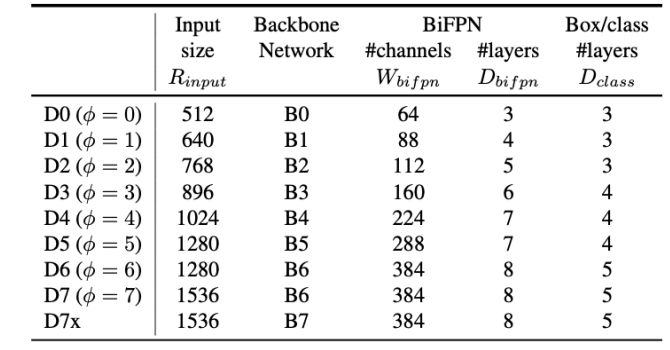
EfficientDet
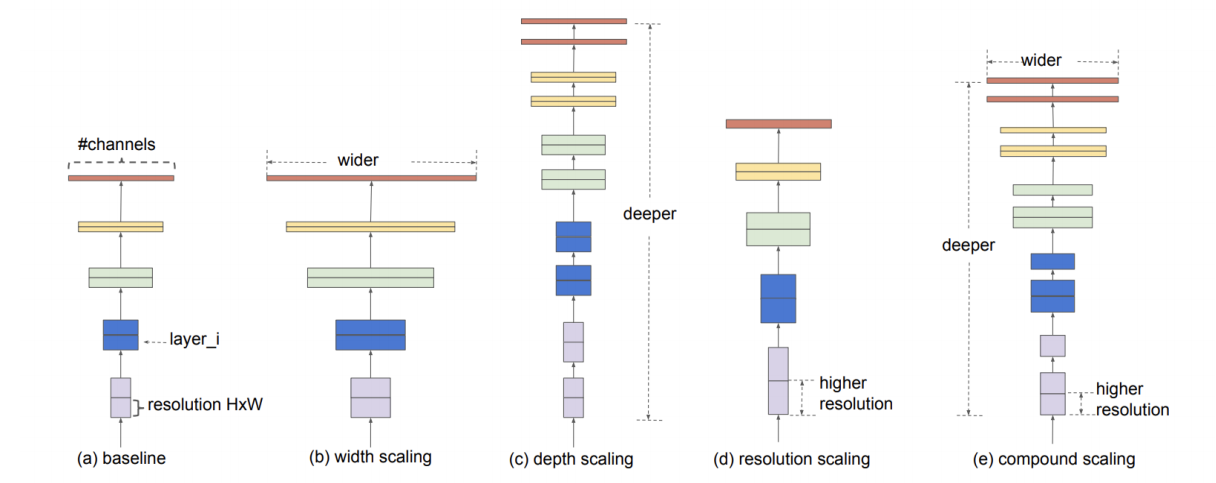
EfficientNet
모델들의 파라미터 수가 점점 많아지고 있다. ConvNet은 점점 더 커짐에 따라 정확해지고 있다.
- 2014 ImageNet winner – GoogleNet ; achieves 74.8% top-1 accuracy with about 6.8M parameters
- 2017 ImageNet winner – SENet ; achieves 82.7% top-1 accuracy with about 145M parameters
위와 같은 결과를 보면, 파라미터가 25배 정도 늘어난 대신, accuracy가 8%정도 늘어난 것을 확인할 수 있다.
사실, 모델 정확도를 높이기 위해 크기를 무한정 늘리는 것은 한계가 있다. 현업에서는 hardware resource의 제한도 있고, 속도 또한 중요하기 때문이다. 그래서, 효율성과 정확도의 trade-off를 통해 모델 사이즈를 줄이는 것이 일반적이다.
EfficientNet의 논문은 아주 큰 SOTA ConvNet의 efficiency를 확보하는 것을 목표로 한다. 큰 모델에 대해서는 어떻게 모델을 압축시킬지가 불분명했던 문제를 모델 스케일링을 통해 어느정도 해결하였다.
-
width scaling
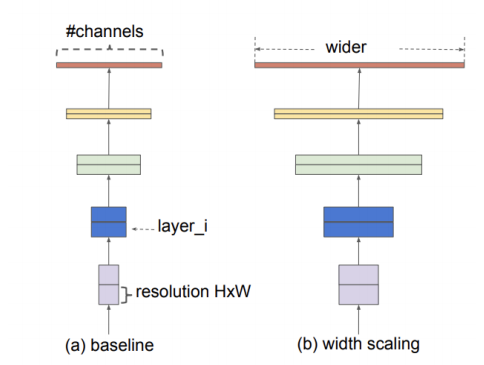
- 네트워크의 width를 스케일링하는 방법은 작은 모델에서 주로 사용된다. (ex. MobileNet, MnasNet )
- 더 wide한 네트워크는 미세한 특징을 잘 잡아내는 경향이 있고, 학습도 쉽다,
- 하지만, 극단적으로 넓지만 얕은 모델은 high-level 특징들을 잘 잡지 못하는 경향이 있다.
-
Depth Scaling
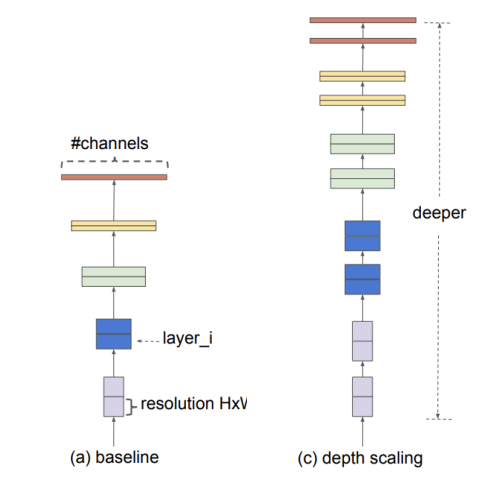
- 네트워크의 깊이를 스케일링하는 방법은 많은 ConvNet 에서 쓰이는 방법이다.
- DenseNet, Inception-v4
- 깊은 ConvNet은 더 풍부하고 복잡한 특징들을 잡아낼 수 있고, 새로운 task에도 잘 일반화할 수 있다.
- 하지만 깊은 네트워크는 gradient vanishing 문제가 있어 학습이 어렵다.
- 네트워크의 깊이를 스케일링하는 방법은 많은 ConvNet 에서 쓰이는 방법이다.
-
Resolution Scaling
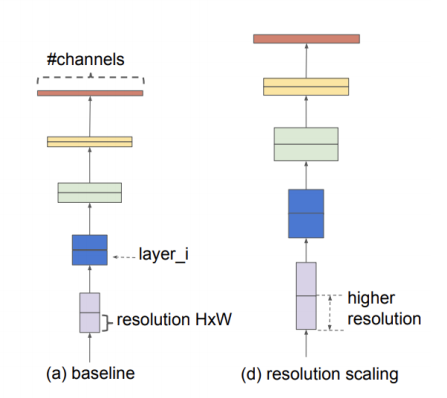
- 고화질의 input 이미지를 이용하면 ConvNet은 미세한 패턴을 잘 잡아낼 수 있다.
- 최근 Gpipe는 480x480 이미지를 이용하여, ImageNet에서 SOTA를 달성하였다.
-
object function
모델의 memory는 target memory보다 작거나 같아야 하고,
모델의 flops 수는 target flops보다 작거나 같아야 한다.
를 갖춘다는 조건 하에, Accuracy()를 최대한 높히는 방법을 찾는다.

-
Observation
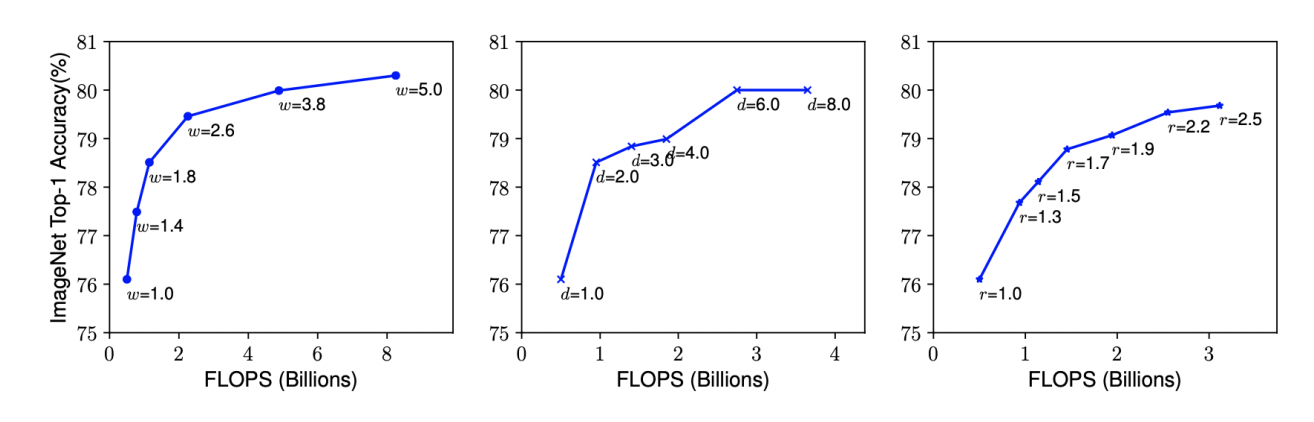
- 네트워크의 폭, 깊이, 혹은 해상도를 키우면 정확도가 향상된다. 하지만 더 큰 모델에 대해서는 정확도 향상 정도가 감소한다
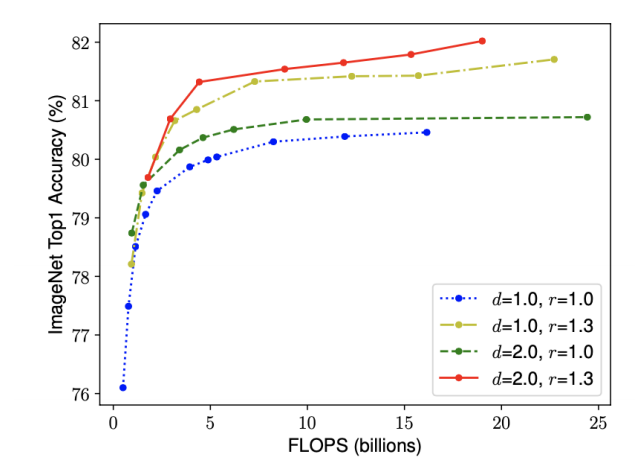
- 더 나은 정확도와 효율성을 위해서는, ConvNet 스케일링 과정에서 네트워크의 폭, 깊이, 해상도의 균형을 잘 맞춰주는 것이 중요하다.
- 네트워크의 폭, 깊이, 혹은 해상도를 키우면 정확도가 향상된다. 하지만 더 큰 모델에 대해서는 정확도 향상 정도가 감소한다
-
compound scaling method
efficientNet을 개발하면서 위와 같은 문제들을 해결할 수 있으면서, depth, width, resolution을 적절하게 조작할 수 있는 방법을 제안한다. 그 것이 compound scaling method이다.
depth :
width :
resolution : 는 다음과 같은 조건을 갖는다.
efficientNet-b0
- MnasNet에 영감을 받음
- Accuracy와 FLOPs를 모두 고려한 nerual network을 개발함
- Nas 결과, EfficientNet-B0은 아래 사진과 같다.

다른 𝜙를 사용해 scale up한 것들을 efficientNet-B1~ B7이라고 부른다.
- 특징
- = 1로 고정
- 를 small grid search를 통해 범위를 정하고, 휴리스틱하게 값을 찾는다.
- compound scaling method를 만족한다.𝛼 = 1.2, β = 1.1, 𝛾 = 1.15 under constraint of
efficientDet
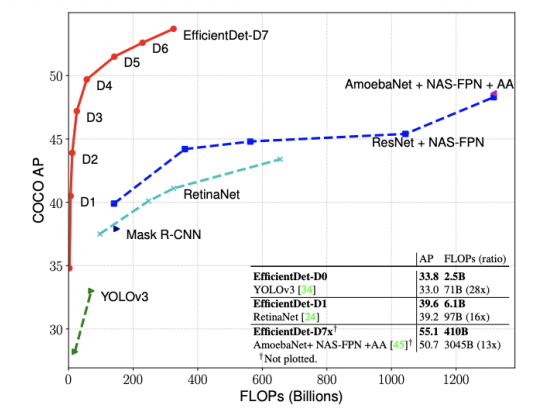
object detection은 특히 속도가 중요하다. 모델이 실생활에 사용되기 위해서는 모델의 사이즈와 대기 시간에 제약이 있기 때문에, 모델의 사이즈와 연산량을 고려해 활용 여부가 결정되기 때문이다. 이러한 제약으로 인해 Object Detection에서 Efficiency가 중요해지게 됨
- 1stage model, Anchor를 없애는 cornetNet 등이 등장했지만, accuracy가 낮게 나온다는 단점이 있다. 자원의 제약이 있는 상태에서 더 높은 정확도와 효율성을 가진 detection 구조를 만드는 것에 efficientNet이 매우 유용하다는 것을 알게 되자, efficientDet이 등장하였다.
efficientDet 발전 과정
1) Efficient multi-scale feature fusion
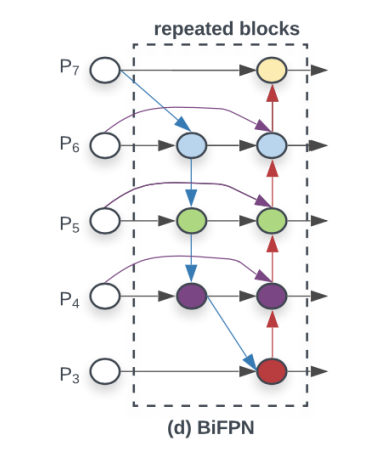
- 기존의 FPN을 기반으로 한 Network에서는 high level feature와 low level feature를 더할 때 channel과 resolution만 맞추어 단순합을 했다. EfficientDet에서는 단순합 대신 가중합(Weighted Feature Fusion)
방법으로 BiFPN(bi-directional feature pyramid network)를 채택하였다. 또한, 모델의 Efficiency를 향상시키기 위해 다음과 같은 cross-scale connections 방법을 이용하였다.
2) 기존의 모델들은 무작정 크기를 키우는 것에 집중하였다.
- 더 좋은 성능을 위해서는 더 큰 backbone 모델을 사용해 detector의 크기를 키우는 것이 일반적이다.
- EfficientDet은 accuracy와 efficiency를 모두 잡기 위해, 여러 constraint를 만족시키는 모델을
찾고자 하였다. - 따라서 EfficientNet과 같은 compound scaling 방식을 제안하였다.