역사적인 흐름을 소개하기에 앞서 과연 좋은 deep learner의 특징은 무엇일까?
1. 좋은 구현 스킬
2. 수학적인 스킬
3. 최근에 그리고 많은 딥러닝과 관련된 논문을 읽어 보았는가?
AI는 사람을 모방하는 것을 의미한다.
그런 AI중에서도 데이터를 다루는 것이 머신러닝이며 그중에서도 신경망을 중점으로 하는 것을 딥러닝이라고 한다.
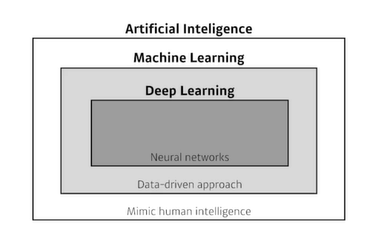
즉 인공지능과 딥러닝은 동치가 아니다.
우리는 AI중에서도 Neural Network를 사용하여 데이터를 분석하는 Deep Learing에 대해 소개할 것이다.
딥러닝의 4가지 키 요소
- 데이터(모델이 훈련할때 필요할)
- 모델(그 데이터들을 학습할)
- 손실함수(그 모델을 적합시키기위한)
- 이 모델을 최적화 시키기 위한 최적화 알고리즘
우리가 논문 자체를 보았을 때 이 4가지를 중점으로 기존보다 어떤점이 좋아졌는지를 확인하면서 보는 것이 좋다.
데이터를 받았을 때 우리는 우리가 풀고자하는 문제에 따라 분석 type이 달라진다.
1. classification(이미지가 있을때 이미지의 라벨을 맞추는것)
2. image segmentation(이미지의 각픽셀별로 뭘 나타내는지 구별해주는거)
3. image detection(이미지 안에의 물체의 bounding box를 찾고 싶은것)
4. pose estimation(이미지 안에 사람의 3차원 스켈레톤 정보를 알아내는것)
5. visual QnA (이미지가 주어지고 질문에 대답하는 것)
Loss fuction
우리가 데이터와 문제에 따른 모델을 정했을 때 어떻게 학습시켜나갈까에 대한 기준이 되는 함수이다.
딥러닝을 하다보면 신경망을 쓰게 되는데 그때의 weight와 bias를 업데이트시켜줘야한다. 그때 이 loss function을 이용한다.
ex)
회귀분석 - MSE
분류문제 - 크로스엔트로피
확률 문제 - MLE(maximum likihood function)
** 여기서 중요한것은 이 loss function은 이루고자 하는 것의 근사치에 불과하다.
즉, 단순히 loss function을 줄인다고 해서 우리가 원하는 값을 항상 이룰 수 없다. 우리가 풀고자하는 것과 loss function의 관계를 잘 파악하고 회귀니깐 mse, 분류니깐 크로스 엔트로피 이런 식으로 결정하면 안됨!
최적화(optimalization)
우리가 데이터,모델,loss function이 정해져 있을 때 네트워크를 줄이는 방법이다.
정말 다양한 방법들이 있다.(모멘텀, adagrad,adam,sgd,mini batch)
정규화(regularization)
과적합을 방지하고 손실함수를 무식하게 줄이는게 우리의 목적이 아니고 학습하지 않은 데이터에서 잘 동작하는것이 목적이기 때문에 정규화를 하게 된다.
drop out,early stopping,k-fold validation,weight decay,batch nomalization,mix up,ensemble,bayesian optimization 등등
딥러닝의 흐름
기존의 머신러닝보다 두각을 나타내기 시작한것은 2012,2013년도 부터이다. 그 때 부터 지금까지 큰 영향을 끼친 모델들을 알아보자(참고-https://dennybritz.com/posts/deep-learning-ideas-that-stood-the-test-of-time/)
-
AlexNet(2012)
이미지 분류 대회에서 처음 딥러닝(CNN)을 이용함 이전까지는 커널 기반, SVM을 이용하였다. 실제적으로 성능 발휘 -
DQN(2013)
큐러닝이라는 강화학습 방법론을 이용해서 딥러닝에 접목한 모델 -
Encoder/Decoder(2014)
어떤 언어가 들어왔을때 벡터화 하고 다른 언어로 바꿔주는거 -
Adam(2014)
요즘 쓰는 optimizer들은 다 adam인데 왜 다 adam을 쓸까? 아담이 결과가 잘나와 그냥!! 논문들을 읽어보면 왜 그러한 최적화를 사용했는지 나와있지 않아 즉, 웬만하면 잘되는것을 쓴다 느낌? -
GAN(2015)
이미지,텍스트를 만들어 내는 것, 딥러닝에서 가장 중요한 것 -
ResNet(2015)
이 모델을 통해 진짜 딥러닝이 가능해졌다? 즉 네트워크를 많이 깊게 쌓았다. 이 모델 전까지 원래 뉴럴 네트워크를 깊게 쌓으면 학습이 잘안된다고 알려져 있엇는데(test 결과가 좋지 않다.) resnet이 나온이후로 가능해졌다. -
Transformer(2017)
-
Bert(2018)
앞에서 설명한 트랜스포머를 활용하는데 bidirectional encoder를 이용하는 것이다.
fine-tuned NLP models인데 이게 굉장히 중요함
** fine-tuning이란?
뉴스 기사를 쓰고 싶은데 학습하기엔 뉴스기사가 엄청 많지 않아 이럴때 위키피디아 같은 큰 말뭉치로 pre-train후에 내가 풀고자 하는 문제에 fine-tuningg하는 것이다. -
Big Language Models(2019)
fine-tuned 모델의 끝판왕, 엄청나게 많은 파라미터 수를 갖고 있다. -
self-supervised learning(2020)
이 방법론이 핫했던 이유는 우리가 한정된 데이터를 학습할 때 학습데이터 외에 라벨을 모르는 비지도 데이터를 활용하겠다는 방법이다.
이것 말고도 다른 한가지 trend가 더 있는데 내가 풀고자 하는 문제에 대해서 잘 알고 있고 이 문제에 대해 굉장한 도메인을 갖고 있을 때 학습 데이터를 도메인 지식을 이용해 만들어 내는 것도 있다.
