학습 내용
데이터 집합에서 검색뿐만 아니라 데이터를 추가/삭제하는 작업을 자주한다면 검색 속도 외에, 소요 비용 등을 고려하여 알고리즘을 선택하는 것이 좋다. 즉, 어떤 목적을 달성하기 위해 용도나 목적,실행 속도, 자료구조 등을 고려하여 알고리즘을 선정해야 한다.
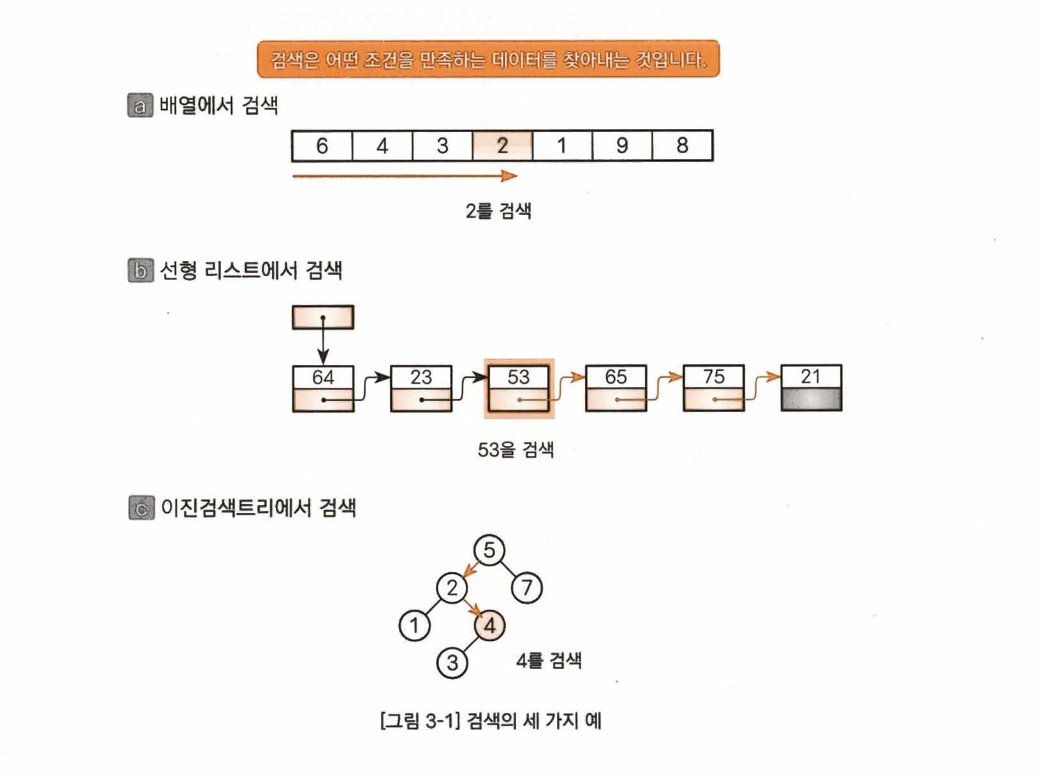
아래의 알고리즘을 활용하여 배열에서의 검색 알고리즘을 공부해보자.
-
선형 검색: 무작위로 늘어서 있는 데이터 모임에서 검색을 수행합니다.
-
이진 검색: 일정한 규칙으로 늘어서 있는 데이터 모임에서 아주 빠른 검색을 수행합니다.
-
해시법: 추가, 삭제가 자주 일어나는 데이터 모임에서 아주 빠른 검색을 수행합니다.
-
체인법: 같은 해시값의 데이터를 선형 리스트로 연결하는 방법
-
오픈 주소법: 데이터를 위한 해시값이 충돌할 때 재해시하는 방법
선형 검색
요소가 직선 모양으로 늘어선 배열에서 원하는 키값을 갖는 요소를 만날 때까지 맨 앞 부터 순서대로 요소를 검색한다. ‘선형 검색(linear search)’ 또는 ‘순차 검색(sequential search)’이라고 한다.
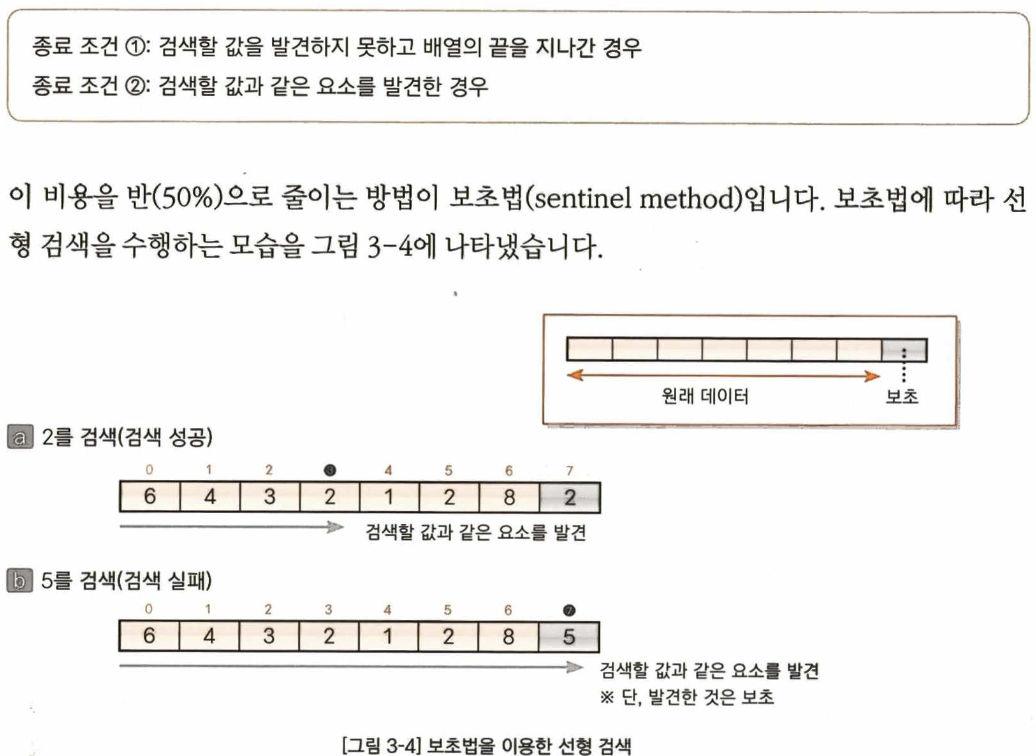
보초법(sentinel method)
찾고자 하는 배열의 맨 끝에 찾고자 하는 key값을 임의로 추가하여 2개의 조건 중 1개를 제외하여 반복 종료에 대한 판단 횟수를 1번 줄여주는 방법이다.
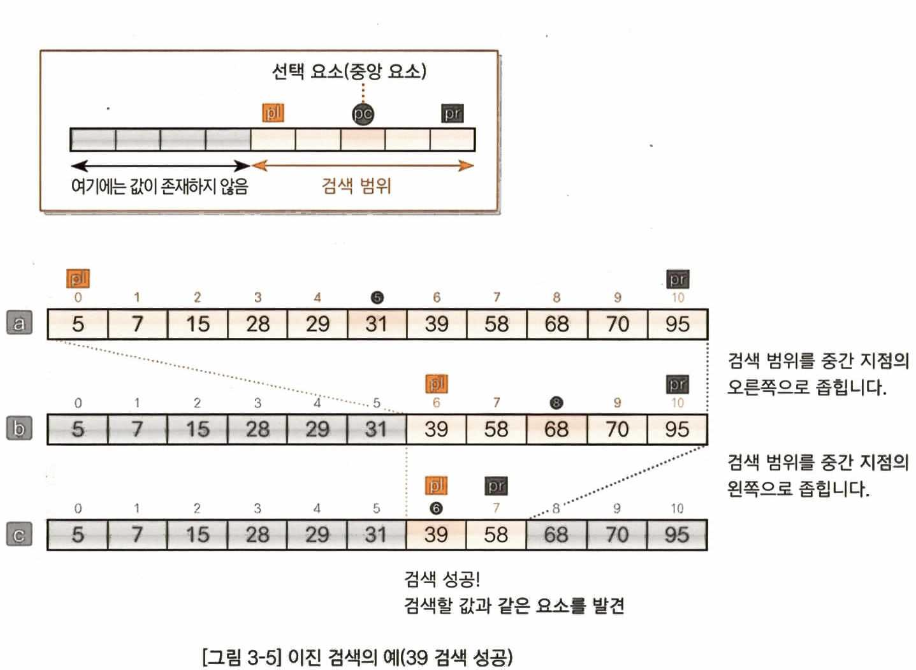
이진 검색
‘이진 검색(binary search)’ 알고리즘을 적용하는 전제 조건은 데이터가 키값으로 이미 정렬(sort) 되어 있다는 것이다. 이진 검색은 선형 검색보다 좀 더 빠르게 검색할수 있다는 장점이 있다.

복잡도
프로그램의 실행 속도는 프로그램이 동작하는 하드웨어나 컴파일러 등의 조건에 따라 달라진다. 알고리즘의 성능을 객관적으로 평가하는 기준을 복잡도(complexity)라고 하는데 다음의 두 가지 요소를 가지고 있다.
- 시간 복잡도(time complexity): 실행에 필요한 시간을 평가
- 공간 복잡도(space complexity): 기억 영역과 파일 공간이 얼마나 필요한지 평가
[참고문헌] Do it! 자료구조와 함께 배우는 알고리즘 입문 - 자바 편 Chapter03
