피어 세션
피어 세션 시간이 1시간이 줄었다. 거기다, 생각보다 강의의 비중이 많아서 대회 관련이야기와 강의 내용 이야기를 하면 1시간이 금방 갔던 것 같다.
대회 관련 이야기
object detection 대회가 시작되었다. 강의, EDA, mmdetection 라이브러리를 이용하여 여러 가지 모델을 탐색하는데 거의 모든 시간을 쓴 것 같다.
EDA
데이터는 재활용 쓰레기 데이터셋 / CC BY 2.0 coco dataset의 형태로 주어 졌다.
모든 bbox로 이루어진 object들을 기준으로 갯수를 살펴보니 어떤 class는 6000장이 넘는 반면, 어떤 class는 150장 정도밖에 없었다. 즉, class imbalance가 심했다.
또한 bbox가 서로 겹치는 형태의 데이터도 많았다. 이러한 문제들을 해결하기 위해 팀원들과 이야기를 해보고 있다.
model
mmdetection library의 yolov3, faster r-cnn, swin을 사용해 보았다.
yolov3같은 경우에는 one-stage detection 모델이지만 real-time task를 마주칠 때를 대비해 연습삼아 사용해보았는데, 결과값이 매우 처참했다. yolov4이상의 모델을 찾던가, 다른 one-stage detection model을 찾아보아야 할 것 같다.
faster r-cnn과 swin은 wandb를 통해 비교를 해보았는데, SGD optimizer를 사용하였고, learning late는 faster r-cnn은 0.02, swin은 0.002를 사용하였고, scheduler는 stepLR을 사용하였다.
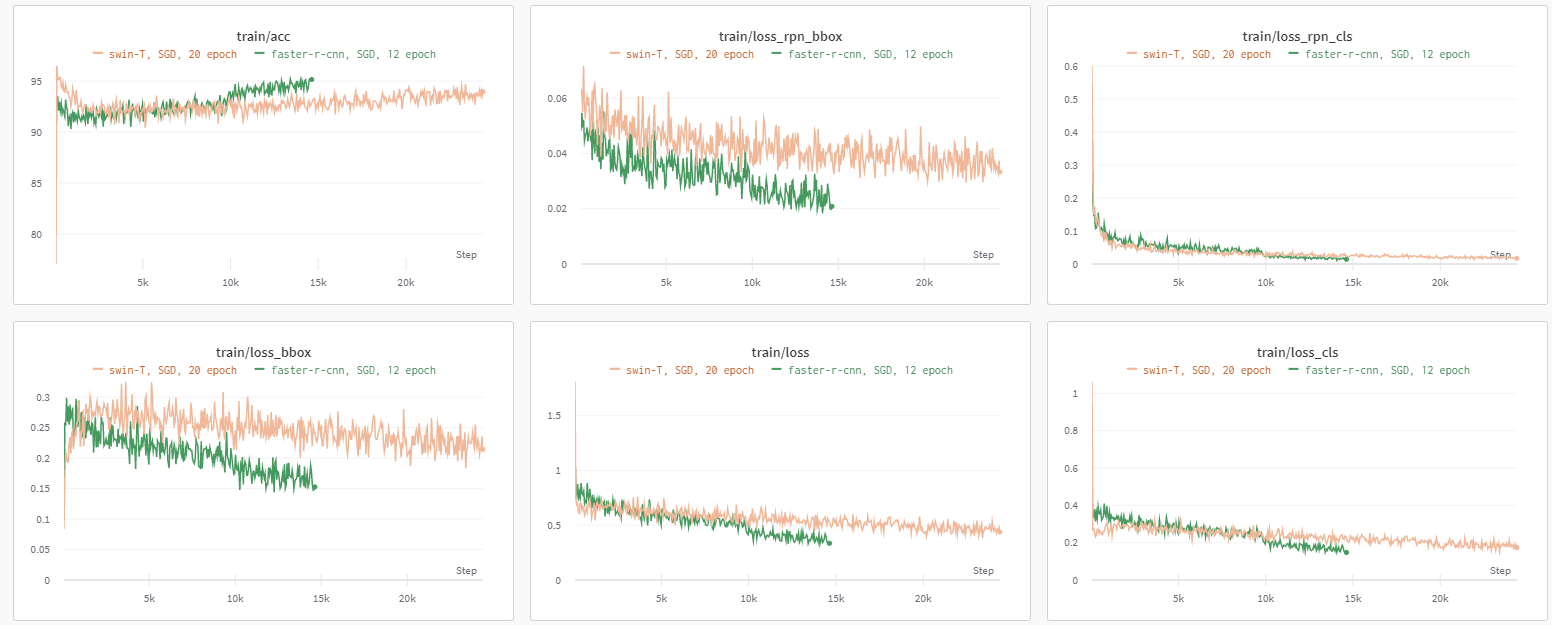
faster r-cnn이 swin보다 성능, loss값이 향상되었지만, swin이 transformer 기반의 모델이라 그런지 리더보드에서의 성능이 압도적으로 높게 나왔다.
