경사하강법?
손실함수에서 모델의 가중치와 바이어스의 최적의 값을 찾기 위해서 사용되는 방법이다.
머신러닝의 최적화 알고리즘 중 하나이다.
작동 방식
-
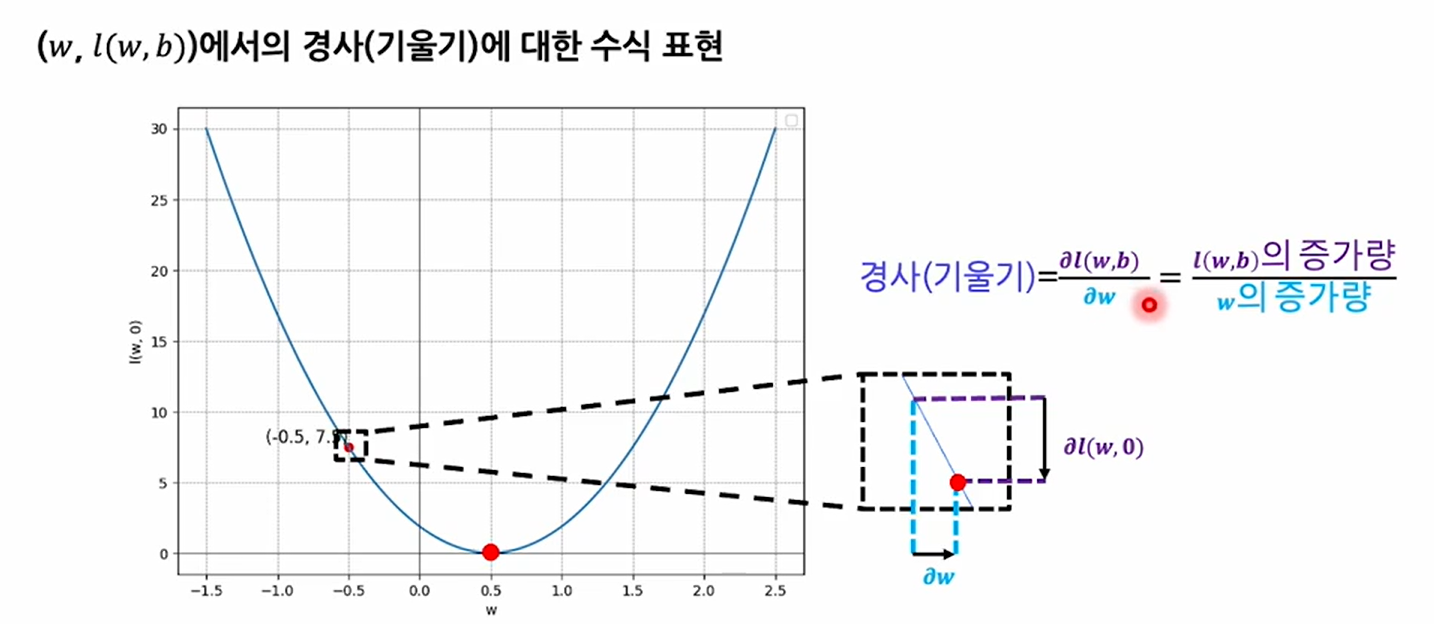
기울기(경사)구하기
예를 들어 b(절편,bias)가 0이라고 가정해보자(계산상 편의를 위해)
그 때 가중치 w값의 변화에 따른 손실 값을 살펴보고, 그 값에서의 기울기를 확인한다.
그래프로 표현해보면 bias를 0, MSE를 사용했기 때문에 포물선 형태가 되는 것을 볼 수 있다.
경사에 대한 기울기를 자동 미분하여 계산해주는 코드를 알아두자
loss.backward() (역전파 과정)
-
가중치 업데이트 하기
경사를 구했으니깐 우리가 어느 방향으로 가야 최솟값으로 갈 수 있는지를 알게 된 것이다. 업데이트는 아래와 같은 식으로 진행된다. (이때 a는 학습률을 의미한다.)
계산한 기울기로 w를 업데이트 하는 코드는 이러하다.
optimizer.step()

학습률이란?
머신러닝과 신경망 훈련에서 매우 중요한 하이퍼 파라미터
이러한 학습률은 모델이 학습할 때 가중치가 업데이트 되는 크기를 결정한다.
근데 이 학습률은 고정된 값이 아니라서 시행착오를 거쳐 최적의 학습률 값을 찾아야한다.- 기울기 초기화
업데이트를 했는데 아직 최솟값에 도달하지 못하면 다시 업데이트를 해줘야 하는데 그 때 이전 단계에서 계산된 기울기를 초기화해야 한다.
즉 각각의 학습 단계마다 기울기를 초기화한다.
optimizer.zero_grad()
지금까지 한 경사하강법 작동과정을 한번에 정리해보자

이런 경사하강법에도 단점이 있다.
경사하강법의 장단점
- 장점
모든 데이터를 사용해 가중치와 바이어스를 구하기 때문에 계산이 정확하고 안정적이다. - 단점
- 대규모 데이터셋의 계산 비용 문제
사실 우리가 이야기하는 경사하강법은 배치경사하강법이다. 배치 경사 하강법은 전체 데이터 셋을 이용하여 손실함수,기울기를 구하는 것을 의미한다. 그래서 대규모 데이터일때는 계산 비용이 매우 커진다.
2.local minima 문제
모델의 학습 과정에서 전체 데이터 셋의 기울기를 평균내어 계산함으로 손실함수 값이 가장 낮은 전역 최솟값(global minimum)이 아닌 주변값에서 낮은 지역 최솟값(local minimum)에 머물수 있다는 단점이 있다.
경사하강법의 대안(확률적 경사하강법)
SGD(stochastic gradient descent)라고도 하는 확률적 경사하강법은 모든 데이터를 이용해서
오차를 계산하는 것이 아닌 각각의 데이터 포인트마다 오차를 계산하는 방식으로 접근한다.
또한 각각의 포인트에서 기울기를 계산함으로써 그 기울기에 노이즈가 포함되게 되는데 이 노이즈는 최적화 과정에서 global minimum에 도달시켜 주는 역할을 한다.
작동원리는 기존의 경사하강법과 유사하다.
import torch.optim as optim # optim은 최적화 모듈
optimizer=optim.SGD(model.parameters(),lr=0.01)
optimizer.zero_grad() # 이전 단계 계산된 기울기 초기화하는 코드
loss.backward() #현재 손실값에 대한 기울기를 자동미분하여 계산하는 코드
optimizer.step() #계산된 기울기로 업데이트를 진행하는 코드확률적 경사 하강법이 계산이 빠르고 메모리 측면에서도 효율적이기는 하나 노이즈가 많고 학습과정이 불안정하는 문제점이 있다.
그래서 두 알고리즘의 장점만 합친것이 미니 배치 경사하강법이라는 것이다.
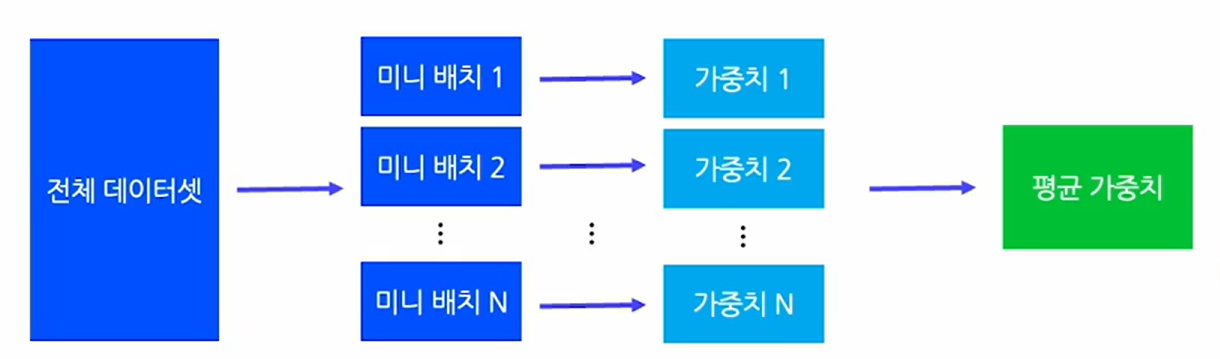
미니 배치 경사하강법
각 데이터를 배치 단위로 묶음으로써 기존의 확률적 경사하강법 보다 안정적으로 학습이 가능하며,
각 미니 배치마다 가중치를 업데이트 함으로써 전체 데이터 셋을 한번에 업데이트 하는 경사하강법 보다 학습속도가 빠르다.