Graph Convolutional Neural Networks for Web-Scale Recommender System
Pinterest + GraphSage = PinSage
Ying, Rex, et al. Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018. 907 citations.
Hamilton, William L., Rex Ying, and Jure Leskovec. "Inductive representation learning on large graphs." 31st Conference on Neural Information Processing Systems (NIPS 2017). 3378 citations.
해당 논문에서 제안한 모델인 PinSage에 대해 알아봅시다.
 Chapter 19, CS224W
Chapter 19, CS224W
Overview
PinSage는 실제 서비스 되고 있는 핀터레스트(Pinterest)에 적용된 추천알고리즘으로, 학습에 쓰인 데이터는 pin과 board로 구성된 3 bililon 노드와 18 bilion 엣지를 가지고 있습니다.
PinSage는 GCN 모델로, 그래프 데이터에 랜덤 워크(randowm walks)와 graph convolution을 적용한 방법론입니다.
추천시스템에 적용하기 위해서는 효율적인 연산이 중요하기 때문에, GCN 모델을 서빙하기 위한 여러가지 방법을 제안하였습니다.
Introduction
당시에 GCNs(Graph Convolutional Networks)은 추천시스템을 포함한 다양한 분야에 적용되면서 많은 발전이 되었습니다. GCN의 핵심은 이웃들(neighbohoods)로부터 특징 정보를 반복적으로 모으는(aggregate) 방법을 학습하는 것입니다. 이때, convolution이라고 불리는 연산을 사용하여 one-hop 이웃들의 정보를 변형하고(transform) 모으게(aggregate) 됩니다. 이 one-hop convolution layer를 여러 개 쌓음으로써 이웃의 정보를 계속적으로 변형하고 모으기 때문에, 멀리 떨어진 이웃들의 정보까지 닿을 수 있습니다. 기존의 content based RNN 모델과는 다르게, GCN은 contents 뿐만 아니라 그래프 구조까지 활용합니다.
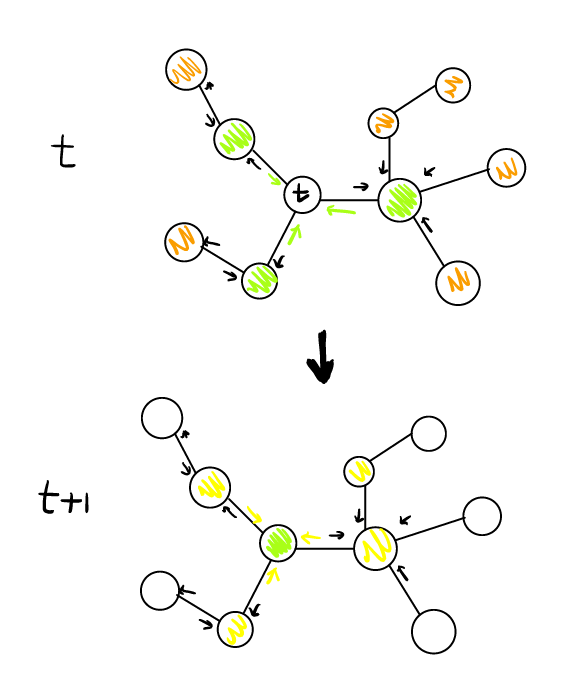
그러나, GCN-based 모델은 scailability가 떨어지기 때문에, 수십억 개의 노드와 엣지를 가지며 시간에 따라 변하는 추천 데이터에 적용하는 것이 매우 어렵습니다.
해당 논문에서는 높은 scailability를 가지고 있는 random walk기반 GCN 모델을 제안하였습니다.
PinSage를 요약하자면 다음과 같습니다.
Scailability
-
On-the-fly convolution (Transductive vs. Inductive)
기존 GCN은 full-graph에서 연산을 진행한 반면, PinSage는 target node를 선정한 뒤 이웃을 sampling하는 방식(computation graph를 생성)으로 진행합니다. 따라서 전체 그래프에 해당하는 연산을 필요로 하는 GCN의 단점을 완화시켰습니다. -
Producer-consumer minibatch construction
Producer와 consumer의 역할을 CPU와 GPU로 나누어 진행하였습니다. CPU를 computation graph 생성을 위한 sampling을 진행하고, GPU는 생성된 computation graph로 모델 학습을 진행합니다. -
Efficient MapReduce inference
MapReduce와 같은 파이프라인을 설계하여 반복적인 연산을 최소화하면서 빠르게 임베딩 벡터를 생성할 수 있습니다.
New techniques
-
Constructing convolutions via random walks
효율적인 연산을 위해 computation graph를 미리 생성한다고 하였습니다. 이때, 무작위하기 이웃을 생성하는 것은 비효율적이기 때문에, short random walk를 사용합니다. -
Importance pooling
Random walk를 활용해 노드들끼리 유사성(similarity)을 구할 수 있습니다. 해당 논문에서는 이 유사성을 importance score로 정의하였으며, 이를 aggretation과 pooling 단계에 사용하여 가중(weighted)연산을 하였고, 46% 성능 증가를 가져왔습니다.
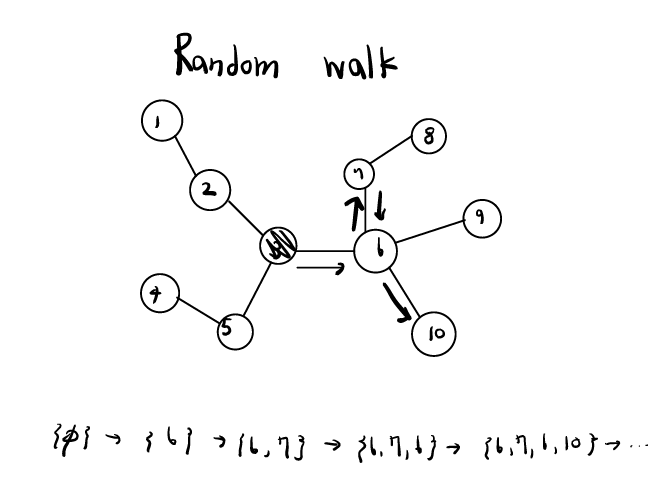
 Figure 1: Overview of our model architecture using depth-2 convolutions
Figure 1: Overview of our model architecture using depth-2 convolutions
- Curriculum training
학습을 진행할 때마다 좀 더 어려운 예시를 모델에 보여줌(curriculum traning)으로써, 12%의 성능 증가를 가져왔습니다.
Method
PinSage의 구조, 학습 방식, MapRudece pipleline에 대해 살펴보겠습니다.
- Node: item (pin and board)
- Feature: visual, textual feature
Problem setup
Pinterest의 contents인 pin은 유저의 주 관심사이며, board는 pin의 collections입니다. 해당 추천시스템은 이러한 pins를 잘 임베딩하고자 하는 것입니다. 임베딩을 위해 그래프를 정의해야 하는데, 여기서는 pin의 집합 와 board의 집합 을 이분 그래프(bipartite graph)로 생성하였습니다.
 Bipartite graph, Chapter 19, CS224W
Bipartite graph, Chapter 19, CS224W
Notations
: set of items
: user-defined contexts
: pin/item
: real-valued attributes (content information, i.e., text and image feature)
Goal
bipartite graph와 node feature 를 활용하여 node embedding을 수행함.
Model Architecture
 Localized convolution
Localized convolution
Step 1: 를 linear layer로 변형함.
Step 2: aggregation/pooling 적용하여 벡터 생성함.
Step 3: 노드의 벡터 와 aggregation된 이웃 벡터 를 concatenate, linear layer로 변형함.
Step 4: nomalization
Inportance-based neighborhoods(Importance pooling)
PinSage에서 핵심인 inportance score에 대해 살펴봅시다. 기존의 GCN과 다르게, PinSage는 타겟 노드에게 상대적으로 많은 영향을 주는 노드들을 선별하여 aggregate/pooling을 진행하였습니다.
Step 1: 타겟 노드 에서 random walk를 시작함.
Step 2: random walk로 방문한 노드들의 방문 횟수를 계산함.
Step 3: 타겟 노드 의 이웃들 중에서 이전 스텝에서 계산한 값 상위 T개를 선출함.
해당 밥법은 두 가지 관점에서 이점을 가져옵니다.
- 메모리를 줄일 수 있다.
- 중요한 이웃들만 고려하여 노드를 업데이트 시킬 수 있다.
또한 Step 2에서 계산한 값을 normarlization을 하여 aggregate/pooling의 weight으로 사용하였습니다.
Stacking convolutions

하나의 Convolution layer 파라미터는 가 있으며, node들끼리 공유하게 됩니다. Algorithm2는 minibatch에 어떻게 convolution layers를 적용하는 지 보여줍니다.
Convolution이 끝난 후 생성된 target node의 representation은 linear layers를 한 번 더 거치게 되고, 최종 output embedding이 만들어지게 됩니다.
모델 파라미터 정리:
각 convolution layer의 weight과 bias:
마지막 linear layer:
Model Training
PinSage는 max-margin ranking loss를 학습에 사용하며, item pair인 을 가깝도록 임베딩하게 됩니다.
수십억 개의 embedding을 학습하기 위해 어떻게 효율적으로 연산을 했는지 살펴보도록 하겠습니다.
Loss function
Basic idea: postive pair의 내적을 최대로 만들고, negative pair의 내적값을 미리 정의한 margin 만큼 거리를 유지하게 만들자.
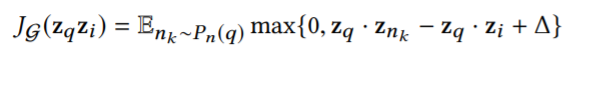 , where 은 negative sample의 분포입니다.
, where 은 negative sample의 분포입니다.
Multi-GPU training with large minibatches
Producer-consumer minibatch constructions
Sampling negative items
PinSage는 학습의 효율을 개선하기 위해 500개의 negative sample을 minibatch마다 공유할 수 있도록 하였습니다.
해당 논문에서는 두 가지의 sampling 방법을 제안하였습니다.
- 무작위 샘플링 (unifonly sample)
전체 아이템세트에서 무작위로 negative item을 뽑는 것으로, postive와 negative를 구분하기 매우 쉽다. - Hard negative sampling
"hard" negative item을 negative sample로 정하여 학습시키 방법으로, positive sample은 아니지만, 상대적으로 가까운 negative sample을 뽑는 방법이다. Personalized PageRank score(C. Eksombatchai, et al.(2018))를 활용하여 item의 score를 결정하게 되고, 2000-5000위 사이의 ranked item을 뽑게 된다.
논문에서는 hard negative sample을 학습에 사용하면, 수렴을 위해 2배의 epoch이 요구된다고 하였습니다. 이를 해결하기 위해, 처음부터 har sample을 사용하는 것이 아닌, 학습을 진행할수록 hard negative sample을 하나씩 추가하는 curriculum training을 적용하였습니다.
 Figure 2: Random negative examples and hard negative examples
Figure 2: Random negative examples and hard negative examples
Node Embeddings vis MapReduce
모델 학습이 끝난 후에, 학습 데이터의 모든 아이템과 그 외의 아이템을 임베딩하는 것은 계산적으로 매우 어려운 일입니다. 따라서 해당 논문에서는 MapReduce approach를 개발하였으며, 반복적인 계산을 줄여 효율적인 연산이 가능하도록 하였습니다.
 Figure 3: Node embedding data flow to compute the first layer representation using MapReduce
Figure 3: Node embedding data flow to compute the first layer representation using MapReduce
Experiments
평가를 위해 두 가지 태스크를 진행하였습니다.
-
Recommending related pins
Related pin을 추천하기 위해 임베딩 공간에서 k nearest neighbor를 선택합니다. -
Recommending pins in a user's home/news feed
Pin을 추천하기 위해, 유저가 가장 최근에 추가한 아이템과 임베딩 공간에서 가장 가까운 아이템을 추천합니다.
Chapter 19, CS224W
Feature used for learning
각각의 pin은 text(title)과 image 데이터와 관련되어 있습니다. 따라서 visual embedding(VGG-16, ), textual embedding (Word2Vec, )를 concatenate하여 node feature를 생성합니다.
Baselines for comparison
- Visual embedding: 이미지 임베딩 공간에서 nearest neighbor 사용
- Annotation embedding: annotation 임베딩 공간에서 nearest neighbor 사용
- Combined embedding: visual + annotation 벡터에 2-layer multi-layer 모델을 사용
- Graph-based method: random-walk-based 방법을 사용하여 타겟 pin의 top K 이웃을 추천
 Table 1: Hit-rate and MRR for PinSage and content-based deep learning baselines
Table 1: Hit-rate and MRR for PinSage and content-based deep learning baselines
Conclusion
- 해당 논문은 random-walk graph convolutional network를 활용한 PinSage라는 모델을 제안하였습니다.
- PinSage는 기존의 GCN 모델이 가지고 있던 scailability의 한계를 극복하기 위해 inductive setting과 MapReduce와 같은 알고리즘을 활용하였습니다.
- 실제 성능과 효율성을 측정하기 위해 A/B test를 진행하였고, 좋은 결과를 보여주었습니다.
