[semantic segmentation model] U-Net
Semantic Segmentation 알고리즘
Overlap tile 기법 : U-Net의 main idea
Contracting Path : 이미지의 context 포착 (이미지의 왼쪽, encoding으로 해석)
Expansive Path : feature map을 upsampling 하고 1)에서 포착한 feature map의 context와 결합 → 이는 더욱 정확한 localization을 하는 역할(decoding)
- FCN과 차이점 1) upsampling 과정에서 feature channel 수가 많다. → context를 resolution successive layer에게 전파할 수 있음을 의미 2) 각 Convolution의 valid part만 사용한다.
*valid part : full context가 들어있는 segmentation map → Overlap-tile 기법을 사용하여 원활한 segmentation이 가능하도록 함
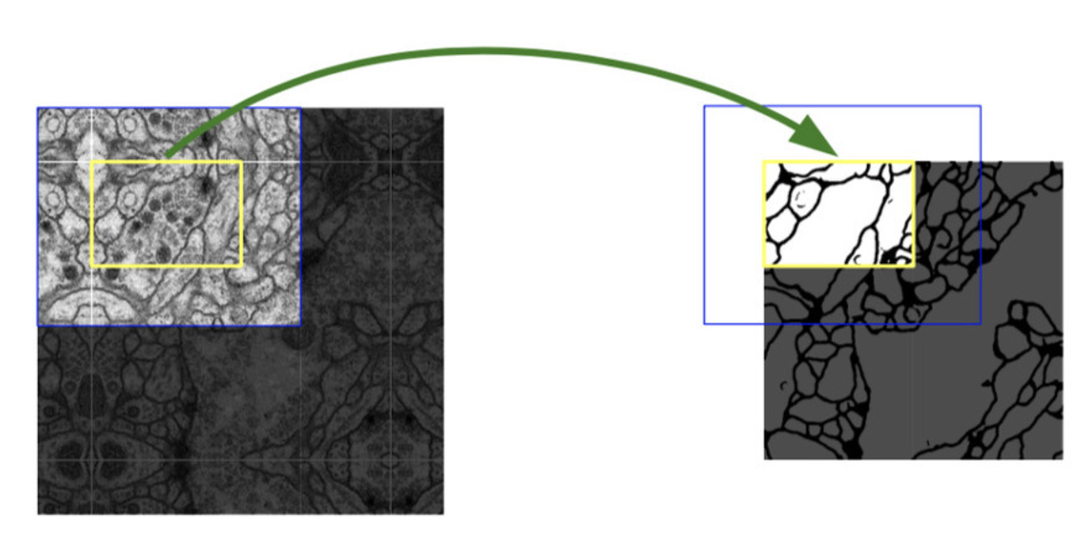
- Blue tile과 Yellow tile이 서로 Overlap되어 있음을 확인할 수 있음 → Blue area에 기반하여 Yellow area의 Segmentation을 prediction 했음을 확인 → missing data는 mirroring을 통하여 extrapolation *extrapolation : 다른 변수와의 관계에 기초하여 변수 값을 추정. Pooling을 할 때, 0으로 이루어진 값으로 인해 값이 사라지게 되는데 이 사라진 값을 추정하겠다는 의미
Data Augmentation
: U-Net은 ****적은 데이터로 충분한 학습을 하기 위해 augmentation 사용
- Preprocessing & augmentation을 하면 대부분 성능이 좋아짐
- 원본에 추가되는 개념이니 성능이 떨어지지 않음
- 쉽고 패턴이 정해져 있음
ex) 이미지 반전, 크롭, 밝기 조절
U-Net에서의 Data Augmentation
1) Elastic Deformation
- 적은 수의 이미지를 가지고 효과적으로 학습하기 위해 사용
2) Weighted Cross Entropy + Data Augmentation
- 많은 cell을 segmentation 해야하는 문제

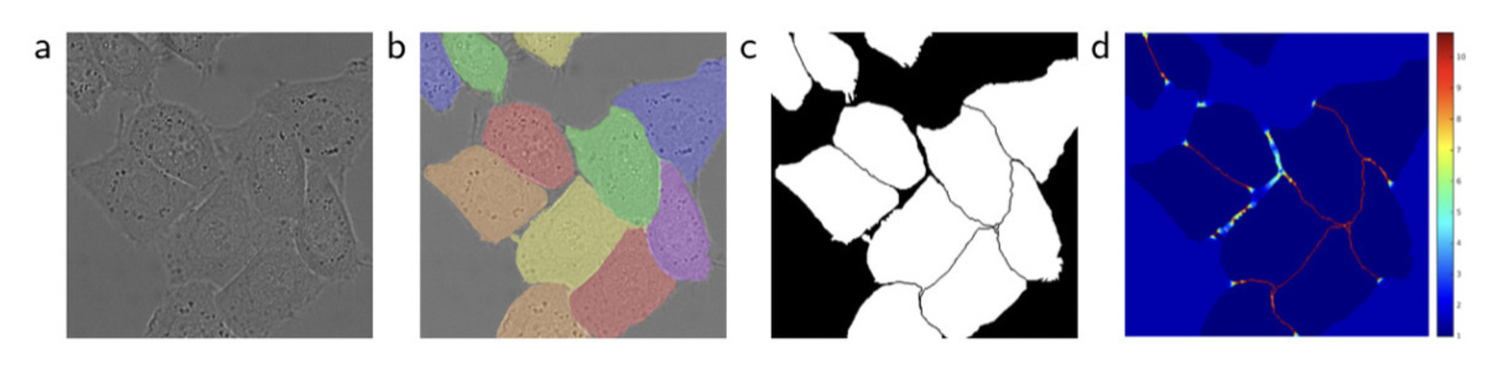
a처럼 cell이 인접해있으면 각 cell과 배경을 구분하는 것은 쉽지만, ****cell 각각을 서로 구분하는 것(논문에서는 instance segmentation이라 표현함)은 어려움. 논문에서는 각 instance의 테두리와 테두리 사이가 반드시 배경이 되도록 처리함. 즉, 2개의 셀이 붙어있는 경우라고 하더라도 그 둘 사이에는 반드시 배경으로 인식되어야 할 틈을 만들겠다 라는 의미 (d에서 확인 가능)
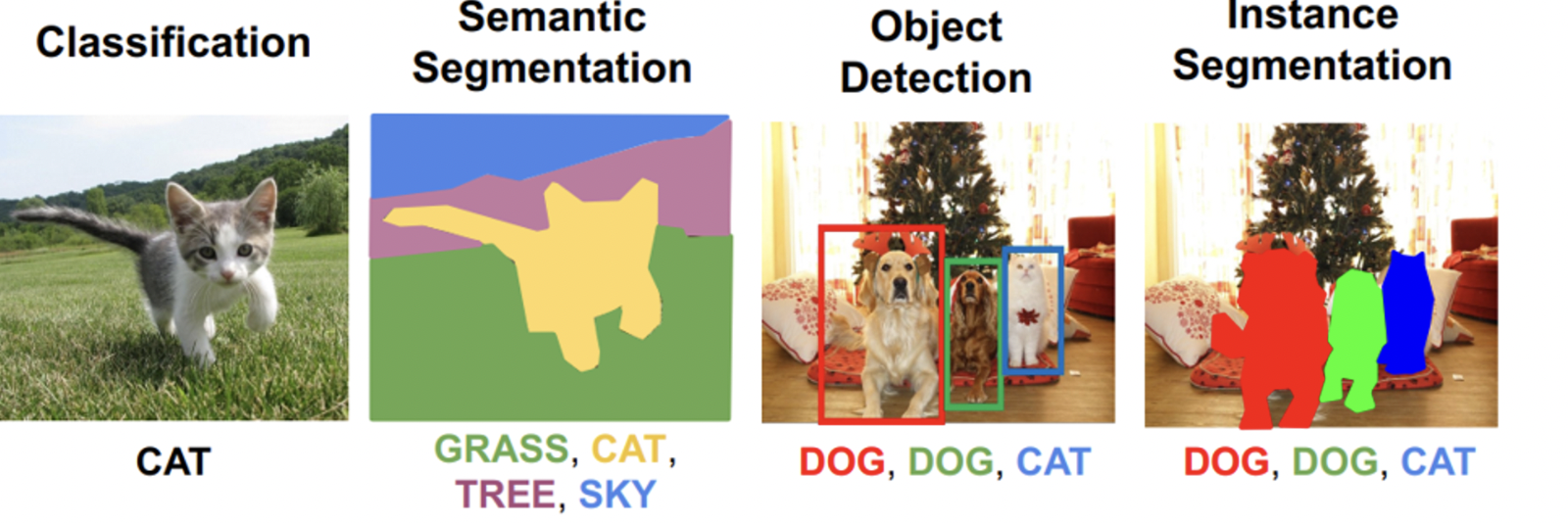
semantic segmentation은 이미지 내에 있는 객체들을 의미 있는 단위로 분할해내는 것이고, instance segmentation 은 같은 카테고리에 속하는 서로 다른 객체까지 더 분할하여 semantic segmentation 범위를 확장한 것
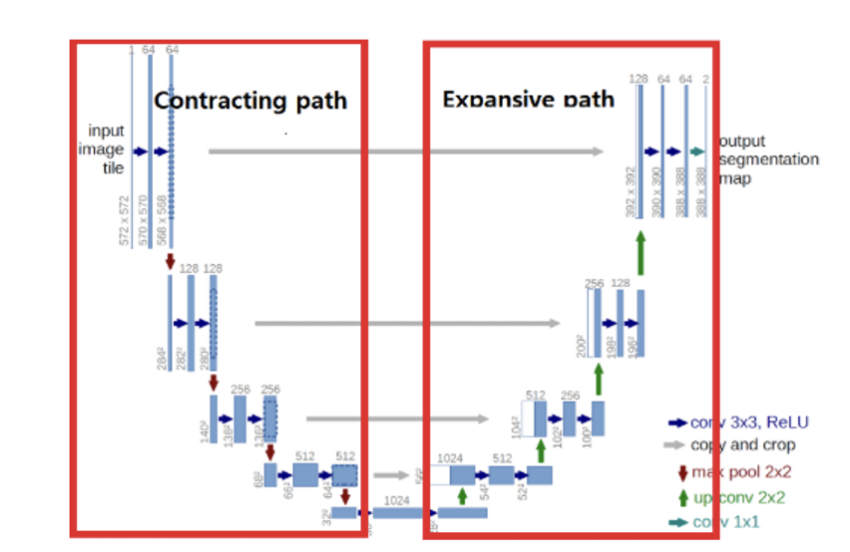
U-Net Architecture
U-Net의 기본 아이디어는 저차원 뿐만 아니라 고차원 정보도 이용하여 이미지의 특징을 추출함과 동시에 정확한 위치 파악도 가능하게 하자는 것이다. 이를 위해서 인코딩 단계의 각 레이어에서 얻은 특징을 디코딩 단계의 각 레이어에 합치는(concatenation) 방법을 사용한다. 인코더 레이어와 디코더 레이어의 직접 연결을 스킵 연결(skip connection)이라고 한다.
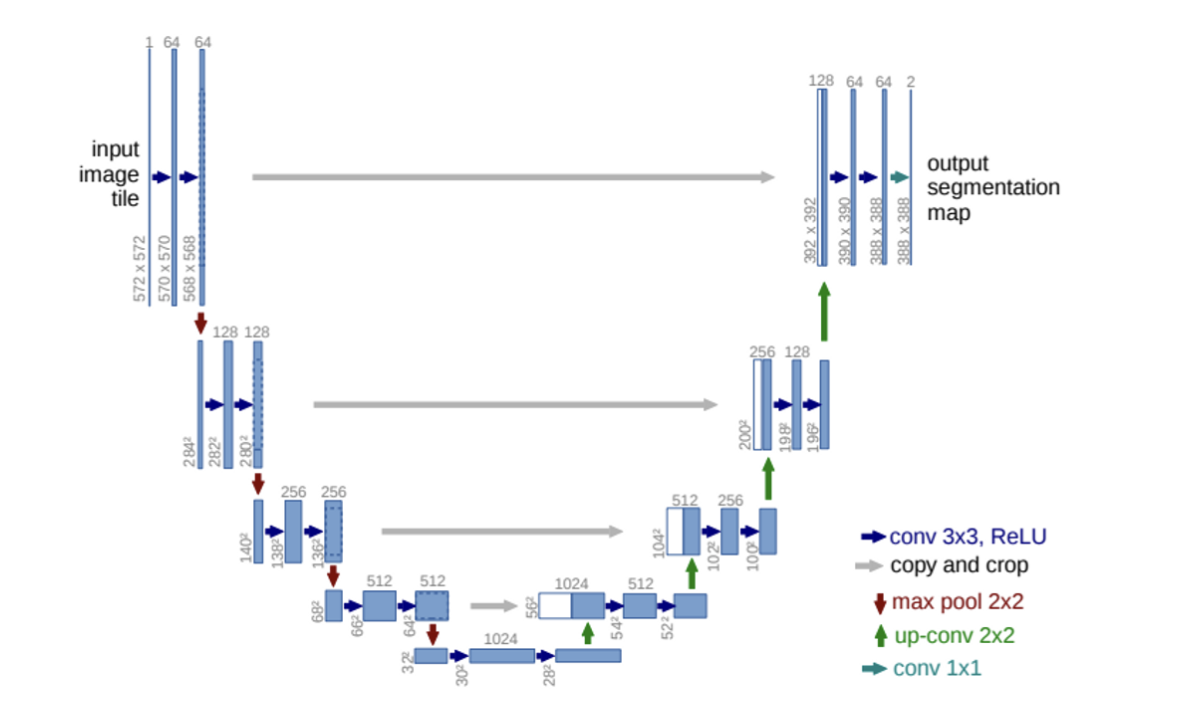
U-Net 은 인코더 또는 축소경로(contracting path)와 디코더 또는 확장경로(expending path)로 구성되며 두 구조는 서로 대칭적이다. 인코더와 디코더를 연결하는 부분을 브릿지(bridge)라고 한다. 인코더와 디코더에서는 모두 3x3 컨볼루션을 사용한다. 인코더의 자세한 구조는 다음 그림과 같다. 맨 아래의 블록은 브릿지이다.
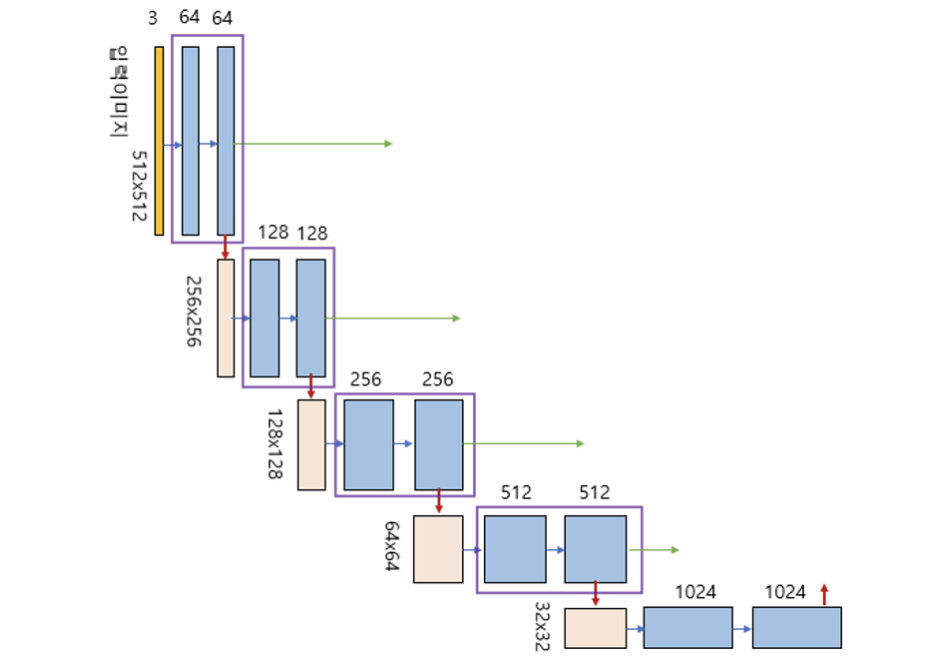
그림에서 세로 방향 숫자는 맵(map)의 차원을 표시하고 가로 방향 숫자는 채널 수를 표시한다. 예를 들면 세로 방향 숫자 256x256 과 가로 방향 숫자 128 은 해당 레이어의 이미지가 256x256x128 임을 의미한다. 입력 이미지는 512x512x3 이므로 RGB 3개 채널을 갖고 크기가 512x512 인 이미지를 나타낸다.
파란색 박스가 인코더의 각 단계마다 계속 반복하여 나타나는 것을 볼 수 있는데, 이 박스는 3x3 컨볼루션, Batch Normalization, ReLU 활성화 함수가 차례로 배치된 것을 나타낸다. 이 박스 두 개를 한데 묶어서 한 개의 레이어 블록으로 구현하여 사용하면 편리하다. 이 블록 이름은 ConvBlock.
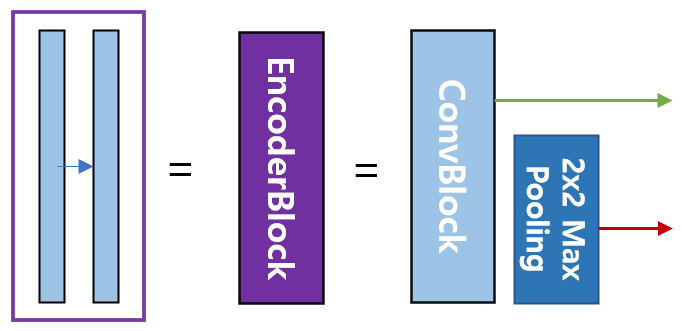
인코더 그림을 보면 보라색 박스안에 한 개의 ConvBlock이 있고 이 박스가 인코더의 각 단계마다 나타나는 것을 볼 수 있다. 이 박스에서 나오는 출력이 2개인데, 한 개의 출력은 U-Net의 디코더로 복사하기 위한 연결선이며, 또 한 개의 출력은 2x2 max pooling 으로 다운 샘플링(down sampling)하여 인코더의 다음 단계로 내보내는 빨간색 화살선이다. 이 박스도 한 개의 레이어 블록으로 구현하여 사용하면 편리하다. 이 블록 이름은 EncoderBlock.
- Contracting Path (모델의 좌측)
Contracting Path는 일반적인 CNN을 따르며,downsampling을 위한 Stride2, 2x2 max pooling 연산과 ReLU를 포함한 두 번의 반복된 3x3 unpadded convolutions 연산을 거친다.
즉, 3x3conv → ReLU → 2x2 max pooling → 3x3conv → ReLU → 2x2 max pooling 이다.
그리고 downsampling 과정에서 feature map channel의 수는 2배로 증가시킨다.
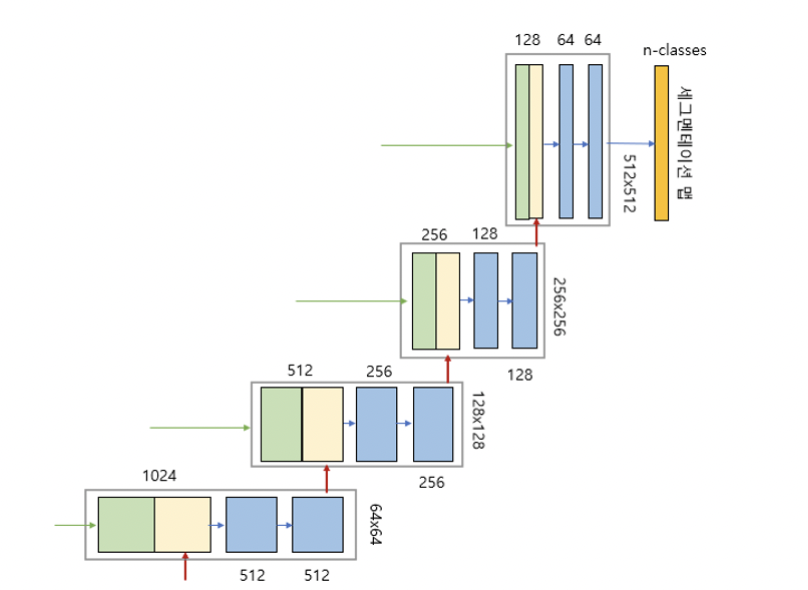
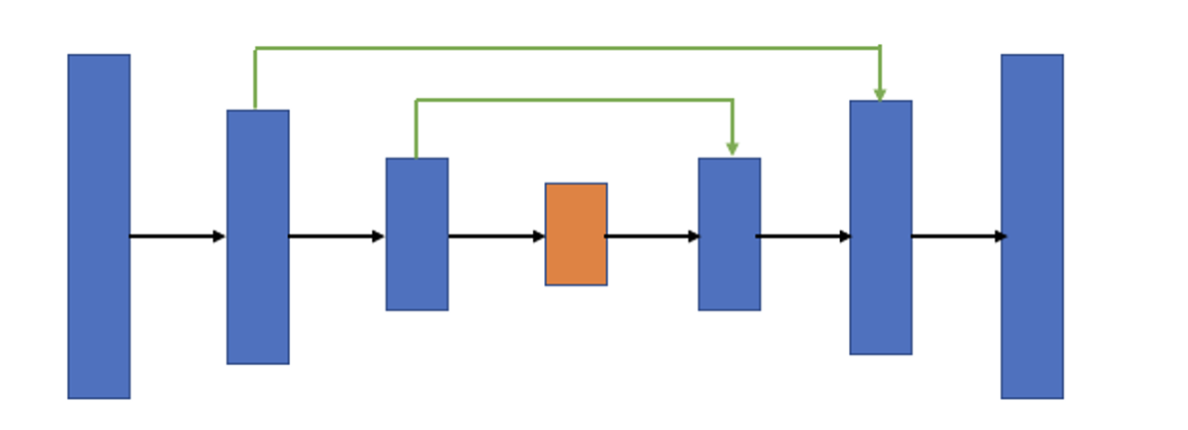
그림에서 파란색 박스 2개는 인코더에 있는 ConvBlock와 동일하다. 녹색 박스는 스킵 연결을 통해서 인코더에 있는 맵을 복사한 것이다. 노란색 박스는 디코더의 하위 단계에서 전치 컨볼루션(transposed convolution)을 통해서 맵의 차원을 두배로 늘리면서 채널 수를 반으로 줄인 것이다. 두 개의 맵을 서로 합쳐서(concatenation) 저차원 이미지 정보뿐만 아니라 고차원 정보도 이용할 수 있는 것이다. 디코더의 그림에서도 회색 박스가 반복적으로 나타나므로 한 개의 레이어 블록으로 구현하여 사용하면 편리하다. 이 블록 이름을 DecoderBlock 이라고 하자.
디코더 그림의 맨 상단의 오른쪽 부분은 U-Net의 출력으로서 1x1 컨볼루션으로 특징 맵을 처리하여 입력 이미지의 각 픽셀을 분류하는 세그멘테이션 맵을 생성하는 부분이다. 컨볼루션 필터의 개수는 분류할 카테고리 개수이며 활성 함수로는 카테고리 수가 1개라면 sigmoid 함수를, 여러 개라면 softmax 함수를 사용한다.
- Expansive Path(모델의 우측)
Expansive Path는 2x2 convolutions를 통해 upsampled된 feature map과 1)의 cropped feature map과의 concatenation 후에 ReLU 연산을 포함한 두 번의 3x3 convolutions 연산을 거친다.
이 때, 1)의 Crop된 featrue map을 보내는 이유는 Convolution을 하면서 border pixel에 대한 정보가 날아가는 것에 대한 양쪽의 보정을 위함이다.
마지막 layer는 1x1 convolution 연산을 하는데 이는 64개의 component feature vector를 desired number of classes에 mapping 하기 위함이다.
