
Image Classification
Image classification이란 입력 이미지가 어떤 카테고리인지 맞추는 task이다. 카테고리는 개, 고양이, 트럭.. 등과 같이 레이블로 주어진다.
semantic gap

semantic gap은 image classification이 해결해야 할 문제의 원인이다. semantic gap이란 인간이 보는 이미지와 컴퓨터 보는 이미지 간의 차이를 말한다. 인간은 고양이 사진을 보면 고양이라고 한 눈에 알아볼 수 있지만 컴퓨터는 이미지를 볼 때 숫자 집합으로 보게 된다. 컴퓨터가 이미지를 보는 방식 때문에 image classification에서 여러 문제가 발생하게 된다.
challenges
픽셀은 여러 변화에 따라 값이 변화하게 된다. 여기서 말하는 여러 변화의 예시는 viewpoint variation, illumination, deformation, occlusion, background clutter, intraclass variation 등이 있다. Image Classification을 수행할 알고리즘은 이런 문제에도 강인하게 동작해야 한다.
previous classification
그렇다면 어떻게 image classifier를 구현할 수 있을까? 정렬과 같은 알고리즘은 구체적인 규칙을 통해서 구현을 할 수 있다. 하지만 고양이와 다른 물체를 인식하는 알고리즘은 이와 같이 구현을 하기엔 어려워 보인다.
Attempts have been made
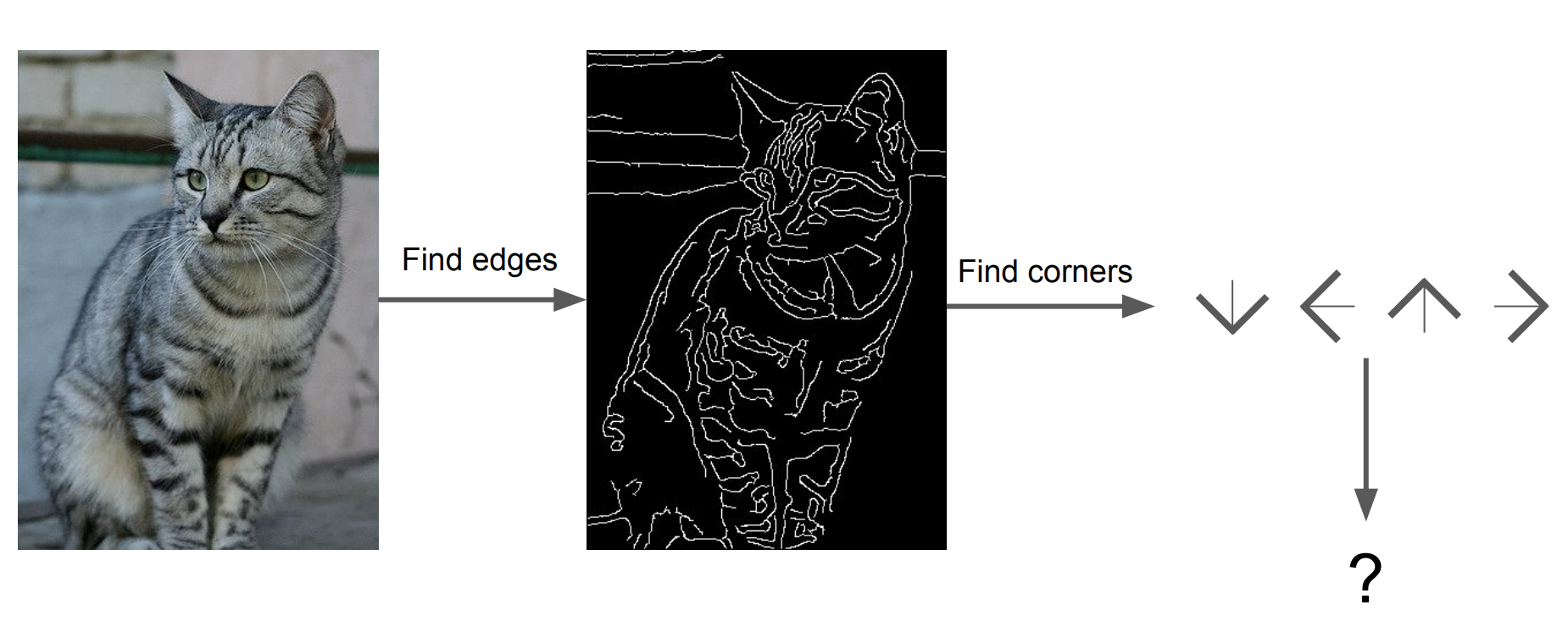
이전 시간에 설명했듯이 Davis Marr 교수님은 인간이 이미지를 edges와 corners 같은 특징(features)으로 인식한다고 했다. 이 연구를 기반으로 만들어진 알고리즘들은 features를 이용해서 이미지를 인식하는 "규칙"을 만들려고 시도했다.
하지만 이런 알고리즘은 여러 단점이 있어 지금은 거의 사용하지 않는다. 첫 째로 위에서 말한 여러 변화에 강인하지 않다. 둘 째로 새로운 클래스마다 새로 feature를 구하고 알고리즘을 구현해야하므로 확장성이 없는 알고리즘이다.
Data Driven Approach
그래서 여러 클래스들에 모두 적용할 수 있는 data driven approach가 등장했다. 이 방식은 객체마다 규칙을 만드는 것이 아닌 단순히 데이터들을 모아 train 함수와 test 함수를 거쳐 진행된다. train 함수는 입력이 이미지와 레이블이고 출력은 모델이다. test 함수는 입력이 모델이고 출력이 이미지의 예측값이다. 이 2개의 함수를 사용하면 모델은 입력 이미지를 고양이로 인식하게 된다.
Nearest Neighbor
Data Driven Approach를 적용한 classifier 중 하나인 Nearest Neighbor의 동작 방식은 다음과 같다. train 시에는 데이터와 레이블을 기억한다. test 시에는 test image와 유사한 train image를 찾아 레이블을 예측한다.
distance metric
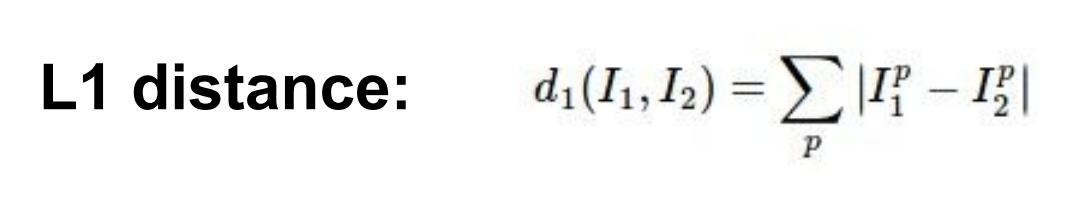
그렇다면 두 이미지 간의 유사도를 어떻게 측정할 수 있을까? L1 distance는 그 방법 중 하나로 수식은 위와 같다.
Nearest Neighbor implemented in numpy
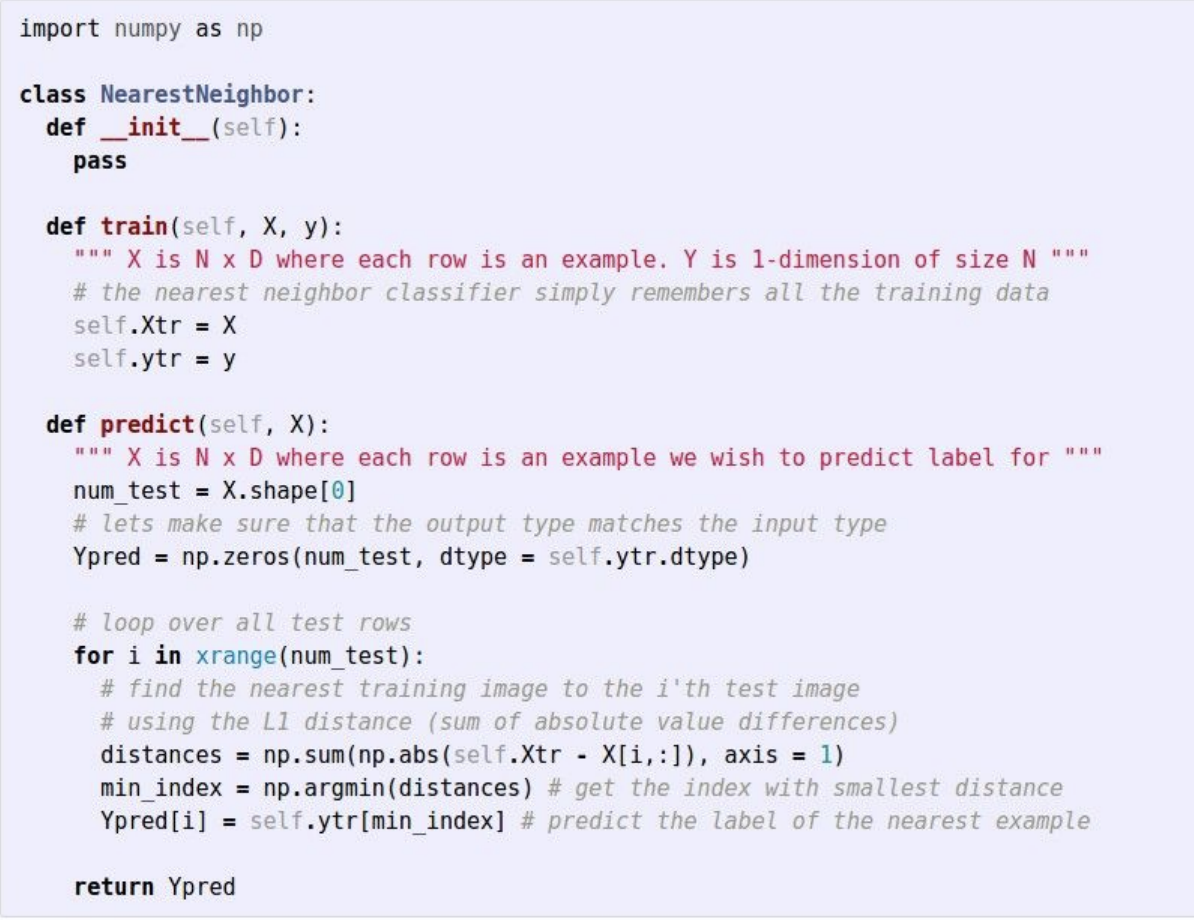
train 함수는 단순히 입력된 학습 이미지 X와 레이블 y를 기억하도록 구현되어있다. 이 함수는 단순히 포인터를 사용해 복사하면 되므로 O(1)의 시간 복잡도를 갖는다.
predict 함수는 test 이미지를 모든 train 이미지와 비교해 거리가 가장 가까운 이미지의 레이블을 예측한다. 이 함수는 테스트 이미지와 N개의 train 데이터 전부를 비교해야하므로 O(N)의 시간 복잡도를 갖는다.
Problem
train은 빠르고 prediction은 느린 이 방식은 우리가 원하는 classifier는 아니다. 우리는 train을 오래하더라도 prediction 시에 빠르게 동작하는 모델을 원한다. 또한 NN은 noise와 이상치에 민감하게 반응하는 단점도 있다.
K-NN
NN의 단점들을 해결하기 위해 NN에서 약간의 변화를 준 K-NN 모델이 만들어졌다. K-NN은 테스트 이미지와 모든 train 데이터를 비교하는 것이 아닌 가까운 이웃을 k개만 찾고 이웃끼리 투표하는 방식으로 레이블을 결정한다.
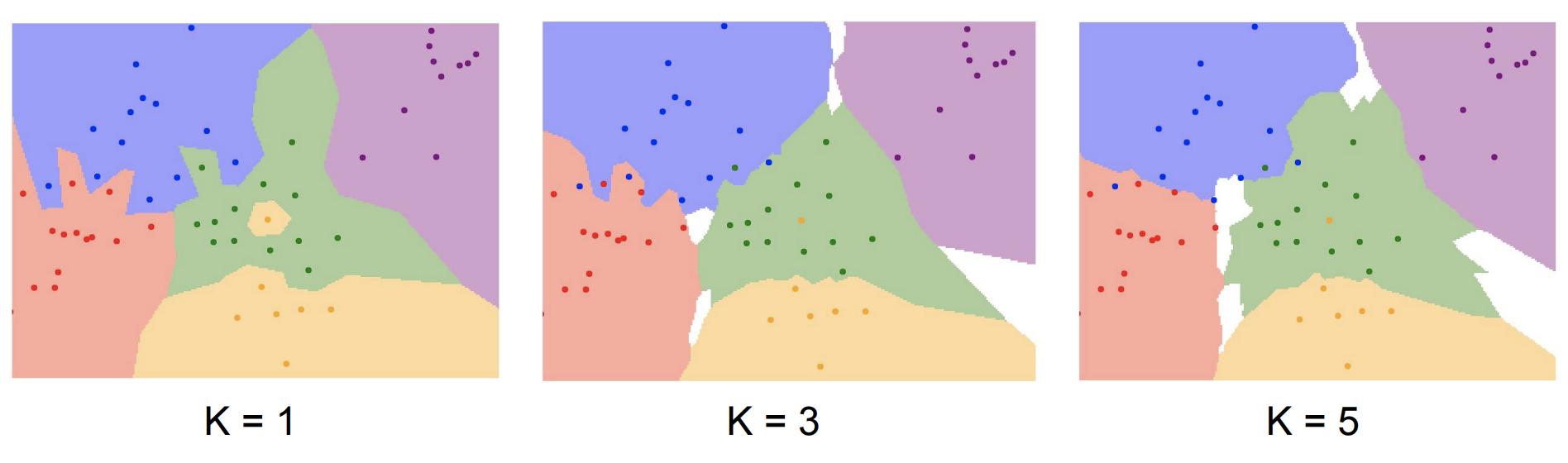
위의 그림을 보면 k=1인 NN의 경우보다 K-NN의 경우가 noise와 이상치에 더 강인하다.
distance metric
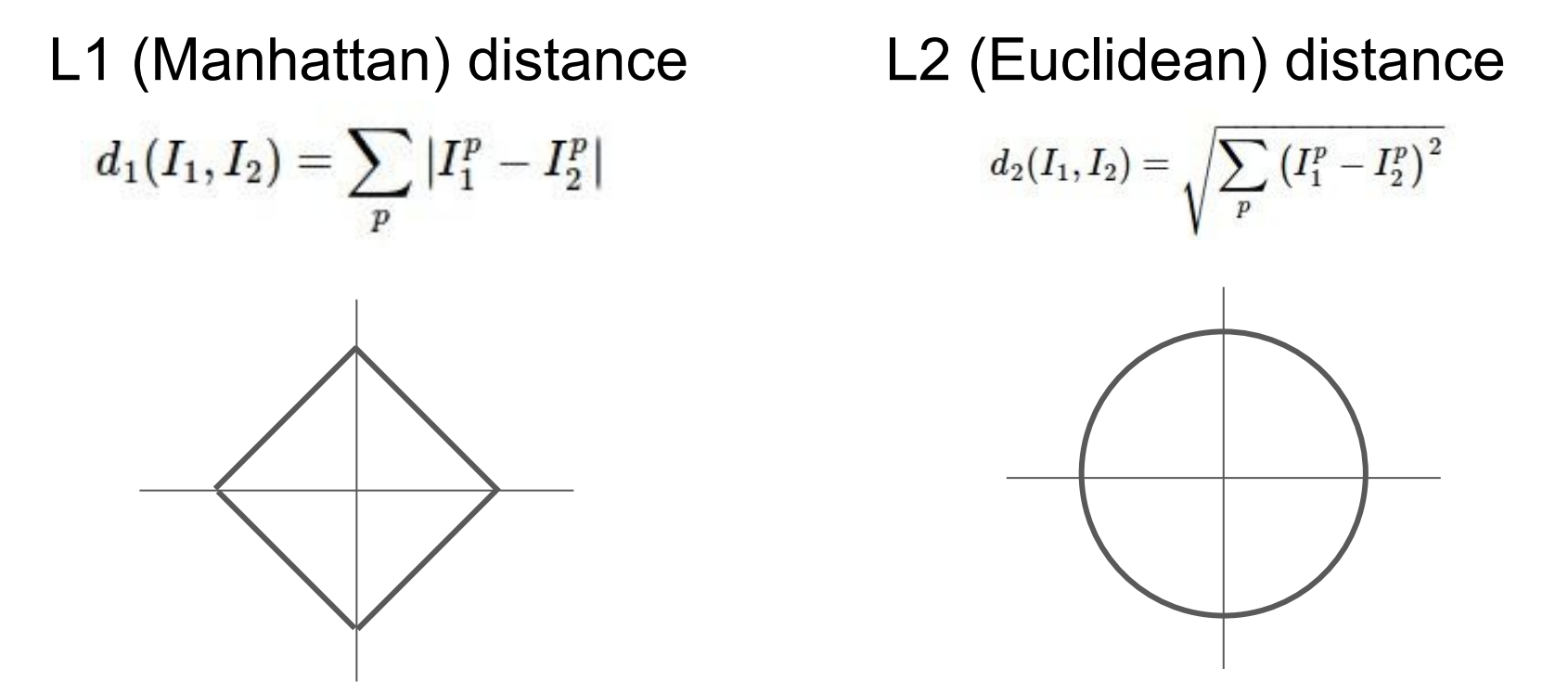
K-NN에서는 distance metric을 기존 NN에서 사용한 L1 distance 이외에도 L2 distance를 사용하고 있다. L2 distance의 수식은 위와 같다.
L1 distance 관점에서 봤을 때 원점과 사각형의 변 사이의 거리는 모두 1로 동일하다. 예를 들어 1사분면의 (0.5, 0.5)와 원점 (0,0)의 거리는 |0.5-0| + |0.5-0| = 1 이다. 마찬가지로 (1,0)과 (0,0)의 거리 역시 1이다. 하지만 L1 distance는 어떤 좌표 시스템이냐에 따라 그 값이 영향을 받는다. 예를 들어 좌표계가 회전하게 된다면 L1 distance는 변하게 된다.
하지만 L2 distance는 이와 다르게 다른 좌표 시스템에서도 변하지 않는 특징을 갖고 있다.
이런 서로 다른 특징들 때문에 distance metric은 어떤 것을 선택하냐에 따라 해당 공간의 근본적인 기하학적 구조 자체가 다르다. feature vectors의 요소들이 개별적 의미를 갖는다면 (ex. 키, 몸무게) L1 distance를 사용하는 것이 좋고 의미를 모르거나 일반적인 의미를 갖는다면 L2 distance를 사용하는 것이 좋다.
즉, K-NN은 모델이 간단하고 distance metric과 k만 정해주면 어떤 종류의 데이터도 다룰 수 있는 좋은 알고리즘이다.
hyperparameters
k와 distance metric 같이 사용자가 학습 중 세팅할 수 있는 값을 hyperparameter라고 한다.
hyperparameters를 잘 설정하기 위해서는 모든 경우의 수를 시도해보고 가장 좋은 성능을 내는 hyperparameters를 선택해야 한다. 여기서 말하는 좋은 성능이란 학습 데이터에서의 정확도가 아닌 새로운 데이터에서의 정확도를 말한다.
그런 의미에서 내 데이터 셋 전부에 잘 맞는 hyperparameters를 선택하는 것은 옳지 않다. 또한 내 데이터 셋을 단순히 train set과 test set으로 나누는 것도 옳지 않다. 왜냐하면 이처럼 hyperparameters를 설정했을 경우, 이것도 test set에게만 잘 맞는 경우일 수도 있기 때문이다.
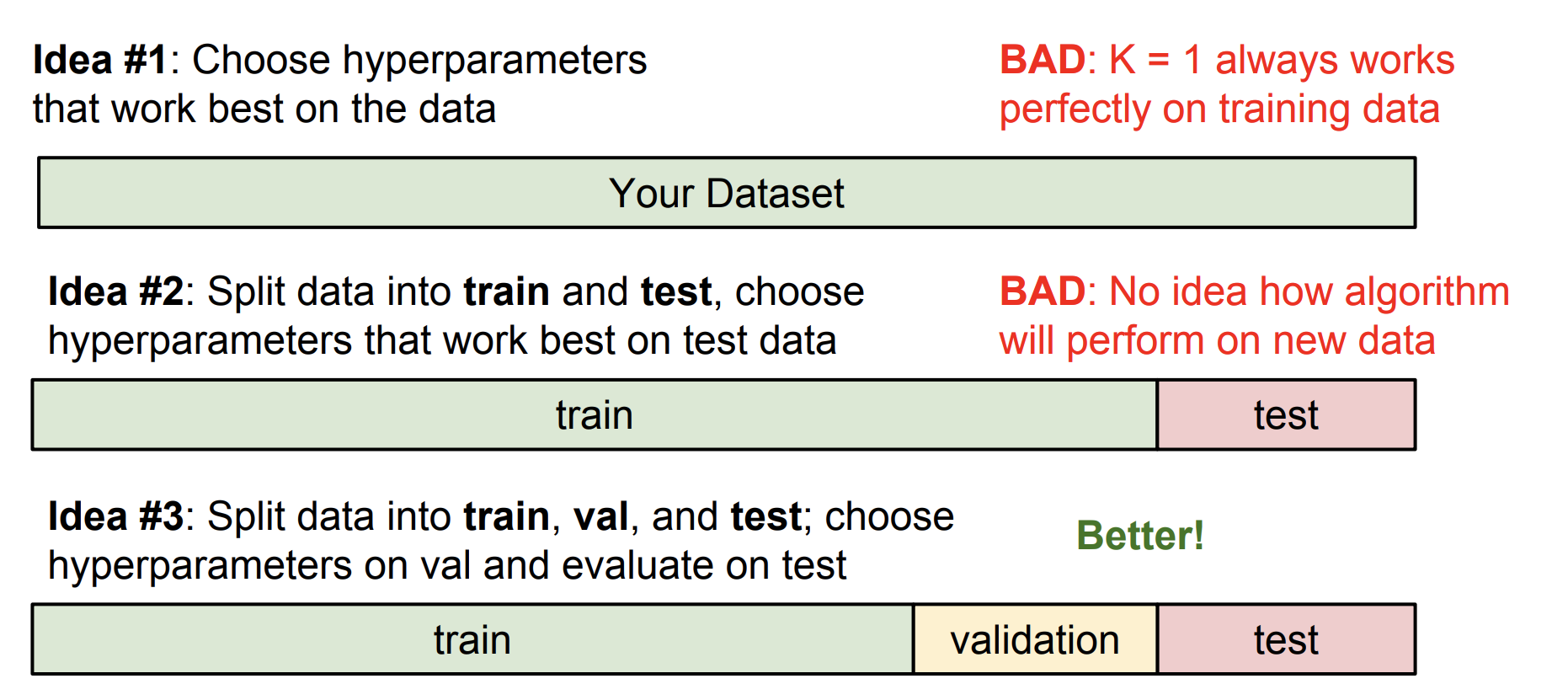
그러므로 데이터 셋을 train/validation/test로 나누는 것이 일반적이다. 이 방식은 먼저 다양한 hyperparameters로 train set을 학습한다. 이후 validation set으로 이를 검증하고 그 중 최고의 hyperparameters를 고른다. 가장 좋았던 hyperparameters로 test set에서 "한 번만" 수행해 정확도를 출력한다. 이와 같이 데이터 셋을 나눠야 선택한 hyperparameters가 "새로운" 데이터에 잘 동작하는지 알 수 있다.
Problem
하지만 K-NN 역시 image classification을 수행하기 위한 적절한 모델은 아니다. test 시에 너무 느리고 distance metric이 두 이미지 간의 유사도를 대변하기에는 부족하기 때문이다.
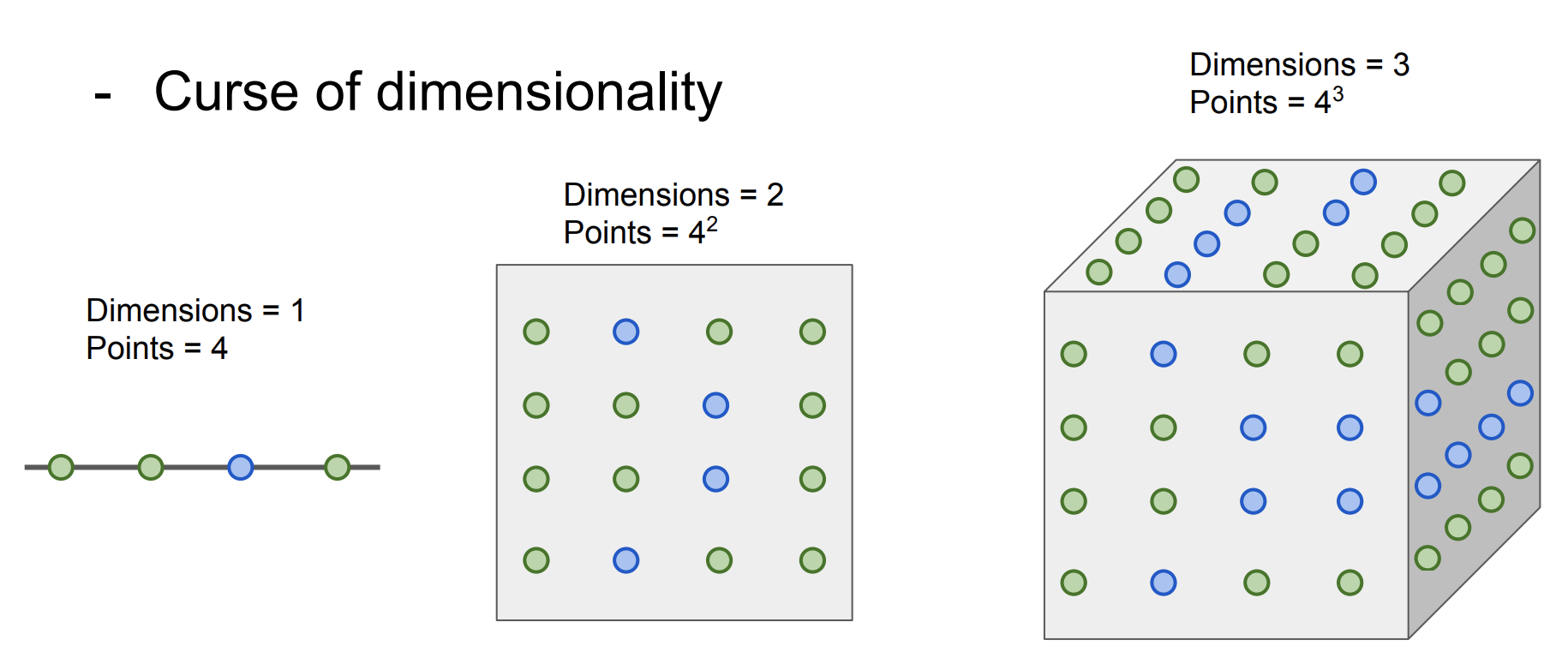
또한 K-NN이 잘 동작하기 위해서는 전체 공간을 조밀하게 덮을 수 있는 충분한 학습 데이터가 필요하다. 충분한 데이터가 없다면 이웃끼리 먼 경우가 발생하거나 분류를 제대로 하지 못하는 문제가 발생한다. 차원이 증가한다면 필요한 데이터 수가 기하급수적으로 증가한다는 문제점도 있다.
Linear Classification
Neural Network는 종종 레고에 비유되기도 한다. Linear Classifiers는 Neural Network라는 구조물을 쌓는 레고 조각으로 중요한 역할을 하는 기본 요소이다.
Parametric Approach
parametric approach에서는 학습 데이터의 정보를 요약하는 방식을 사용해 test time에서 빠르게 동작한다. K-NN(data driven approach)은 parameter가 없어서 전체 학습 데이터를 test time에서 사용했고 이 때문에 모델의 prediction 속도가 느렸다. 하지만 parametric approach에서는 학습 데이터를 W라는 parameter에 요약해 test time에서 더 이상 학습 데이터가 필요없게 한다.
Linear Classifier
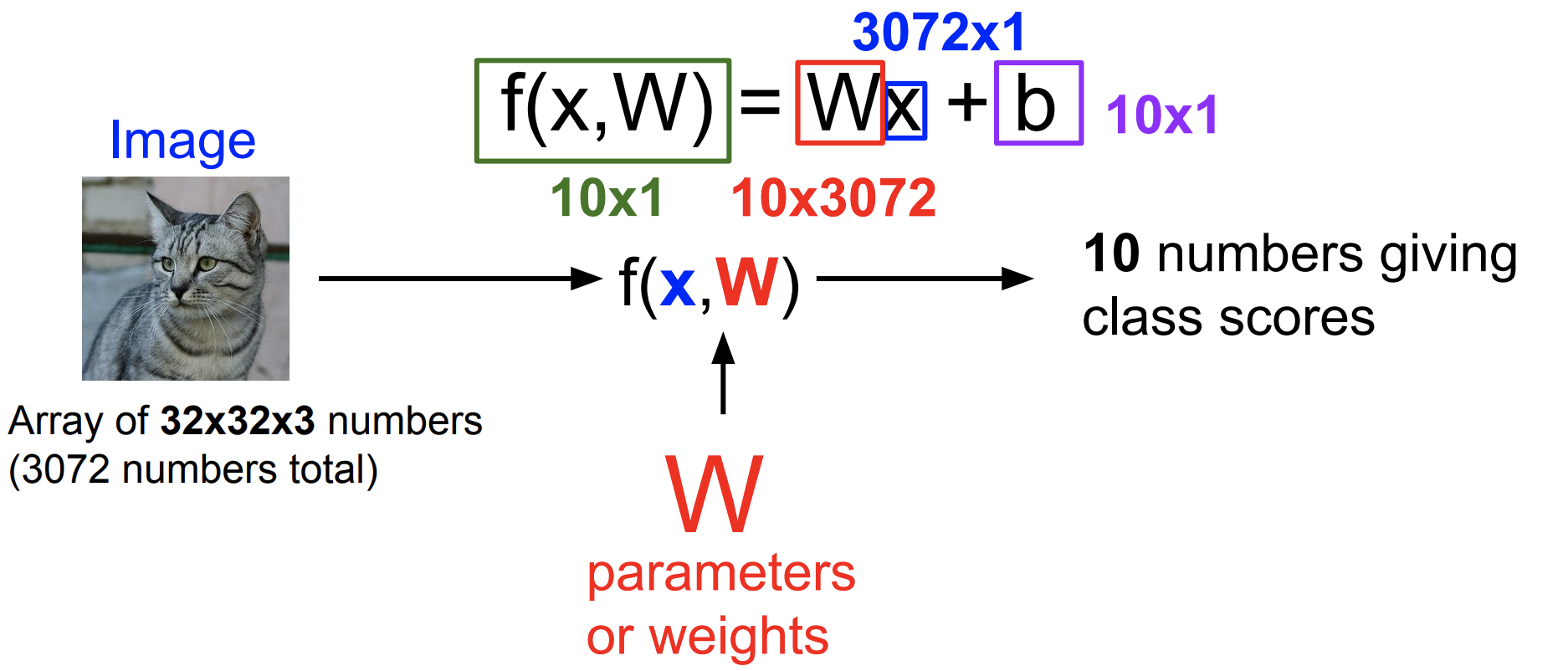
Linear classifier는 입력 데이터 x와 parameter W를 단순히 곱해서 입력 데이터를 요약한다.
입력 이미지가 32x32x3(가로,세로 32와 RGB 3 채널)의 크기로 주어졌을 때 10개의 클래스 중 하나를 맞추는 문제를 예로 들어보자. 먼저 이미지를 1차원의 벡터로 쭉 펼쳐 3072x1의 크기로 나타낸다. 클래스는 10개이므로 W와 x를 곱했을 때 크기는 10x1이어야 한다. 그러므로 W는 10x3072의 크기를 가지는 행렬이 된다.
뒤에 b가 더해지는 경우도 있는데 이는 bias를 의미한다. bias는 데이터와 무관하게 특정 클래스에 우선권을 부여한다. 예를 들어 데이터 셋에 고양이 데이터가 많다면 고양이에 해당하는 bias가 큰 값을 갖게 된다. bias는 10x1의 크기를 갖는다.
interpreting a Linear Classifier

W는 해당하는 이미지의 대략적인 그림을 나타낸다. 학습 과정에서 W를 시각화해서 나타내면 위와 같은 그림이 출력된다. 그림을 보면 레이블의 특징이 미세하게 보이는데 이는 여러 입력 데이터를 평균화해서 나타낸 결과이기 때문이다.
하지만 이런 특징때문에 각 클래스에 대해 단 하나의 템플릿만을 학습한다는 단점이 있다. 위의 그림에서 말의 예시를 보면 머리가 양쪽에 있는 것을 볼 수 있는데 이런 점이 Linear Classifier의 문제점이다.
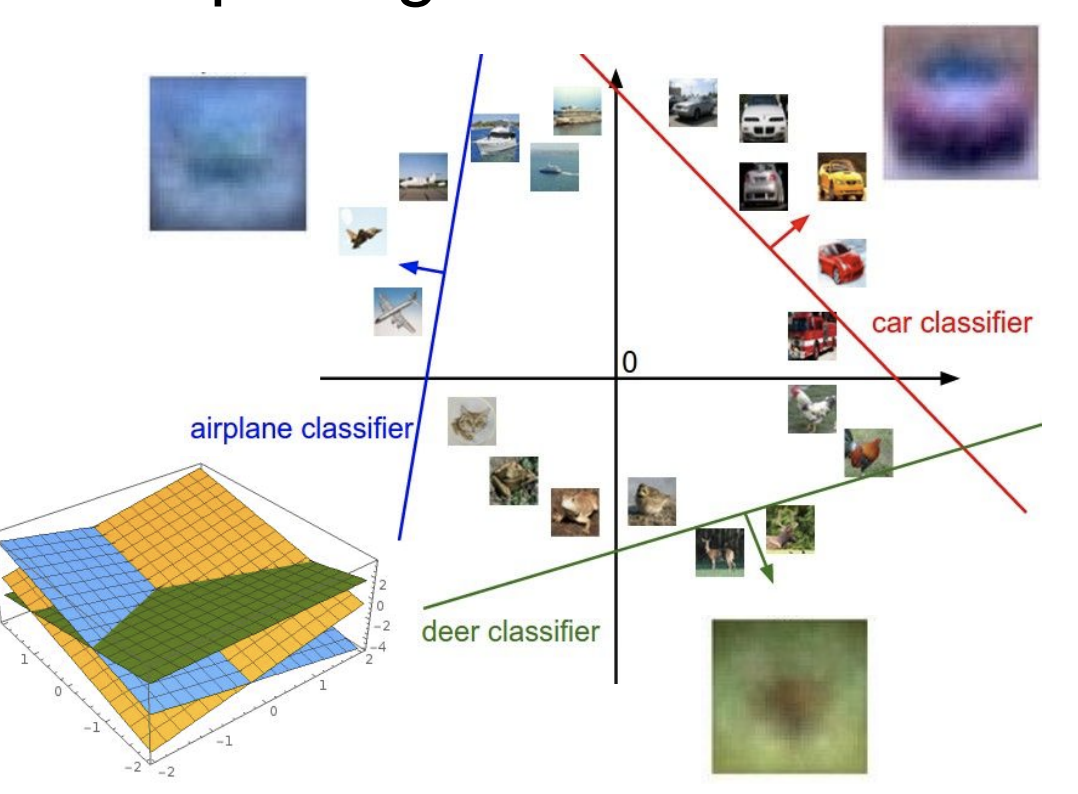
다른 관점에서 Linear Classifier는 이미지들을 구분하는 선으로 볼 수 있다. 이미지들을 고차원 공간의 한 점으로 생각한다면 Linear Classifier는 이들을 분류해주는 평면 혹은 직선이 된다.
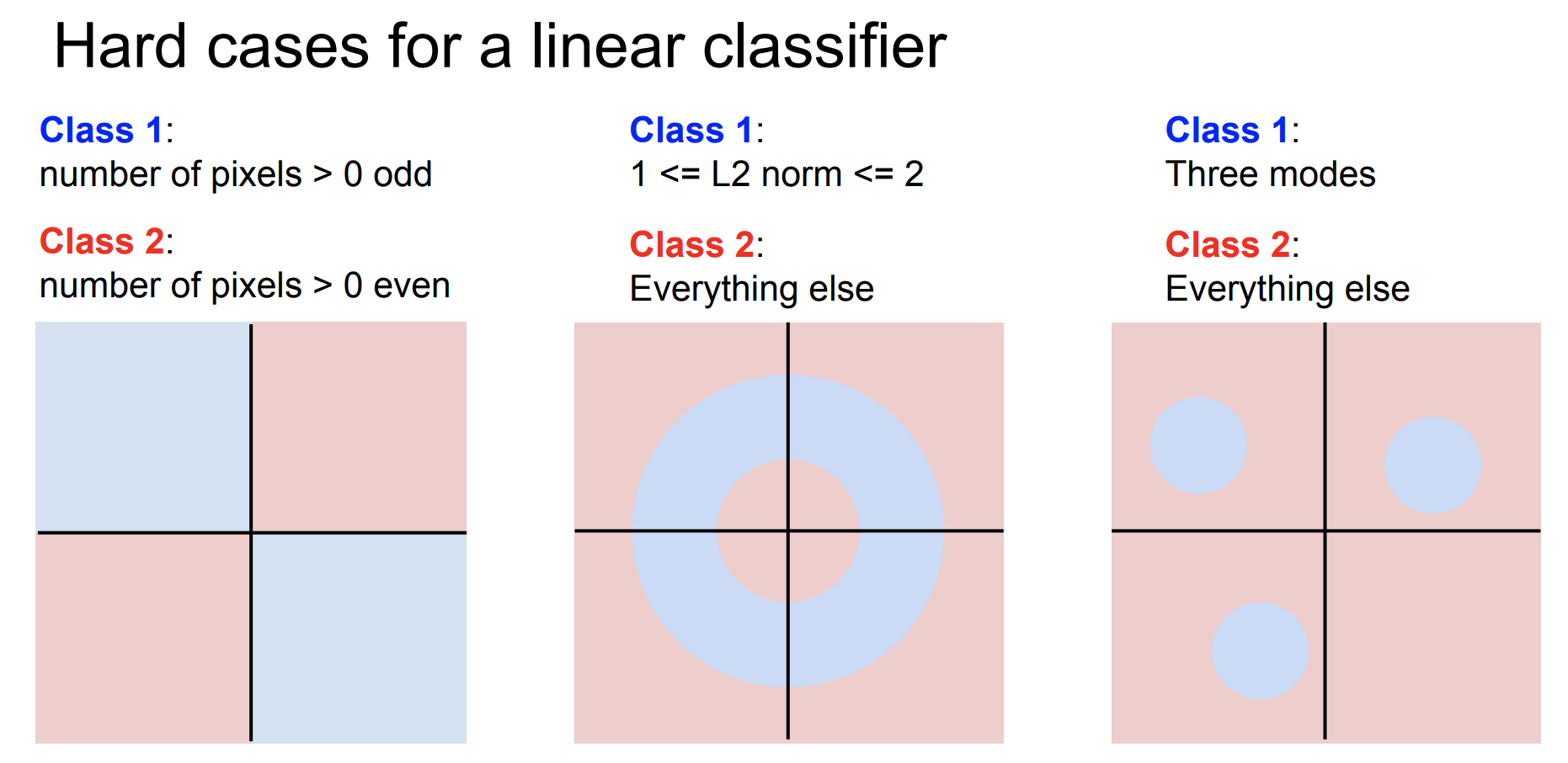
하지만 여전히 linear classifier 하나만으로는 해결하지 못하는 문제들도 있다. 위와 같이 XOR, nonlinear, multimodal data 등은 하나의 linear classifier로 해결하지 못한다.
다음시간에는 좋은 W를 찾기 위한 loss function과 optimization, ConvNets에 대해 알아보도록 하자.
