모델 개발 프로세스는 목적이 Research와 production인가에 따라 다르다. Research는 보통 자신의 컴퓨터, 서버 인스턴스 등에서 실행하며, 학습된 모델을 서비스 단계에서 사용할 수 있도록 만드는 과정이 필요하다. 이를 production 환경에 모델을 배포한다고 표현한다.
production은 서비스 단계에서 활용할 수 있게 만드는 과정이다. 이 때 production를 위한 개발에서는 data쪽으로 문제가 research를 위한 개발보다 많을 수 밖에 없다.
- 모델의 결과값이 이상한 경우가 존재할때
- 원인 파악이 필요하다
- input data가 이상값일 때
- Research할 땐 Outlier로 제외할 수 있지만, 실제 서비스에서는 제외가 힘든 상황이 올 수 있다.
- 모델의 성능이 변경될 때
- 서비스를 하면서 data가 변하기 때문에 등의 이유로 모델의 성능이 바뀔 수 있다.
- 이를 판단하기 위해 예측값과 실제 레이블을 알아야 한다. 그러나 정형 데이터에서는 알 수 있지만, 비정형 데이터에서는 이것을 찾기 힘들 수 있다.
- 새 모델이 더 좋지 않을 때
- 이전 모델을 다시 사용하여야 한다. 그러므로 이것을 다시 사용하기 위한 작업이 필요하다.
- Research 환경에서 성능이 더 좋았던 모델이 production 환경에서는 더 좋지 않을 수 있다.
- 그 외의 다양한 이슈도 존재한다.
이와 같은 문제들을 해결하여야 한다.
MLOps = ML (Machine Learning) + Ops (Operations)
머신러닝 모델을 운영하면서 반복적으로 필요한 업무를 자동화시키는 과정으로, 머신러닝 모델 개발(ML Dev)과 머신러닝 모델 운영(Ops)에서 사용되는 문제, 반복을 최소화하고 비즈니스 가치를 창출하는 것을 목표로 한다.
| Research ML | Production ML | |
|---|---|---|
| 데이터 | static | Dynamic |
| 중요 요소 | 성능 | 성능+속도+해석가능여부 |
| 도전 과제 | sota, 새로운 구조의 모델 | 안정적인 운영, 전체 시스템 구조 |
| 학습 | 모델 구조, 파라미터 기반 재학습 | 시간의 흐름에 따라 재학습 |
| 목적 | 논문 출판 | 서비스에서 문제 해결 |
| 표현 | offline | online |
MLOps Component
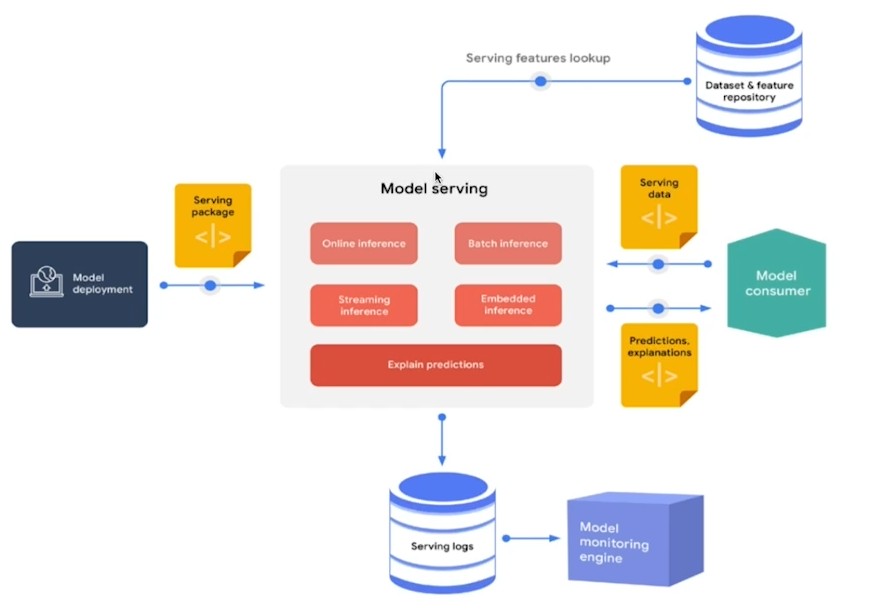
- cloud
특정 회사는 클라우드를 사용하지 못하는 경우가 있지만(금융권 등) 대부분 클라우드를 활용한다.
클라우드 : AWS, GCP, Azure, NCP 등
온 프레미스 : 회사나 대학원의 전산실에 서버를 직접 설치

- Batch Serving
Batch Serving은 많은 데이터을 일정 주기로 예측을 하는 것을 뜻하며, Jupyter Notebook에서 실행하는 방식은 대부분 Batch Serving으로 쉽게 변경이 가능하다.(Dataframe의 데이터를 한번에 예측)
반대로 실시간으로 예측하는 것을 Online serving이라고 한다.
model Management
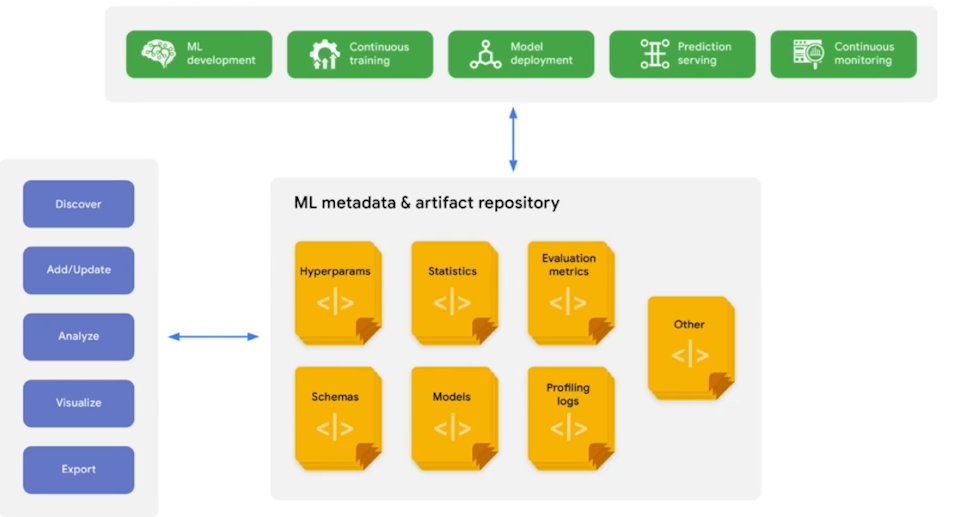
캐글 등에서는 모델의 성능을 기록하면서 대회를 수행하는 경우가 많다. 현업에서는 해당 모델을 가지고 다시 학습하거나 배포 하는 등의 경우가 많기 때문에 Management 도구들을 이용하는 것이 좋다.
대표적으로 mlflow, wandb등이 있다.
Feature Store
Feature store는 feature들을 집계한 것을 뜻하며, 모델을 만들 때 Feature store를 사용하게 된다. 이로 인해 데이터 전처리 시간을 줄일 수 있다.
주로 정형 데이터에서 많이 사용하지만, 이미지 등과의 비정형 데이터에서도 사용할 가능성이 있다. 이 때, 이미지 등 비정형 데이터는 어떻게 이를 저장할 지가 중요하다.
FEAST등을 사용한다. FEAST는 feature store를 어떻게 만들고, 어떻게 가져올지를 설정한다.
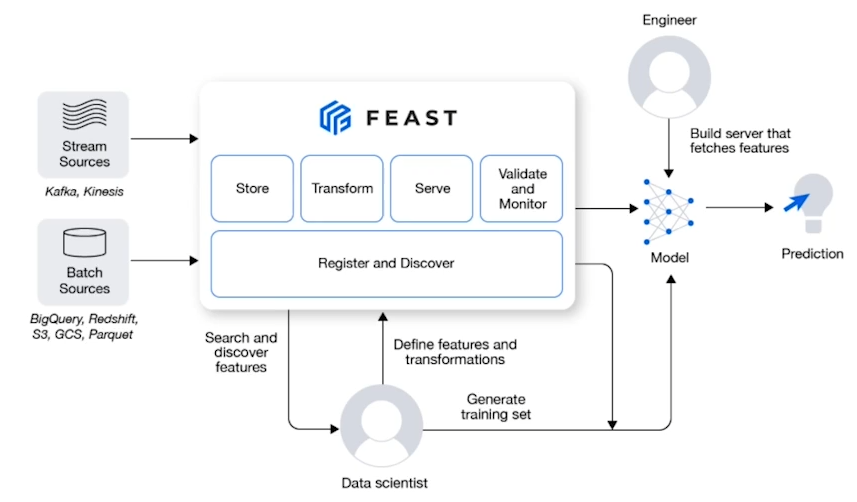
Stream Sources: 실시간 예측
Batch Sources : data warehouse 등에서 저장된 feature
Data Validation
Research와 production의 분포 차이가 어떤지 파악해야 할 필요가 있다.
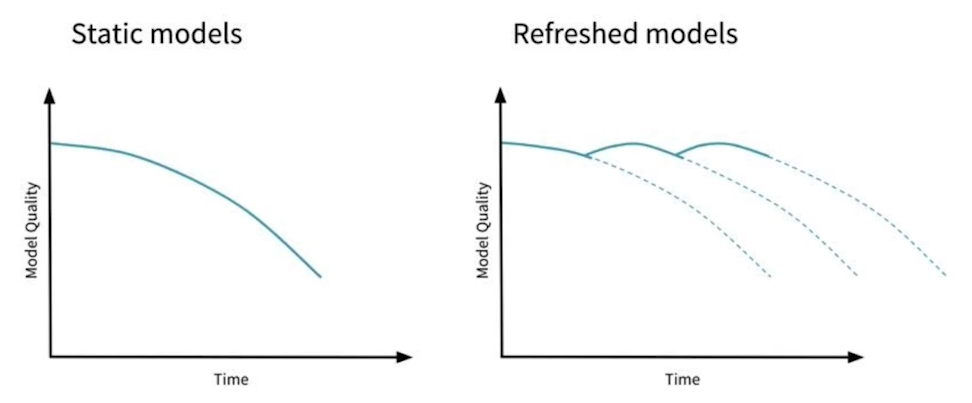
static model은 시간에 따라 성능이 낮아지지만 refreshed model은 재학습을 통해 성능을 유지할 수 있도록 한다.
TFDV(Tensorflow data validation), AWS Deequ등이 있다.
**그 외에도 Continuous Training(새 데이터가 들어올 때 등의 이유로 재학습), Monitoring, AutoML등이 있다
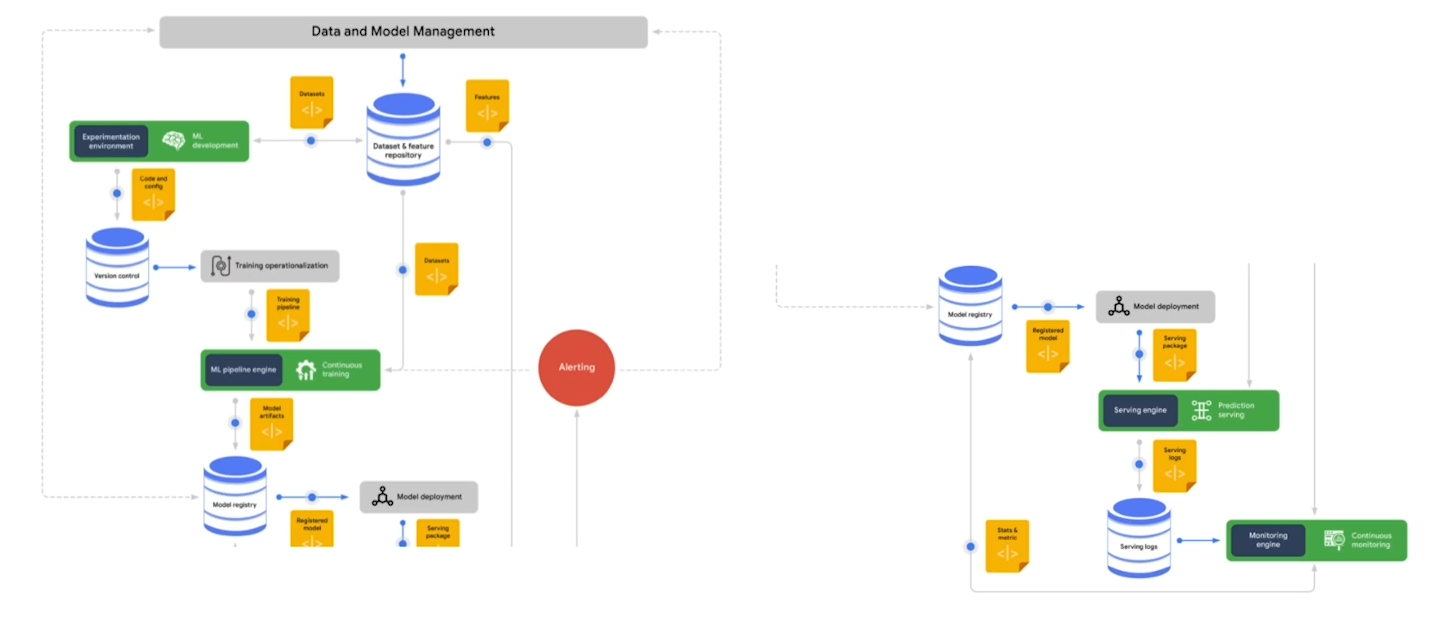
MLops는 꾸준이 발전하고 있기 때문에 머신러닝 모델을 직접 운영하면서 신경써야 하는 부분을 생각하는 것이 좋다.
MLOps는 회사의 비즈니스 상황과 모델 운영 상황에 따라 우선 순위가 달라지기 때문에 앞선 모든 요소가 항상 존재해야 하는 것은 아님을 꼭 인지하기!
MLOps를 처음부터 진행하는 것이 오히려 비효율적일 수 있다. 처음엔 작은 단위의 MVP(Minimal Value Product)로 시작해서 점점 운영 리소스가 많이 소요될 때 하나씩 구축하는 방식을 활용하는 것이 좋다.
