
Intro.
김 팀장🗣️ "문제가 생겼어. 길이 25cm, 무게 150g이면 분명 도미일 텐데 자네 모델은 빙어라고 예측한다는군?"
ㅇ ~ㅇ....
1. 모델 만들기
전에 만든 모델 그대로 써도 되지만, 좀 더 세련된 방법으로 다시 만들어보자!
입력 데이터 준비 by NUMPY
.column_stack(()): 전달받은 리스트를 세로로 세워서 이어 붙이는 함수

타깃 데이터 준비 by NUMPY
np.ones(): 원하는 크기의 배열에 1을 채워서 만들어주는 함수np.zeros(): 원하는 크기의 배열에 0을 채워서 만들어주는 함수.concatenate(()): 첫 번째 차원에 따라 배열을 연결하는 함수

훈련/테스트 세트 분할 by SKLEARN
train_test_split(): 알아서 훈련세트와 테스트세트로 분할해주는 함수 (알아서 섞어주고 비율도 맞춰줌)

stratify: 특정 클래스 비율에 맞게 데이터를 나누는 옵션(매개변수)

모델 훈련/평가 & 새 데이터 적용
- 이전 시간에 만든 모델과 동일
 똑같이 정확도 100%인 모델을 만들었는데, 어째서 도미를 빙어라고 판단하는 것인가...
똑같이 정확도 100%인 모델을 만들었는데, 어째서 도미를 빙어라고 판단하는 것인가...
2. 문제 분석
산점도로 확인
.kneighbors(): 'k-최근접 이웃' 모델의 옵션으로, 가장 가까운 이웃 k개를 찾아주는 메소드.distances와indexes를 함께 반환함.
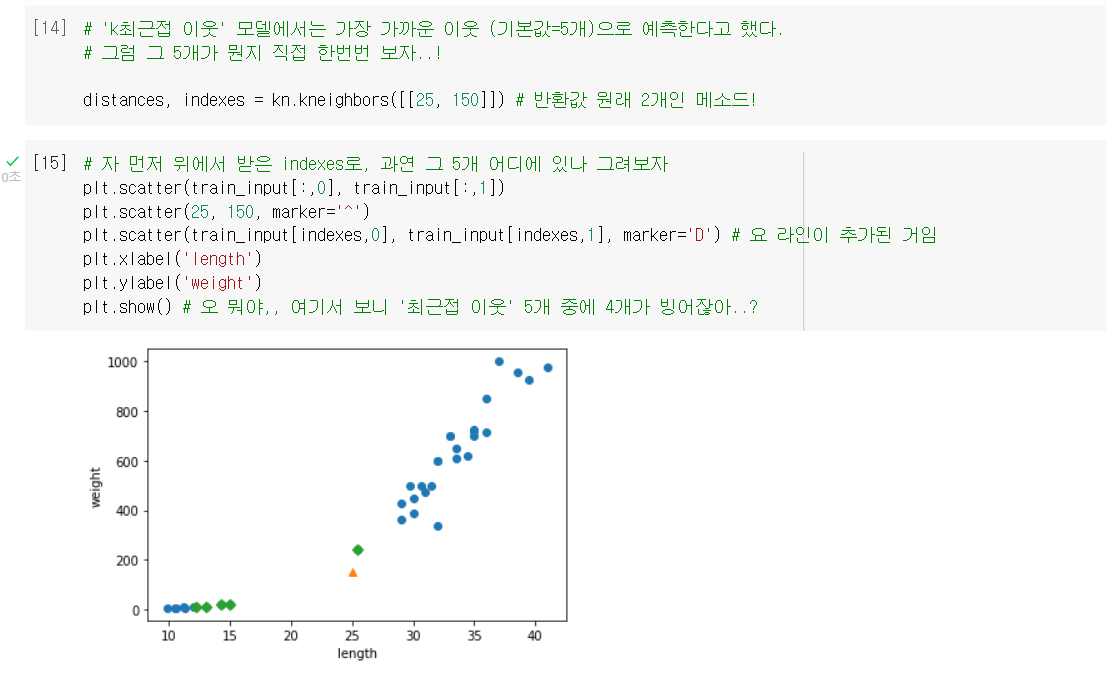
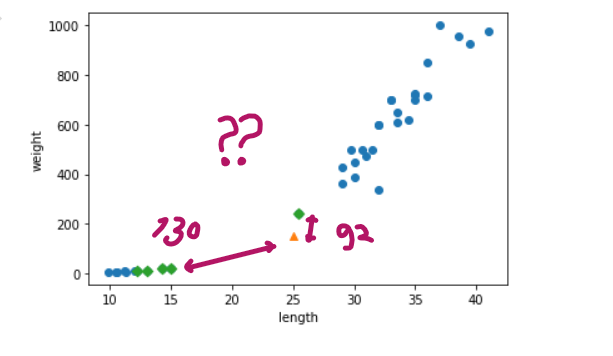
수치로도 확인
실마리 발견
- 뭐야.. 92랑 130이면 차이가 2배도 안 나는데, 산점도에선 왜 이렇게 차이가 심하게 그려져 있어? ➡️ x축 눈금이랑 y축 눈금이 차이가 나서 그렇구나!
3. 문제 해결
1차 시도: 축을 동일하게
.xlim(): x축의 범위를 지정하는 함수
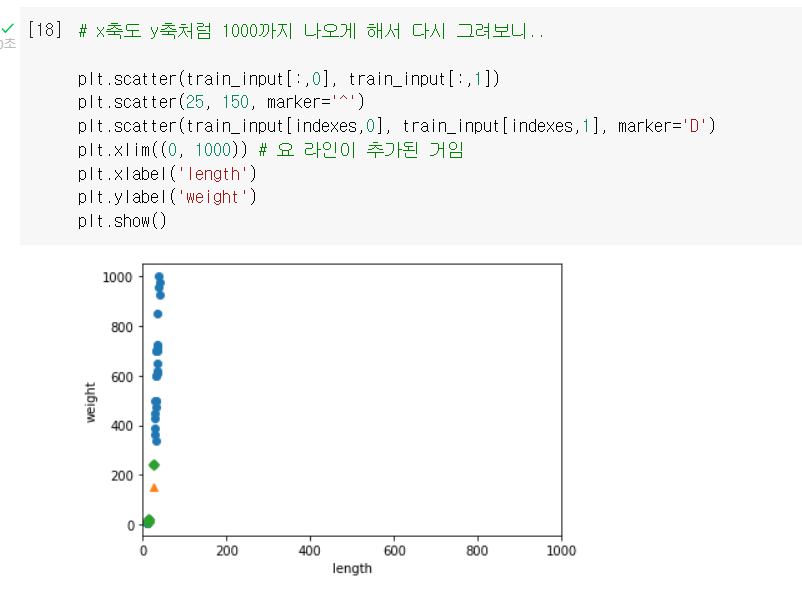
- 이제 가까운 이웃이 빙어일 수도 있겠다고 보이긴 함.
But, 일직선처럼 되어버려서 length 특성은 사실상 영향력이 사라져버림...
2차 시도: 데이터 전처리
⭐이렇게 두 특성이 분포하는 범위(스케일) 자체가 다를 땐, 그냥 비교하면 안 된다! 일정한 기준으로 맞춰줘야 함! = 데이터 전처리
- 대표적인 전처리 방법인 '표준점수'를 사용해보자!
.mean(): 평균을 계산해주는 함수.std(): 표준편차를 계산해주는 함수axis=0: 배열의 행(첫번째 축)을 따라 계산해달라는 옵션

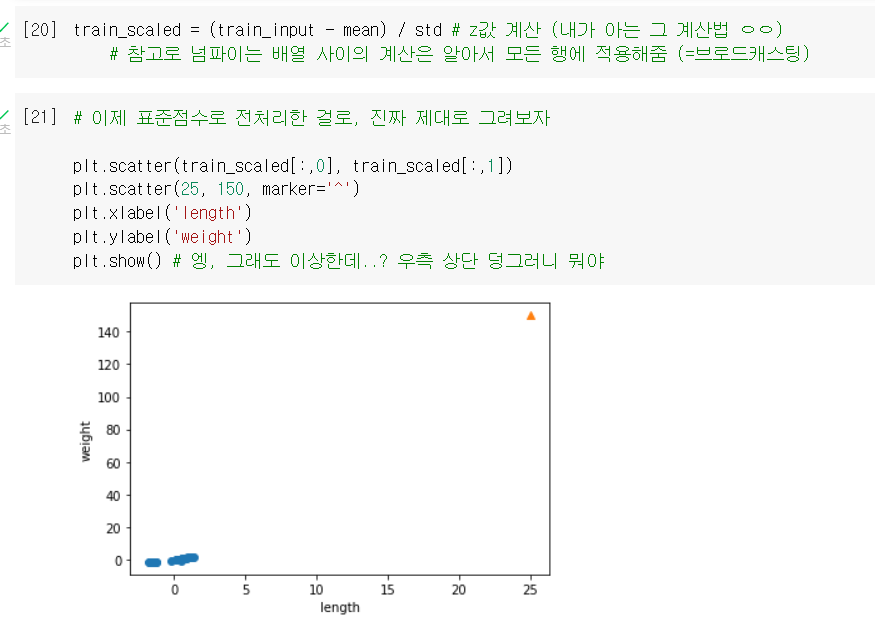
- 모르고 샘플은 표준화를 안 해줘서 다시..!
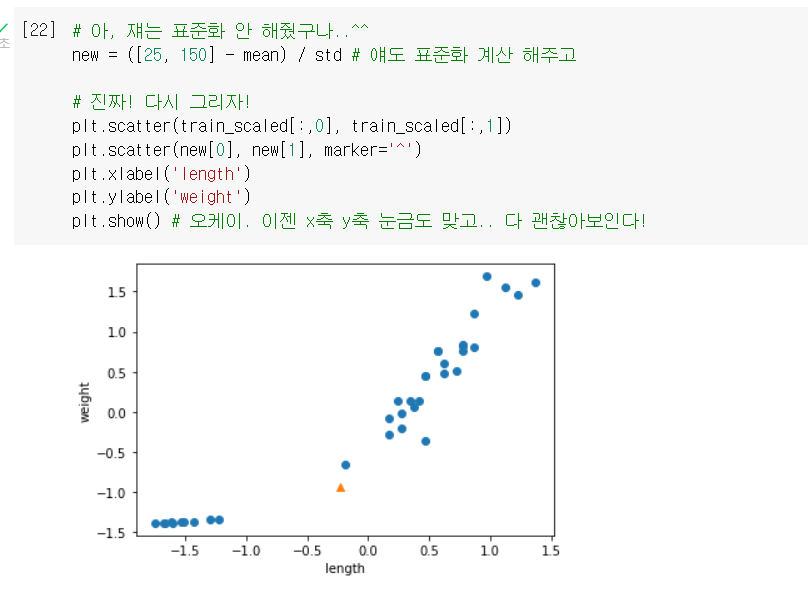
- 그리고 이 제대로 된 데이터로, 다시 모델 훈련 & 평가 !
(❗참고로, 테스트세트도 훈련세트의 mean과 std로 표준화한다는 사실 기억)

- 이제 그 문제의 도미(25cm, 150g)도 올바르게 판단함 !!!
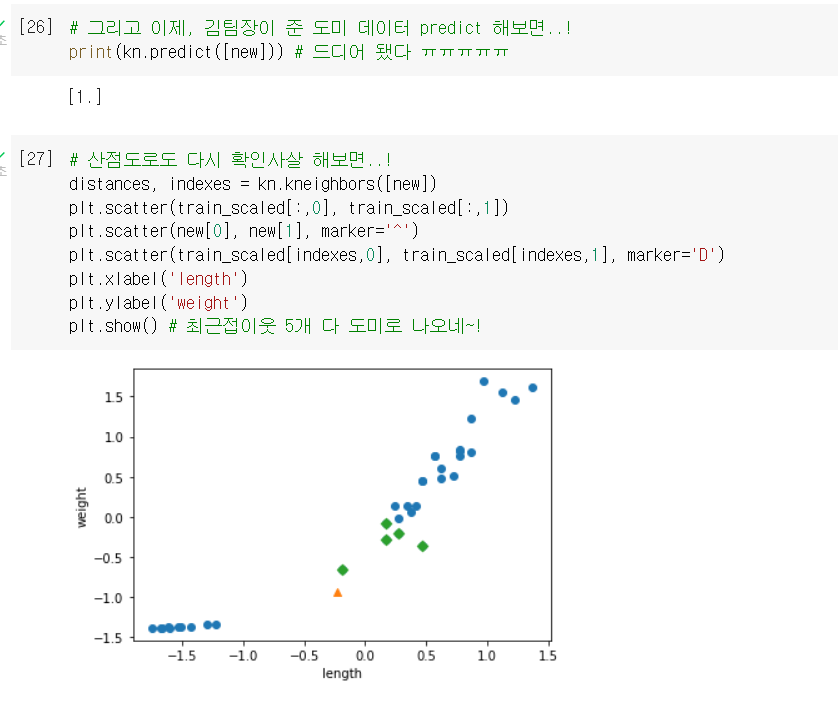 이제야 스케일에 영향을 받지 않고 안정적인 예측을 할 수 있는 모델 완성!
이제야 스케일에 영향을 받지 않고 안정적인 예측을 할 수 있는 모델 완성!
➕플러스 알파
➊ 브로드캐스팅
- 크기가 다른 넘파이 배열끼리 사칙연산 시, 연산을 모든 행/열로 알아서 확장하는 기능
train_scaled = (train_input - mean) / std↪ ex. 입력 훈련세트를 표준화시킬 때, train_input은 (36,2)의 배열이고 mean과 std는 (1,2)의 배열이었는데, 알아서 확장해서 36개의 모든 행에 대해 평균값을 구해준 것!
🤔 Hmmmm...
93p. stratify는 왜 fish_target에만 해주는 걸까? fish_data는 안 해줘도 됨?
결국 우리가 원하는 건 0과 1의 비율이 골고루 맞는 거니까 그런 것 같은데? fish_data는 애초에 값들이 가지각색이니까 기준을 정한다는 것도 말이 안 되는 것 같고.. 그리고 그래서 아마 뒤에 나오는 회귀분석(118p)에서도 사용하지 못하는 것 같다..! ⏯️
98p. 축 범위 맞추는 것만으로는 해결이 안 된다는 거죠? 혹시 축 범위만 맞추면 해결되는 경우도 있나요?
👨🏻🏫축 범위를 통일한 것은 시각적으로 문제점을 드러내기 위해서지, 데이터를 전처리한 것이 아닙니다. 모델 훈련을 위해서는 데이터를 전처리해서 실제 값을 변경해야 합니다. 🆗
98p. 두 특성 간 스케일이 다르다는 것은 곧, 단위(척도)가 다르다는 말과 동일한 것으로 이해해도 될까요?
👨🏻🏫대부분 단위가 다르면 스케일이 다르지만 반드시 그렇지는 않을 것 같습니다. 🆗 (그치, 이게 꼭 단위가 달라야되는 게 아니라, 차지하고 있는 값들의 범위가 너무 다르면 그것도 그냥 스케일이 다르다고 보는 거 같음. 312p 참고)
99p. '기준이 다르면 알고리즘이 올바르게 예측할 수 없다'고 되어있는데, 그렇다면 이전 차시들에서 만들었던 모델도 다 엉터리였던 건가요?
👨🏻🏫사이킷런의 LinearRegression 클래스는 전처리가 필요없습니다. 또 특성을 하나만 사용하는 경우에도 전처리가 필요 없습니다. 그외에는 데이터 전처리가 대부분 필요합니다. 🆗 (데이터 전처리 안 한다고 해서 잘못된 모델은 아니라는 의미에서 말씀해주신 듯! 여튼 k-neighbors 모델은 거리기반이니까 전처리가 필요하고, 엄밀히 말하면 앞에서 만들었던 모델들은 전처리가 안 된 미숙한 모델이라 할 수 있을 듯.)
🤓 To wrap up...
k-최근접 이웃 모델이, 도미로 보이는 생선을 빙어로 잘못 구분한다는 소식 → (넘파이로 데이터 준비하고 동일한 모델 훈련) → 산점도와 수치로 확인해보니 정말 빙어로 구분했다 → 문제는 x축(길이)과 y축(무게) 사이의 스케일이 차이 나는 것이었다! → 그냥 축을 동일하게 맞추니까 x축의 영향력이 사라져버렸다 → 표준점수로 전처리하니 해결!
스케일이 서로 다른 특성(데이터)을 활용했을 때 생기는 문제점과, 그 해결방안을 배웠다. 표준화(z)는 참 고등학생 때부터 지금까지 쭉 쓴다는 게 신기할 따름이다. 데이터분석 직무에서는 데이터 전처리 작업도 많이 하게 된다고 했던 것 같은데, 다른 전처리 방법들도 무엇이 있는지 궁금해진다.
