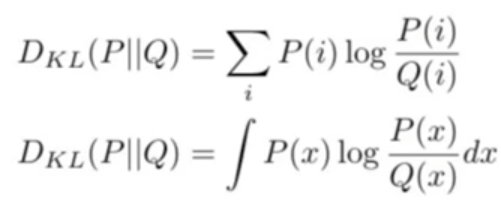손실함수
정의
머신러닝(딥러닝) 모델이 얼마나 좋은지, 나쁜지를 정량화 하는 함수 ( )
y_hat(예측값)과 y(실제값)이 얼마나 다른지에 따라 모델에 페널티를 주는 양수를 출력한다.
- 손실함수가 가져야 하는 성질
1. 이면 loss가 0이어야 한다.
2. 이면 모델에 패널티를 주어 미세 조정할 수 있다.
3. 와 의 격차가 크면 크게 패널티를 줘야 한다.
- 손실 함수 정의하는 방법
1. 차별적 설정(discriminative)(마진 기반손실)
이진 분류의 경우 기준값을 y=1 or y=-1로 두어 loss function을 로 두어
부호가 같으면(같은 클래스, 정확한 분류) 손실이 작거나 0,
부호가 다르면(다른 클래스,잘못된 분류) 손실이 크게 한다.
의 절대값이 크면 클수록 모델이 자신 있게 분류 한 것
차별적 설정은 머신러닝 모델에서 자주 쓰인다.
마진 기반손실 종류 예시)
- 0/1 손실
잘못 분류하면 loss가 1, 정확하면 loss가 0으로 두는 step function인데
단점이 이면 미분이 불가능하다는 점이다.(쓰기 힘들다.)
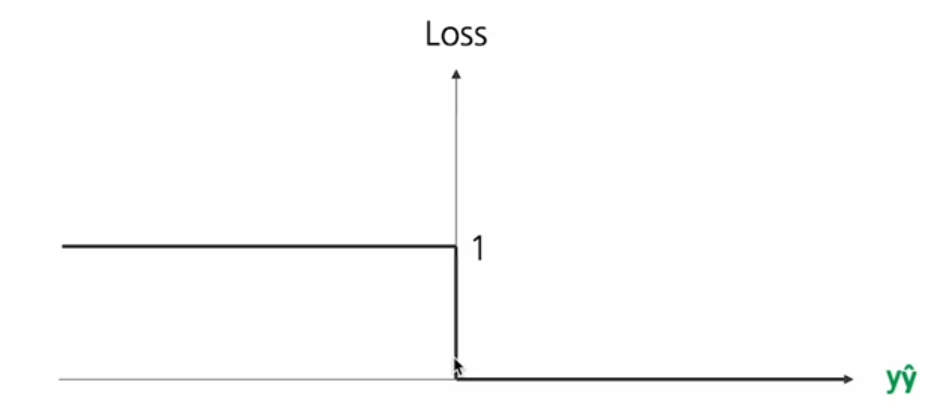
- 로그 손실
step function을 로그 함수를 적용해 나타낸것으로 정확할수록 패널티가 작아진다. 연속함수라서 어느 시점이든 미분가능하다!
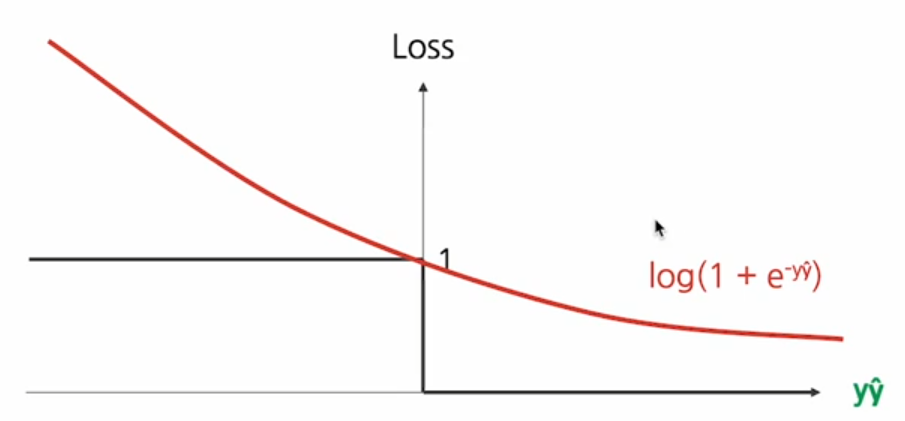
- 지수 손실
로그 손실과 비슷하지만 잘못된 경우에 로그 보다 더 엄격하게 패널티를 부여하고 정확한 경우에 로그보다 더 적게 패널티를 부여한다.
지수 손실은 매우 가파라서 outlier의 영향을 많이 받는다. 노이즈가 많은 데이터에 부적합 - Hinge 손실
어느정도 자신 있게 맞았다고 생각하면 0을 주고 그게 아니면 어느 정도 로스를 선형적으로 주는 손실 함수이다.
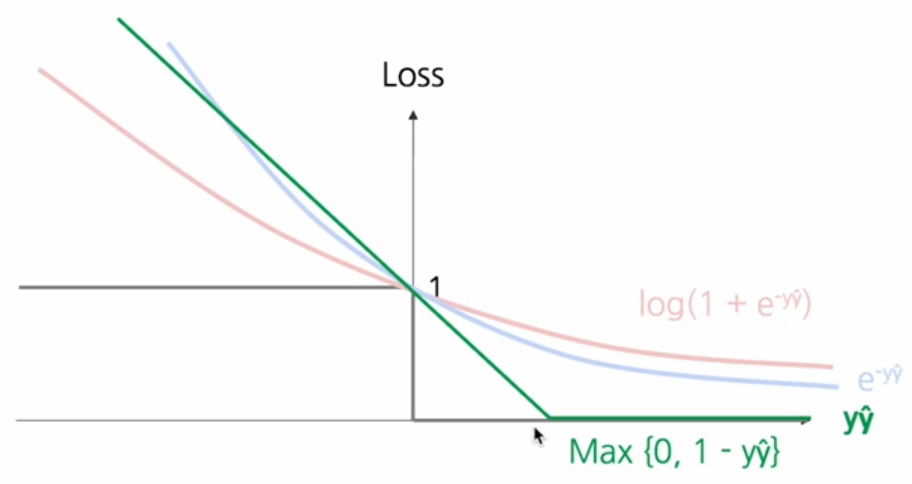
Hinge 손실과 로그 손실이 널리 사용되는데
힌지 손실은 로그보다 계산이 매우 효율적이고(미분값이 항상 상수, 굳이 미분안해봐도 암),
로그는 출력을 p(y|x)(확률값)로 볼 수 있어서 힌지보다 해석이 쉽다.
2. 확률적 설정
딥러닝 모델을 짤때는 차별적 설정을 쓰지 않고 확률적 설정을 쓴다.
ex)
- sigmoid
시그모이드는 이진 분류 문제에 대해 한 클래스의 확률인 하나의 점수 를 예측하고 그 점수 차이에 대해 시그모이드 함수를 적용해 손실을 구한다. - softmax
output이 2개가 아닌 여러 개가 있을 때 맞는 클래스를 1로 두고 다른클래스들은 모두 0으로 두기 위해 소프트맥스를 사용한다. 입력값을 지수화 하는 소프트맥스는 큰 수를 다루게 되어 수치적 불안성이 발생할 수 있다.
이를 예방하기 위해서는 가장 큰 값을 계산하여 모든 값에서 그 값만큼 빼주면 가장 큰 값이 0이 되어 안정적으로 변할 수 있다. - cross entropy
는 i번째 데이터에 k번째 클래스의 정답값을 의미한다.
크로스 엔트로피 식은 복잡해보여도 모든 클래스를 더하면 인 항만 남는다.
즉, 모든 샘플에 대한 -log(올바른 클래스에 대한 예측확률)의 합계이다.
이진 크로스 엔트로피는 아래의 식에서 K가 2개일 때이다.
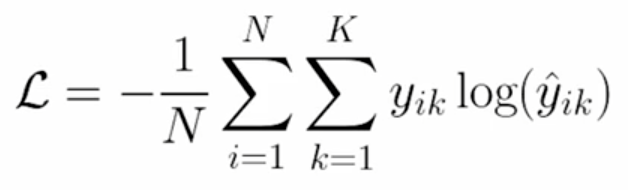
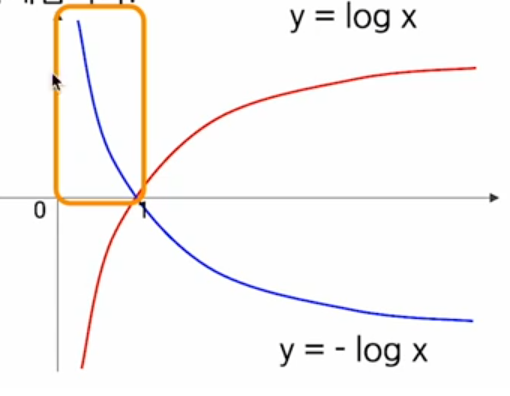
앞에 '-'를 붙이는 이유는 아래의 그림과 같이 예측확률이 1에 가까울 수록 0의 값을 주고 0에 가까울수록 큰수를 줄 수 있도록 하기 위해서 앞에 -를 붙인 것이다.
- KL(Kullback-Leibler) 발산
KL은 두 개의 확률 분포가 있을 때 두 분포의 유사성을 측정하는 것이다.
KL의 값이 작으면 작을수록 두 확률의 분포가 비슷하다는 것이다.
머신러닝에서 두개의 분포를 비교할때 자주 쓰인다. 하지만 실제 거리를 나타내지는 않는다.