[혼공머신] 4-1. 로지스틱 회귀
혼공머신

Intro.
한빛 마켓의 새로운 이벤트인 '한빛 럭키백' 출시! 그런데 고객들이 구매에 대한 판단을 하려면 럭키백에 포함된 생선의 확률을 알려줘야겠네... 그냥 분류만 하는 건 앞에서 해봤는데, 그 분류에 대한 확률도 구할 수 있는 걸까?
= 럭키백에 들어가는 생선은 7개. 럭키백에 들어간 생선의 크기, 무게, 길이 등이 주어졌을 때, 7개 생선에 대한 확률을 출력해야 함!
1. k-최근접 이웃 분류
k-최근접 이웃 모델은 가까운 이웃 중 가장 많은 것을 타깃으로 채택했었다. 그렇다면, 그 '가까운 이웃'들의 비율이 있을 것이다. → 실제로 이 분류기에서 확률계산 기능을 제공함!
데이터 준비
- 이번에도 인터넷에서 데이터 내려받기 by Pandas
.unique(): 중복되는 거 빼고 고유한 값들 보여주는 함수

- 이 생선의 종류들을 알아맞춰야 하니까, Species 열을 target(정답) 으로 하고
나머지 5개의 열을 input(입력) 으로 하면 됨! + 넘파이 배열로 변경

- 세트 분할 및 전처리(표준화)

샘플 예측하기
- 준비한 데이터로
KNeighborsClassifier모델 훈련시키기 (2장과 동일)

- 사이킷런에서는 문자열로 된 타깃값 (0, 1 지정할 필요 없이) 그대로 사용 가능!
.classes_: KNeighborsClassifier에서 정렬된 타깃값은 여기에 저장되어있음.

- 분류기를 이용해서 예측해보면 (= 원래 이 모델로 하던 그 기능)

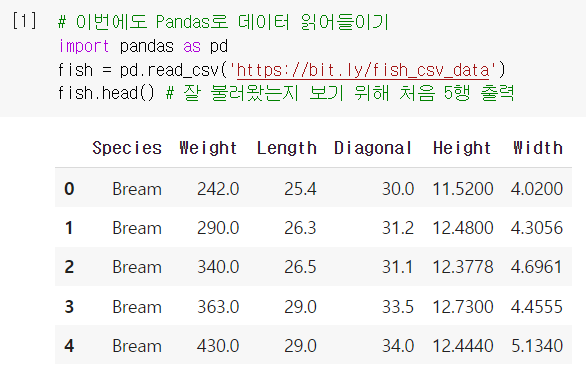
예측확률 구하기
- 그럼 이 5개의 예측은 어떤 확률 속에서 나왔을까? (= 이게 새로운 내용!!)
-.predict_proba(): 예측에 대한 확률값을 계산해주는 메소드.
-np.round: 소수점 첫째자리에서 반올림해주는 넘파이 함수.
-decimals: 반올림(round)의 자릿수를 지정해주는 매개변수.
 ex) 4번째 샘플 : Perch일 확률이 66%, Roach일 확률이 33%였음
ex) 4번째 샘플 : Perch일 확률이 66%, Roach일 확률이 33%였음
 실제로 가까운 이웃 구해보니 진짜 그러함 ㅇㅇ
실제로 가까운 이웃 구해보니 진짜 그러함 ㅇㅇ
➡️ 이게 바로 '예측 확률'임. 근데 이 경우는 가능한 확률이 0, 1/3, 2/3, 3/3 밖에 없어서 제대로 된 확률스러운(?) 느낌이 없음. 좀 더 연속적인 확률로 나타내는 방법 없을까?
2. 로지스틱 회귀
로지스틱 회귀의 기본 개념
- 이름은 '회귀'지만, 놀랍게도 대표적인 '분류' 알고리즘임. ^^;;;
- 아래와 같은 선형방정식을 학습하는 것까지는 선형회귀와 동일함.
- 근데 이 를 그대로 쓰면 '회귀'지만, 시그모이드 함수에 넣으면 0~1의 값이 됨.
= 즉, 확률처럼 볼 수 있게 되는 거임!
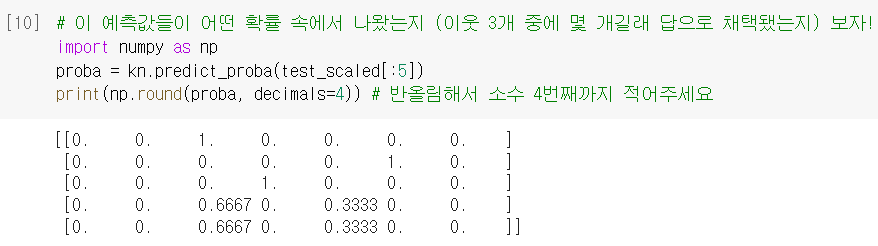
- 시그모이드 함수(또는 로지스틱 함수)
: 자연상수 를 로 거듭제곱하고 1을 더한 값에, 역수를 취하면,
아래와 같은 그래프를 얻을 수 있음. 가 0일 때는 0.5가 됨.- >0 : 양성 / <0 : 음성 → 이렇게 반 잘라서 생각하기도 편함.
(=0은 보통 음성에 포함시킴. 사이킷런에서도 그러함.)
3. 이진분류 by 로지스틱 회귀
데이터 준비 및 모델 훈련
- 전체 7마리 다 하기 전에, 2마리(도미/빙어)만 가지고 이진분류 연습해보자.
불리언 인덱싱으로 Bream, Smelt 행만 골라내면 됨. LogisticRegression(): 로지스틱 회귀모델 (역시 linear_model 패키지 아래에 있음)

샘플 예측하기
- 여기까지가 원래 하던 '분류' 딱 거기까지임. (도미or빙어에 대한 판단)

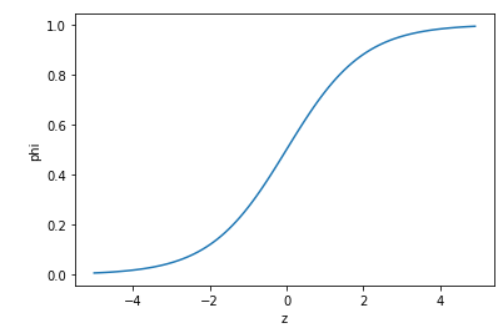
예측확률 구하기
- 위에서 예측한 결과가 어떤 확률 속에서 나왔나 구해보자. (마찬가지로
.predict_proba)

❗이진분류에서는, 1열이 음성 클래스이고 2열이 양성 클래스임
= 앞에서 사이킷런은 문자열 그대로 쓸 땐 알파벳순으로 한다고 했었으니,
빙어가 양성이 되겠네 (if. 도미를 양성으로 쓰고 싶으면, 2장에서 했듯이 0/1 지정해주면 됨)
= 위의 예측 결과와 비교해보면, Bream 4개 / Smelt 1개니까 맞아떨어지네 ㅇㅇ - 로지스틱 회귀모델이 학습한 계수를 확인해보자.

- 절편과 계수가 있으니 회귀방정식을 쓸 수 있음 → 그 방정식에 따라 샘플마다 값도 구할 수 있다는 얘기가 됨 (무게, 길이 등등 5개 넣으면 값 나오니까)
.decision_function(): LogisticRegression()에서 값을 출력하는 메소드

- 근데 값이 있다는 건? → 또 이걸 '시그모이드 함수'에 넣어서 확률을 구할 수 있다는 얘기가 됨 (= 위에서 구했던 예측확률과 같은 값이 나와야겠지 ㅇㅇ)
expit(): 사이파이 라이브러리에서 제공하는 시그모이드 함수
 구해보니까 진짜 같음 ㅇㅇ! 대신, 이진분류에서
구해보니까 진짜 같음 ㅇㅇ! 대신, 이진분류에서 decision_function의 반환값은 양성클래스에 대한 z값이란 걸 알 수 있음. (음성 = 1-양성 으로 사후 계산)
4. 다중분류 by 로지스틱 회귀
⭐자, 이제 그럼 우리의 진짜 문제를 위해, 다중분류로 넘어와보자.
모델 훈련
- 이제 전체 7마리 다 써서 훈련. 방식은 이진분류 때와 동일함.
max_iter: 충분한 훈련을 위해 반복횟수를 지정하는 매개변수 (기본값=100)
C: (릿지의alpha처럼) 규제의 양을 조절하는 매개변수. (기본값=1)

샘플 예측하기
predict: 5개의 특성을 바탕으로 판단했을 때 7개의 생선 중 무엇일지 ㅇㅇ.

예측확률 구하기
predict_proba: 위의 예측 결과가 어떤 확률 속에서 나왔는지 ㅇㅇ.
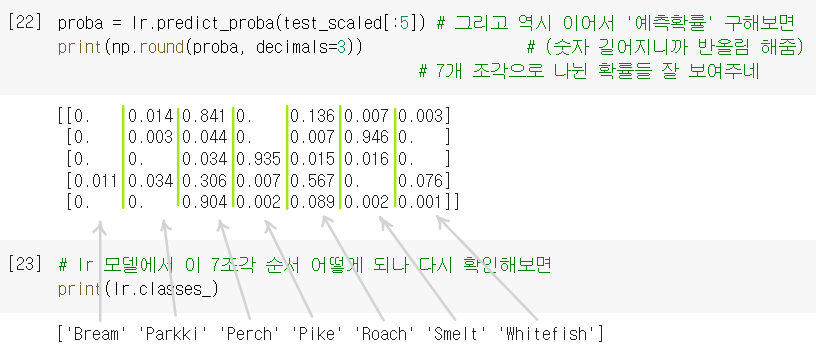
❗다중분류에서는, 클래스 개수만큼 확률을 출력함.
= 위의 예측결과와 비교해보면 각각 가장 높은 확률이랑 맞아떨어짐 ㅇㅇ
= (해석) 첫번째 샘플은 Bream일 확률 0 / Parkki일 확률 0.014 / Perch일 확률 0.841 / Pike일 확률 0 / Roach일 확률 0.136 / Smelt일 확률 0.007 / Whitefish일 확률 0.003 이었던 것이다.- (마찬가지로) 모델이 학습한 계수도 구할 수 있음. 근데 한 샘플 당 확률이 7조각이니까, 방정식도 7세트가 나옴! (Bream 확률 구하는 식, Parkki 확률 구하는 식, ••• Whitefish 확률 구하는 식)

- 이번에도 역시 절편과 계수로 회귀방정식 쓰고 → 그 방정식에 따라 샘플마다 값도 구할 수 있음 (방정식이 7세트니까 샘플마다 값도 7개씩)
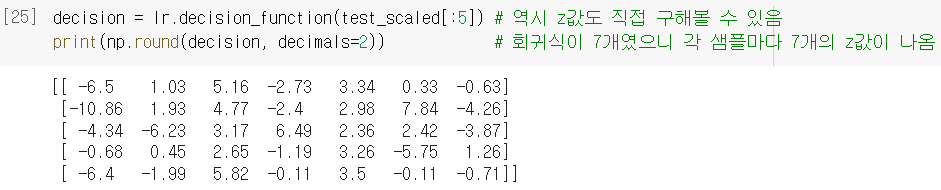
- (마찬가지로) 값이 있다는 건? →
'시그모이드 함수'에 넣어서 확률 계산 가능
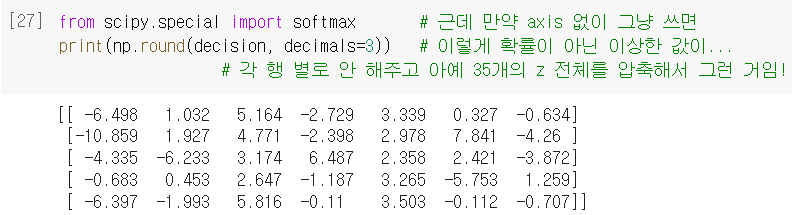
❗근데 다중분류는, 이진분류(샘플당 값 1개)와 달리, 값이 여러 개라서 다 합치면 1을 넘어갈 수 있음 = 한 샘플 내의 7개 값을 다 합치면 1이 되도록 적당히 압축 필요
➡️ 그게 바로, 소프트맥스 함수 !!! (그래서 여기선 시그모이드 X)
softmax(): 여러 개의 선형방정식의 출력값()을 0~1 사이로 압축하고, 총합이 1이 되게 만드는 함수. → 여기 넣어서 확률 구해보니 [22]에서 구했던 것과 동일^^

➕플러스 알파
➊ 불리언 인덱싱
- 넘파이 배열은 True/False 값을 전달하여 행을 선택할 수 있음.
char_arr = np.array(['a', 'b', 'c', 'd', 'e'])
print(char_arr[[True, False, True, False, False]])
---------------------------------------------------------------
['a' 'c'] # 이렇게 True 위치의 원소만 뽑아냄!➋ L2 규제
- LogisticRegression은 기본적으로 릿지회귀처럼 '계수의 제곱을 기준으로 규제'하는데, 이런 규제를 L2 규제라고 부름.
- 릿지회귀에서는
alpha가 커질수록 규제가 커졌지만,C는 반대로 작을수록 규제가 커지니 사용할 때 헷갈리지 않게 주의! (최적의C값도 역시 직접 찾아야 함)
➌ 소프트맥스 함수의 axis
- 참고로
axis는 소프트맥스 계산의 단위를 각 행마다 하기 위해서 설정해주는 거임.
➍ 확인문제 2번 풀이 (혼공미션)
[설명]
로지스틱 회귀는 선형방정식에서 출력된 값을 특정 함수에 집어넣어 '확률'처럼 보이게 할 수 있다. 이진분류는 0~1 사이의 값으로 압축시켜주는 시그모이드 함수를 쓴다. 다중분류는 값이 여러 개라서 시그모이드로 할 수 없고, 그걸 다 압축시켜주는 소프트맥스 함수를 써야한다.
🤔 Hmmmm...
179p. 넘파이로 안 바꾸면 어떻게 되나요? 그냥 리스트 형태로 나오나?
182p. 4번째 샘플 불러올 때, 왜 [3:4]로 불러오는 거죠..?
kn.neighbors()는 2차원 배열을 넣어줘야해서 그런 거임! (310p 참고) ⏯️
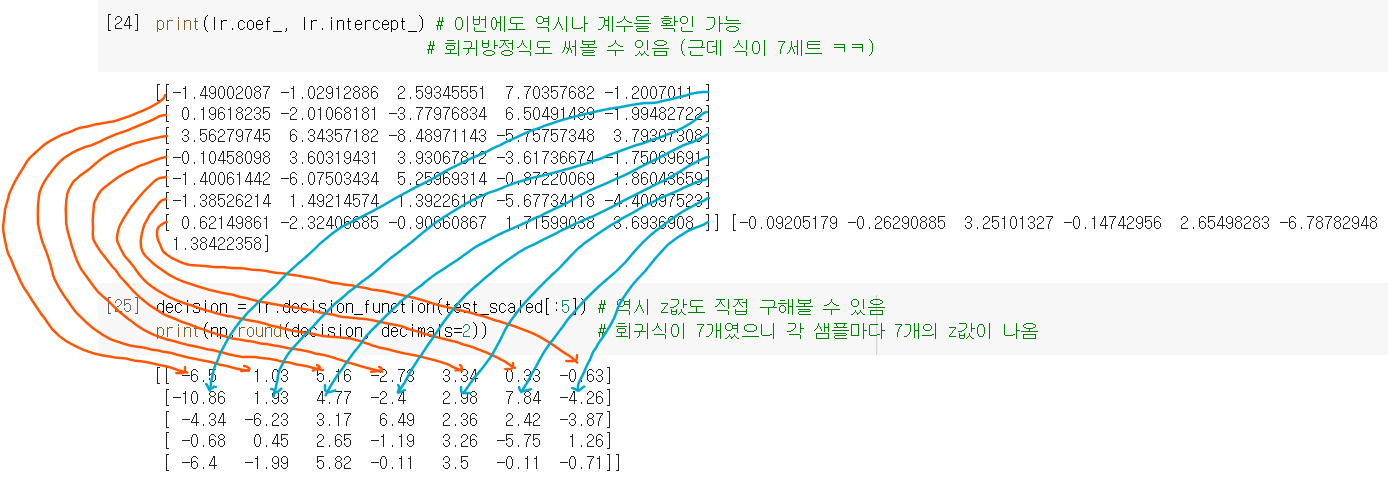
190-191p 과정 이해 잘 안 되면 이 그림을 기억하자. 이런 식으로 각 샘플마다 7개의 방정식 적용돼서 z값이 7개가 나오는 것이다..! 🆗
🤓 To wrap up...
갑자기 처음 보는 지수함수가 등장하고.. 설상가상으로 더 복잡한 소프트맥스 함수까지 나와서 당황스러웠다ㅠ 다행히 강의랑 같이 보면서 천천히 이해할 수 있었다,,, 결국 지수함수 자체가 중요한 건 아니고, "다중회귀식의 결과값(z)을 적당히 계산해주니까 0~1사이의 값이 나와서, 그걸 확률로 보겠다"는 식의 논리인 것 같다..!
'럭키백' 이벤트 출시 = 분류모델에서 '분류'뿐만 아니라 분류의 근거가 되는 '확률'까지 필요한 상황 → ① k-최근접 이웃 분류모델에서 .predict_proba로 확률 출력 가능! → but 확률 치고 너무 불연속적인 수치.. → ② 새로운 알고리즘, 로지스틱 회귀모델을 사용 = 결과값(z)을 0~1 사이의 값으로 재구성해서 확률처럼 보이게 출력 가능!! → 이진분류는 시그모이드 함수 활용, z가 0보다 크면 양성 클래스! → 다중분류는 소프트맥스 함수 활용, z가 가장 큰 클래스 채택!
