[Paper review] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
0. Abstract
- Transformer가 NLP 태스크에서는 우수한 성능을 보이나 CV에서는 한계를 지님
- Vision에서는 attention + CNN 결합하여 사용함 → CNN에 의존
- 본 논문에서는 pure Transformation 만으로 이미지 분류 성능이 좋음을 보여줌 (CNN 의존성에서 탈피)
1. Introduction
-
Transformer와 같은 self-attention 기반 아키텍처는 NLP에서 강세를 보임, 하지만 CV 분야에서는 여전히 convolution 아키텍처가 우세함
-
NLP에서의 성공에서 영감을 받아 CNN + self-attention을 적용하거나 전체 구조를 self-attention으로 실험한 연구들이 등장
→ 이론적으로는 효율적이었으나 어텐션 계산 방식으로 널리 적용되지는 못함
-
-
large scale 이미지 인식 분야에서는 ResNet이 SOTA로 남아있음
-
이미지에 트랜스포머를 적용하는 Vision Transformer를 위해 트랜스포머 구조를 약간 수정함
- 이미지를 patch들로 분할 후, 선형 임배딩 시퀀스를 input으로 전달
- image patch = NLP token
- 이미지를 patch들로 분할 후, 선형 임배딩 시퀀스를 input으로 전달
-
mid-sized 데이터셋으로 훈련 시 유사한 사이즈의 ResNet 아키텍처 모델들에 비해 낮은 정확도
- 트랜스포머 모델은 CNN에 비해 적은 Inductive bias를 가져 데이터셋이 적을수록 일반화에 약한 성능을 보임
- 큰 데이터셋으로 했을 때에는 ViT에서 훌륭한 결과를 보임
- 트랜스포머 모델은 CNN에 비해 적은 Inductive bias를 가져 데이터셋이 적을수록 일반화에 약한 성능을 보임
2. Related Work
- NLP
- CV
- ViT의 차별성
- ImageNet 데이터셋보다 더 큰 데이터에서 진행
- ResNet 기반 CNN보다 더 좋은 성능을 보일 수 있음
3. Method
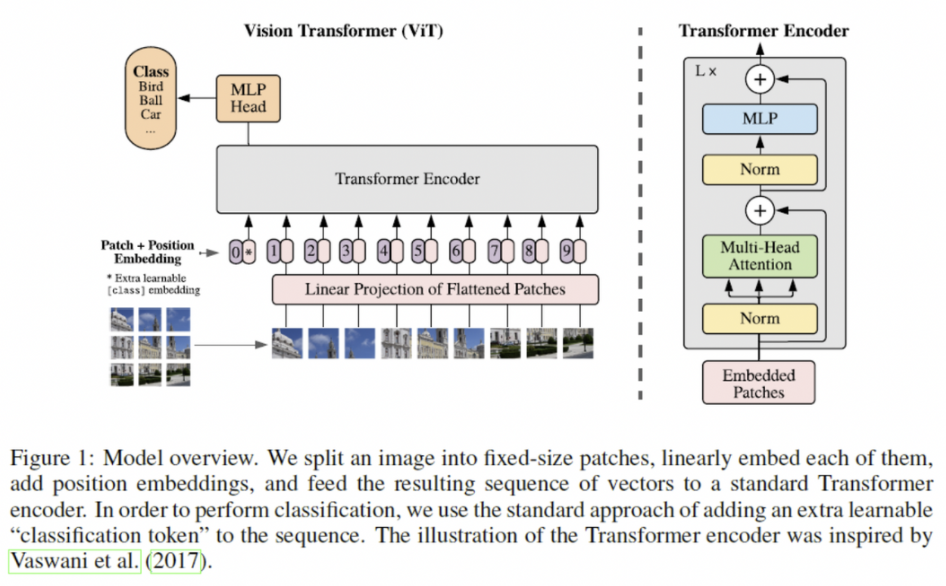
model overview
이미지를 고정된 사이즈 patch로 분할
선형 임베딩 시키고 + 포지션 임베딩
트랜스포머 인코더에 벡터 시퀀스 심기
→ classification을 위해서는 “classification token” 추가
3.1 Vision Transformer (ViT)
overview
토큰 임베딩으로 된 1차원 시퀀스를 input으로 받음
고정 patch로 나뉜 이미지를 flatten 하여 1차원으로 형성
1차원으로 바뀐 이미지를 Transformer 적용 가능한 D차원의 벡터로 매핑 → 이미지 형태 변경
- BERT의 [class] 토큰과 유사하게 임베딩된 패치들의 맨 앞에 하나의 학습가능한 class 토큰 임베딩 벡터 추가
- 공간적 정보를 위해 postion 임베딩 추가
-
2D-aware 위치 임베딩을 사용했지만 유의미한 성능을 보이지 못해, learnable 1D 위치임베딩을 사용함
→ 벡터 임베딩 최종값이 도출되면 이 시퀀스가 인코더의 input이 됨
-
- Transformer 인코더는 multiheaded self-attention과 MLP blocks의 교차구성
- MLP는 GELU를 활성화 함수로 사용하는 2개의 hidden layer을 포함하여 구성
- hidden layer는 3072/4096/5120 하이퍼 파라미터 옵션
- MLP는 GELU를 활성화 함수로 사용하는 2개의 hidden layer을 포함하여 구성
Hybrid Architecture
- 하이브리드 모델에서는 CNN을 통과한 feature map을 input으로 사용할 수 있음
- 1*1 사이즈로 patch 설정하여 flatten하면 바로 Transformer 차원 D로 projection
3.2 Fine Tuning and Higher Resolution
- pre-train된 ViT 데이터셋을 fine-tuning하여 사용
- fine-tuning 시 pre-training 된 것보다 고해상의 파일을 사용하면 성능이 높아짐
- patch 사이즈는 유지하되 시퀀스는 늘어남
- 이 때 position 임베딩은 필요없어짐
4. Experiments
4.1 Setup
dataset : ILSVRC-2012 ImageNet, JFT etc
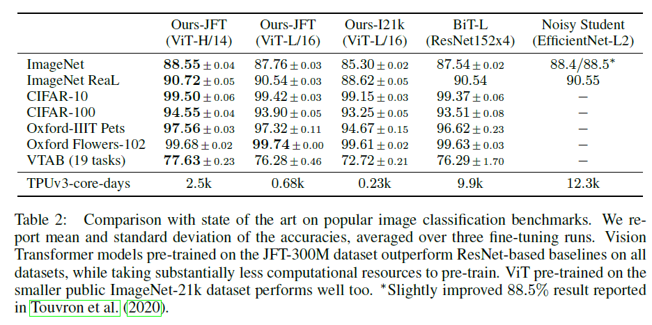
4.2 Comparison to SOTA
4.3 Pre-training Data Requirements
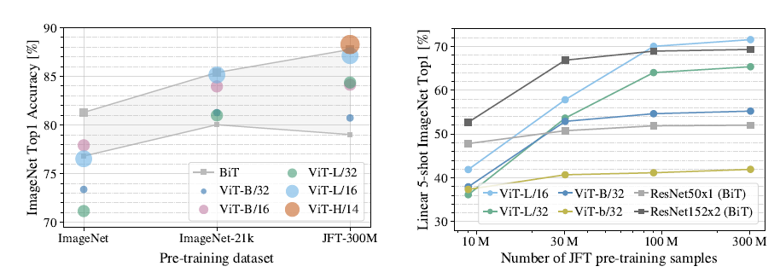
- ViT는 Inductive Bias가 기존 CNN 계열보다 부족하기 때문에 사전학습 데이터셋 크기가 클 때 좋은 성능을 보여줌.
- 이때 사전학습 시 사용되는 데이터셋 크기가 ViT에 어떤 영향을 미치는지에 대한 실험을 진행.
- ImageNet (1.3M), ImageNet21K (14M), JFT (300M)에 사전학습하고 ImageNet 데이터셋에 대해 분류 성능 평가를 진행.
- 이때 가장 작은 데이터셋에서 사전 학습 수행 시, weight decay, dropout, label smoothing과 같은 regularization을 적용함
4.4 Scaling Study
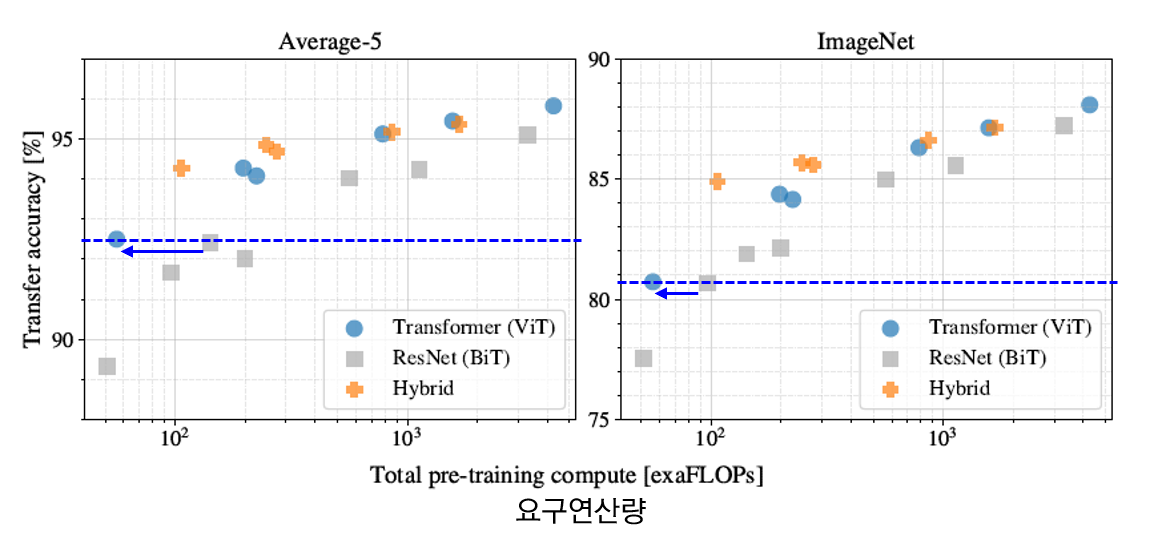
- JFT 300M 데이터셋에서 모델 별로 계산량/성능을 비교하는 실험 진행 → 하이퍼 파라미터 고정
- ViT 계열은 ResNet 계열에 비해 동일 성능을 얻기 위한 연산량이 더 적음
- hybrid의 경우, 연산량이 증가하긴 했으나 ViT보다 더 좋은 성능을 보여줌
- ViT 계열은 ResNets 계열과 달리 모델이 커짐에도 불구하고 성능 포화 없이 지속적으로 성능이 증가함
5. Conclusion
- 의의
- Transformer 모델을 image recognition에 직접 적용
- self-attention을 CV에 적용한 다른 논문들과 달리 image-specific한 inductive biases를 아키텍처에서 제외함
- image = sequence patch로 보고, NLP에서처럼 인코더에 적용함
- large 데이터셋에서 아주 좋은 성능을 보임!
- 한계
- detection / segmentation에서는 아직 한계를 지님
- self-supervised learning 방법론을 성공적으로 적용시킬 방안을 탐색할 필요가 있음
- 모델 구조 개선 필요
