데이터사이언스 오리지널
아래 내용은 AWSKRUG (AWS 한국 사용자모임) 데이터 소모임에서 발표한 내용입니다.
https://www.meetup.com/ko-KR/awskrug/events/299642049/
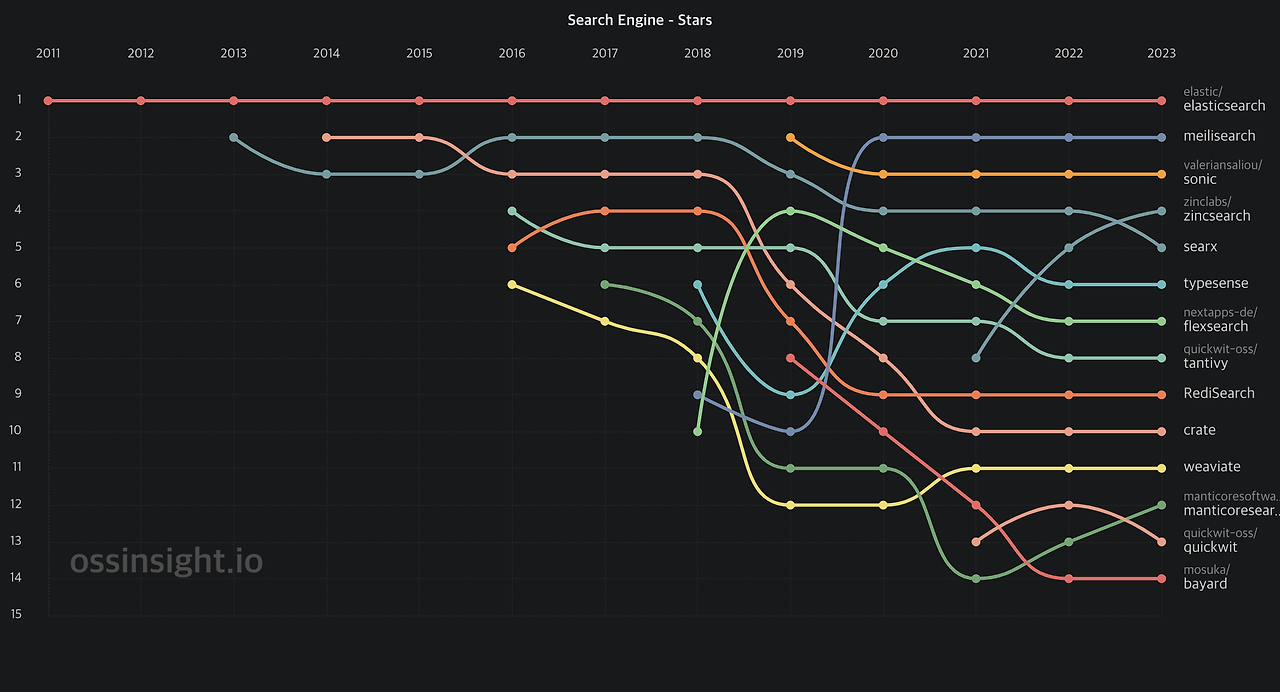
ES의 독주를 추격하는 검색엔진 meilisearch
Meilisearch ?
💡 Meilisearch는 RESTful 검색 API 입니다 . 빠르고 관련성 높은 검색 경험을 원하는 모든 사람을 위한 즉시 사용 가능한 솔루션을 목표로 합니다 ⚡️🔎
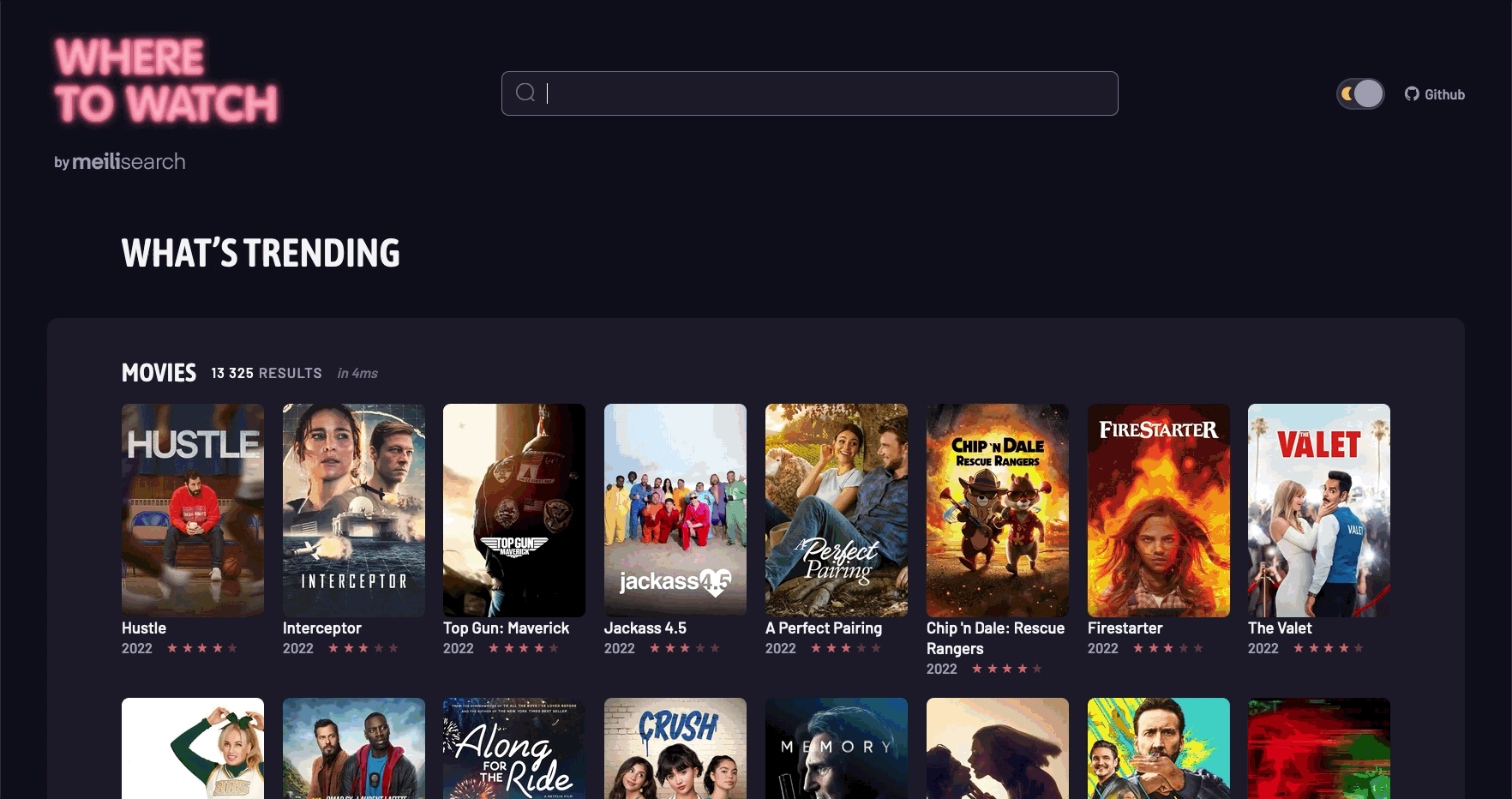
https://where2watch.meilisearch.com/
특징
- 엄청나게 빠른 속도: 50밀리초 이내에 응답
- 입력하면서 검색 :접두어 검색을 사용하여 키를 누를 때마다 결과가 업데이트됩니다.
- 오타 허용: 쿼리에 오타나 철자가 틀린 경우에도 관련 일치 항목을 얻습니다. (한국어에선 비활성화...)
- 종합적인 언어 지원 : 중국어, 일본어, 히브리어, 라틴 알파벳을 사용하는 언어 에 대한 최적화된 지원
- 전체 문서 반환: 검색 시 전체 문서를 반환합니다.
- 사용자 정의 가능한 검색 및 인덱싱: 요구 사항에 맞게 검색 동작을 사용자 정의합니다.
- RESTful API
- 검색 미리보기: 프런트엔드를 구현하지 않고도 검색 설정을 테스트할 수 있습니다.
- API 키 관리: API 키로 인스턴스를 보호하세요. 데이터가 항상 안전하도록 만료 날짜를 설정하고 인덱스 및 엔드포인트에 대한 액세스를 제어하세요.
- 다중 테넌트 및 테넌트 토큰: 복잡한 다중 사용자 애플리케이션을 관리합니다. 테넌트 토큰은 각 사용자가 검색할 수 있는 문서를 결정하는 데 도움이 됩니다.
- 다중 검색: 단일 HTTP 요청으로 여러 인덱스에 대해 여러 검색 쿼리를 수행합니다.
- 지리 검색: 지리적 위치를 기준으로 결과 필터링 및 정렬
- 인덱스 스와핑: 검색 중단 시간 없이 주요 데이터베이스 업데이트 배포
철학?
- 우리의 목표는 개발자와 최종 사용자 모두에게 간단하고 직관적인 경험을 제공
- Meilisearch는 주요 데이터 저장소가 되어서는 안 됩니다 . 데이터베이스가 아닌 검색 엔진!
- Meilisearch는 사이트를 개발하든, 앱을 개발하든 상관없이 50밀리초 미만의 응답 시간
패싯검색(facet search)이란?
접두사(prefix) 검색 -
Given a set of words in a dataset:
film cinema movies show harry potter shine musical
query: s: response:
show
shine
but not
movies
musical
query: sho: response:
showRESTfulAPI
다른 검색엔진과 비교


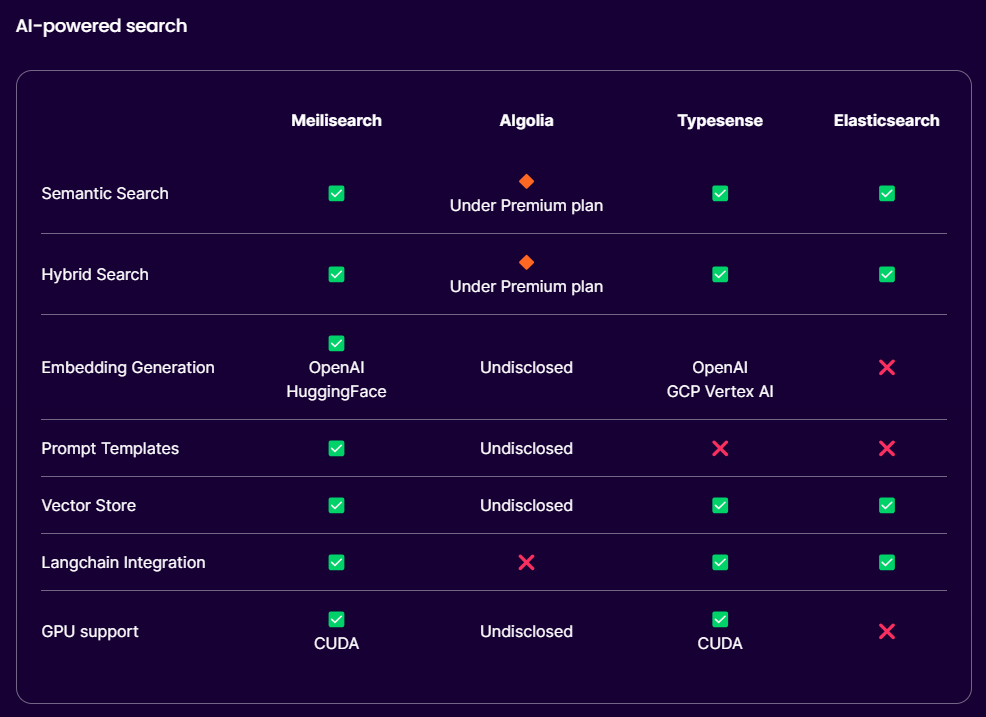
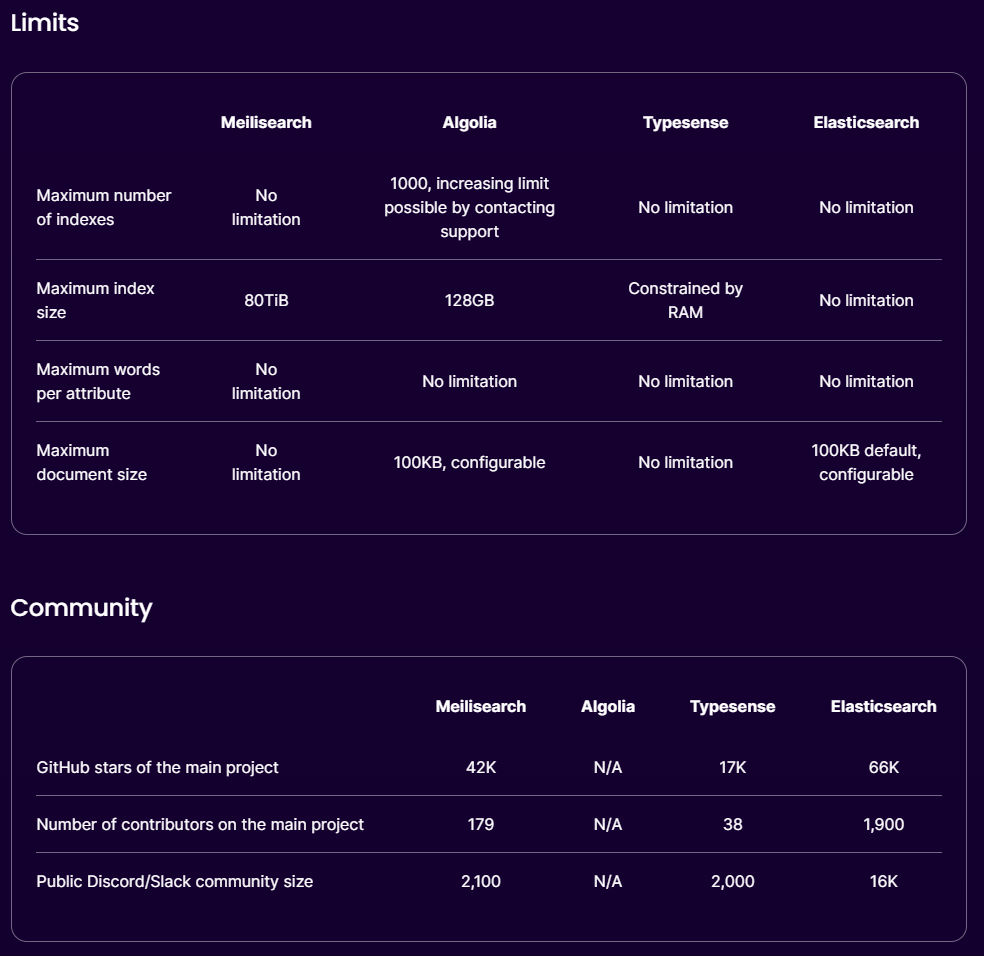
Elastic Search와 비교
아래광고는
only ES사용해서 검색서비스를 구축하기가 어렵다는 것을 반증합니다.

왜냐하면?
- Elastic Search는 백엔드 검색엔진으로 설계
- 백엔드 검색엔진이란, 방대양의 데이터 검색과 텍스트 분석수행 목적에 부합하게 구현됨. 즉 로그분석과 같은 작업 (Back-facing search)에 적합. - ELK
- 따라서 최종 사용고객에게 서비스하기 위해서는 많은 노력이 필요
- Meilisearch 는 오히려 최종 사용고객향(Front-facing search)을 위한 검색엔진을 목적으로 개발됨
- 상품, 인명 등 제한된 사이즈에서 검색하는데 탁월한 성능을 지님 (속도가 대부분의 경우 비교할 수 없을 정도로 빠르고, 오타보정, 접두사 검색등의 기능이 기본제공)
따지자면 알골리아가 비빌만한 경쟁서비스 (하지만 알골리아는 유료)

CookBook
Syncing databases with PostgreSQL and meilisync — Meilisearch documentation
Postman collection for Meilisearch — Meilisearch documentation
Deploy a Meilisearch instance on AWS — Meilisearch documentation
Integrate Meilisearch Cloud with Vercel — Meilisearch documentation
설치과정 안내
-
도커로 합니다.
-
이미지를 가져옵니다
-
일단 고~
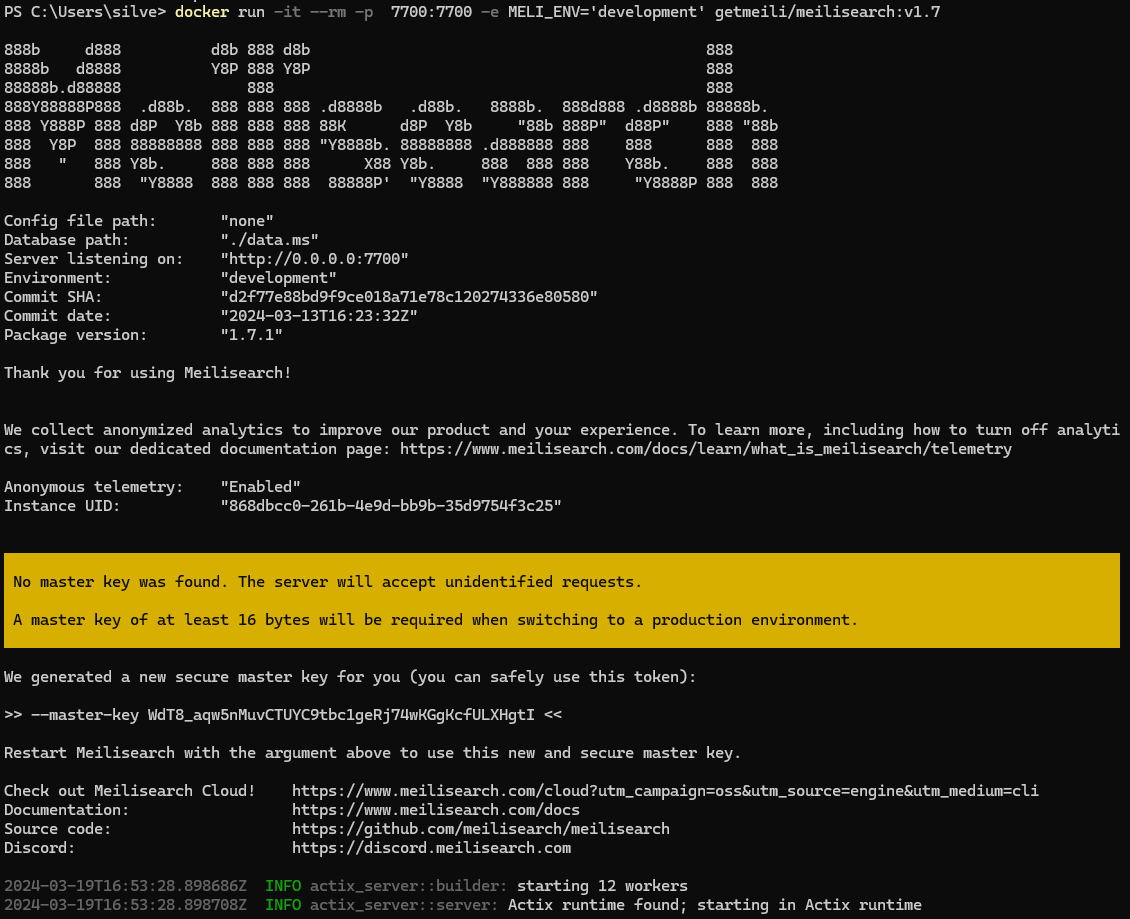
-
친절하게 마스터키(api key) 만들어줌
-
다시고
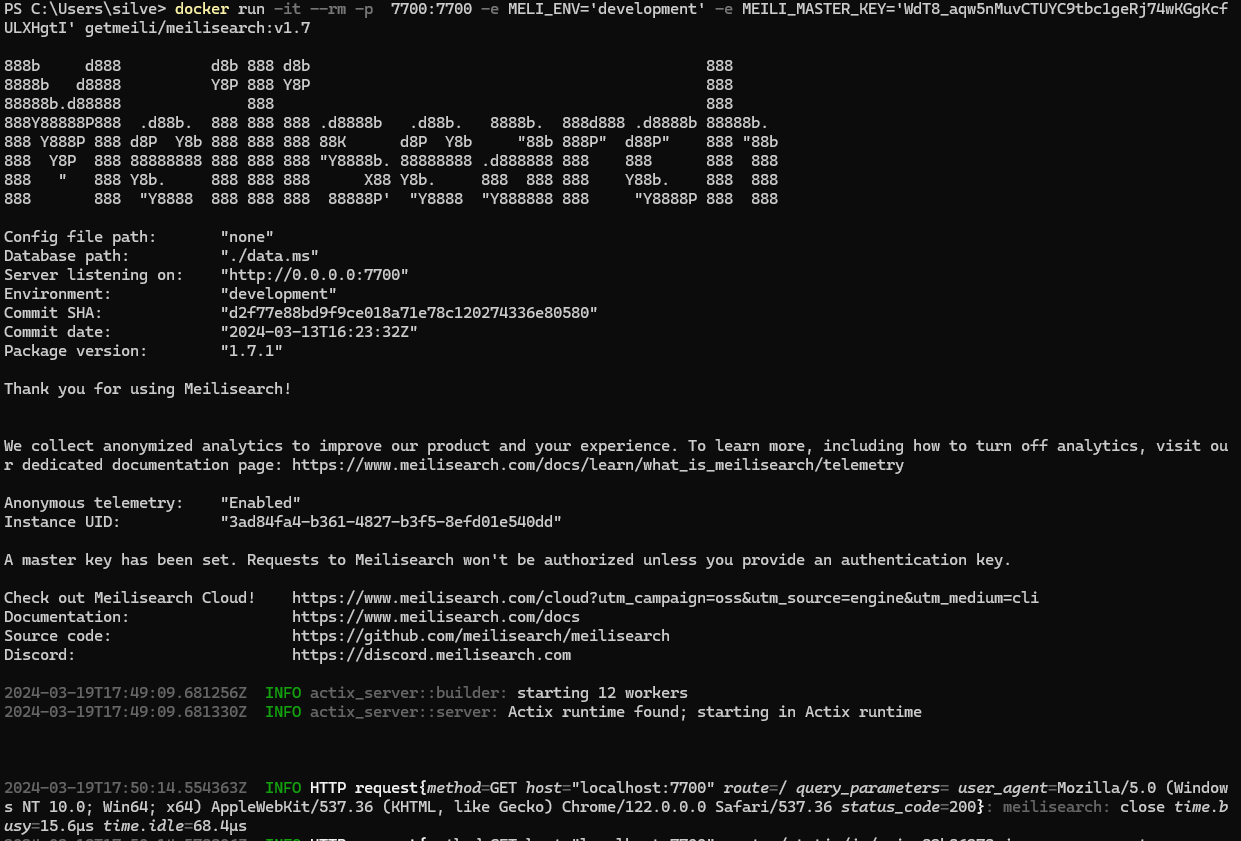
-
화면가보자 localhost:7700
-
아까 만들어준 키를 입력하자
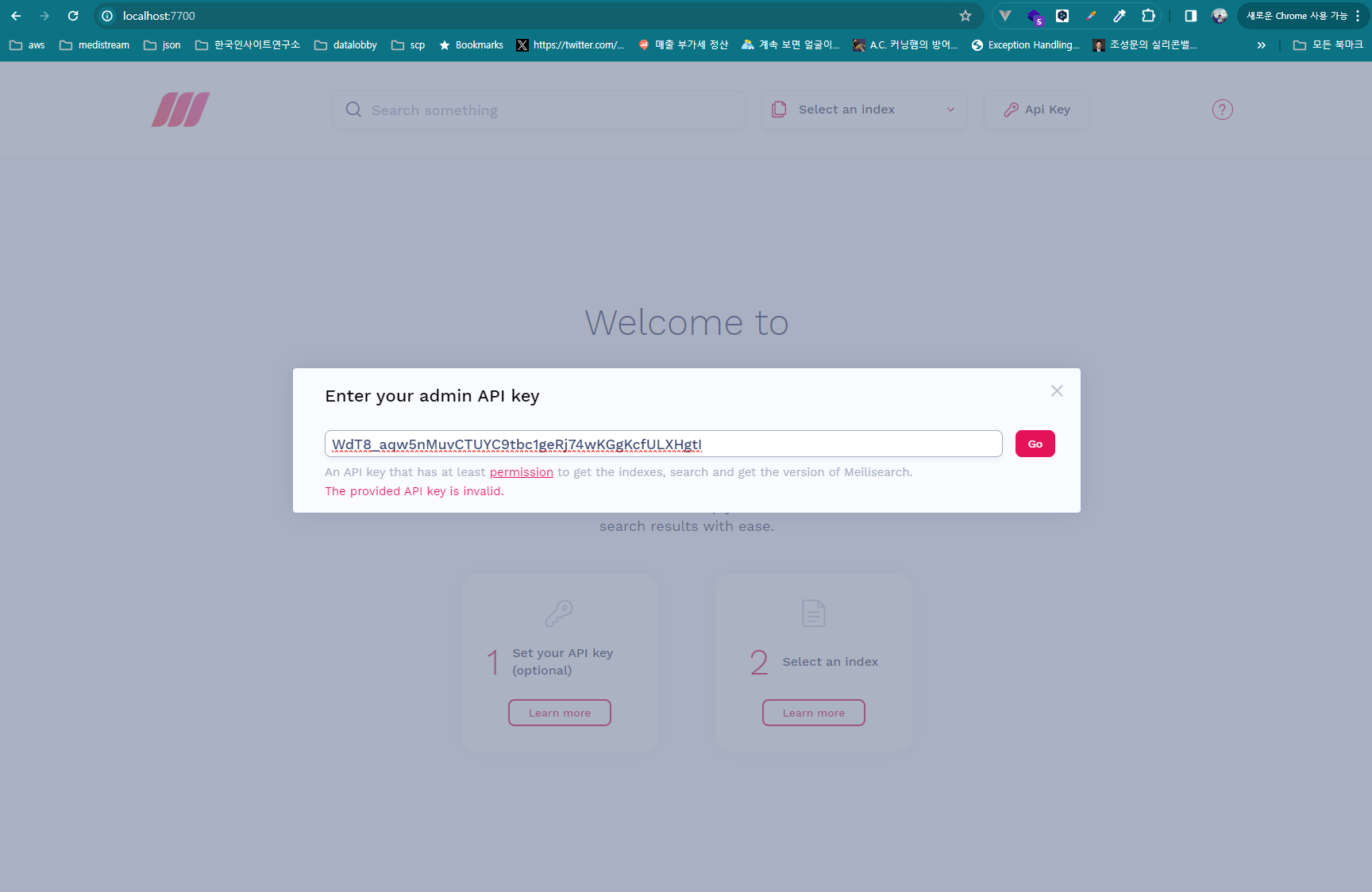
💡 👏👏👏 완료~ 참쉽죠?
데이터 넣고 한번 돌려봅시다
- 나무위키 덤프를 받습니다.
- 그중에서 '걸그룹' 이란 단어가 포함된 문서만 인덱싱합니다.
- 파이썬 클라이언트 모듈을 이용해서 쉽게 검색엔진에 로딩합니다.
- 기본으로 제공되는 web ui 화면을 통해 검색해봅시다.
샘플데이터 : 나무위키 덤프
heegyu/namuwiki · Datasets at Hugging Face
의존성 설치
pip3 install datasets jsonlines meilisearch
실행코드 (python)
# load.py
########### 데이터셋을 파일로 내립니다. ('걸그룹' 이란 단어가 포함된 문서만)
from datasets import load_dataset
dataset = load_dataset("heegyu/namuwiki", split='train[:90%]')
filtered = dataset.filter(lambda x: len(x['text']) < 3000).filter(lambda x: '걸그룹' in x['text'])
print(len(filtered))
filtered.to_json("girlgroup.ndjson")
########### 파일을 읽어서 간단한 전처리 수행합니다.
import jsonlines
def mediaWiki_to_markdown(text):
# 헤더 변환
text = re.sub(r'(={2,})(.*?)\1', lambda match: f"{'#' * len(match.group(1))} {match.group(2)}", text)
# 굵은 글씨 변환
text = re.sub(r"'''(.*?)'''", r"**\1**", text)
# 기울임 변환
text = re.sub(r"''(.*?)''", r"*\1*", text)
# 링크 변환
text = re.sub(r'\[\[(.*?)\]\]', r'[\1](\1)', text)
text = re.sub(r'\[\[(.*?)\|(.*?)\]\]', r'[\2](\1)', text)
# 이미지 변환
text = re.sub(r'\[\[파일:(.*?)\|.*?\]\]', r'', text)
# 목록 변환
text = re.sub(r'^\* (.*)', r'* \1', text, flags=re.MULTILINE)
# 인용 변환
text = re.sub(r'^>(.*)', r'> \1', text, flags=re.MULTILINE)
return text
documents = []
with jsonlines.open("girlgroup.ndjson") as f:
for i, line in enumerate(f.iter()):
# 너무 긴 문서는 제외
if len(line['text']) > 3000:
continue
line["id"] = i
line['text'] = mediaWiki_to_markdown(line['text'])
documents.append(line)
docs = documents
# 검색엔진에 넣습니다. python sdk 사용
import meilisearch
client = meilisearch.Client('http://localhost:7700', '1bc7eb62470c77149919')
# 인덱스가 존재하면 삭제
client.index('girlgroup').delete()
print('index deleted')
client.create_index('girlgroup', {'primaryKey': 'id'})
print(f"girlgroup created successfully")
client.index('girlgroup').add_documents(docs)
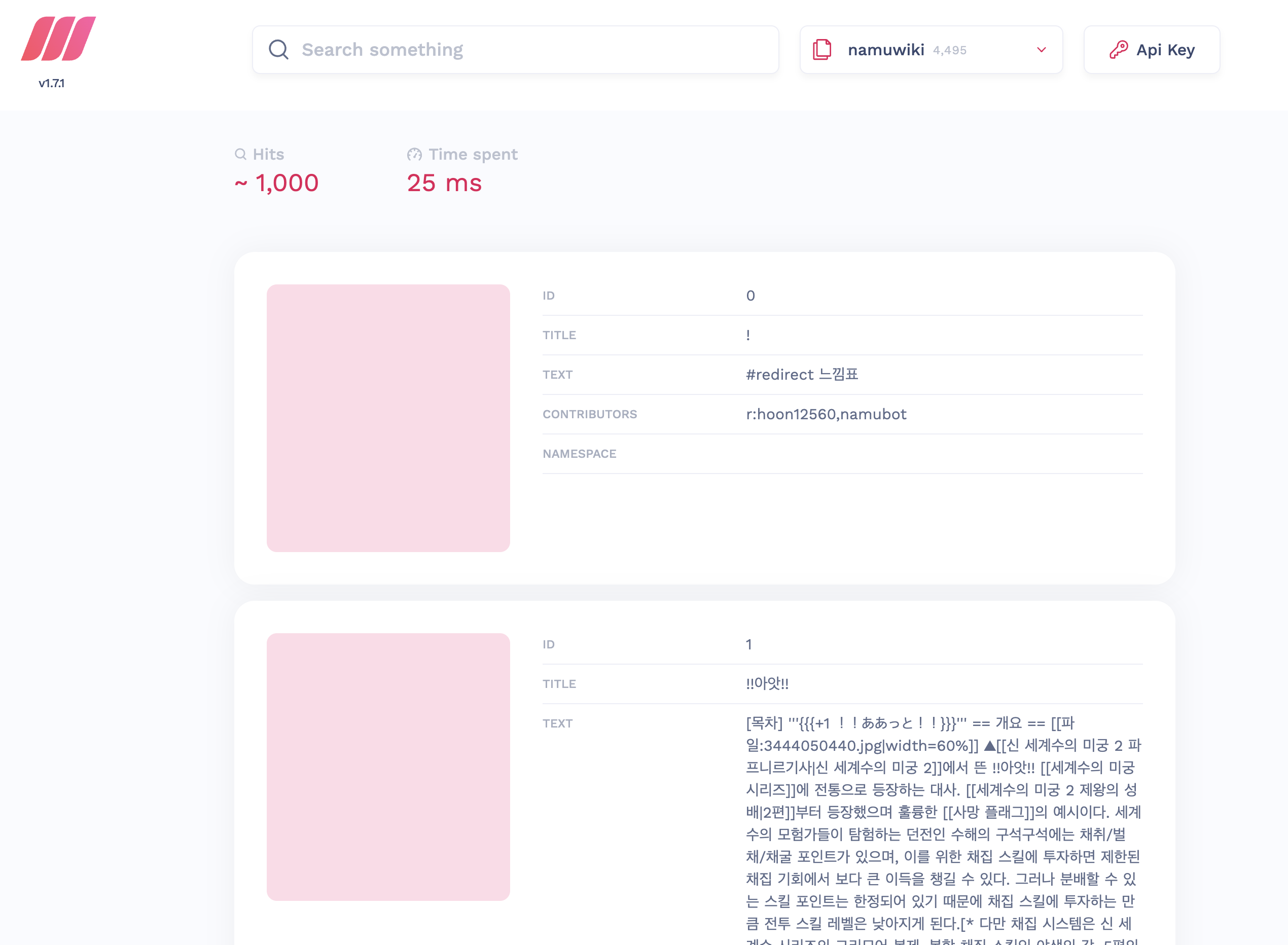
localhost:7700
RAG 데모 서비스 만들기
streamlit을 활용해서 간단하게 검색엔진meilisearch+openai chat_completion을 결합하여 RAG 서비스를 모델링 합니다.
RAG?
LLM을 활용한 생성형 AI(chatGTP)서비스의 최대 단점인 할루시네이션(템플러 생각나면 나랑 같은 세대... 좋아요 눌러주세요)을 보완하기 위한 꼼수?
LLM에 질문과 답변의 맥락 정보를 제공해서 적절한 답변을 생성하게 합니다. (헛소리를 못하게 막음)
💡 검색-증강 생성이란 무엇인가요?
RAG(Retrieval-Augmented Generation)는 대규모 언어 모델의 출력을 최적화하여 응답을 생성하기 전에 학습 데이터 소스 외부의 신뢰할 수 있는 지식 베이스를 참조하도록 하는 프로세스입니다. 대규모 언어 모델(LLM)은 방대한 양의 데이터를 기반으로 학습되며 수십억 개의 매개 변수를 사용하여 질문에 대한 답변, 언어 번역, 문장 완성과 같은 작업에 대한 독창적인 결과를 생성합니다. RAG는 이미 강력한 LLM의 기능을 특정 도메인이나 조직의 내부 지식 기반으로 확장하므로 모델을 다시 교육할 필요가 없습니다. 이는 LLM 결과를 개선하여 다양한 상황에서 관련성, 정확성 및 유용성을 유지하기 위한 비용 효율적인 접근 방식입니다.
출처 - RAG란?
streamlit
💡 streamlit
데이터 과학자와 개발자가 빠르게 데이터 애플리케이션을 만들 수 있도록 돕는 오픈소스 파이썬 라이브러리입니다. 사용자는 몇 줄의 코드만으로 인터랙티브한 웹 애플리케이션을 구축할 수 있습니다
개발문서
https://docs.streamlit.io/
시크릿 관리 방법
-> 아래 위치에 secrets.toml을 만드시고 openai_api_key를 넣습니다.
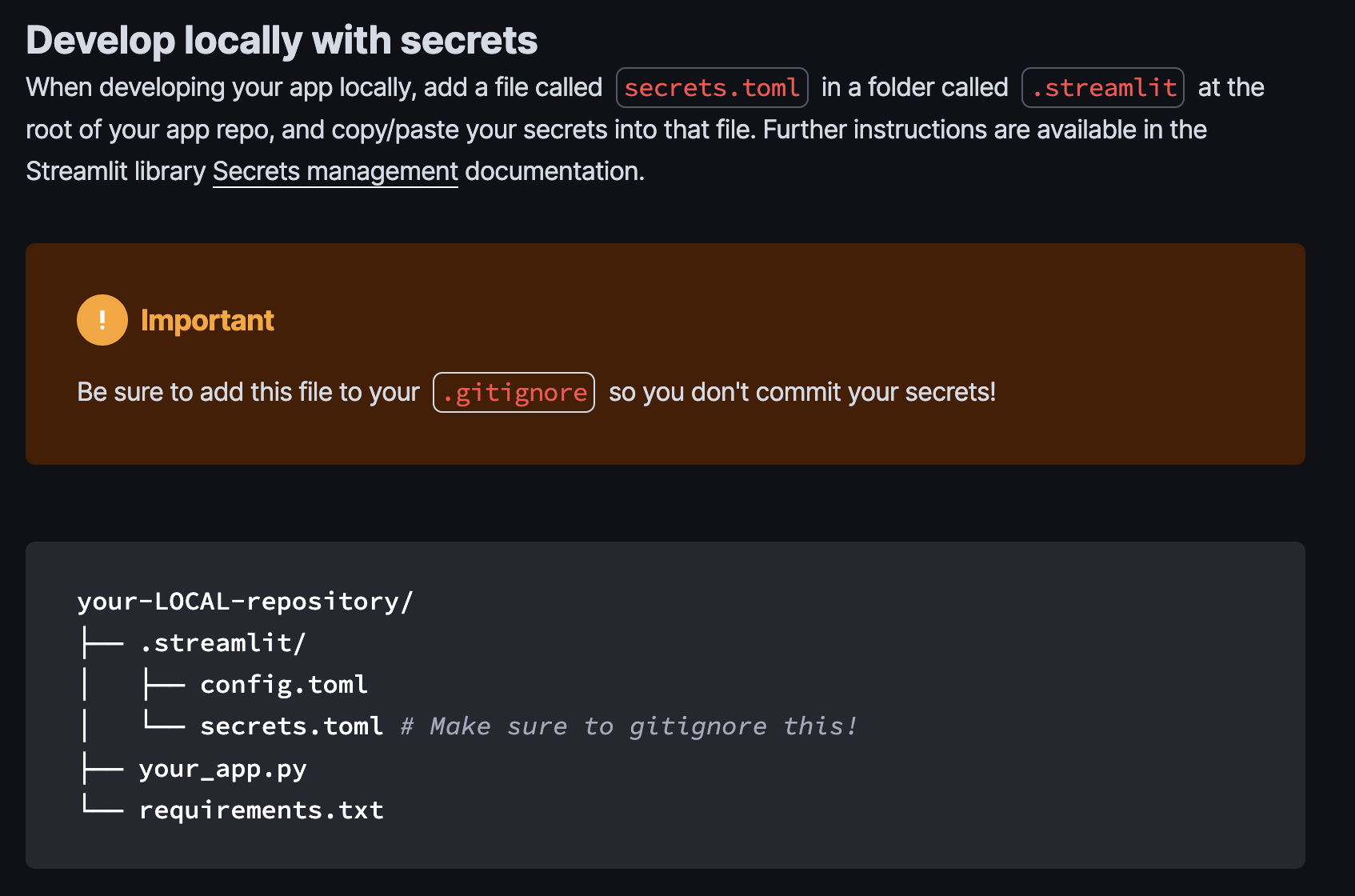
# This is a TOML document.
# secrets.toml
OPENAI_API_KEY = "sk-XXXXXXXXXXXXXXXXXXXX"
app code
pip3 install streamlit openai# app.py
import streamlit as st
from openai import OpenAI
import meilisearch
# 검색엔진 API 키 설정
meili = meilisearch.Client('http://localhost:7700', 'meilisearch 서버 띄울때 넣은 MEILI_MASTER_KEY')
# OPENAI 서비스 키 설정
gpt = OpenAI(api_key=st.secrets["OPENAI_API_KEY"])
st.set_page_config(layout="wide")
col1, col2 = st.columns(2, gap="small")
with col1:
st.title('걸그룹 검색기 :tulip::cherry_blossom::rose:')
search = st.form('search')
sentence = search.text_input('검색어 입력')
submit = search.form_submit_button(f'검색!')
if submit:
#search(query: str, opt_params: Mapping[str, Any] | None = None)→ Dict[str, Any]
res = meili.index('girlgroup').search(
'"'+sentence+'"',
# {
# 'hybrid': {
# 'semanticRatio': 0.5,
# 'embedder': 'default'
# }
# }
)
l = res['hits'][:10]
for i in l:
st.title(i['title'])
st.subheader(i['id'])
st.markdown(i['text'].replace(sentence, f":red[{sentence}]") )
st.write('---')
with col2:
st.title("챗봇 🤖")
on = st.toggle('RAG 활성화')
if on:
st.write(':rocket: :red[RAG 작동!]')
def getMessage():
messages = []
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
if( on ) :
#챗봇에 물어보는 문장을 직접 넣으면 검색엔진이 못찾아서 그냥 첫단어만 짤라서 넣음
#나중에 벡터검색을 활용해서 hybrid_search 로 변경하면 전체 넣어도 됨
qq = prompt.split(' ', 1)[0]
res = meili.index('girlgroup').search(qq)
context = res['hits'][0]['text']
q = template.format(context=context, question=prompt)
messages.append({"role": "user", "content": q})
else:
for message in st.session_state.messages:
messages.append({"role": message["role"], "content": message["content"]})
return messages
if "openai_model" not in st.session_state:
st.session_state["openai_model"] = "gpt-3.5-turbo"
if "messages" not in st.session_state:
st.session_state.messages = []
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
if prompt := st.chat_input("What is up?"):
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)
with st.chat_message("assistant"):
print(st.session_state.messages)
stream = gpt.chat.completions.create(
model=st.session_state["openai_model"],
messages=getMessage(),
stream=True,
)
response = st.write_stream(stream)
st.session_state.messages.append({"role": "assistant", "content": response})실행~
$streamlit run app.py결과
RAG 없이 질문하는 경우
필요한 정보를 주지 않았기 때문에 의미없는 답변이 돌아 옵니다.
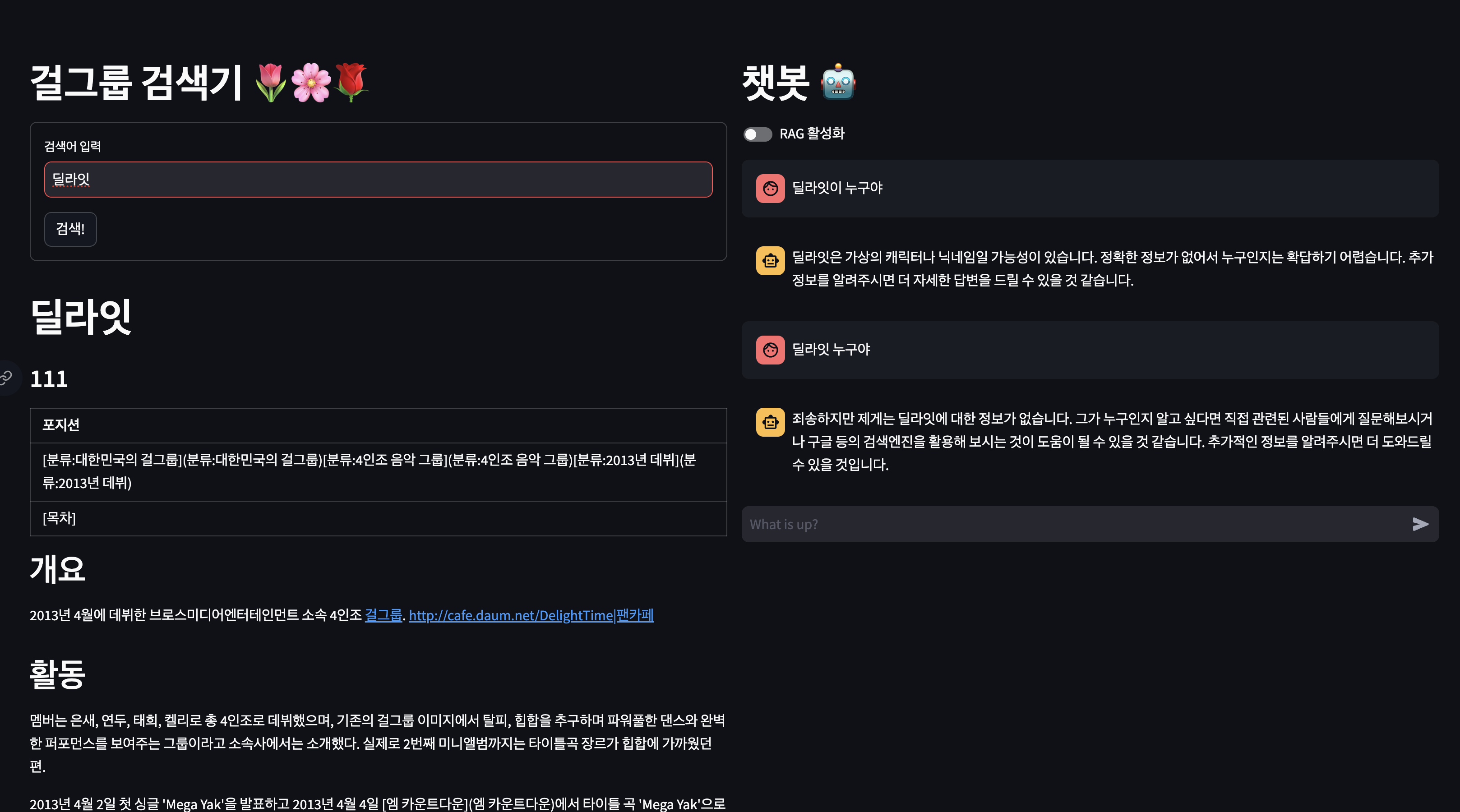
RAG 활성화
잘 요약해서 답변해 줍니다. 👏👏👏
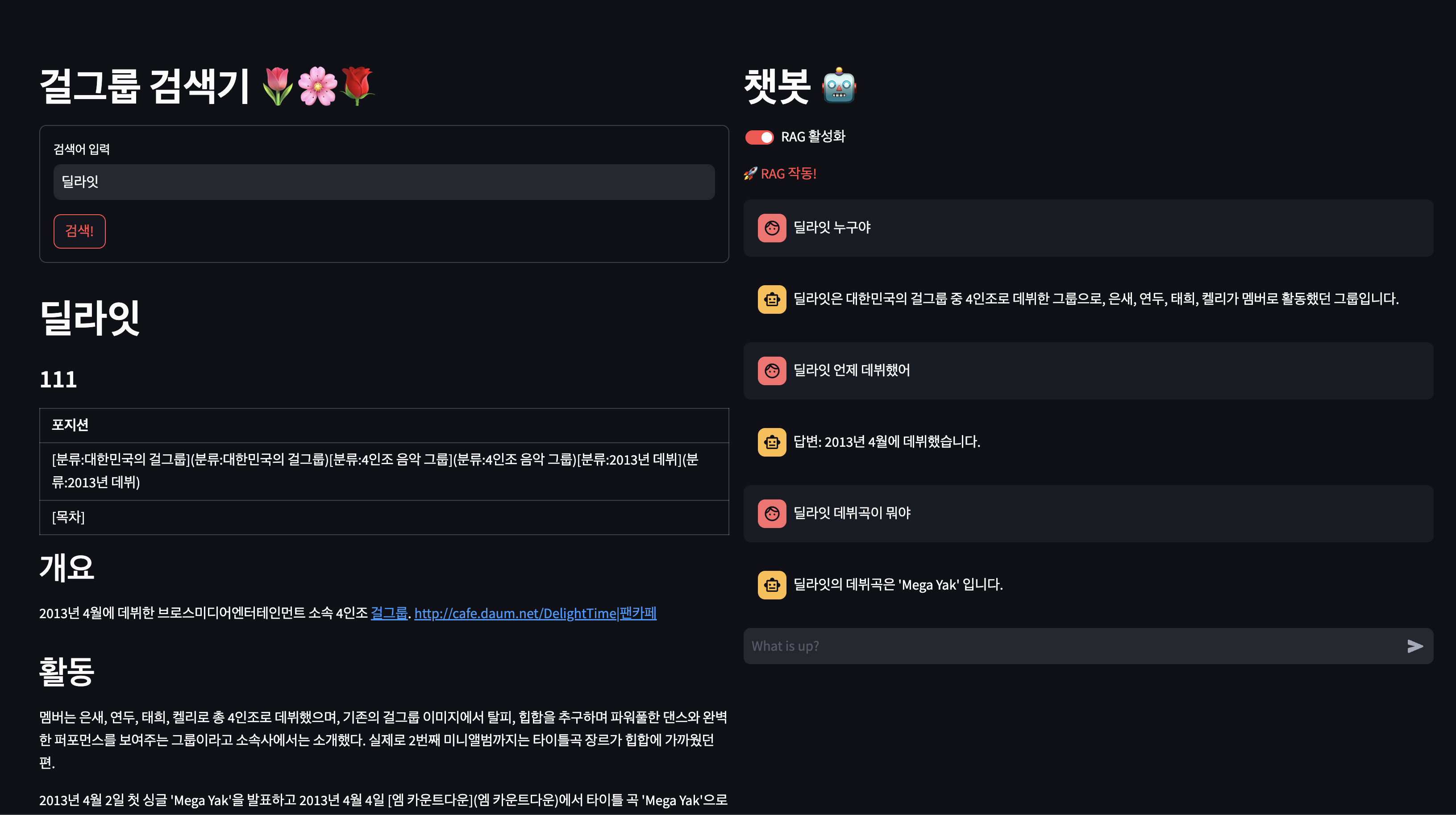
<참고> 걸그룹 딜라잇
Vector Search?
Vector search — Meilisearch documentation
텍스트 임베딩을 통해 의미검색(semantic search)이 가능합니다.
다음 기회에 관련 꿀팁을 정리 해보겠습니다.
꿀팁
- metrics - prometheus 엔드포인트와 호환됩니다.
- 인덱싱 성능을 높일때는 메모리보다 코어가 많을 수록 유리합니다.
다 좋을 수는 없습니다.
meilisearch는 LMDB를 내부 저장소로 활용하고 있기 때문에, LMDB를 알면 특성을 이해하는데 큰 도움이 됩니다. LMDB는 아래와 같은 특징이 있습니다.
- 디스크 IO작업을 최소화 하여 빠른 성능
- 트랜잭션 (ACID) 지원
- 자유로운 스키마 (장점이자 단점)
- 읽기 동시성(Read Concurrency) 지원
- 여러 프로세스에서 동시에 데이터를 읽을 수 있습니다.
- 쓰기 단일 프로세스 제한(Single Writer Process)
- 한 번에 하나의 프로세스만 데이터를 수정할 수 있습니다.
- 다른 프로세스에서 쓰기 작업 중일 때 또 다른 프로세스가 쓰기를 시도하면 실패합니다.
GitHub - meilisearch/charabia: Library used by Meilisearch to tokenize queries and documents
- 메모리 사용량이 많음: MeiliSearch는 모든 데이터를 메모리에 로드하므로 대량의 데이터를 색인화할 때 많은 메모리가 필요합니다. 이는 리소스가 제한된 환경에서 문제가 될 수 있습니다.
- 즉시 갱신 미지원: MeiliSearch는 실시간 색인을 지원하지만, 데이터 변경 시 전체 재색인이 필요합니다. 이는 대량의 데이터를 자주 갱신해야 하는 경우 비효율적일 수 있습니다.
- 스키마 변경 불가능: MeiliSearch에서 한번 정의된 스키마는 변경할 수 없습니다. 스키마를 변경하려면 전체 데이터를 재색인해야 합니다.
- 지원 언어 제한: MeiliSearch는 주로 영어와 서구 언어에 최적화되어 있으며, 동양권 언어에 대한 지원이 부족한 편입니다. - 토크나이저 이슈
- 커뮤니티 규모: MeiliSearch는 비교적 새로운 프로젝트이므로 커뮤니티 규모가 작고, 문서화 및 외부 지원이 부족할 수 있습니다.
- 분산 스케일 아웃이 어렵습니다. ← 애초에 이렇게 사용하려고 하면 안됩니다
