CS231n 2020년도 과제를 수행하고 정리한 포스트다. 과제 내용은 CS231n github에서 확인할 수 있다.
code implement 1
k-NN의 test 과정에서 test 이미지와 train 이미지의 거리를 구하는 과정이다. 거리는 L2 distance metric을 사용했고 이중 for문을 사용해 구현했다.
def compute_distances_two_loops(self, X):
num_test = X.shape[0]
# test 이미지 개수는 500개
num_train = self.X_train.shape[0]
# train 이미지 개수는 5000개
dists = np.zeros((num_test, num_train))
# 500*5000 크기의 0으로 채워진 행렬을 만든다.
for i in range(num_test):
for j in range(num_train):
dists[i][j] = np.sqrt(np.sum(np.square(X[i] - self.X_train[j])))
return distsdists 행렬은 500 * 5000 크기의 행렬인데 행렬의 각 요소는 test 이미지와 train 이미지의 거리를 의미한다. i번 째 test 이미지와 j번 째 train 이미지의 거리를 L2 distance metric 공식대로 작성했다.
- np.square() : 행렬의 요소 단위로 제곱을 반환한다.
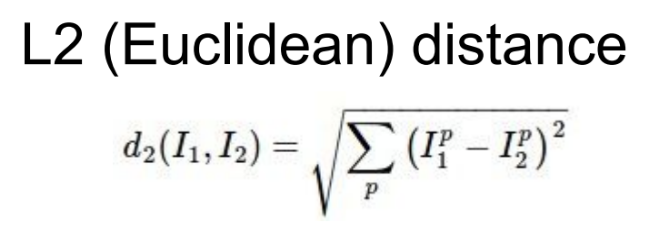
Inline Question 1
Notice the structured patterns in the distance matrix, where some rows or columns are visibly brighter.
(Note that with the default color scheme black indicates low distances while white indicates high distances.)
What in the data is the cause behind the distinctly bright rows?
What causes the columns?
Y𝑜𝑢𝑟𝐴𝑛𝑠𝑤𝑒𝑟: fill this in.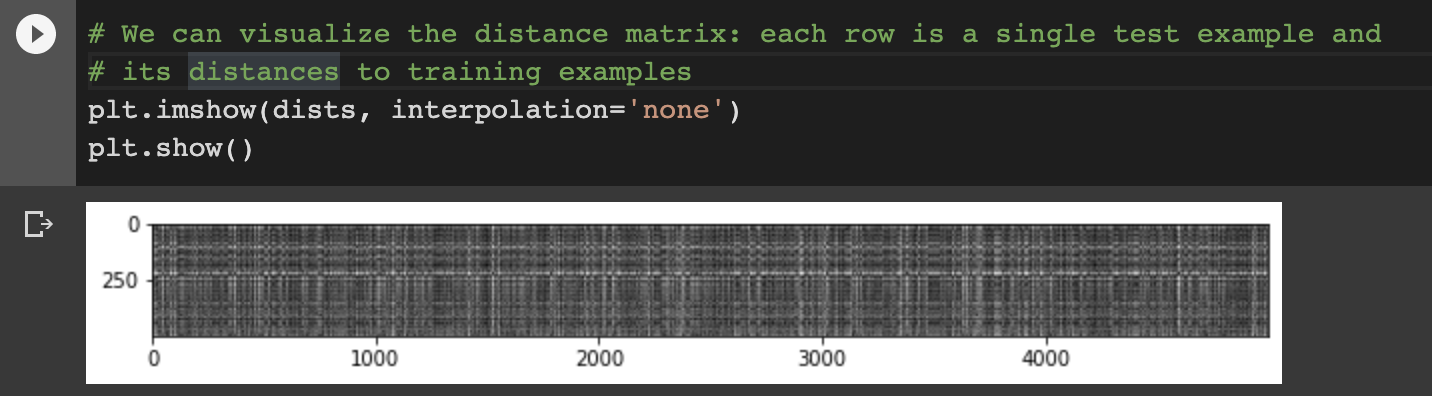
dists 행렬의 요소는 두 이미지 간의 거리이다. 문제에 나와있듯이 검은색은 낮은 거리를, 흰색은 높은 거리를 의미한다. 그러므로 행과 열에서 나타나는 밝은 값들은 test 이미지와 train 이미지의 유사도가 작다는 것을 의미한다.
행에서 한 줄로 나타난 밝은 선의 경우, 그 test 이미지는 모든 train 이미지와 거리가 멀다. 반대로 열의 한 줄로 나타난 밝은 선은 train 이미지가 모든 test 이미지와 거리가 멀다. 즉, 한 줄에 해당하는 이미지는 outlier라고 해석할 수 있다고 생각한다.
code implement 2
test 이미지의 label을 예측하는 predict_labels 함수를 구현했다.
def predict_labels(self, dists, k=1) :
num_test = dists.shape[0]
# shape[0]으로 dists 행렬의 행 개수 뽑기 -> 500개
y_pred = np.zeros(num_test)
for i in range(num_test) :
closest_y = []
# 가장 가까운 label
###################################################
closest_y = self.y_train[np.argsort(dists[i])][:k]
y_pred[i] = np.argmax(np.bincount(closest_y))
###################################################
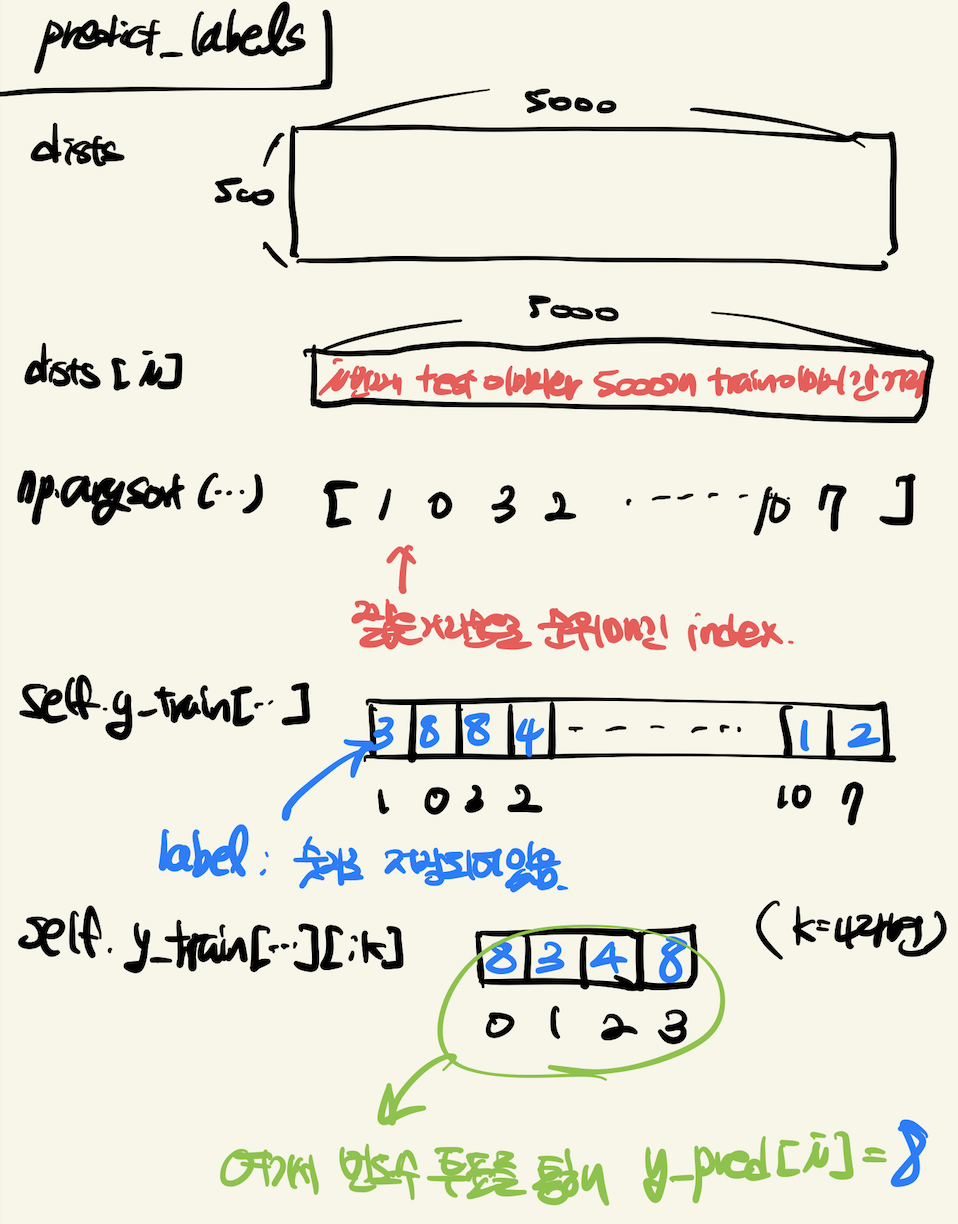
return y_pred먼저 dists 행렬의 행 개수를 num_test(test 이미지 개수)에 저장한다. 이후 test 이미지 개수만큼의 0으로 채워진 행렬 y_pred를 만든다. for문을 test 이미지 개수만큼 돌면서 해당 test 이미지의 예측 label을 y_pred 행렬에 넣는다.
closest_y = self.y_train[np.argsort(dists[i])][:k]코드를 자세히 보면 dists[i]는 i 번째 test 이미지 하나와 모든 train 이미지의 거리가 담겨있는 행렬이다. 이 행렬의 요소들을 argsort() 함수로 짧은 거리 순으로 정렬해 인덱스 리스트를 반환한다. y_train은 label이 숫자로 담긴 배열이다. argsort() 함수로 얻은 인덱스를 y_train 배열에 매핑하고 0~k-1 인덱스에 해당하는 label을 closest_y에 넣어준다. 즉, dists[i]에서 거리가 가까운 label k개가 closest_y이다.
y_pred[i] = np.argmax(np.bincount(closest_y))이 부분은 k가 1이 아닐 경우를 위한 부분이다. bincount 함수는 0부터 closest_y까지 빈도수를 리스트로 반환한다. 예를 들어 설명하면 아래와 같다.
given_array = [3,2,2,6,7,4,8,9,9,9]
answer = np.bincount(given_array)
print(answer)
# the printed result is : [0 0 2 1 1 0 1 1 1 3]이후 argmax 함수로 그 중 가장 빈도수가 높은 label을 y_pred에 저장한다. 거리가 가까운 k개의 label에서 투표를 해 가장 높은 득표를 한 label이 예측치가 된다.
복잡한 이 과정을 그림으로 나타내면 아래와 같다.
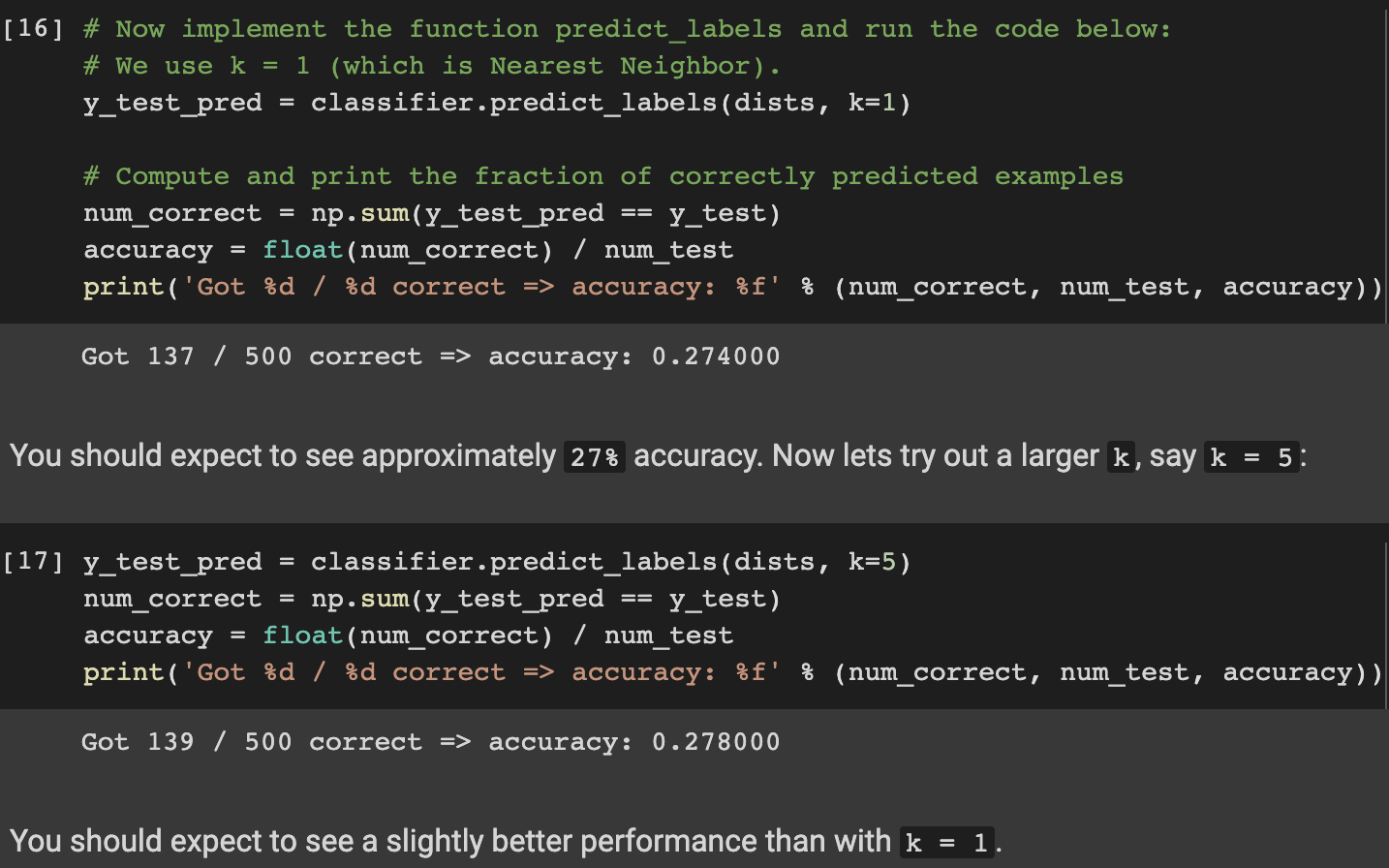
구현한 함수를 사용해서 정확도를 출력해보았다. k=1인 경우 27.4%의 정확도가 나왔고 k=5인 경우 약간의 성능이 향상되어 27.8%의 정확도가 나왔다.
inline Question 2

Answer : 1,3
Explanation :
1) 이미지 전체 평균을 각 이미지의 픽셀에서 빼는 경우이다. 이 경우 같은 방향으로 같은 양만큼 움직이기 때문에 L1 distance는 변하지 않는다.
2) 각 픽셀의 평균을 각 이미지의 픽셀에서 빼는 경우이다. 픽셀의 평균은 각각 다를 것이므로 L1 distance는 변한다.
3, 4는 1, 2번과 같은 이유로 3은 변하고 4는 변하지 않는다.
5) lect2 강의시간에 L1 distance는 어떤 좌표 시스템이냐에 따라 값이 달라진다고 했다. 데이터의 축이 90도의 배수만큼 회전할 때는 L1 distance가 변하지 않지만, 그 외의 값만큼 회전할 경우에는 거리의 변화가 있다고 한다. (아직 이 개념을 정확하게 이해하지 못했다.)
code implement 3
이전에 구현했던 L2 distance를 one loop와 no loop로 구현해보았다.
one loop은 numpy의 broadcasting를 사용해서 구현했다.
# compute_distances_one_loop
for i in range(num_test):
dists[i] = np.sqrt(np.sum(np.square(X[i] - self.X_train), axis = 1))
'''
X[i].shape : 1*3072
X_train.shape : 5000*3072
broadcasting에 의해서 5000*3072 - 5000*3072의 square 연산이 수행된다.
이전 two loop의 경우 square 연산 이후 1*3072 크기의 array가 나왔지만
broadcasting을 사용한 one loop의 경우 5000*3072 크기의 array이므로
sum 연산을 해줄 때 axis = 1이라고 parameter를 지정해줘서 압축 연산을 수행해야 한다.
두 번째 축, 열을 압축시켜 없애는 sum 연산이 수행되므로 sum의 결과는 5000*1 크기의 array이다.
'''no loop의 경우 L2 distance metric의 수식을 풀어서 구현했다.
L2 distance에서 (A-B)^2를 A^2 + B^2 - 2AB로 풀어쓸 수 있는데 이를 코드로 작성하면 아래과 같다. 이 때 주의할 점은 행렬 곱과 합을 수행할 때 크기를 맞춰줘야한다. 이를 위해 transpose와 broadcasting을 이용해준다.
# compute_distances_no_loops
dists = np.sqrt(-2*np.dot(X, self.X_train.T) + np.sum(np.square(self.X_train), axis=1) + np.transpose([np.sum(np.square(X), axis=1)]))
실행 시간을 비교해보면 two loop는 35초, one loop는 31초, no loop는 1초가 걸린다. no loop가 압도적으로 실행 시간이 빠른 것을 볼 수 있다.
code implement 4
이후 작성 예정
