dataset problem
우리가 학습하는 데이터는 종종 실제 데이터의 복잡한 분포를 모두 cover하지 못하거나 근본적으로 bias되어 있는 경향이 있다.
많은 데이터를 이용해서 평균을 취했을 때 정말 이미지가 다양하고 가지각색이라면 밑의 그림처럼 특정 패턴이 보이면 안된다.
이렇게 실제 데이터와 학습데이터의 gap차이가 모델의 일반화 성능에 방해 요소로 작용하게 된다.

또한 현업에서 학습데이터를 취득해서 사용할 때 아무리 학습데이터를 다양하게 취득해도 실제 분포를 따라가지 못한다.
예를 들어 밝은 강아지 이미지만 학습하고 어두운 강아지 이미지를 넣으면 모델이 혼동 되는 것이다.
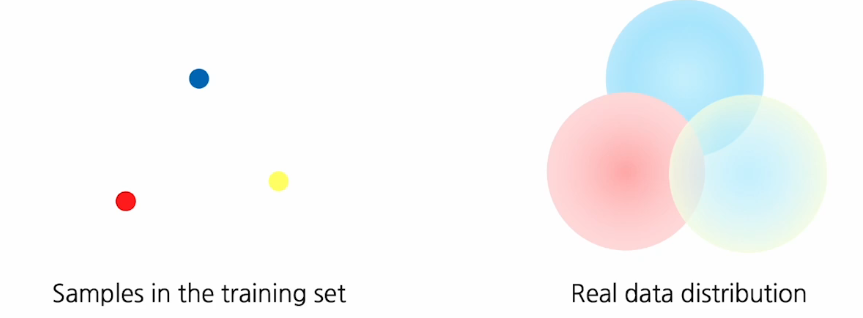
즉 훈련 데이터 셋을 아무리 잘 모으려고 해도 실제 데이터 셋을 대표하거나 완전히 커버하지 못한다.
Augmentation
이 기법은 소수의 데이터를 가지고도 데이터를 불려서 실제 다양한 데이터 분포를 최대한 커버할려는 방식이다.
데이터가 이미지인 경우 이미지 processing 테크닉으로 이미지를 증강할 수 있다.
ex) 회전, 크롭, 밝기 등등..
numpy나 openCV를 library를 통해서도 데이터 증강을 효과적으로 사용할 수 있다.
증강의 목적
train data에 다양함을 주어 다양성을 확보함으로써 최대한 real data distribution과 비슷한 형태의 데이터를 만들어 내는 것이다.
Brightness adjustment
밝기를 조절하여 증가하는 방식이다.
그래서 모델이 다양한 밝기에 강인하게 한다.
def brightness_augmetation(img):
# 각 색상 채널의 값을 100씩 더해준다.
img[:,:,0]=img[:,:,0]+100
img[:,:,1]=img[:,:,1]+100
img[:,:,2]=img[:,:,2]+100
# 이미지는 8비트여서 0~255사이의 값을 갖기 때문에 그것을 넘는다면 clip을 해주자
img[:,:,0][img[:,:,0]>255]=255
img[:,:,1][img[:,:,0]>255]=255
img[:,:,2][img[:,:,0]>255]=255
Rotate,Flip
img_rotated=cv2.rotate(img,cv2.ROTATE_90_CLOCKWISE)
img_flipped=cv2.rotate(img,cv2.ROTATE_180)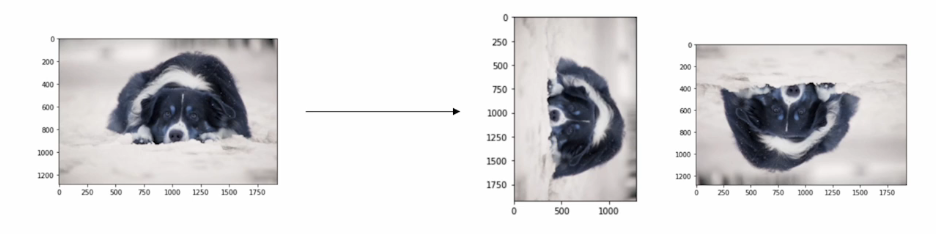
Crop
이미지를 crop을 통해서 모델에 이미지 일부분만 들어와도 성능을 낼 수 있겠끔 강인하게 학습시켜준다.
# 넘파이 인덱싱을 통해서 간단하게 구현할 수 있다.
y_start=500
crop_y_size=400
x_start=300
crop_x_size=800
img_cropped = img[x_start:x_start+crop_x_size,y_start:y_start+y_crop_size,:]
Affine transformation
이미지를 많이 왜곡 시키기는 하지만 line비율, 평행구조는 동일 하게 유지하면서 증강시키는 방식이 affine trnasformation이다.
이것도 openCV를 통해서 구현할 수 있다.
rows,cols,ch=image.shape
pts1=np.float([[50,50],[200,50],[50,200]])
pts2=np.float([[10,100],[200,50],[100,250]])
M=cv2.getAffienTransform(pts1,pts2)
shear_img=cv2.warpAffine(image,M,(cols,rows))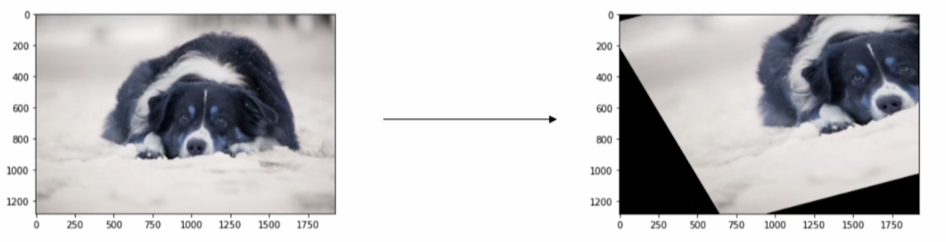
CutMix
crop과 함께 다른 클래스의 정보를 mixing해서 더 어려운 데이터를 만드는 방식이다.
구현은 간단하지만 실제로 수행했을 때 모델의 성능을 획기적으로 높일수 있는 방법이다!!

RandAugment
위에서 배운 여러가지 augment들을 종합해서 최고의 성능을 내는 augmetation 전략을 짜는 것은 쉽지 않다.
RandAugment는 자동으로 좋은 증강기법의 조합을 찾아내는 기법이다.
찾는 방법은 간단하게 여러가지 증강기법을 샘플링하고 적용한 다음, 그 도출 값을 평가하고 반복 수행하면서 최종적인 조합을 찾아내는 것이다.
예시)
어떤 policy를 찾아 내기 위해서 파라미터들을 찾는다.
- 그래서 처음 어떤 증강기법을 사용할 것인지 선택하고
- 그다음 그 증강을 얼마나의 강도로 적용할 것인지
이 2 파라미터로 샘플링을 한다.
밑의 사진은 강도를 9로 하고 Shear X와 AutoContrast 증강기법을 적용했다.
이것을 평가 후 더 좋은 조합은 없는지 반복 수행한다.

Rand Augment의 장점
굉장히 간단한 방법들을 조합하여 이용하지만 증강기법을 적용하고 안하고는 모델의 성능면에서 많은 차이를 나타낸다.
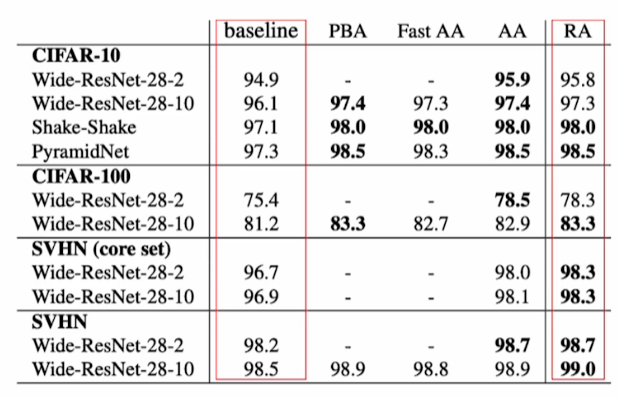
최근에 나온 증강 기법들
copy-paste
밑에 사진을 보면 왼쪽에 segmentation사진이 보일 것이다.
이 데이터 셋을 segmentation에 따라서 잘라낸 후 새로운 이미지 위에 붙여서 합성을 하는 것이 copy-paste이다.
이렇게 간단한 copy-paste로 마구마구 합성해주는 것도 굉장히 강한 증강이 된다는 연구 결과가 있다.

Learning-based video motion magnification
위에서 배운 copy-paste는 이미지 증강 뿐만 아니라 새로운 application을 수행하는 모델을 도출하는데도 활용될 수 있다.
응용사례는 Learning-based video motion magnification이다.
예를 들어 이 아이가 잘 자고 있는건지 숨을 못쉬는 건지 모션이 작아 잘 파악할 수 없다. 그럴때 그 모션을 증폭시켜서 잘 자고 있는지 확인해 줄 수 있는 그런 application이다.

하지만 이 비디오 모션 magnification은 실제 데이터를 취득할 수가 없다.(존재하지 않는 비디오 이기 때문이다.)
그래서 input,output 데이터가 필요하다.(but 존재하지않아..)
실제로 취득할 수 없기 때문에 우리가 합성 데이터를 사용하는 것이다!!
실제세계에 존재하지 않는 비디오를 합성할 때 쓰는 방법
random한 background data와 segmentation data를 활용해서 굉장히 작은 모션의 input video와 증폭된 video출력을 합성해 내는 것이다.
이때 copy-taste가 사용된다. 또한 움직임을 표현하기 위해 translation을 사용했다.
예시 사진을 보면 피자 위에서 소가 날라다닌다. 말이 안되지만 모션이라는 것은 국부적인 움직임을 통해서 느낄 수 있는 것이고, semantic 객체에 대한 클래스 정보 보다는 texture의 움지기임이 중요하다.
그래서 local 하게 작게 잘라서 보면 실제 비디오와 합성된 비디오의 모션이 그렇게 큰 차이가 없고 간단한 translation으로 세상의 대부분의 복잡한 모션도 끊어서 보면은 굉장히 유사하겠끔 모델링 할 수 있다.
이런 합성 데이터 만으로도 충분한 결과를 낼 수 있다.

이러한 기법을 통해 특정 응용 모델을 만들 때에도 타겟 task data가 취득하기 어려울지라도 합성데이터는 굉장히 쉽게 만들 수 있기 때문에 손쉽게 모델을 구축할 수 있다.
