cycleGAN을 사용해서 사진을 만화로 바꾸는 style transfer를 진행했다. baseline 모델의 성능을 측정해보고 기존 모델보다 성능을 개선하고자 한다.
introduction


요즘 스노우, 틱톡 등 많은 플랫폼에서 자신의 얼굴을 만화풍의 그림으로 바꿔주는 기능을 제공하고 있다. 이와 같이 이미지를 특정 스타일로 변환하는 task를 Image to image translation 혹은 style transfer라고 한다. 이는 대부분 딥러닝에서 이미지 생성을 위한 모델인 GAN을 활용해서 구현했는데 그 중에서도 cycleGAN을 활용해서 프로젝트를 진행했다.
image source : '박나래, 비, 김희철'이 만찢남녀 도전한 '스노우 순정만화필터'
cycleGAN에 대하여
cycleGAN에 대해 설명하기 전, 먼저 GAN의 핵심 아이디어에 대해 설명해보겠다. GAN은 실제 데이터와 유사한 가짜 데이터를 생성하는 생성자(generator)와 이 것이 실제 데이터인지 가짜 데이터인지 구분하는 판별자(Discriminator)를 번갈아 학습한다. 생성자는 실제 데이터와 거의 유사한 가짜 데이터를 만들고 판별자는 실제 데이터와 가짜 데이터를 잘 구별하는 것이 이 모델의 목적이다.
cycleGAN 문제상황
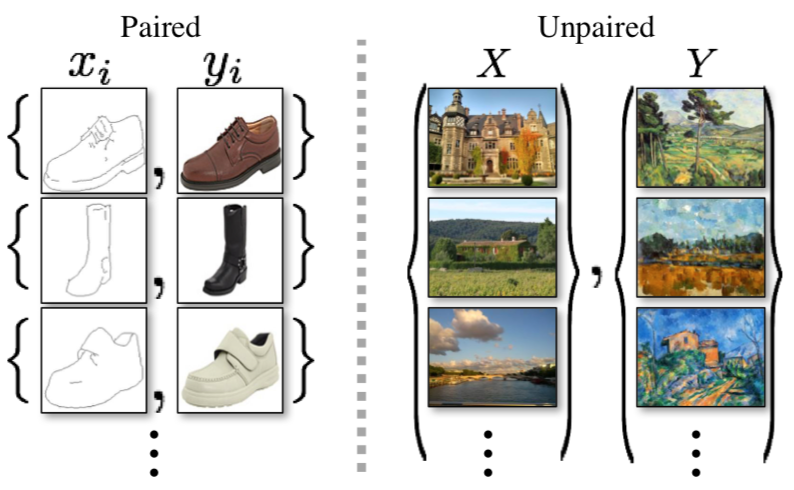
cycleGAN 저자의 전 논문인 pix2pix는 한 도메인에서 다른 도메인으로의 style transfer를 진행할 때 쌍으로 이루어진 데이터를 사용했다. 쌍 데이터(paired data)는 변환하려는 데이터가 변환되는 데이터에 어떻게 대응되는지 정보가 담겨있다. 하지만 실제로 쌍으로 이루어진 데이터는 잘 존재하지도 않고 구하기도 어렵다. cycleGAN은 이러한 문제점을 해결하기 위해 쌍이 맞지 않는 데이터로도 학습이 가능한 모델을 제안했다.
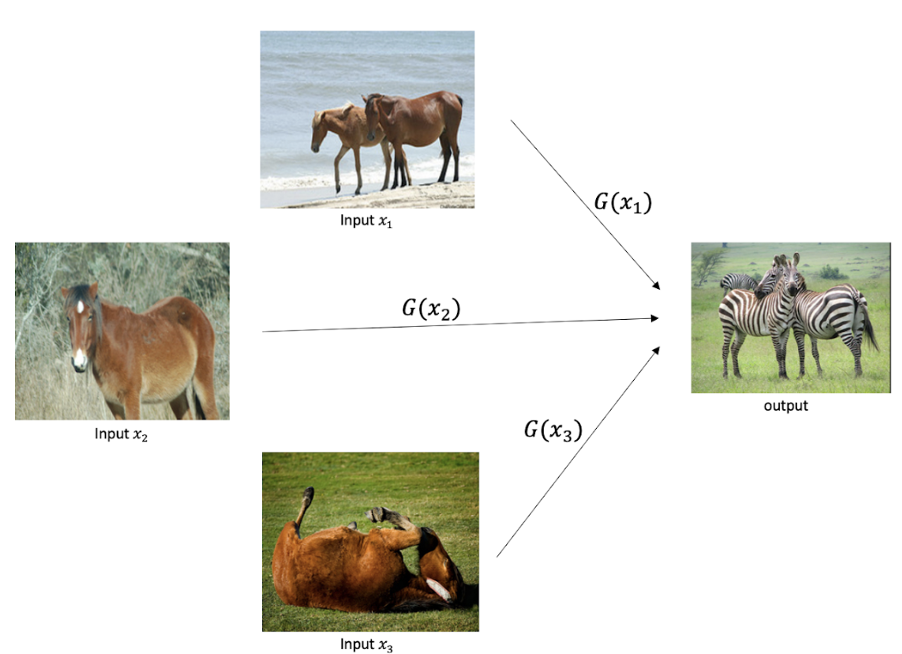
그러나 일반적인 GAN의 손실함수를 사용해서 쌍이 맞지 않는 데이터로 학습을 진행한다면 content가 무시되면서 변환되는 문제점이 생긴다. 위의 이미지와 같이 생성자가 어떤 입력이든 타겟 도메인에 해당하는 하나의 이미지만 제시할 수 있다는 것이다.
cycleGAN 핵심 아이디어 & 구조

cycleGAN은 이러한 문제를 해결하기 위해서 cycle consistency loss를 사용한다. 한 번 translate한 이미지가 다시 원본 이미지로 돌아올 수 있도록 하는 것이 핵심 아이디어이다.
즉, 원본 이미지의 content는 보존하면서 도메인과 관련한 특성만 바꾸도록 하는 것이다.
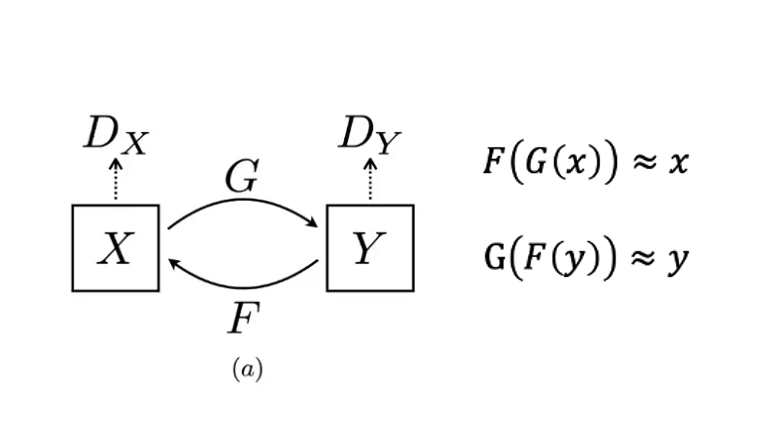
이를 위해 사이클갠은 생성자, 판별자를 각각 2개씩 사용한다. x 도메인에서 생성자 G를 거쳐서 Y 도메인의 이미지를 만들 수 있고 반대로 y 도메인에서 생성자 F를 거쳐서 x 도메인의 이미지를 만들 수 있다. Dx는 특정 이미지가 x 도메인의 이미지로 그럴싸한지 판별한다. Dy 또한 마찬가지다.
그래서 cycleGAN의 목표는 G(x)를 다시 F에 넣었을 때 원본아미지 x를 복구할 수 있도록 로스를 구성해서 학습을 진행한다. 이와 같이 사이클을 돌아 원래대로 돌아오는 이러한 loss를 cycle consistency loss라고 한다.
cycleGAN 목적함수

사이클갠의 전체 목적함수는 다음과 같다.
처음에 나오는 두 GAN loss(adversarial loss)는 각 도메인으로 이미지를 생성하는 로스로 일반적으로 GAN에서 사용하는 minmax 목적함수와 동일하다.
cycle Loss는 한 바퀴돌아 다시 원본 이미지로 돌아올 수 있도록 하는 로스다. 이전에 설명했던 것처럼 이미지가 두 생성자를 모두 거쳤을 때 원본이미지와 가능한 차이가 없도록 학습을 진행한다.
좀 더 자세한 모델의 구조와 동작과정에 대해서는 cycleGAN 논문에서 확인할 수 있다.
baseline model
지금까지 cycleGAN 모델에 대한 이론적인 설명을 했다면 이젠 실제로 사용한 baseline 코드와 결과, 작업환경에 대해 설명하겠다.
Dataset
사용한 데이터셋은 selfie2anime로 학습 시 사진, 만화 3400장, 테스트 시 사진, 만화 100장을 사용했다. 데이터셋은 캐글에서 다운받아 사용했다.
code
baseline으로 사용한 코드는 파이토치 딥러닝 프로젝트 모음집 서적에서 pytorch로 구현한 code를 사용했다. 작업 환경은 Colab에서 진행했다.
Hyper parameters
dataset_name="selfie2anime"
channels = 3
img_height = 256
img_width = 256
n_residual_blocks=9
lr=0.0002
b1=0.5
b2=0.999
n_epochs=20
init_epoch=0
decay_epoch=10
lambda_cyc=10.0
lambda_id=5.0
n_cpu=8
batch_size=1
sample_interval=100
checkpoint_interval=5
... 생략
# Losses
criterion_GAN = torch.nn.MSELoss()
criterion_cycle = torch.nn.L1Loss()
criterion_identity = torch.nn.L1Loss()
# Optimizers
optimizer_G = torch.optim.Adam(
itertools.chain(G_AB.parameters(), G_BA.parameters()), lr=lr, betas=(b1, b2)
)
optimizer_D_A = torch.optim.Adam(D_A.parameters(), lr=lr, betas=(b1, b2))
optimizer_D_B = torch.optim.Adam(D_B.parameters(), lr=lr, betas=(b1, b2))
사용한 hyper parameters이다.
colab의 최대 런타임 길이가 12시간이기에 너무 큰 에폭으로는 학습이 불가능했다. Baseline으로 가져온 코드에서는 에폭을 200으로 학습시켰으나 이럴 시에 학습하는 데만 몇 일이 걸리므로 이 프로젝트에서는 epoch을 20으로 설정하고 학습을 진행했다.
손실함수로는 GAN Loss는 MSELoss를 cycle-consistency Loss와 Identity Loss는 L1Loss를 사용했다. Optimizer는 Adam을 사용했다.
나머지는 baseline code와 동일하게 설정했다.
baseline loss graph
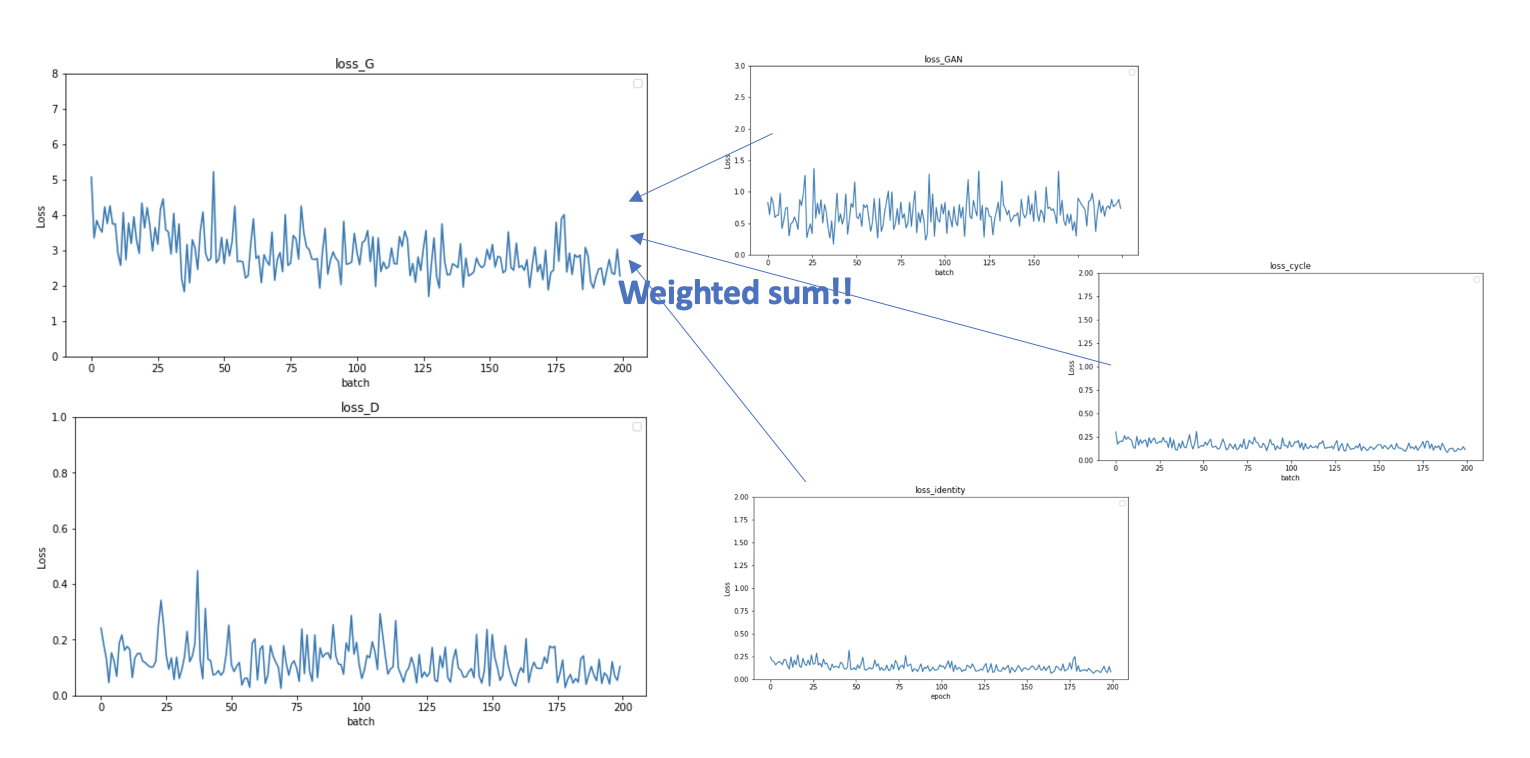
이를 바탕으로 학습을 진행했고 학습 과정 중에 확인된 로스 그래프는 위와 같다. 그래프는 파이썬의 matplotlib.pyplot를 사용해서 그렸다.
왼쪽의 D loss는 discriminator의 전체 손실함수이고 G loss는 generator의 전체 손실함수이다.
위에서 설명한 목적함수에서의 adversarial loss, cycle loss, identitiy loss에 가중치를 주어 더한 것이 loss G 이다. 이전에 설명하지 않은 identity loss는 입력 이미지의 색감이나 형태들을 보존하는 역할을 한다. loss G를 보면 값이 중간중간 튀기는하지만 점점 줄어들며 학습이 진행된 것을 볼 수 있다.
또 생성자 로스가 증가할때는 판별자 로스가 감소하고 판별자 로스가 증가할때는 생성자 로스가 감소하는 현상을 볼 수 있다. 이는 생성자와 판별자가 서로 견제하며 학습이 진행하기 때문에 이와 같은 현상이 나타난 것으로 생각된다.
FID
baseline model의 학습 결과를 보여주기 전에 결과에 대한 평가 방식을 먼저 얘기해보고자 한다.
생성된 이미지에 대한 평가는 정성적인 평가와 정량적인 평가로 나누어서 진행했다. 정량적인 평가는 GAN을 평가하는데 여러 논문에서 사용하고 있는 FID scoreF를 사용했다. 원본 이미지와 생성된 이미지의 특징의 거리를 숫자로 나타낸다. 결론만 말하자면 숫자가 작을수록 좋은 결과이다.
baseline model result

베이스라인 모델로 생성된 이미지는 다음과 같다. 학습 이후 테스트 결과에서 변환된 이미지를 저장해 그 중 성공적인 케이스인 이미지이다. 베이스 라인 모델에서도 어느정도 카툰화가 진행된 것을 볼 수 있고 FID score는 145.61으로 측정되었다.
이를 기준으로 이제는 베이스라인 모델에서 성능을 올려보기 위해 적용해본 기법들을 설명하고 그 결과들을 비교 해보겠다.
improving cycleGAN
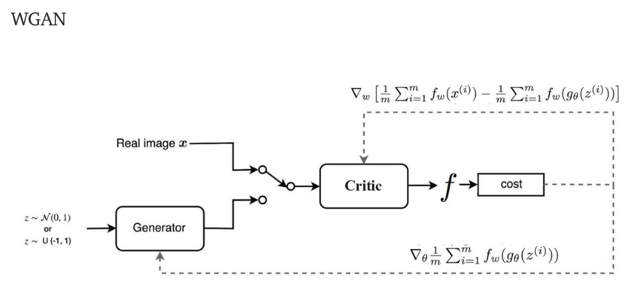
WGanGP Loss

처음으로 적용한 기법은 생성자가 판별자를 속이도록 이미지를 생성하기 위한 loss인 GAN loss를 바꾸는 것이다.
최근 cycleGAN에 대한 논문에서는 GAN loss를 기존의 MSE 기반의 loss를 사용하는 대신에 wgan-gp loss를 활용하는 경우가 더 많다는 것을 발견했다. 이를 적용해보기 위해 위와 같이 GAN loss가 적용되는 코드를 수정해주었다.
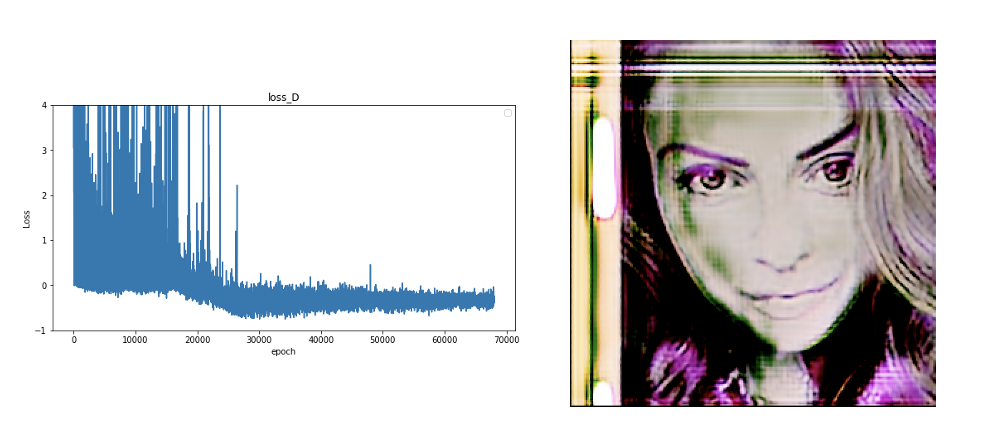
학습을 진행해본 결과 style transfer가 거의 이루어지지 않았고 loss 그래프에서도 discriminator의 loss가 0 이하의 값을 가졌다. 이는 이 모델이 잘못된 모델임을 의미하고 생성된 이미지 또한 다음과 같이 학습이 거의 이루어지지 않았다.
이와 같은 결과가 나온 이유를 찾아보니 wgan-gp loss를 사용하기 위해서는 기존 판별자가 아닌 새로운 판별자 구조인 critic을 구현해줘야한다는 것을 알았다. 기존 판별자는 이미지가 real인지 fake인지만 구별했다면 critic은 이미지의 realness 혹은 fakeness를 점수화해서 나타낸다. critic을 구현하려고 시도해보았으나 역량에 넘어가는 일이라 판단되어 다른 기법을 적용해보기로 했다.
자세한 내용을 원한다면 해당 논문과 참고한 블로그을 읽어보길 바란다.
Edge smoothing
두 번째로 적용해본 기법은 edge smoothing이다.
만화 이미지에서는 사진이나 다른 예술방식에는 없는 분명한 경계선이라는 특징이 있다. 이러한 만화 이미지의 특성을 고려해 입력 만화 이미지에 가장자리 선을 부드럽게 smoothing해준 데이터셋을 만들고 Discriminator가 이러한 이미지를 입력으로 받았을 때 0을 아웃풋 하도록 즉, 만화 이미지가 아니라고 판단하도록 하는 edge-smoothing 파트를 추가하였다.

edge promoting의 결과는 다음과 같다. 베이스라인 모델에 비해 색감이 더 살아났고 만화 이미지와 같이 뚜렷한 경계선이 나타난 것을 볼 수 있다.
하지만 FID를 측정해본 결과 150.38으로 정량적으로는 baseline보다 안좋은 결과가 나왔고 학습시간은 베이스라인 모델과 동일했지만 edge smoothing 하는데 30분 정도의 시간이 추가로 소요되었다.
LeakyReLu
마지막으로는 활성화 함수를 변경해보았다.
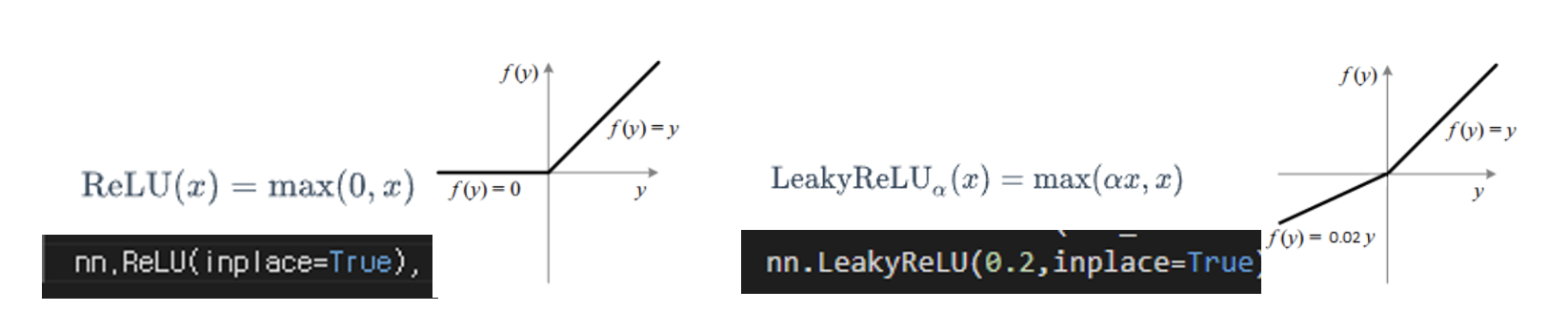
기존 generator 구조에서는 활성화함수로 relu를 사용했다. 하지만 relu의 경우 모델이 학습되는 동안 가중치의 합이 음수가 되면 계속해서 0을 출력하고 이는 dead ReLU라는 문제를 발생시킨다. 이를 방지하기 위한 방법 중의 하나인 LeakyReLu는 이를 방지하고 x가 0보다 작아도, 0을 출력하는 것이 아닌 ax를 출력함으로써 dead ReLU문제를 방지한다.
이와 관련한 논문에서는 마지막 층의 활성화 함수는 nn.tanh로 변경하지 말라는 조언에 따라 이를 제외하고 모든 relu를 leakyrelu로 변경해주었다.

leakyrelu의 결과는 다음과 같다.
정성적으로 봤을 때도 베이스라인 모델이나 다른 기법을 적용했을 때보다도 더 좋은 결과가 출력되었고 FID score도 143.06으로 베이스 라인 모델에 비해 좋은 값이 출력되었다. 해당 기법을 적용한 결과 이미지의 특징으로는 명암 효과가 짙어진 것과 얼굴의 눈이 아닌 다른 위치에서 눈으로 인식해 제일 우측 사진의 입 쪽에 눈과 같은 이미지가 출력되는 문제가 있었다.
프로젝트를 마치며
결과비교
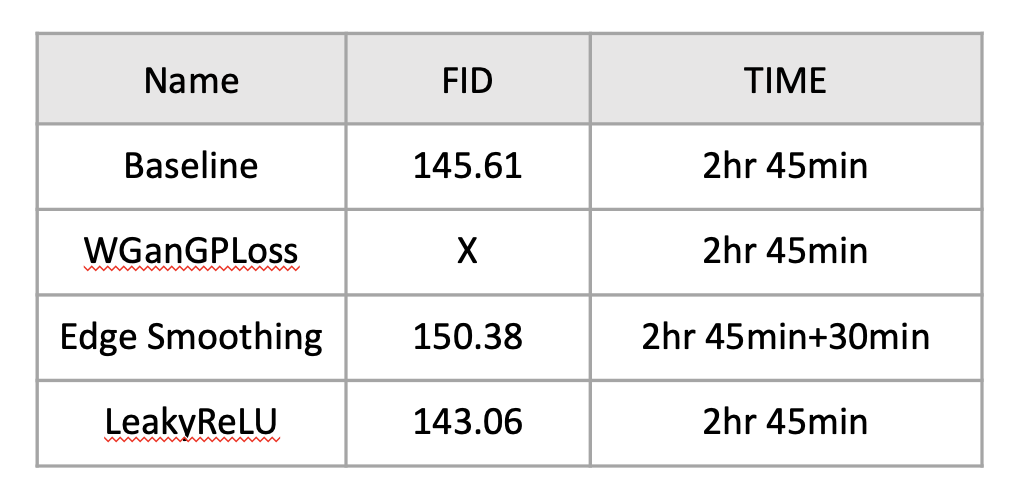
베이스라인 모델과 지금까지 적용해본 기법들의 FID score와 실행시간을 표로 정리해보았다.
적용해본 기법들이 모두 정량적으로 성능을 높여주지는 못했지만 edge smoothing 같은 경우 눈으로 봤을 때 더 괜찮은 결과가 나왔고 leakyRelu의 경우 정량적, 정성적 모두 더 좋은 결과를 얻을 수 있었다.
느낀점
이 프로젝트를 진행하면서 새로운 것들이 많았다. 제대로 된 프로젝트도 처음이었고 팀원과 함께하는 프로젝트도 처음이었고 파이토치도 처음으로 만진 프로젝트였다.
처음엔 내가 과연 할 수 있을까 라는 걱정과 불안에 휩싸였지만 너무 먼 미래를 보기 보단 바로 당장에 할 수 있는 것들을 차근차근 해나가다보니 어느새 프로젝트가 완성되어 있었다. 앞으로 다른 프로젝트나 공부, 일을 할 때 정말 중요한 마음가짐인 것 같다. devide & conquer 라는 개념을 알고리즘 수업 시간에 교수님께서 공대생이 꼭 가져야하는 마인드라고 설명해주셨던 것이 기억났다. 내가 해결할 수 없을 것 같은 문제가 닥쳤을 때 큰 산을 보는 것이 아니라 내 앞에 있는 계단 하나를 차근차근 해결하면서 정상에 오르도록 해보자.
물론 이번 프로젝트가 내 스스로 완전히 만족할 만한 결과를 도출해내지는 못했다. colab을 사용하면서 최대 런타임 길이 제한 때문에 긴 시간 학습시키지 못했고 하드웨어도 colab에서 제공하는 GPU를 사용했기에 빠른 학습이 불가능했다. 또한 적용한 기법들이 모두 성능 향상을 이끌어내지도 못했고 많은 기법을 적용하지도 못했던 점이 아쉬웠다.
하지만 진행한 task에 맞는 성능 향상 기법들을 찾아내 적용하고 그 결과를 확인하는 과정이 개인적으로 의미있는 경험이었다.
다음에도 다른 프로젝트를 소개하면서 글을 써보도록 하겠다.
