
Efficient Grammar Fuzzing
목차
- Synopsis
- Efficient Grammar Fuzzing
- Derivation Trees
- An Insufficient Algorithm
- Derivation Trees
- Representing Derivation Trees
- Expanding a Node
- Picking a Children Alternative to be Expanded
- Getting a List of Possible Expansions
- Putting Things Together
- Expanding a Tree
- Closing the Expansion
- Excursion: Implementing Cost Functions
- End of Excursion
- Node Inflation
- Three Expansion Phases
- Putting it all Together
- Synopsis
- Efficient Grammar Fuzzing
- Derivation Trees
- Lessons Learned
Synopsis
이 챕터에서 제공되는 코드를 사용하기 위해 추가하세요.
>>> from fuzzingbook.GrammarFuzzer import <identifier>다음 기능을 사용합니다.
Efficient Grammar Fuzzing
이 챕터는 문법을 사용하여 구문적으로 유효한 입력을 생성하는 효율적인 Grammar Fuzzer를 소개합니다.
>>> from Grammars import US_PHONE_GRAMMAR
>>> phone_fuzzer = GrammarFuzzer(US_PHONE_GRAMMAR)
>>> phone_fuzzer.fuzz()
'(519)333-4454'GrammarFuzzer 생성자는 동작을 제어하기 위해서 많은 키워드 인수들을 사용합니다.
예를 들어 start_symbol은 확장 시작 기호를 설정할 수 있게 해줍니다.
>>> area_fuzzer = GrammarFuzzer(US_PHONE_GRAMMAR, start_symbol='<area>')
>>> area_fuzzer.fuzz()
'718'GrammarFuzzer 생성자를 매개 변수화하는 방법은 다음과 같습니다.
Produce strings from `grammar`, starting with `start_symbol`.
If `min_nonterminals` or `max_nonterminals` is given, use them as limits
for the number of nonterminals produced.
If `disp` is set, display the intermediate derivation trees.
If `log` is set, show intermediate steps as text on standard output.
Derivation Trees
내부적으로, GrammarFuzzer는 단계별로 확장하는 derivation trees를 사용합니다. 문자열을 생성한 후, 생성된 트리는 derivation_tree 속성을 통해 접근할 수 있습니다.
>>> display_tree(phone_fuzzer.derivation_tree)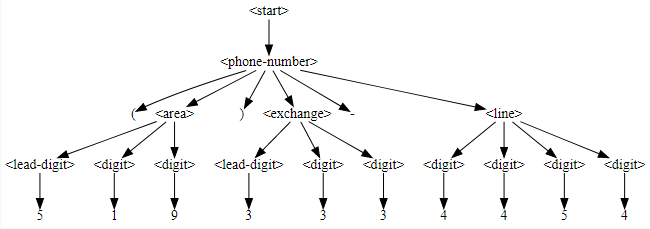
derivation tree의 내부 표현에서 노드는 쌍(기호, 자식)입니다. 비단말에서 기호는 확장중인 기호이고 하위 노드는 추가 노드의 목록입니다. 단말의 경우 기호는 단말 문자열이고 하위 문자열은 비어있습니다.
>>> phone_fuzzer.derivation_tree
('<start>',
[('<phone-number>',
[('(', []),
('<area>',
[('<lead-digit>', [('5', [])]),
('<digit>', [('1', [])]),
('<digit>', [('9', [])])]),
(')', []),
('<exchange>',
[('<lead-digit>', [('3', [])]),
('<digit>', [('3', [])]),
('<digit>', [('3', [])])]),
('-', []),
('<line>',
[('<digit>', [('4', [])]),
('<digit>', [('4', [])]),
('<digit>', [('5', [])]),
('<digit>', [('4', [])])])])])이 장에는 시각화 도구(특히 display_tree())를 포함하여 derivation trees에서 사용할 수 있는 다양한 도우미 함수가 포함되어 있습니다.
An Insufficient Algorithm
이전 장에서는 문법을 사용하여 구문적으로 유효한 문자열을 자동으로 생성하는 simple_grammar_fuzzer() 함수를 소개했습니다. 그러나 simple_grammar_fuzzer()는 이름 그대로 단순합니다. 문제를 설명하기 위해 chpater on grammars:에서 EXPR_GRAMMA_BNF에서 만든 expr_grammar로 돌아가 보겠습니다.
import bookutilsfrom bookutils import quizfrom typing import Tuple, List, Optional, Any, Union, Set, Callable, Dictfrom bookutils import unicode_escapefrom Grammars import EXPR_EBNF_GRAMMAR, convert_ebnf_grammar, Grammar, Expansion
from Grammars import simple_grammar_fuzzer, is_valid_grammar, exp_stringexpr_grammar = convert_ebnf_grammar(EXPR_EBNF_GRAMMAR)
expr_grammar{'<start>': ['<expr>'],
'<expr>': ['<term> + <expr>', '<term> - <expr>', '<term>'],
'<term>': ['<factor> * <term>', '<factor> / <term>', '<factor>'],
'<factor>': ['<sign-1><factor>', '(<expr>)', '<integer><symbol-1>'],
'<sign>': ['+', '-'],
'<integer>': ['<digit-1>'],
'<digit>': ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'],
'<symbol>': ['.<integer>'],
'<sign-1>': ['', '<sign>'],
'<symbol-1>': ['', '<symbol>'],
'<digit-1>': ['<digit>', '<digit><digit-1>']}expr_grammar에 흥미로운 속성이 있습니다. simple_grammar_fuzzer()에 입력을 주면 결과 값이 고정됩니다.
from ExpectError import ExpectTimeoutwith ExpectTimeout(1):
simple_grammar_fuzzer(grammar=expr_grammar, max_nonterminals=3)Traceback (most recent call last):
File "<ipython-input-11-fbcda5f486bb>", line 2, in <cell line: 1>
simple_grammar_fuzzer(grammar=expr_grammar, max_nonterminals=3)
File "/home/jovyan/docs/notebooks/Grammars.ipynb", line 97, in simple_grammar_fuzzer
if len(nonterminals(new_term)) < max_nonterminals:
File "/home/jovyan/docs/notebooks/Grammars.ipynb", line 61, in nonterminals
return RE_NONTERMINAL.findall(expansion)
File "/home/jovyan/docs/notebooks/Timeout.ipynb", line 43, in timeout_handler
raise TimeoutError()
TimeoutError (expected)왜 그럴까요? 문법을 보세요. 여러분이 simple_fuzzer에 대해 알고 있는 것을 기억하세요. 그리고 expansion을 보려면 log=true를 인수로 simple_grammar_fuzer()를 실행하세요.
Quiz
왜 simple_grammar_fuzzer()가 문제가 될까요?
- 무한히 많은 추가가 발생해서
- 무한 자릿수를 생성해서
- 무한히 많은 괄호를 생성해서
- 무한한 수의 부호를 만들어내서
문제는 이 규칙에 있습니다:
expr_grammar['<factor>']['<sign-1><factor>', '(<expr>)', '<integer><symbol-1>']여기서 (expr)을 제외한 모든 선택사항은 일시적인 경우에도 기호 수를 증가시킵니다. 확장할 기호 수에 엄격한 제한을 두기 때문에, <factor>를 확장할 수 있는 유일한 선택은 (<expr>)이며, 이는 괄호를 무한히 추가하는 결과로 이어집니다.
...((((((((...expr...))))))))...잠재적으로 무한 확장의 문제는 simple_grammar_fuzzer()의 여러 문제 중 하나일 뿐입니다. 더 많은 문제는 다음과 같습니다.
- 비효율적입니다. 매번 동작을 반복할 때마다, 기호를 확장하기 위해 지금까지 생성한 문자열을 검색합니다. 이것은 생성한 문자열의 길이가 길어질수록 더욱 더 비효율적이게 됩니다.
- 통제하기 힘듭니다. 기호 수를 제한하더라도 매우 긴 문자열, 심지어 위에서 설명한 무한히 긴 문자열을 얻을 수 있습니다.
길이에 따른 문자열 생성 시간을 그래프로 표시하여 위 두가지 문제를 설명해보겠습니다.
from Grammars import simple_grammar_fuzzerfrom Grammars import START_SYMBOL, EXPR_GRAMMAR, URL_GRAMMAR, CGI_GRAMMARfrom Grammars import RE_NONTERMINAL, nonterminals, is_nonterminalfrom Timer import Timertrials = 50
xs = []
ys = []
for i in range(trials):
with Timer() as t:
s = simple_grammar_fuzzer(EXPR_GRAMMAR, max_nonterminals=15)
xs.append(len(s))
ys.append(t.elapsed_time())
print(i, end=" ")
print()0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 average_time = sum(ys) / trials
print("Average time:", average_time)Average time: 0.20005843754%matplotlib inline
import matplotlib.pyplot as plt
plt.scatter(xs, ys)
plt.title('Time required for generating an output');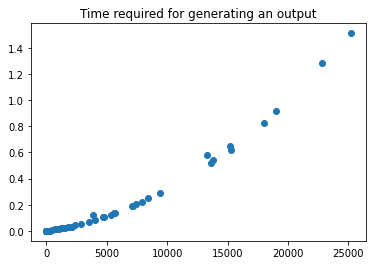
우리는 (1) 출력을 생성하는 데 필요한 시간이 해당 출력의 길이에 따라 제곱으로 증가하고 (2) 생성된 출력의 많은 부분의 길이가 수만자라는 것을 알 수 있습니다.
이러한 문제를 해결하기 위해서 보다 더 스마트한 알고리즘이 필요합니다. 즉 더 효율적이며, 확장을 더 잘 제어할 수 있고 expr_grammar에서 무한 확장이 잠재적으로 발생하는 것을 예측할 수 있는 알고리즘이 필요합니다.
Derivation Trees
더 효율적인 알고리즘을 얻고 expansions에 대한 더 좋은 제어를 하기 위해, 우리는 우리의 문법이 생성하는 문자열에 특별한 표현을 사용할 것입니다. 일반적인 아이디어는 나중에 확장될 트리 구조인 소위 derivation tree를 사용하는 것입니다. 이러한 표현을 통해 우리는 항상 확장 상태를 추적할 수 있으며, 어떤 요소가 어떤 요소로 확장되었는지, 어떤 기호를 여전히 확장해야 하는지 등의 질문에 답할 수 있습니다. 또한 트리에 새 요소를 추가하는 것이 문자열을 반복적으로 교체하는 것보다 훨씬 효율적입니다.
프로그래밍에 사용되는 다른 트리와 마찬가지로 derivation tree(파스 트리 또는 구체적인 구문 트리라고도 함)는 다른 노드(자녀 노드라고 함)를 자식 노드로 갖는 노드로 구성됩니다. 트리는 상위 노드가 없는 노드 하나로 시작됩니다. 이를 루트 노드라고 하며 하위 노드가 없는 노드를 리프라고 합니다.
derivation trees와 함께 문법 확장 프로세스는 다음 단계에서 설명됩니다. 트리의 루트 로서 단일 노드를 시작하여 시작 기호를 나타냅니다 (이 경우 <start>.

트리를 확장하기 위해, 우리는 자식이 없는 비말단 기호 S를 검색하면서 트리를 순회합니다. 따라서 S는 여전히 확장되어야 하는 기호입니다. 그런 다음 문법에서 S의 확장 기호를 선택했습니다. 그런 다음 S의 새로운 자식으로 선택한 확장 기호를 추가합니다. 시작 기호 <start>의 경우 확장자는 <expr>뿐이므로 자식으로 추가합니다.

derivation tree에서 생성된 문자열을 구성하기 위해, 우리는 트리를 순서대로 순회하고 트리의 리프에 있는 기호를 수집합니다. 위의 경우 문자열 "<expr>"을 얻습니다.
트리를 더욱 확장하기 위해 확장할 다른 기호를 선택하고 확장을 자식으로 추가합니다. 이렇게 하면 <expr>기호를 얻을 수 있는데, 이 기호는 <expr> + <term>로 확장되어 세개의 자식을 더하게 됩니다.

확장할 기호가 남아 있지 않을 때까지 확장을 반복합니다.

이제 문자열 2 + 2에 대한 표현이 있습니다. 그러나 문자열과 달리 derivation tree는 생성된 문자열의 전체 구조(및 생산 이력 또는 파생 이력)를 기록합니다. 또한 하나의 하위 트리(하위 구조)를 다른 하위 트리(하위 구조)와 교체하는 등 간단한 비교와 조작이 가능합니다.
Representing Derivation Trees
파이썬에서 derivation tree를 표현하기 위해 다음 형식을 사용합니다. 노드는 쌍입니다.
(SYMBOL_NAME, CHILDREN)여기서 SYMBOL_NAME은 노드를 나타내는 문자열(예: "<start>" 또는 "+")이고 CHILDEN은 하위 노드의 목록입니다.
CHILDREN은 다음과 같은 특별한 값을 가질 수 있습니다:
- 향후 확장을 위한 자리 표시자가 없습니다. 즉, 노드가 비단말기 기호이므로 더 확장해야 합니다.
- [] (즉, 빈 리스트)는 자식이 없음을 나타냅니다. 이는 노드가 더 이상 확장할 수 없는 단말 기호라는 것을 의미합니다.
DerivationTree 타입은 바로 이 구조를 가집니다.
DerivationTree = Tuple[str, Optional[List[Any]]]위의 중간 단계 <expr> + <term> 을 나타내는 매우 간단한 derivation tree를 살펴보자.
derivation_tree: DerivationTree = ("<start>",
[("<expr>",
[("<expr>", None),
(" + ", []),
("<term>", None)]
)])이 트리의 구조를 더 잘 이해하기 위해 트리를 시각화하는 display_tree() 함수를 소개하겠습니다.
Excursion: Implementing display_tree()
우리는 위의 구조를 가로질러 graphviz 패키지의 도트 그리기 프로그램을 알고리즘으로 사용합니다. 트리 시각화에 관심이 없는 경우 아래 예제로 바로 건너뛸 수 있습니다.
from graphviz import Digraphfrom IPython.display import displayimport redef dot_escape(s: str) -> str:
"""Return s in a form suitable for dot"""
s = s.replace('\n', '\\n')
s = re.sub(r'([^a-zA-Z0-9" ])', r"\\\1", s)
return sassert dot_escape("hello") == "hello"
assert dot_escape("<hello>, world") == "\\<hello\\>\\, world"
assert dot_escape("\\n") == "\\\\n"
assert dot_escape("\n") == "\\\\n"현재 deliversation_tree를 시각화하는 데 관심이 있는데, 시각화 절차를 일반화하는 것이 좋습니다. 특히, display_tree() 메서드가 트리 같은 데이터 구조를 표시할 수 있다면 도움이 될 것입니다. 이를 가능하게 하기 위해 주어진 데이터 구조에서 현재 기호와 자식 기호를 추출하는 도우미 메서드 extract_node()를 정의합니다. 기본 구현에서는 deliversation_tree 노드에서 기호, 자식 및 주석을 추출하기만 하면 됩니다.
def extract_node(node, id):
symbol, children, *annotation = node
return symbol, children, ''.join(str(a) for a in annotation)트리를 시각화하는 동안 특정 노드를 다르게 표시하는 것이 유용할 수 있습니다. 예를 들어 처리되지 않은 노드와 처리된 노드를 구분하는 것이 유용할 수 있습니다. 기본 디스플레이를 제공하는 도우미 프로시저 default_node_attr()을 정의하며, 이는 사용자가 커스텀 마이징할 수 있습니다.
def default_node_attr(dot, nid, symbol, ann):
dot.node(repr(nid), dot_escape(unicode_escape(symbol)))노드와 마찬가지로 엣지도 수정해야 할 수 있습니다. default_edge_attr()을 사용자가 커스텀 마이징할 수 있는 도우미 프로시저로 정의합니다.
def default_edge_attr(dot, start_node, stop_node):
dot.edge(repr(start_node), repr(stop_node))트리를 시각화하는 동안 때때로 트리의 모양을 변경하고자 할 수 있습니다. 예를 들어, 트리를 위에서 아래로 배치하는 것보다 왼쪽에서 오른쪽으로 배치하는 것이 더 쉽게 볼 수 있습니다. 이를 위해 다른 도우미 프로시저 default_graph_attr()을 정의합니다.
def default_graph_attr(dot):
dot.attr('node', shape='plain')마지막으로, 우리는 이러한 네 가지 함수 extract_node(), default_edge_attr(), default_node_attr() 및 default_graph_attr()을 사용해서 트리를 시각화하는 데 사용하는 메서드 display_tree()를 정의합니다.
def display_tree(derivation_tree: DerivationTree,
log: bool = False,
extract_node: Callable = extract_node,
node_attr: Callable = default_node_attr,
edge_attr: Callable = default_edge_attr,
graph_attr: Callable = default_graph_attr) -> Any:
# If we import display_tree, we also have to import its functions
from graphviz import Digraph
counter = 0
def traverse_tree(dot, tree, id=0):
(symbol, children, annotation) = extract_node(tree, id)
node_attr(dot, id, symbol, annotation)
if children:
for child in children:
nonlocal counter
counter += 1
child_id = counter
edge_attr(dot, id, child_id)
traverse_tree(dot, child, child_id)
dot = Digraph(comment="Derivation Tree")
graph_attr(dot)
traverse_tree(dot, derivation_tree)
if log:
print(dot)
return dotEnd of Excursion
트리는 다음과 같이 시각화합니다.
display_tree(derivation_tree)
Quiz
다음 중 derivation_tree의 내부 표현은 무엇입니까?
- ('<start>', [('<expr>', (['<expr> + <term>']))])
- ('<start>', [('<expr>', (['<expr>', ' + ', <term>']))])
- ('<start>', [('<expr>', [('<expr>', None), (' + ', []), ('<term>', None)])])
- (('<start>', [('<expr>', [('<expr>', None), (' + ', []), ('<term>', None)])]), None)
직접 확인할 수 있습니다.
derivation_tree('<start>', [('<expr>', [('<expr>', None), (' + ', []), ('<term>', None)])])이 책에서는 개별 노드에 주석을 추가할 수 있는 display_annotated_tree() 함수를 가끔 사용합니다.
Excursion: Source code and example for display_annotated_tree()
display_annotated_tree()는 주석이 달린 트리 구조를 표시하고 그래프를 왼쪽에서 오른쪽으로 표시합니다.
def display_annotated_tree(tree: DerivationTree,
a_nodes: Dict[int, str],
a_edges: Dict[Tuple[int, int], str],
log: bool = False):
def graph_attr(dot):
dot.attr('node', shape='plain')
dot.graph_attr['rankdir'] = 'LR'
def annotate_node(dot, nid, symbol, ann):
if nid in a_nodes:
dot.node(repr(nid),
"%s (%s)" % (dot_escape(unicode_escape(symbol)),
a_nodes[nid]))
else:
dot.node(repr(nid), dot_escape(unicode_escape(symbol)))
def annotate_edge(dot, start_node, stop_node):
if (start_node, stop_node) in a_edges:
dot.edge(repr(start_node), repr(stop_node),
a_edges[(start_node, stop_node)])
else:
dot.edge(repr(start_node), repr(stop_node))
return display_tree(tree, log=log,
node_attr=annotate_node,
edge_attr=annotate_edge,
graph_attr=graph_attr)display_annotated_tree(derivation_tree, {3: 'plus'}, {(1, 3): 'op'}, log=False)
End of Excursion
트리의 모든 리프 노드를 문자열로 보려면 다음과 같은 all_terminals() 함수가 유용합니다.
def all_terminals(tree: DerivationTree) -> str:
(symbol, children) = tree
if children is None:
# This is a nonterminal symbol not expanded yet
return symbol
if len(children) == 0:
# This is a terminal symbol
return symbol
# This is an expanded symbol:
# Concatenate all terminal symbols from all children
return ''.join([all_terminals(c) for c in children])all_terminals(derivation_tree)'<expr> + <term>'tree_to_string() 함수도 트리를 문자열로 변환하지만, 비말단 기호를 빈 문자열로 대체합니다.
def tree_to_string(tree: DerivationTree) -> str:
symbol, children, *_ = tree
if children:
return ''.join(tree_to_string(c) for c in children)
else:
return '' if is_nonterminal(symbol) else symboltree_to_string(derivation_tree)' + 'Expanding a Node
이제 확장되지 않은 기호(예를 들어, 위의 deliversation_tree)를 가진 트리를 가져와서 이 모든 기호를 차례로 확장하는 알고리즘을 개발하겠습니다. 이전의 퍼저와 마찬가지로, 우리는 Fuzzer의 특별한 하위 클래스인 Grammar Fuzer를 만듭니다. GrammarFuzer는 문법과 시작 기호를 얻습니다. 다른 매개 변수는 나중에 생성을 제어하고 디버깅을 지원하는 데 사용됩니다.
from Fuzzer import Fuzzerclass GrammarFuzzer(Fuzzer):
"""Produce strings from grammars efficiently, using derivation trees."""
def __init__(self,
grammar: Grammar,
start_symbol: str = START_SYMBOL,
min_nonterminals: int = 0,
max_nonterminals: int = 10,
disp: bool = False,
log: Union[bool, int] = False) -> None:
"""Produce strings from `grammar`, starting with `start_symbol`.
If `min_nonterminals` or `max_nonterminals` is given, use them as limits
for the number of nonterminals produced.
If `disp` is set, display the intermediate derivation trees.
If `log` is set, show intermediate steps as text on standard output."""
self.grammar = grammar
self.start_symbol = start_symbol
self.min_nonterminals = min_nonterminals
self.max_nonterminals = max_nonterminals
self.disp = disp
self.log = log
self.check_grammar() # Invokes is_valid_grammar()GrammarFuzer에 메서드를 추가하기 위해서 MutationFuzer class에 이미 도입된 hack을 사용할 수 있습니다. 생성자
class GrammarFuzzer(GrammarFuzzer):
def new_method(self, args):
pass새로운 메서드 new_method()를 GrammarFuzer class에 추가할 수 있습니다. (사실, 우리는 이전 것을 확장하는 새로운 Grammar Fuzer class를 얻지만, 우리의 모든 목적을 위해, 이것은 문제가 되지 않습니다.)
Excursion: check_grammar() implementation
위의 hack을 사용하여 주어진 문법의 일관성을 검사하는 도우미 메서드 check_grammar()를 정의할 수 있습니다.
class GrammarFuzzer(GrammarFuzzer):
def check_grammar(self) -> None:
"""Check the grammar passed"""
assert self.start_symbol in self.grammar
assert is_valid_grammar(
self.grammar,
start_symbol=self.start_symbol,
supported_opts=self.supported_opts())
def supported_opts(self) -> Set[str]:
"""Set of supported options. To be overloaded in subclasses."""
return set() # We don't support specific optionsEnd of Excursion
이제 시작 기호만으로 트리를 구성하는 도우미 메서드 init_tree()를 정의하겠습니다.
class GrammarFuzzer(GrammarFuzzer):
def init_tree(self) -> DerivationTree:
return (self.start_symbol, None)f = GrammarFuzzer(EXPR_GRAMMAR)
display_tree(f.init_tree())<start>이것이 우리가 확장하고자 하는 트리입니다.
Picking a Children Alternative to be Expanded
GrammarFuzer의 중심 메서드 중 하나는 choice_node_expansion()입니다. 이 메서드는 노드(예: <start> 노드 및 확장 가능한 모든 자식 목록)를 가져오고, 그 중 하나를 선택한 다음 가능한 자식 목록에 인덱스를 반환합니다.
이 메서드를 오버로딩하면(특히 나중의 장에서), 우리는 다른 전략을 구현할 수 있습니다. 현재로서는 단순히 주어진 자식 목록 중 하나를 무작위로 선택하기만 하면 됩니다.
class GrammarFuzzer(GrammarFuzzer):
def choose_node_expansion(self, node: DerivationTree,
children_alternatives: List[List[DerivationTree]]) -> int:
"""Return index of expansion in `children_alternatives` to be selected.
'children_alternatives`: a list of possible children for `node`.
Defaults to random. To be overloaded in subclasses."""
return random.randrange(0, len(children_alternatives))Getting a List of Possible Expansions
가능한 자식 목록을 실제로 얻으려면 확장 문자열을 가져와서 문자열의 각 기호(단자 또는 비단자)에 대해 하나씩 derivation trees 목록으로 분해하는 도우미 함수 expansion_to_children()이 필요합니다.
Excursion: Implementing expansion_to_children()
expansion_to_children() 함수는 re.split() 메서드를 사용하여 확장 문자열을 하위 노드 목록으로 분할합니다.
def expansion_to_children(expansion: Expansion) -> List[DerivationTree]:
# print("Converting " + repr(expansion))
# strings contains all substrings -- both terminals and nonterminals such
# that ''.join(strings) == expansion
expansion = exp_string(expansion)
assert isinstance(expansion, str)
if expansion == "": # Special case: epsilon expansion
return [("", [])]
strings = re.split(RE_NONTERMINAL, expansion)
return [(s, None) if is_nonterminal(s) else (s, [])
for s in strings if len(s) > 0]End of Excursion
expansion_to_children("<term> + <expr>")[('<term>', None), (' + ', []), ('<expr>', None)]epsilon expansion의 경우 <symbol> ::= 와 같이 빈 문자열로 확장해야 합니다.
expansion_to_children("")[('', [])]Grammars 챕터에서 nonterminal()과 마찬가지로 향후 확장에 대해 제공하므로 확장에 추가 데이터가 포함된 튜플(무시됨)이 될 수 있습니다.
expansion_to_children(("+<term>", {"extra_data": 1234}))[('+', []), ('<term>', None)]우리는 이 도우미를 GrammarFuzer의 한 메서드로 구현하여 하위 클래스에서 오버로드할 수 있습니다.
class GrammarFuzzer(GrammarFuzzer):
def expansion_to_children(self, expansion: Expansion) -> List[DerivationTree]:
return expansion_to_children(expansion)Putting Things Together
- 트리의 확장되지 않은 노드
- 랜덤 확장 선택
- 새로운 트리 반환
expand_node_company 메서드가 수행하는 작업입니다.
Excursion: expand_node_randomly() implementation
expand_node_randomly() 함수는 도우미 함수 choose_node_expansion()을 사용하여 가능한 자식 배열에서 인덱스를 임의로 선택합니다. (choose_node_expansion()은 하위 클래스에서 오버로드될 수 있습니다.)
import randomclass GrammarFuzzer(GrammarFuzzer):
def expand_node_randomly(self, node: DerivationTree) -> DerivationTree:
"""Choose a random expansion for `node` and return it"""
(symbol, children) = node
assert children is None
if self.log:
print("Expanding", all_terminals(node), "randomly")
# Fetch the possible expansions from grammar...
expansions = self.grammar[symbol]
children_alternatives: List[List[DerivationTree]] = [
self.expansion_to_children(expansion) for expansion in expansions
]
# ... and select a random expansion
index = self.choose_node_expansion(node, children_alternatives)
chosen_children = children_alternatives[index]
# Process children (for subclasses)
chosen_children = self.process_chosen_children(chosen_children,
expansions[index])
# Return with new children
return (symbol, chosen_children)일반 expand_node() 메서드는 나중에 다른 확장 전략을 선택하는 데 사용할 수 있습니다. 현재로서는 expand_node_randomly()만 사용합니다.
class GrammarFuzzer(GrammarFuzzer):
def expand_node(self, node: DerivationTree) -> DerivationTree:
return self.expand_node_randomly(node)도우미 함수 process_chosen_children()은 아무 작업도 하지 않으며, 하위 클래스에 의해 오버로드되면 자식중에 하나를 선택해서 처리할 수 있습니다.
class GrammarFuzzer(GrammarFuzzer):
def process_chosen_children(self,
chosen_children: List[DerivationTree],
expansion: Expansion) -> List[DerivationTree]:
"""Process children after selection. By default, does nothing."""
return chosen_childrenEnd of Excursion
expand_node_randomly()는 다음과 같이 동작합니다.
f = GrammarFuzzer(EXPR_GRAMMAR, log=True)
print("Before expand_node_randomly():")
expr_tree = ("<integer>", None)
display_tree(expr_tree)
print("After expand_node_randomly():")
expr_tree = f.expand_node_randomly(expr_tree)
display_tree(expr_tree)
# docassert
assert expr_tree[1][0][0] == '<digit>'quiz("What tree do we get if we expand the `<digit>` subtree?",
[
"We get another `<digit>` as new child of `<digit>`",
"We get some digit as child of `<digit>`",
"We get another `<digit>` as second child of `<integer>`",
"The entire tree becomes a single node with a digit"
], 'len("2") + len("2")')Quiz
<digit> 서브 트리를 확장하면 어떤 트리를 얻을 수 있습니까?
- <digit>의 새로운 자식으로 또 다른 <digit>을 얻습니다.
- <digit>의 자식으로써 숫자를 얻습니다.
- <integer>의 두번째 자식으로 또 다른 <digit>을 얻습니다.
- 전체 트리가 숫자가 있는 단일 노드가 됩니다.
우리는 확실히 이것을 시험해 볼 수 있습니다.
digit_subtree = expr_tree[1][0] # type: ignore
display_tree(digit_subtree)<digit>print("After expanding the <digit> subtree:")
digit_subtree = f.expand_node_randomly(digit_subtree)
display_tree(digit_subtree)
우리는 <digit>이 한 자리 숫자로 다시 확장되는 것을 볼 수 있습니다.
Quiz
original expr_tree가 이 변경 사항의 영향을 받습니까?
- 네 새 자식을 얻습니다.
- 아니요 변하지 않습니다.
하위 트리 중 하나를 변경했지만 original expr_tree는 영향을 받지 않습니다.
display_tree(expr_tree)
그 이유는 expand_node_randomly()가 새(확장) 트리를 반환하고 인수로 전달된 트리를 변경하지 않기 때문입니다.
Expanding a Tree
이제 단일 노드를 트리의 일부 노드로 확장하는 기능을 적용하겠습니다. 이를 위해 먼저 트리에서 확장되지 않은 노드를 검색해야 합니다. possible_expansions()는 트리에 확장되지 않은 기호가 몇 개 있는지 카운트합니다.
class GrammarFuzzer(GrammarFuzzer):
def possible_expansions(self, node: DerivationTree) -> int:
(symbol, children) = node
if children is None:
return 1
return sum(self.possible_expansions(c) for c in children)f = GrammarFuzzer(EXPR_GRAMMAR)
print(f.possible_expansions(derivation_tree))2any_possible_expansions() 메서드는 트리에 확장되지 않은 노드가 있으면 True를 반환합니다.
class GrammarFuzzer(GrammarFuzzer):
def any_possible_expansions(self, node: DerivationTree) -> bool:
(symbol, children) = node
if children is None:
return True
return any(self.any_possible_expansions(c) for c in children)f = GrammarFuzzer(EXPR_GRAMMAR)
f.any_possible_expansions(derivation_tree)True여기 우리 트리 확장 알고리즘의 핵심 메서드인 expand_tree_once()가 있습니다. 먼저 확장이 없는 비단말 기호가 존재하는지 체크합니다. 존재한다면 위에서 설명한 대로 expand_node()를 호출합니다.
노드가 이미 확장되어 있는 경우(즉, 하위 노드가 있는 경우) 확장되지 않은 기호가 여전히 있는 하위 집합을 확인하고, 그 중 하나를 무작위로 선택한 다음 해당 하위 노드에 재귀적으로 적용합니다.
Excursion: expand_tree_once() implementation
expand_tree_once() 메서드는 자식을 대체합니다. 즉, 새 트리를 반환하지 않고 인수로 전달되는 트리를 실제로 변환합니다. 이러한 내부 변환은 이 기능을 특히 효율적으로 만듭니다. 다시, 우리는 확장 가능한 자식 목록에서 선택된 인덱스를 반환하기 위해 도우미 메서드(choose_tree_expansion())을 사용합니다.
class GrammarFuzzer(GrammarFuzzer):
def choose_tree_expansion(self,
tree: DerivationTree,
children: List[DerivationTree]) -> int:
"""Return index of subtree in `children` to be selected for expansion.
Defaults to random."""
return random.randrange(0, len(children))
def expand_tree_once(self, tree: DerivationTree) -> DerivationTree:
"""Choose an unexpanded symbol in tree; expand it.
Can be overloaded in subclasses."""
(symbol, children) = tree
if children is None:
# Expand this node
return self.expand_node(tree)
# Find all children with possible expansions
expandable_children = [
c for c in children if self.any_possible_expansions(c)]
# `index_map` translates an index in `expandable_children`
# back into the original index in `children`
index_map = [i for (i, c) in enumerate(children)
if c in expandable_children]
# Select a random child
child_to_be_expanded = \
self.choose_tree_expansion(tree, expandable_children)
# Expand in place
children[index_map[child_to_be_expanded]] = \
self.expand_tree_once(expandable_children[child_to_be_expanded])
return treeEnd of Excursion
expand_tree_once()의 작동 방식을 설명하겠습니다. 우리는 위에서부터 파생된 트리부터 시작합니다...
derivation_tree = ("<start>",
[("<expr>",
[("<expr>", None),
(" + ", []),
("<term>", None)]
)])
display_tree(derivation_tree)
... 이제 두 번 확장합니다.
f = GrammarFuzzer(EXPR_GRAMMAR, log=True)
derivation_tree = f.expand_tree_once(derivation_tree)
display_tree(derivation_tree)
derivation_tree = f.expand_tree_once(derivation_tree)
display_tree(derivation_tree)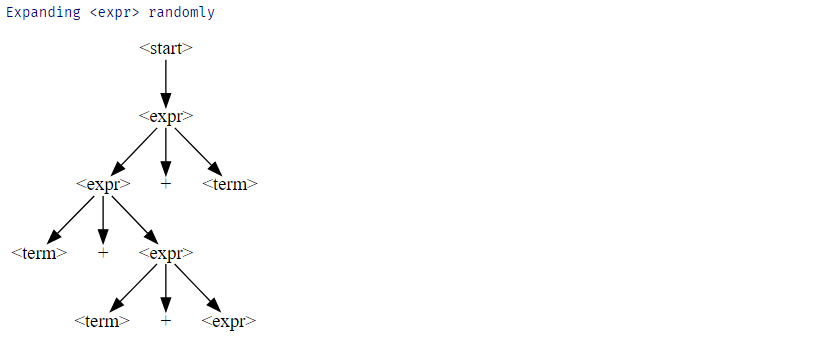
각 단계마다 하나의 기호가 더 확장되는 것을 볼 수 있습니다. 이제, 트리를 점점 더 확장하면서, 이것을 계속해서 적용하기만 하면 됩니다.
Closing the Expansion
expand_tree_once()를 사용하면 트리를 계속 확장할 수 있습니다. 하지만 어떻게 멈출까요? Luke가 [Luke et al, 2000]에서 소개한 핵심 아이디어는 derivation tree를 최대 크기로 부풀린(가로) 후 트리 크기를 최소로 늘리는(세로) 확장만 적용하자 입니다. 예를 들어, <factor>의 경우, 더 이상의 재귀(와 잠재적 크기 팽창)를 유발하지 않기 때문에 <integer>로의 확장을 선호합니다. 마찬가지로, <integer>의 경우 트리 크기가 <digit><integer>보다 적게 증가하기 때문에 <digit>으로의 확장을 선호합니다.
기호를 확장하는 비용을 식별하기 위해서, 우리는 서로 상호 의존하는 두 가지 함수를 소개합니다.
- symbol_cost()는 기호의 모든 확장에 대한 최소 비용을 반환하며, expansion_cost()를 사용하여 각 확장에 대한 비용을 계산합니다.
- expansion_cost()는 모든 확장의 합계를 반환합니다. 순회 중에 비단말이 나올 경우 확장 비용은 ∞,이며, 이는 재귀(잠재적으로 무한)를 나타냅니다.
Excursion: Implementing Cost Functions
class GrammarFuzzer(GrammarFuzzer):
def symbol_cost(self, symbol: str, seen: Set[str] = set()) \
-> Union[int, float]:
expansions = self.grammar[symbol]
return min(self.expansion_cost(e, seen | {symbol}) for e in expansions)
def expansion_cost(self, expansion: Expansion,
seen: Set[str] = set()) -> Union[int, float]:
symbols = nonterminals(expansion)
if len(symbols) == 0:
return 1 # no symbol
if any(s in seen for s in symbols):
return float('inf')
# the value of a expansion is the sum of all expandable variables
# inside + 1
return sum(self.symbol_cost(s, seen) for s in symbols) + 1End of Excursion
다음은 두 가지 예입니다. 한 자리수 확장에서 우리는 반드시 한개는 선택해야 하기 때문에, 최소 확장 비용은 1입니다.
f = GrammarFuzzer(EXPR_GRAMMAR)
assert f.symbol_cost("<digit>") == 1그러나 <expr> 확장의 최소 비용은 5이며, 이는 필요한 확장의 최소 개수이기 때문입니다.
(<expr> → <term> → <factor> → <integer> → <digit> → 1)
assert f.symbol_cost("<expr>") == 5위의 비용을 고려하여 expand_node()의 변형인 expand_node_by_cost(self, node, choice)를 정의합니다. 모든 자식의 최소 비용 비용을 결정한 다음 choose() 함수를 사용하여 리스트에서 자식을 선택합니다. 이것은 기본적으로 최소 비용입니다. 여러 명의 아이들이 모두 동일한 최소 비용을 가질 경우, 이 중에서 랜덤으로 선택합니다.
Excursion: expand_node_by_cost() implementation
class GrammarFuzzer(GrammarFuzzer):
def expand_node_by_cost(self, node: DerivationTree,
choose: Callable = min) -> DerivationTree:
(symbol, children) = node
assert children is None
# Fetch the possible expansions from grammar...
expansions = self.grammar[symbol]
children_alternatives_with_cost = [(self.expansion_to_children(expansion),
self.expansion_cost(expansion, {symbol}),
expansion)
for expansion in expansions]
costs = [cost for (child, cost, expansion)
in children_alternatives_with_cost]
chosen_cost = choose(costs)
children_with_chosen_cost = [child for (child, child_cost, _)
in children_alternatives_with_cost
if child_cost == chosen_cost]
expansion_with_chosen_cost = [expansion for (_, child_cost, expansion)
in children_alternatives_with_cost
if child_cost == chosen_cost]
index = self.choose_node_expansion(node, children_with_chosen_cost)
chosen_children = children_with_chosen_cost[index]
chosen_expansion = expansion_with_chosen_cost[index]
chosen_children = self.process_chosen_children(
chosen_children, chosen_expansion)
# Return with a new list
return (symbol, chosen_children)End of Excursion
shortcut expand_node_min_cost()는 min()을 choose() 함수로 전달하므로 최소 비용으로 노드를 확장할 수 있습니다.
class GrammarFuzzer(GrammarFuzzer):
def expand_node_min_cost(self, node: DerivationTree) -> DerivationTree:
if self.log:
print("Expanding", all_terminals(node), "at minimum cost")
return self.expand_node_by_cost(node, min)이제 위의 expand_node_min_cost()를 확장 함수로 사용하여 derivation tree의 확장을 멈추는데 이 함수를 적용할 수 있습니다.
class GrammarFuzzer(GrammarFuzzer):
def expand_node(self, node: DerivationTree) -> DerivationTree:
return self.expand_node_min_cost(node)f = GrammarFuzzer(EXPR_GRAMMAR, log=True)
display_tree(derivation_tree)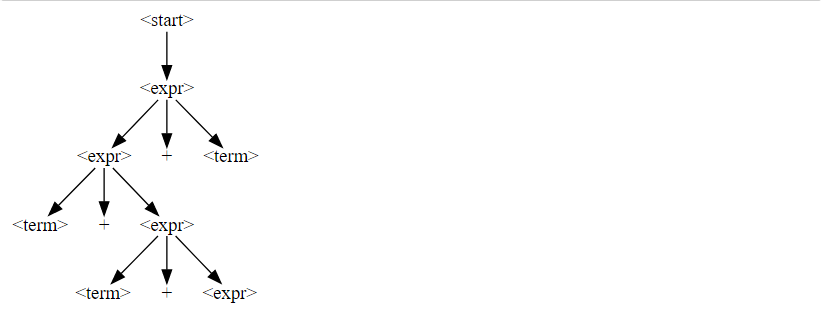
# docassert
assert f.any_possible_expansions(derivation_tree)if f.any_possible_expansions(derivation_tree):
derivation_tree = f.expand_tree_once(derivation_tree)
display_tree(derivation_tree)
# docassert
assert f.any_possible_expansions(derivation_tree)if f.any_possible_expansions(derivation_tree):
derivation_tree = f.expand_tree_once(derivation_tree)
display_tree(derivation_tree)
# docassert
assert f.any_possible_expansions(derivation_tree)if f.any_possible_expansions(derivation_tree):
derivation_tree = f.expand_tree_once(derivation_tree)
display_tree(derivation_tree)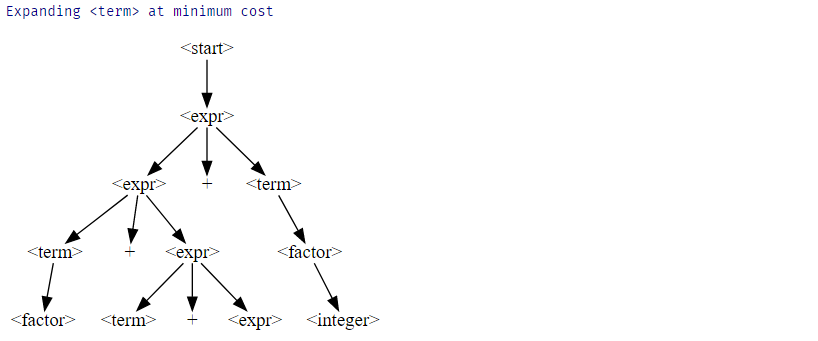
우리는 모든 비단말이 확장될 때 까지 계속 확장할 것입니다.
while f.any_possible_expansions(derivation_tree):
derivation_tree = f.expand_tree_once(derivation_tree) Expanding <integer> at minimum cost
Expanding <digit> at minimum cost
Expanding <factor> at minimum cost
Expanding <integer> at minimum cost
Expanding <digit> at minimum cost
Expanding <expr> at minimum cost
Expanding <term> at minimum cost
Expanding <term> at minimum cost
Expanding <factor> at minimum cost
Expanding <factor> at minimum cost
Expanding <integer> at minimum cost
Expanding <digit> at minimum cost
Expanding <integer> at minimum cost
Expanding <digit> at minimum cost최종 트리입니다.
display_tree(derivation_tree)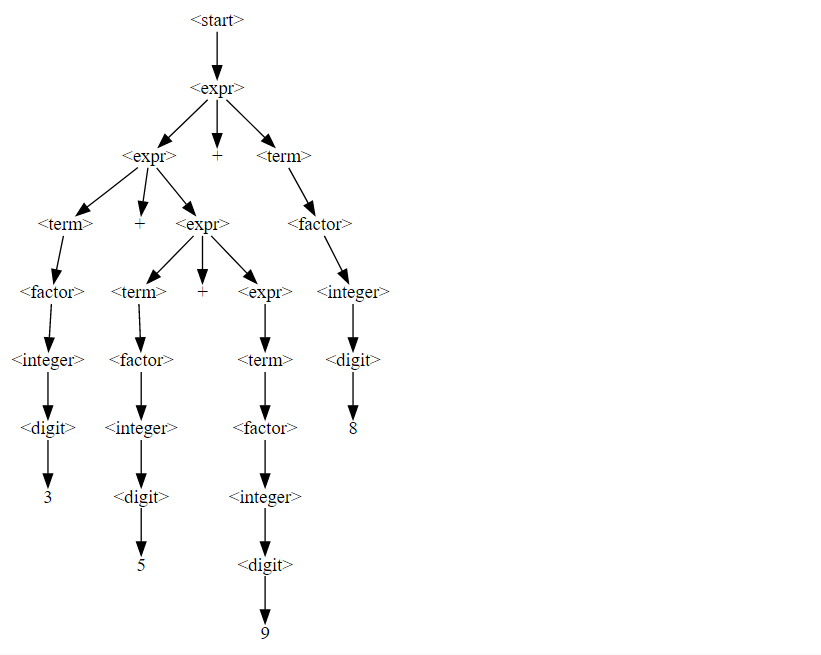
우리는 각 단계에서 expand_node_min_cost()가 기호수를 늘리지 않는 확장을 선택하여 결국 모든 열린 확장을 닫는것을 볼 수 있습니다.
Node Inflation
특히 확장을 시작할 때는 가능한 한 많은 노드를 확보하는 데 관심이 있을 수 있습니다. 즉, 확장할 수 있는 비단말을 더 많이 제공하는 확장을 선호합니다. 이는 실제로 expand_node_min_cost()가 제공하는 것과 정반대이며, 비용이 가장 높은 노드 중에서 항상 선택하는 expand_node_max_cost() 메서드를 구현할 수 있습니다.
class GrammarFuzzer(GrammarFuzzer):
def expand_node_max_cost(self, node: DerivationTree) -> DerivationTree:
if self.log:
print("Expanding", all_terminals(node), "at maximum cost")
return self.expand_node_by_cost(node, max)expand_node_max_cost()를 설명하기 위해 expand_node()를 다시 재정의하고 expand_tree_once()를 사용하여 몇 가지 확장 단계를 보여 줍니다.
class GrammarFuzzer(GrammarFuzzer):
def expand_node(self, node: DerivationTree) -> DerivationTree:
return self.expand_node_max_cost(node)derivation_tree = ("<start>",
[("<expr>",
[("<expr>", None),
(" + ", []),
("<term>", None)]
)])f = GrammarFuzzer(EXPR_GRAMMAR, log=True)
display_tree(derivation_tree)
# docassert
assert f.any_possible_expansions(derivation_tree)if f.any_possible_expansions(derivation_tree):
derivation_tree = f.expand_tree_once(derivation_tree)
display_tree(derivation_tree)
# docassert
assert f.any_possible_expansions(derivation_tree)if f.any_possible_expansions(derivation_tree):
derivation_tree = f.expand_tree_once(derivation_tree)
display_tree(derivation_tree)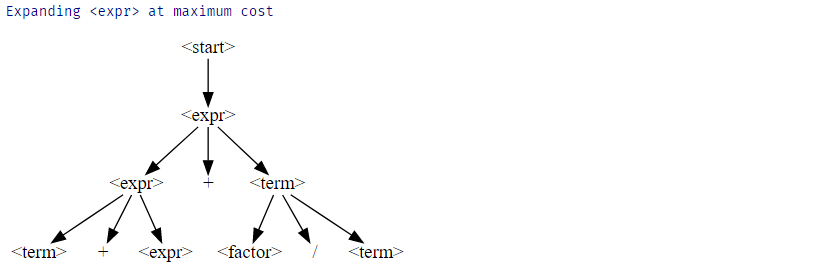
# docassert
assert f.any_possible_expansions(derivation_tree)if f.any_possible_expansions(derivation_tree):
derivation_tree = f.expand_tree_once(derivation_tree)
display_tree(derivation_tree)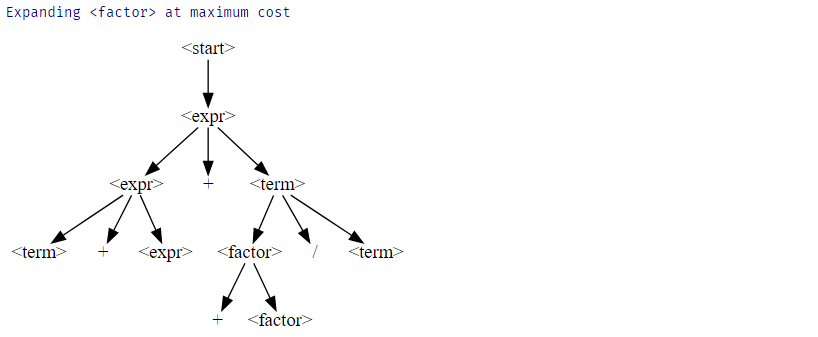
각 단계에 따라 비단말의 수가 증가하는 것을 볼 수 있습니다. 분명히, 우리는 이 숫자에 제한을 두어야 합니다.
Three Expansion Phases
이제 세 단계를 모두 하나의 함수 expand_tree()에 포함시킬 수 있으며, 다음과 같이 작동합니다.
-
최대 비용 확장입니다. 최소한의 min_nonterminals 비단만이 생길 때까지 최대 비용으로 트리를 확장합니다. 이 단계는 min_nonterminals를 0으로 설정하면 쉽게 건너뛸 수 있습니다.
⇾ 다양한 결과가 나오게 하기 위해서 -
무작위 확장입니다. max_nonterminals 비단말에 도달할 때까지 트리를 무작위로 계속 확장하세요.
-
최소 비용 확장입니다. 최소 비용으로 확장을 종료합니다.
⇾ 최소 비용 확장을 통해 비단말 기호를 단말 기호로 바꾸고 결과를 생성하여 확장을 종료하기 위해서
expand_node가 적용할 확장 메서드를 참조하도록 하여 이 세 단계를 구현합니다. 이는 expand_node(메서드 참조)를 먼저 expand_node_max_cost로 설정한 다음(즉, expand_node() 를 호출하면 expand_node_max_cost()가 호출됩니다.), expand_node_randomy, 마지막으로 expand_node_min_cost로 설정하여 제어합니다. 처음 두 단계에서는 min_nonterminals와 max_nonterminals의 최대 한계도 각각 설정합니다.
Excursion: Implementation of three-phase expand_tree()
class GrammarFuzzer(GrammarFuzzer):
def log_tree(self, tree: DerivationTree) -> None:
"""Output a tree if self.log is set; if self.display is also set, show the tree structure"""
if self.log:
print("Tree:", all_terminals(tree))
if self.disp:
display(display_tree(tree))
# print(self.possible_expansions(tree), "possible expansion(s) left")
def expand_tree_with_strategy(self, tree: DerivationTree,
expand_node_method: Callable,
limit: Optional[int] = None):
"""Expand tree using `expand_node_method` as node expansion function
until the number of possible expansions reaches `limit`."""
self.expand_node = expand_node_method # type: ignore
while ((limit is None
or self.possible_expansions(tree) < limit)
and self.any_possible_expansions(tree)):
tree = self.expand_tree_once(tree)
self.log_tree(tree)
return tree
def expand_tree(self, tree: DerivationTree) -> DerivationTree:
"""Expand `tree` in a three-phase strategy until all expansions are complete."""
self.log_tree(tree)
tree = self.expand_tree_with_strategy(
tree, self.expand_node_max_cost, self.min_nonterminals)
tree = self.expand_tree_with_strategy(
tree, self.expand_node_randomly, self.max_nonterminals)
tree = self.expand_tree_with_strategy(
tree, self.expand_node_min_cost)
assert self.possible_expansions(tree) == 0
return treeEnd of Excursion
우리의 예시에서 이것을 시험해 봅시다. 먼저 half-expanded derivation tree로 시작합니다.
initial_derivation_tree: DerivationTree = ("<start>",
[("<expr>",
[("<expr>", None),
(" + ", []),
("<term>", None)]
)])display_tree(initial_derivation_tree)
이제 확장 전략을 이 트리에 적용합니다. 처음에는 노드를 최대 비용으로 확장한 다음 무작위로 확장한 다음 최소 비용으로 확장을 종료하는 것을 알 수 있습니다.
f = GrammarFuzzer(
EXPR_GRAMMAR,
min_nonterminals=3,
max_nonterminals=5,
log=True)
derivation_tree = f.expand_tree(initial_derivation_tree)Tree: <expr> + <term>
Expanding <term> at maximum cost
Tree: <expr> + <factor> / <term>
Expanding <expr> randomly
Tree: <term> + <expr> + <factor> / <term>
Expanding <factor> randomly
Tree: <term> + <expr> + -<factor> / <term>
Expanding <term> randomly
Tree: <factor> + <expr> + -<factor> / <term>
Expanding <factor> randomly
Tree: -<factor> + <expr> + -<factor> / <term>
Expanding <factor> randomly
Tree: --<factor> + <expr> + -<factor> / <term>
Expanding <term> randomly
Tree: --<factor> + <expr> + -<factor> / <factor> / <term>
Expanding <factor> at minimum cost
Tree: --<factor> + <expr> + -<integer> / <factor> / <term>
Expanding <term> at minimum cost
Tree: --<factor> + <expr> + -<integer> / <factor> / <factor>
Expanding <expr> at minimum cost
Tree: --<factor> + <term> + -<integer> / <factor> / <factor>
Expanding <term> at minimum cost
Tree: --<factor> + <factor> + -<integer> / <factor> / <factor>
Expanding <factor> at minimum cost
Tree: --<factor> + <factor> + -<integer> / <factor> / <integer>
Expanding <factor> at minimum cost
Tree: --<factor> + <integer> + -<integer> / <factor> / <integer>
Expanding <integer> at minimum cost
Tree: --<factor> + <digit> + -<integer> / <factor> / <integer>
Expanding <factor> at minimum cost
Tree: --<integer> + <digit> + -<integer> / <factor> / <integer>
Expanding <factor> at minimum cost
Tree: --<integer> + <digit> + -<integer> / <integer> / <integer>
Expanding <integer> at minimum cost
Tree: --<integer> + <digit> + -<digit> / <integer> / <integer>
Expanding <digit> at minimum cost
Tree: --<integer> + 1 + -<digit> / <integer> / <integer>
Expanding <digit> at minimum cost
Tree: --<integer> + 1 + -3 / <integer> / <integer>
Expanding <integer> at minimum cost
Tree: --<digit> + 1 + -3 / <integer> / <integer>
Expanding <digit> at minimum cost
Tree: --0 + 1 + -3 / <integer> / <integer>
Expanding <integer> at minimum cost
Tree: --0 + 1 + -3 / <digit> / <integer>
Expanding <integer> at minimum cost
Tree: --0 + 1 + -3 / <digit> / <digit>
Expanding <digit> at minimum cost
Tree: --0 + 1 + -3 / 7 / <digit>
Expanding <digit> at minimum cost
Tree: --0 + 1 + -3 / 7 / 0이게 마지막 derivation tree입니다.
display_tree(derivation_tree)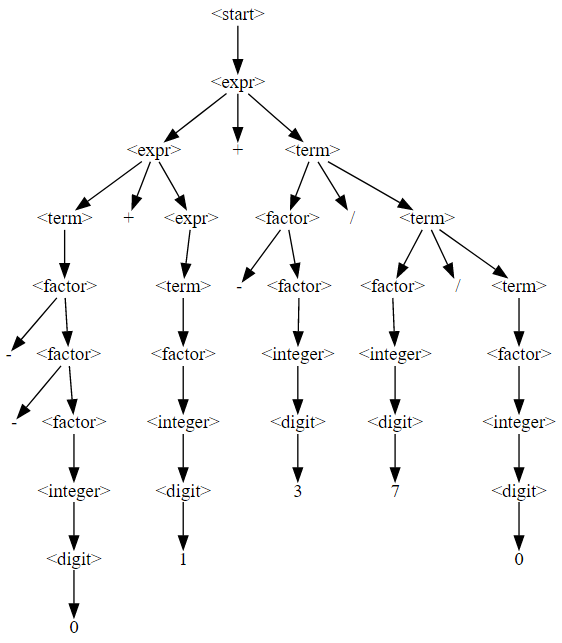
결과 문자열은 다음과 같습니다.
all_terminals(derivation_tree)'--0 + 1 + -3 / 7 / 0'Putting it all Together
이를 바탕으로, 우리는 simple_grammar_fuzzer()와 같이 단순히 문법을 취하고 그것으로부터 문자열을 생성하는 함수 fuzz()를 정의할 수 있습니다.
class GrammarFuzzer(GrammarFuzzer):
def fuzz_tree(self) -> DerivationTree:
"""Produce a derivation tree from the grammar."""
tree = self.init_tree()
# print(tree)
# Expand all nonterminals
tree = self.expand_tree(tree)
if self.log:
print(repr(all_terminals(tree)))
if self.disp:
display(display_tree(tree))
return tree
def fuzz(self) -> str:
"""Produce a string from the grammar."""
self.derivation_tree = self.fuzz_tree()
return all_terminals(self.derivation_tree)이제 이를 모든 정의된 문법에 적용할 수 있습니다
f = GrammarFuzzer(EXPR_GRAMMAR)
f.fuzz()'++2.937 * -7 * ++-6'fuzz()를 호출한 후 생성된 derivation tree는 derivation tree 속성에 접근할 수 있습니다:
display_tree(f.derivation_tree)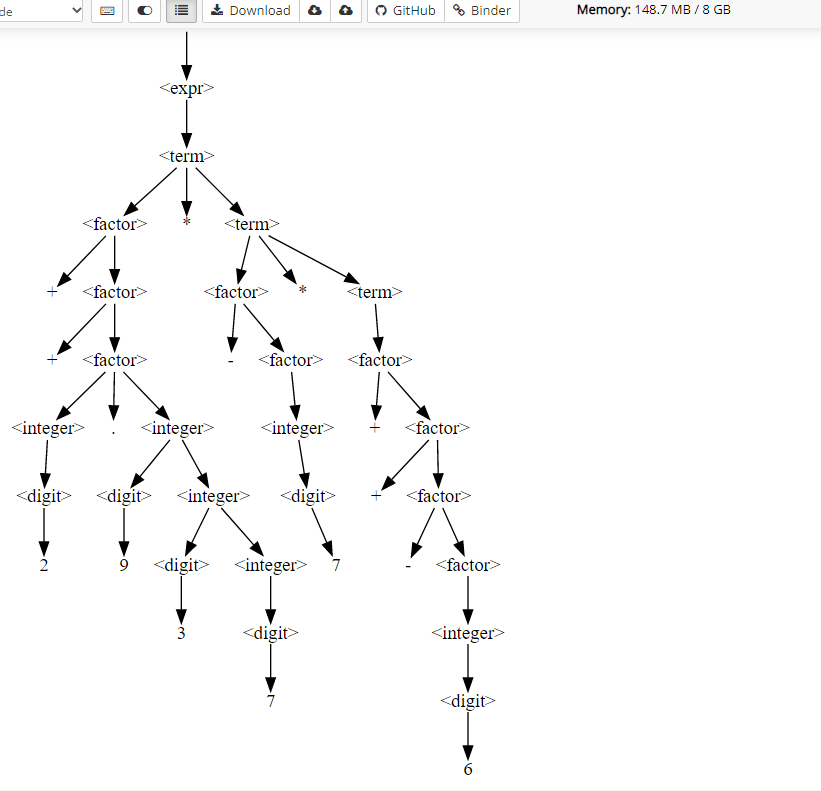
다른 문법 형식에서 문법 퍼저를 시험해 봅시다.
f = GrammarFuzzer(URL_GRAMMAR)
f.fuzz()'ftps://user:password@cispa.saarland:04/x74?x64=x64'display_tree(f.derivation_tree)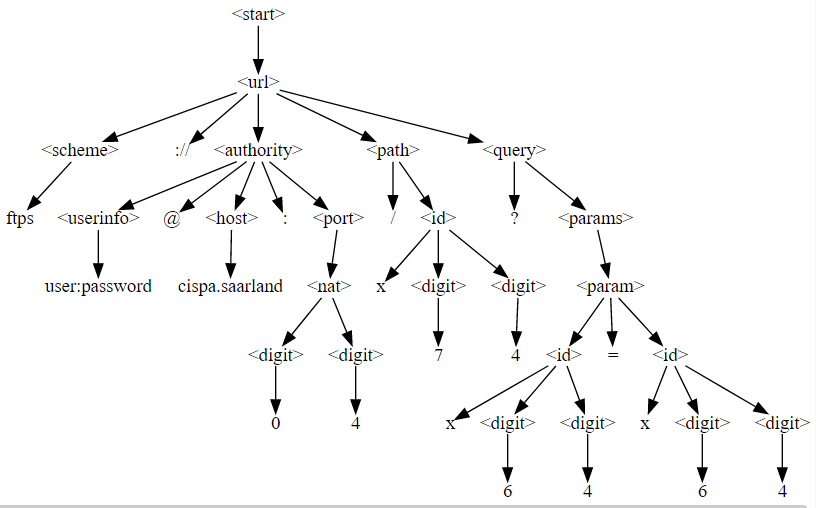
f = GrammarFuzzer(CGI_GRAMMAR, min_nonterminals=3, max_nonterminals=5)
f.fuzz()'%18+0'display_tree(f.derivation_tree)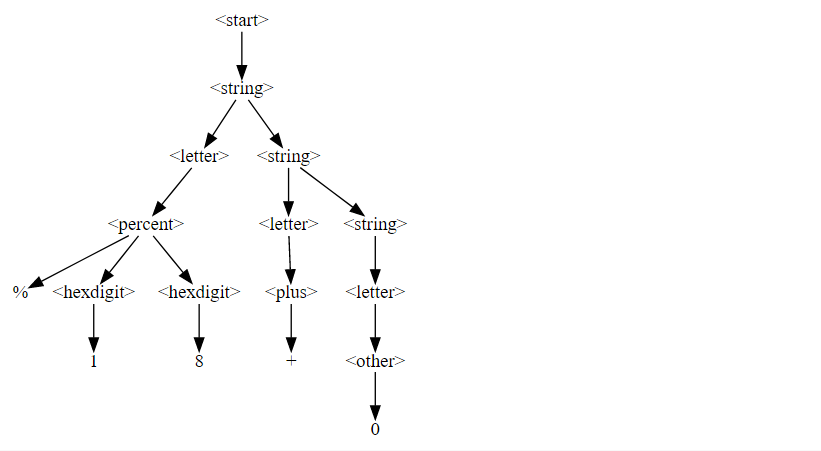
simple_grammar_fuzzer()와 어떤점이 다를까요?
trials = 50
xs = []
ys = []
f = GrammarFuzzer(EXPR_GRAMMAR, max_nonterminals=20)
for i in range(trials):
with Timer() as t:
s = f.fuzz()
xs.append(len(s))
ys.append(t.elapsed_time())
print(i, end=" ")
print()0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 average_time = sum(ys) / trials
print("Average time:", average_time)Average time: 0.016987550000000056%matplotlib inline
import matplotlib.pyplot as plt
plt.scatter(xs, ys)
plt.title('Time required for generating an output');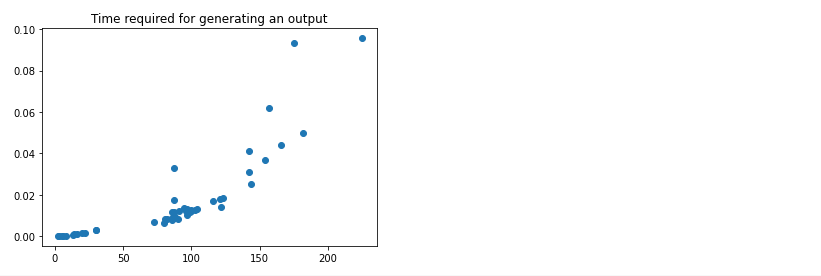
테스트 생성 속도가 훨씬 빠를 뿐 아니라 입력 값도 훨씬 작습니다. derivation tree를 사용하면 문법 생성을 훨씬 더 잘 제어할 수 있습니다.
마지막으로, simple_grammar_fuzzer()가 실패한 expr_grammar에서 GrammarFuzzer는 어떻게 작동합니까? 문제 없이 작동합니다.
f = GrammarFuzzer(expr_grammar, max_nonterminals=10)
f.fuzz()'4 + (3 - 2 + 4) * 8 * 6 - 4 / 6 * 0'Grammar Fuzzer를 통해 우리는 이제 더 많은 퍼저를 구축하고 소프트웨어 테스트 생성의 세계에서 더 흥미로운 개념을 설명할 수 있는 탄탄한 기반을 갖게 되었습니다. 이들 중 다수는 심지어 문법을 쓸 필요가 없습니다 – 대신, 그들은 가까이에 있는 도메인으로부터 문법을 추론하고, 따라서 문법을 쓰지 않고도 문법 기반의 퍼징을 사용할 수 있습니다. 채널을 고정하세요!
Synopsis
Efficient Grammar Fuzzing
이 장에서는 문법적으로 유효한 입력 문자열을 생성하기 위해 문법을 사용하는 효율적인 문법 퍼저인 GrammarFuzer를 소개합니다. 일반적인 용도는 다음과 같습니다.
from Grammars import US_PHONE_GRAMMARphone_fuzzer = GrammarFuzzer(US_PHONE_GRAMMAR)
phone_fuzzer.fuzz()'(519)333-4454'예를 들어 GrammarFuzer 생성자는 동작을 제어하기 위해 다음과 같은 키워드 인수를 사용합니다. start_symbol을 사용하면 확장이 시작하는 기호를 설정할 수 있습니다(<start> 대신).
area_fuzzer = GrammarFuzzer(US_PHONE_GRAMMAR, start_symbol='<area>')
area_fuzzer.fuzz()'718'GrammarFuzzer 생성자를 매개 변수화하는 방법은 다음과 같습니다.
# ignore
import inspect# ignore
print(inspect.getdoc(GrammarFuzzer.__init__))Produce strings from `grammar`, starting with `start_symbol`.
If `min_nonterminals` or `max_nonterminals` is given, use them as limits
for the number of nonterminals produced.
If `disp` is set, display the intermediate derivation trees.
If `log` is set, show intermediate steps as text on standard output.# ignore
from ClassDiagram import display_class_hierarchy# ignore
display_class_hierarchy([GrammarFuzzer],
public_methods=[
Fuzzer.__init__,
Fuzzer.fuzz,
Fuzzer.run,
Fuzzer.runs,
GrammarFuzzer.__init__,
GrammarFuzzer.fuzz,
GrammarFuzzer.fuzz_tree,
],
types={
'DerivationTree': DerivationTree,
'Expansion': Expansion,
'Grammar': Grammar
},
project='fuzzingbook')
Derivation Trees
내부적으로 GrammarFuzer는 단계별로 확장하는 derivation trees를 사용합니다. 문자열을 생성한 후 생성된 트리는 deliversation_tree 속성에서 액세스할 수 있습니다.
display_tree(phone_fuzzer.derivation_tree)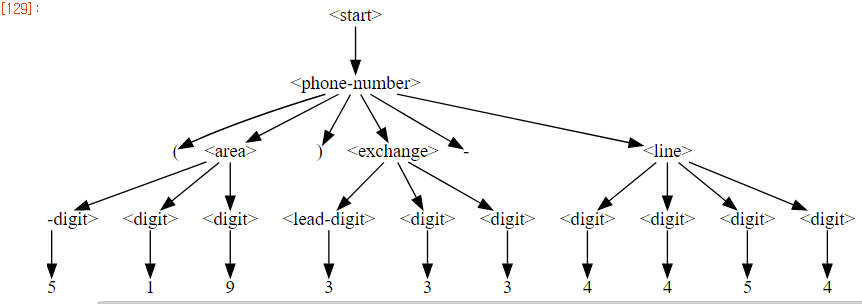
derivation trees의 내부 표현에서 노드는 쌍(기호, 자식)입니다. 비단말의 경우 기호는 확장 중인 기호이고 하위 노드는 추가 노드의 목록입니다. 단말의 경우 기호는 단말 문자열이고 하위 문자열은 비어 있습니다.
phone_fuzzer.derivation_tree('<start>',
[('<phone-number>',
[('(', []),
('<area>',
[('<lead-digit>', [('5', [])]),
('<digit>', [('1', [])]),
('<digit>', [('9', [])])]),
(')', []),
('<exchange>',
[('<lead-digit>', [('3', [])]),
('<digit>', [('3', [])]),
('<digit>', [('3', [])])]),
('-', []),
('<line>',
[('<digit>', [('4', [])]),
('<digit>', [('4', [])]),
('<digit>', [('5', [])]),
('<digit>', [('4', [])])])])])이 장에는 시각화 도구(특히 display_tree())를 포함하여 derivation trees에서 작업할 수 있는 다양한 도우미가 포함되어 있습니다.
Lessons Learned
- Derivation trees는 입력 구조를 표현하는 데 중요합니다.
- derivation trees를 기반으로한 문법 퍼징
- 문자열 기반 문법 퍼징보다 훨씬 더 효율적입니다.
- 입력 생성을 훨씬 더 잘 제어할 수 있습니다.
- 무한 확장에 이르는 것을 효과적으로 방지합니다.
[ The Fuzzing Book ]
Efficient Grammar Fuzzing
