을 생성한다는 것입니다. 구문론적 관점에서 입력은 주어진 문법의 제약을 만족시키기 때문에 실제로 항상 유효합니다. (물론, 우선 유효한 문법이 필요합니다.) 그러나 문법은 쉽게 표현할 수 없는 의미론적 특성도 있습니다. 예를 들어 URL에 대해 포트 범위가 1024 ~ 2048 사이여야 하는 경우 문법으로 쓰기 어렵습니다. 더 복잡한 제약 조건을 만족해야 한다면, 문법이 표현할 수 있는 것의 한계에 빠르게 도달합니다.
이것을 피하는 한 가지 방법은 이 책의 뒷부분에서 논의할 것처럼 문법에 제약을 가하는 것입니다. 또 다른 방법은 grammar-based fuzzing과 mutation-based fuzzing의 장점을 결합하는 것입니다. 이 아이디어는 grammar-generated 입력을 mutation-based fuzzing의 seed로 사용하는 것입니다. 이렇게 하면 정상적인 grammar-generated 입력을 시드로 비정상적인 값들이 포함된 grammar-generated 입력을 만들어 낼 수 있습니다. 그래서 정상적인 입력 뿐만 아니라 비정상적인 입력도 테스트할 수 있게 됩니다.
생성된 입력을 시드로 사용하기 위해서 앞에서 소개한 mutation fuzzers에 직접 줄 수 있습니다.
from MutationFuzzer import MutationFuzzer # minor dependencynumber_of_seeds = 10
seeds = [
simple_grammar_fuzzer(
grammar=URL_GRAMMAR,
max_nonterminals=10) for i in range(number_of_seeds)]
seeds['ftps://user:password@www.google.com:80',
'http://cispa.saarland/',
'ftp://www.google.com:42/',
'ftps://user:password@fuzzingbook.com:39?abc=abc',
'https://www.google.com?x33=1&x06=1',
'http://www.google.com:02/',
'https://user:password@www.google.com/',
'ftp://cispa.saarland:8080/?abc=abc&def=def&abc=5',
'http://www.google.com:80/def?def=abc',
'http://user:password@cispa.saarland/']m = MutationFuzzer(seeds)[m.fuzz() for i in range(20)]['ftps://user:password@www.google.com:80',
'http://cispa.saarland/',
'ftp://www.google.com:42/',
'ftps://user:password@fuzzingbook.com:39?abc=abc',
'https://www.google.com?x33=1&x06=1',
'http://www.google.com:02/',
'https://user:password@www.google.com/',
'ftp://cispa.saarland:8080/?abc=abc&def=def&abc=5',
'http://www.google.com:80/def?def=abc',
'http://user:password@cispa.saarland/',
'Eh4tp:www.coogle.com:80/def?d%f=abc',
'ftps://}ser:passwod@fuzzingbook.com:9?abc=abc',
'uftp//cispa.sRaarland:808&0?abc=abc&def=defabc=5',
'http://user:paswor9d@cispar.saarland/v',
'ftp://Www.g\x7fogle.cAom:42/',
'hht://userC:qassMword@cispy.csaarland/',
'httx://ww.googlecom:80defde`f=ac',
'htt://cispq.waarlnd/',
'htFtp\t://cmspa./saarna(md/',
'ft:/www.google.com:42\x0f']처음 10개의 fuzz() 호출이 시드 입력을 반환하는 반면, 나중에 호출은 다시 임의의 mutations을 생성합니다. MutationFuzzer 대신 MutationCoverageFuzzer를 사용하면 다시 범위별로 검색을 안내할 수 있으므로 여러 퍼저의 장점을 하나로 통합할 수 있습니다.
A Grammar Toolbox
이제 우리가 문법을 작성하는데 도움이 되는 몇가지 기술을 소개하겠습니다.
Escapes
문법에서 <and>가 비단말자를 구분하는 경우, 몇몇의 입력이 <and>를 포함해야 한다는 것을 실제로 어떻게 표현할 수 있을까요? 정답은 간단합니다: 그저 그들을 위한 기호를 도입하면 됩니다.
simple_nonterminal_grammar: Grammar = {
"<start>": ["<nonterminal>"],
"<nonterminal>": ["<left-angle><identifier><right-angle>"],
"<left-angle>": ["<"],
"<right-angle>": [">"],
"<identifier>": ["id"] # for now
}simple_nonterminal_grammar에서 <left-angle>에 대한 확장도 <right-angle>에 대한 확장도 비단말자로 오인할 수 없습니다. 따라서 우리는 원하는 만큼 생산할 수 있습니다.
Extending Grammars
이책의 코스에서 우리는 빈번하게 기존의 문법을 확장하여 새로운 기능을 가진 문법을 만드는 문제에 부딪힙니다. 이러한 확장은 객체 지향 프로그래밍의 subclassing과 매우 유사합니다.
기존 문법 g에서 새로운 문법 g'을 만들기 위해서, 우리는 먼저 g를 g'으로 복사한 다음 새로운 alternatives를 가지고 기존 규칙을 확장하거나 새로운 기호를 추가합니다. 다음은 식별자에 대한 더 나은 규칙으로 위의 비단말 문법을 확장하는 예입니다.
import copynonterminal_grammar = copy.deepcopy(simple_nonterminal_grammar)
nonterminal_grammar["<identifier>"] = ["<idchar>", "<identifier><idchar>"]
nonterminal_grammar["<idchar>"] = ['a', 'b', 'c', 'd'] # for nownonterminal_grammar{'<start>': ['<nonterminal>'],
'<nonterminal>': ['<left-angle><identifier><right-angle>'],
'<left-angle>': ['<'],
'<right-angle>': ['>'],
'<identifier>': ['<idchar>', '<identifier><idchar>'],
'<idchar>': ['a', 'b', 'c', 'd']}이러한 문법 확장은 일반적인 연산이기 때문에, 우리는 먼저 주어진 문법을 복사하고 파이썬 딕셔너리 update() 메서드를 사용하여 딕셔너리를 업데이트하는 사용자 정의 함수 extend_grammar()를 도입합니다.
def extend_grammar(grammar: Grammar, extension: Grammar = {}) -> Grammar:
new_grammar = copy.deepcopy(grammar)
new_grammar.update(extension)
return new_grammarextend_grammar() 함수의 호출은 위의 "manual" 예시와 마찬가지로 simple_nonterminal_grammar를 nonterminal_grammar로 확장합니다.
nonterminal_grammar = extend_grammar(simple_nonterminal_grammar,
{
"<identifier>": ["<idchar>", "<identifier><idchar>"],
# for now
"<idchar>": ['a', 'b', 'c', 'd']
}
)Character Classes
위의 nonterminal_grammar에서는 처음 몇 글자만 나열했는데, 실제로 문법의 모든 문자나 숫자를 수동으로 나열하는 것은 좀 귀찮습니다.
그러나 문법은 프로그램의 일부이므로 프로그래밍 방식으로도 구성될 수 있다는 것을 기억하십시오. 문자열의 문자 목록을 구성하는 함수 srange()를 도입하면 됩니다.
import stringdef srange(characters: str) -> List[Expansion]:
"""Construct a list with all characters in the string"""
return [c for c in characters]모든 ASCII 문자를 포함하는 상수 string.ascii_letters를 전달하려면 srange()는 모든 ASCII 문자 리스트를 반환합니다.
string.ascii_letters'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'srange(string.ascii_letters)[:10]['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']문법에서 이러한 상수를 사용하여 식별자를 빠르게 정의할 수 있습니다.
nonterminal_grammar = extend_grammar(nonterminal_grammar,
{
"<idchar>": (srange(string.ascii_letters) +
srange(string.digits) +
srange("-_"))
}
)[simple_grammar_fuzzer(nonterminal_grammar, "<identifier>") for i in range(10)]['b', 'd', 'V9', 'x4c', 'YdiEWj', 'c', 'xd', '7', 'vIU', 'QhKD']crange(start, end)는 ASCII 시작에서 끝(포함)까지의 모든 문자 목록을 반환합니다.
def crange(character_start: str, character_end: str) -> List[Expansion]:
return [chr(i)
for i in range(ord(character_start), ord(character_end) + 1)]이를 사용하여 문자 범위를 표시할 수 있습니다.
crange('0', '9')['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']assert crange('a', 'z') == srange(string.ascii_lowercase)Grammar Shortcuts
위의 nonterminal_grammar에서, 다른 문법에서와 같이, 우리는 재귀(recursion)를 사용하여 문자의 반복을 표현해야 합니다.
nonterminal_grammar["<identifier>"]['<idchar>', '<identifier><idchar>']예를 들어, 비단말자가 1회 이상 반복되는 문자 쉬퀀스여야 한다고 간단히 말할 수 있다면 조금 더 쉬울 수 있습니다.
<identifier> = <idchar>+여기서 +는 +가 붙은 기호가 비어있지 않은 반복임을 나타냅니다.
+와 같은 연산자는 문법에서 편리한 shortcuts로 자주 도입됩니다. 형식적으로, 우리의 문법은 소위 Backus-Naur 형식 또는 줄여서 BNF 형식으로 나옵니다. Operators는 BNF를 _extended BNF 또는 줄여서 EBNF*로 확장합니다.
- <symbol>? 형식은 선택 사항임을 나타냅니다. 즉, 0 또는 1회 발생할 수 있습니다.
- <symbol>+ 형식은 1회 이상 반복적으로 발생할 수 있음을 나타냅니다.
- <symbol>* 형식은 이 0회 이상 발생할 수 있음을 나타냅니다. (즉, 선택적 반복입니다.)
문제를 더욱 흥미롭게 하기 위해 위의 shortcuts와 함께 괄호를 사용하고자 합니다. 그래서, (<foo><bar>)?는 <foo>와 <bar>가 선택 사항임을 나타냅니다.
이러한 연산자를 사용하면 식별자 규칙을 보다 간단한 방법으로 정의할 수 있습니다. 이를 위해 원본 문법의 복사본을 만들고 <identifier>규칙을 수정합시다.
nonterminal_ebnf_grammar = extend_grammar(nonterminal_grammar,
{
"<identifier>": ["<idchar>+"]
}
)마찬가지로, 우리는 표현 문법을 단순화할 수 있습니다. 기호가 어떻게 선택적인지, 그리고 정수가 어떻게 숫자의 시퀀스로 표현될 수 있는지 생각해보세요.
EXPR_EBNF_GRAMMAR: Grammar = {
"<start>":
["<expr>"],
"<expr>":
["<term> + <expr>", "<term> - <expr>", "<term>"],
"<term>":
["<factor> * <term>", "<factor> / <term>", "<factor>"],
"<factor>":
["<sign>?<factor>", "(<expr>)", "<integer>(.<integer>)?"],
"<sign>":
["+", "-"],
"<integer>":
["<digit>+"],
"<digit>":
srange(string.digits)
}이러한 EBNF 문법을 가지고 자동으로 BNF 문법으로 변환하는 함수 convert_ebnf_grammar()를 구현해 보자.
convert_ebnf_grammar() 구현
우리의 목표는 위와 같은 EBNF 문법을 일반 BNF 문법으로 변환하는 것입니다. 이것은 네 가지 규칙으로 이루어집니다.
- 식 (content)op, ?, +, * 중 하나인 op는 <new-symbol>op가 됩니다. <new-symbol> ::= content
- 식 <symbol>?는 <new-symbol>이 됩니다. <new-symbol> ::= <empty> | <symbol>
- 식 <symbol>+는 <new-symbol>가 됩니다. <new-symbol> ::= <symbol> | <symbol>
- 식 <symbol>*는 <new-symbol>가 됩니다. <new-symbol> ::= <empty> | <symbol>
여기서 <empty>는 <empty> ::= 와 같이 빈 문자열로 확장됩니다. (이것은 앱실론 팽창이라고 불립니다.)
이 연산자들이 정규식을 상기시킨다면, 이것은 우연이 아닙니다: 사실, 모든 기본 정규식은 위의 규칙(및 위에서 정의된 대로 crange()가 있는 character classes)을 사용하여 문법으로 변환될 수 있습니다.
위의 예제에 이러한 규칙을 적용하면 다음과 같은 결과를 얻을 수 있습니다.
- <idchar>+는 <idchar><new-symbol>과 함께 <new-symbol> ::= <idchar> | <idchar><enw-symbol>이 됩니다.
- <integer>(.<integer>)? 는 <integer><new-symbol>과 함께 <new-symbol> ::= <empty> | .<integer>가 됩니다.
이 규칙들을 세 단계로 실행합시다.
Creating New Symbols
첫째, 우리는 new symbols를 만드는 메커니즘이 필요합니다. 이것은 꽤 간단합니다.
def new_symbol(grammar: Grammar, symbol_name: str = "<symbol>") -> str:
"""Return a new symbol for `grammar` based on `symbol_name`"""
if symbol_name not in grammar:
return symbol_name
count = 1
while True:
tentative_symbol_name = symbol_name[:-1] + "-" + repr(count) + ">"
if tentative_symbol_name not in grammar:
return tentative_symbol_name
count += 1assert new_symbol(EXPR_EBNF_GRAMMAR, '<expr>') == '<expr-1>'Expanding Parenthesized Expressions
다음으로, 우리는 우리의 expansion에서 괄호로 묶인 식을 추출하고 위의 규칙에 따라 확장할 수 있는 수단이 필요합니다. 식 추출부터 시작하겠습니다.
RE_PARENTHESIZED_EXPR = re.compile(r'\([^()]*\)[?+*]')def parenthesized_expressions(expansion: Expansion) -> List[str]:
# In later chapters, we allow expansions to be tuples,
# with the expansion being the first element
if isinstance(expansion, tuple):
expansion = expansion[0]
return re.findall(RE_PARENTHESIZED_EXPR, expansion)assert parenthesized_expressions("(<foo>)* (<foo><bar>)+ (+<foo>)? <integer>(.<integer>)?") == [
'(<foo>)*', '(<foo><bar>)+', '(+<foo>)?', '(.<integer>)?']이제 이것을 사용하여 위의 규칙 1을 적용할 수 있으며, 괄호 안에 표현식을 위한 새로운 기호를 도입할 수 있습니다.
def convert_ebnf_parentheses(ebnf_grammar: Grammar) -> Grammar:
"""Convert a grammar in extended BNF to BNF"""
grammar = extend_grammar(ebnf_grammar)
for nonterminal in ebnf_grammar:
expansions = ebnf_grammar[nonterminal]
for i in range(len(expansions)):
expansion = expansions[i]
if not isinstance(expansion, str):
expansion = expansion[0]
while True:
parenthesized_exprs = parenthesized_expressions(expansion)
if len(parenthesized_exprs) == 0:
break
for expr in parenthesized_exprs:
operator = expr[-1:]
contents = expr[1:-2]
new_sym = new_symbol(grammar)
exp = grammar[nonterminal][i]
opts = None
if isinstance(exp, tuple):
(exp, opts) = exp
assert isinstance(exp, str)
expansion = exp.replace(expr, new_sym + operator, 1)
if opts:
grammar[nonterminal][i] = (expansion, opts)
else:
grammar[nonterminal][i] = expansion
grammar[new_sym] = [contents]
return grammar이렇게 하면 위에서 스케치한 대로 변환됩니다.
convert_ebnf_parentheses({"<number>": ["<integer>(.<integer>)?"]}){'<number>': ['<integer><symbol>?'], '<symbol>': ['.<integer>']}중첩 괄호로 묶인 식에도 사용할 수 있습니다.
convert_ebnf_parentheses({"<foo>": ["((<foo>)?)+"]}){'<foo>': ['<symbol-1>+'], '<symbol>': ['<foo>'], '<symbol-1>': ['<symbol>?']}Expanding Operators
괄호로 묶인 식을 확장한 후 기호 뒤에 연산자(?, *, +)를 처리해야 합니다. 위의 convert_ebnf_parenthes() 함수와 마찬가지로 먼저 모든 기호를 추출한 다음 연산자를 추출합니다.
RE_EXTENDED_NONTERMINAL = re.compile(r'(<[^<> ]*>[?+*])')def extended_nonterminals(expansion: Expansion) -> List[str]:
# In later chapters, we allow expansions to be tuples,
# with the expansion being the first element
if isinstance(expansion, tuple):
expansion = expansion[0]
return re.findall(RE_EXTENDED_NONTERMINAL, expansion)assert extended_nonterminals(
"<foo>* <bar>+ <elem>? <none>") == ['<foo>*', '<bar>+', '<elem>?']우리의 converter는 심볼과 연산자를 추출하고 위에 제시된 규칙에 따라 새로운 심볼을 추가합니다.
def convert_ebnf_operators(ebnf_grammar: Grammar) -> Grammar:
"""Convert a grammar in extended BNF to BNF"""
grammar = extend_grammar(ebnf_grammar)
for nonterminal in ebnf_grammar:
expansions = ebnf_grammar[nonterminal]
for i in range(len(expansions)):
expansion = expansions[i]
extended_symbols = extended_nonterminals(expansion)
for extended_symbol in extended_symbols:
operator = extended_symbol[-1:]
original_symbol = extended_symbol[:-1]
assert original_symbol in ebnf_grammar, \
f"{original_symbol} is not defined in grammar"
new_sym = new_symbol(grammar, original_symbol)
exp = grammar[nonterminal][i]
opts = None
if isinstance(exp, tuple):
(exp, opts) = exp
assert isinstance(exp, str)
new_exp = exp.replace(extended_symbol, new_sym, 1)
if opts:
grammar[nonterminal][i] = (new_exp, opts)
else:
grammar[nonterminal][i] = new_exp
if operator == '?':
grammar[new_sym] = ["", original_symbol]
elif operator == '*':
grammar[new_sym] = ["", original_symbol + new_sym]
elif operator == '+':
grammar[new_sym] = [
original_symbol, original_symbol + new_sym]
return grammarconvert_ebnf_operators({"<integer>": ["<digit>+"], "<digit>": ["0"]}){'<integer>': ['<digit-1>'],
'<digit>': ['0'],
'<digit-1>': ['<digit>', '<digit><digit-1>']}All Together
먼저 괄호를 확장하고 그 다음 연산자를 결합할 수 있습니다.
def convert_ebnf_grammar(ebnf_grammar: Grammar) -> Grammar:
return convert_ebnf_operators(convert_ebnf_parentheses(ebnf_grammar))convert_ebnf_grammar()를 사용하는 예는 다음과 같습니다.
convert_ebnf_grammar({"<authority>": ["(<userinfo>@)?<host>(:<port>)?"]}){'<authority>': ['<symbol-2><host><symbol-1-1>'],
'<symbol>': ['<userinfo>@'],
'<symbol-1>': [':<port>'],
'<symbol-2>': ['', '<symbol>'],
'<symbol-1-1>': ['', '<symbol-1>']}expr_grammar = convert_ebnf_grammar(EXPR_EBNF_GRAMMAR)
expr_grammar{'<start>': ['<expr>'],
'<expr>': ['<term> + <expr>', '<term> - <expr>', '<term>'],
'<term>': ['<factor> * <term>', '<factor> / <term>', '<factor>'],
'<factor>': ['<sign-1><factor>', '(<expr>)', '<integer><symbol-1>'],
'<sign>': ['+', '-'],
'<integer>': ['<digit-1>'],
'<digit>': ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'],
'<symbol>': ['.<integer>'],
'<sign-1>': ['', '<sign>'],
'<symbol-1>': ['', '<symbol>'],
'<digit-1>': ['<digit>', '<digit><digit-1>']}성공! 우리는 EBNF 문법을 BNF로 멋지게 변환했습니다.
character class와 EBNF 문법 변환으로, 우리는 문법을 더 쉽게 쓸 수 있는 두 가지 강력한 도구를 가지고 있습니다. 우리는 문법을 다룰 때 이것들을 반복해서 사용할 것입니다.
Grammar Extensions
이 책을 읽는 동안, 우리는 종종 probabilities나 constraints과 같은 문법에 대한 추가 정보를 지정하고자 합니다. 이러한 확장뿐만 아니라 가능한 다른 확장을 지원하기 위해 주석 메커니즘을 정의합니다.
문법에 주석을 달기 위한 우리의 개념은 개별 expansion에 주석을 추가하는 것입니다. 이를 위해, 우리는 expansion이 문자열일 뿐만 아니라 문자열 쌍과 속성 집합일 수 있도록 허용합니다.
"<expr>":
[("<term> + <expr>", opts(min_depth=10)),
("<term> - <expr>", opts(max_depth=2)),
"<term>"]여기서 opts() 함수를 사용하면 개별 expansion에 적용되는 주석을 표현할 수 있습니다. 이 경우 덧셈은 min_depth 값 10으로, 뺄셈은 max_depth 값 2로 주석을 달 수 있다. 이러한 주석의 의미는 문법을 다루는 개별 알고리즘에 맡겨집니다. 그러나 일반적으로 주석은 무시될 수 있습니다.
opts() 함수 구현
opts() 도우미 함수는 인수의 값 매핑을 반환합니다.
def opts(**kwargs: Any) -> Dict[str, Any]:
return kwargsopts(min_depth=10){'min_depth': 10}확장 문자열과 확장 및 주석 쌍을 모두 처리하기 위해 지정된 도우미 함수 exp_string() 및 exp_opts()를 통해 확장 문자열과 관련 주석에 액세스합니다.
def exp_string(expansion: Expansion) -> str:
"""Return the string to be expanded"""
if isinstance(expansion, str):
return expansion
return expansion[0]exp_string(("<term> + <expr>", opts(min_depth=10)))'<term> + <expr>'def exp_opts(expansion: Expansion) -> Dict[str, Any]:
"""Return the options of an expansion. If options are not defined, return {}"""
if isinstance(expansion, str):
return {}
return expansion[1]def exp_opt(expansion: Expansion, attribute: str) -> Any:
"""Return the given attribution of an expansion.
If attribute is not defined, return None"""
return exp_opts(expansion).get(attribute, None)exp_opts(("<term> + <expr>", opts(min_depth=10))){'min_depth': 10}exp_opt(("<term> - <expr>", opts(max_depth=2)), 'max_depth')2마지막으로 특정 옵션을 설정하는 도우미 함수를 정의합니다.
def set_opts(grammar: Grammar, symbol: str, expansion: Expansion,
opts: Option = {}) -> None:
"""Set the options of the given expansion of grammar[symbol] to opts"""
expansions = grammar[symbol]
for i, exp in enumerate(expansions):
if exp_string(exp) != exp_string(expansion):
continue
new_opts = exp_opts(exp)
if opts == {} or new_opts == {}:
new_opts = opts
else:
for key in opts:
new_opts[key] = opts[key]
if new_opts == {}:
grammar[symbol][i] = exp_string(exp)
else:
grammar[symbol][i] = (exp_string(exp), new_opts)
return
raise KeyError(
"no expansion " +
repr(symbol) +
" -> " +
repr(
exp_string(expansion)))Checking Grammars
문법은 문자열로 표현되기 때문에 오류를 일으키기 쉽습니다. 그래서 문법의 일관성을 확인하는 도우미 기능을 소개하겠습니다.
도우미 함수 is_valid_grammar()는 사용된 모든 기호가 정의되었는지 여부를 확인하기 위해 문법을 반복하며, 그 반대의 경우도 마찬가지이다. 여기서 자세히 살펴볼 필요는 없지만, 항상 그렇듯이 입력 데이터를 사용하기 전에 바로 파악하는 것이 중요합니다.
is_valid_grammar() 함수 구현
import sysdef def_used_nonterminals(grammar: Grammar, start_symbol:
str = START_SYMBOL) -> Tuple[Optional[Set[str]],
Optional[Set[str]]]:
"""Return a pair (`defined_nonterminals`, `used_nonterminals`) in `grammar`.
In case of error, return (`None`, `None`)."""
defined_nonterminals = set()
used_nonterminals = {start_symbol}
for defined_nonterminal in grammar:
defined_nonterminals.add(defined_nonterminal)
expansions = grammar[defined_nonterminal]
if not isinstance(expansions, list):
print(repr(defined_nonterminal) + ": expansion is not a list",
file=sys.stderr)
return None, None
if len(expansions) == 0:
print(repr(defined_nonterminal) + ": expansion list empty",
file=sys.stderr)
return None, None
for expansion in expansions:
if isinstance(expansion, tuple):
expansion = expansion[0]
if not isinstance(expansion, str):
print(repr(defined_nonterminal) + ": "
+ repr(expansion) + ": not a string",
file=sys.stderr)
return None, None
for used_nonterminal in nonterminals(expansion):
used_nonterminals.add(used_nonterminal)
return defined_nonterminals, used_nonterminalsdef reachable_nonterminals(grammar: Grammar,
start_symbol: str = START_SYMBOL) -> Set[str]:
reachable = set()
def _find_reachable_nonterminals(grammar, symbol):
nonlocal reachable
reachable.add(symbol)
for expansion in grammar.get(symbol, []):
for nonterminal in nonterminals(expansion):
if nonterminal not in reachable:
_find_reachable_nonterminals(grammar, nonterminal)
_find_reachable_nonterminals(grammar, start_symbol)
return reachabledef unreachable_nonterminals(grammar: Grammar,
start_symbol=START_SYMBOL) -> Set[str]:
return grammar.keys() - reachable_nonterminals(grammar, start_symbol)def opts_used(grammar: Grammar) -> Set[str]:
used_opts = set()
for symbol in grammar:
for expansion in grammar[symbol]:
used_opts |= set(exp_opts(expansion).keys())
return used_optsdef is_valid_grammar(grammar: Grammar,
start_symbol: str = START_SYMBOL,
supported_opts: Set[str] = set()) -> bool:
"""Check if the given `grammar` is valid.
`start_symbol`: optional start symbol (default: `<start>`)
`supported_opts`: options supported (default: none)"""
defined_nonterminals, used_nonterminals = \
def_used_nonterminals(grammar, start_symbol)
if defined_nonterminals is None or used_nonterminals is None:
return False
# Do not complain about '<start>' being not used,
# even if start_symbol is different
if START_SYMBOL in grammar:
used_nonterminals.add(START_SYMBOL)
for unused_nonterminal in defined_nonterminals - used_nonterminals:
print(repr(unused_nonterminal) + ": defined, but not used",
file=sys.stderr)
for undefined_nonterminal in used_nonterminals - defined_nonterminals:
print(repr(undefined_nonterminal) + ": used, but not defined",
file=sys.stderr)
# Symbols must be reachable either from <start> or given start symbol
unreachable = unreachable_nonterminals(grammar, start_symbol)
msg_start_symbol = start_symbol
if START_SYMBOL in grammar:
unreachable = unreachable - \
reachable_nonterminals(grammar, START_SYMBOL)
if start_symbol != START_SYMBOL:
msg_start_symbol += " or " + START_SYMBOL
for unreachable_nonterminal in unreachable:
print(repr(unreachable_nonterminal) + ": unreachable from " + msg_start_symbol,
file=sys.stderr)
used_but_not_supported_opts = set()
if len(supported_opts) > 0:
used_but_not_supported_opts = opts_used(
grammar).difference(supported_opts)
for opt in used_but_not_supported_opts:
print(
"warning: option " +
repr(opt) +
" is not supported",
file=sys.stderr)
return used_nonterminals == defined_nonterminals and len(unreachable) == 0is_valid_grammar() 함수를 사용해 봅시다. 위에서 정의한 문법은 테스트를 통과합니다.
assert is_valid_grammar(EXPR_GRAMMAR)
assert is_valid_grammar(CGI_GRAMMAR)
assert is_valid_grammar(URL_GRAMMAR)이 검사는 EBNF 문법에도 적용할 수 있습니다.
assert is_valid_grammar(EXPR_EBNF_GRAMMAR)그러나 이것들은 테스트를 통과하지 못합니다.
assert not is_valid_grammar({"<start>": ["<x>"], "<y>": ["1"]})'<y>': defined, but not used
'<x>': used, but not defined
'<y>': unreachable from <start>assert not is_valid_grammar({"<start>": "123"})'<start>': expansion is not a listassert not is_valid_grammar({"<start>": []})'<start>': expansion list emptyassert not is_valid_grammar({"<start>": [1, 2, 3]})'<start>': 1: not a string(#type: 주석을 무시하면 위에 오류로 플래그가 표시되는 정적 체커를 피할 수 있습니다.
지금부터 우리는 문법을 정의할 때 항상 is_valid_grammar()를 사용할 것입니다.
Lessons Learned
- 문법은 구문적으로 유효한 입력을 표현하고 만들어내기 위한 강력한 도구입니다.
- 문법에서 생성된 입력은 그대로 사용하거나 mutation-based fuzzing의 seeds로 사용할 수 있습니다.
- 문법은 character classses와 연산자를 통해 확장되어 더 쉽게 작성될 수 있습니다.
[ The Fuzzing Book ]
Fuzzing with Grammars
