머신러닝(Machine Learning)
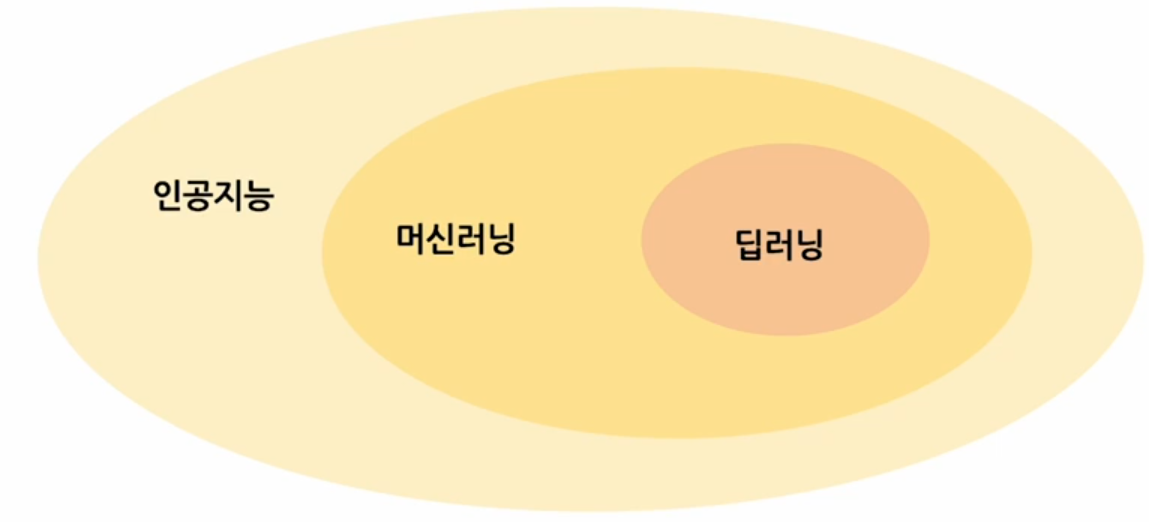
인공지능, 머신러닝, 딥러닝은 개념의 차이가 있다.
인공지능 - artifical intellingence 기계가 인간처럼 지능적인 행동을 할 수 있게 하는 모든 기술, 굉장히 포괄적이다.
머신러닝 - 어떤 데이터로부터 패턴을 인식하고 그 패턴을 기반으로 결과를 예측하는 모델을 의미한다. (패턴인식)
딥러닝 - 머신러닝을 가능하게 하는 한가지 메소드이다. Deep Neural Network(DNN)를 이용해서 굉장히 복잡한 패턴을 학습하는 기술
머신러닝에 대해 좀 더 알아보면 머신러닝은 다음과 같은 알고리즘을 연구하는 학문이다.
어떠한 작업 T에 대하여
경험 E와 함께
성능 P를 향상시킨다.
그래서 <T,P,E>가 주어져야 머신러닝이 정의가 된다.
ex) 이미지 분류
T : 주어지 이미지가 개인지 고양이인지
P : 분류 정확도
E : 개와 고양이 이미지로 이루어진 학습 데이터 셋
-
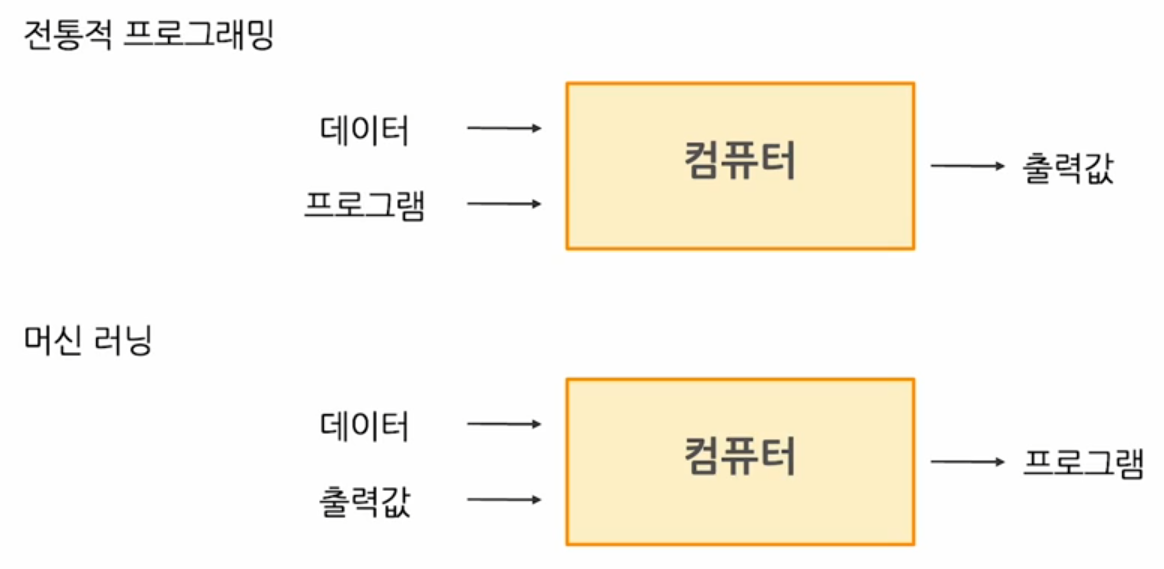
머신러닝과 전통적인 프로그래밍의 차이
sorting을 예시로 들자면 전통적인 프로그래밍(sort,dfs 알고리즘)은 데이터와 sort해주는 함수를 넣으면 정렬된 출력값을 내보낸다.
머신러닝은 분류문제로 예시를 들자면 이미지 데이터와 개인지 고양이인지 알려주는 label을 같이 넣어주면 개와 고양이를 분류하는 모델(프로그램)을 만든다.
-
머신러닝 적용 사례
CV(컴퓨터 비전), 자연어 처리(Chat GPT), 문자 인식(자동완성기능),음성 인식 등 다양한 방면으로 활용된다. 일상 곳곳에 활용되며, 인간의 일들을 곧 대체할 것이다. -
머신러닝의 종류
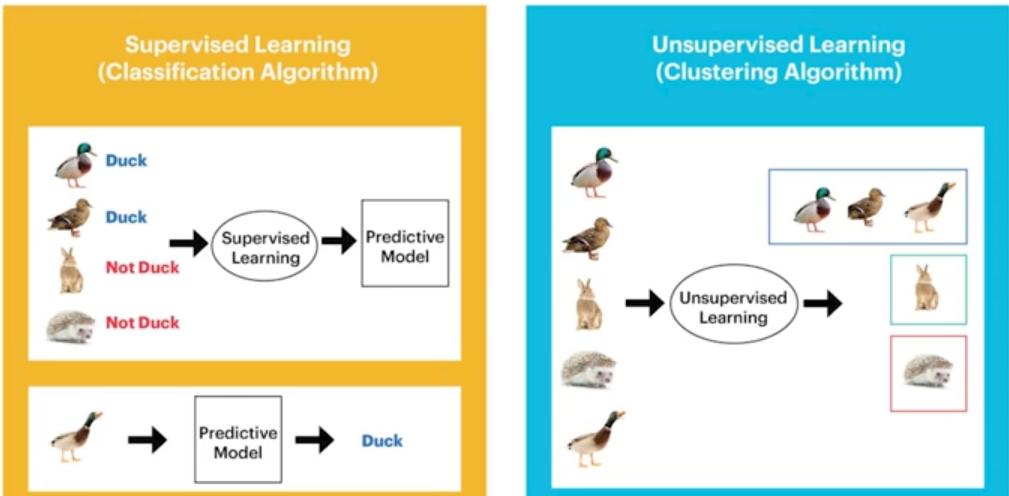
1)지도 학습
input data와 output data가 다 매칭되어 있는 상태에서 학습할 때 학습데이터+원하는 출력을 세트로 제공한다.(딥러닝에 나오는 많은 방법론들이 지 도학습에 해당한다.)
ex) 회귀문제, 분류문제
2)비지도 학습
input data만 있으며, 원하는 출력도 없다. 비지도 학습은 label이 없는 데이터에서 x의 성질만을 이용해서 패턴을 학습한다. 가까이 있는 것끼리 묶어준다.
ex) 클러스터링(군집화), 유전체학 응용(비슷한 유전자끼리 묶어준다.)
3)강화 학습
어떤 데이터 셋을 통해 학습하기 보단 어떤 로봇(agent)을 특정 환경에 던져놓고 그 로봇이 그 환경과 상호작용하면서 스스로 기술을 자동 학습하게 하는 방식이다.
주어진 상태에서 수행해야 할 작업을 알려주는 매핑을 policy라고 한다. 그리고 그 작업을 잘 수행하면 reward를 준다.
ex) 로봇 팔 물건 들게 학습시키기 같은 로봇 제어, 자율 주행
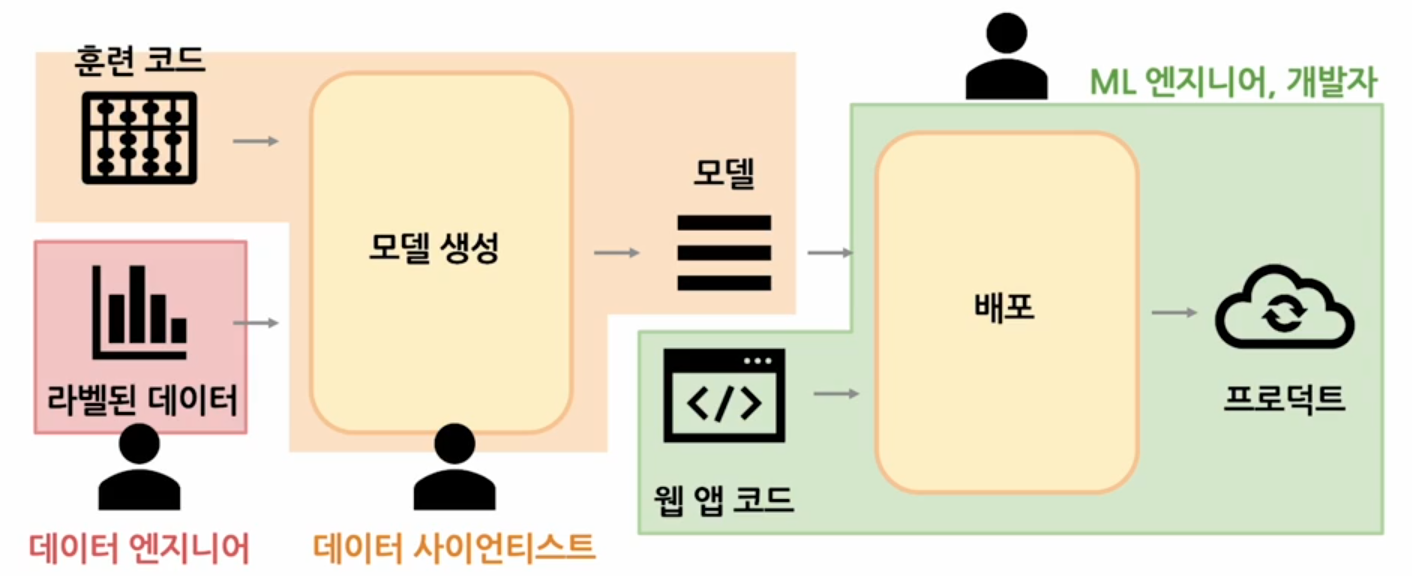
ML lifecycle
ML lifecycle은 머신러닝 모델을 개발하고 배포하고 유지 보수하는 일련의 단계들을 정의하는 프로세스이다.
즉 우리가 학교나 기업에서 특정한 문제를 풀기 위해 머신러닝을 쓸텐데
어떤 머신러닝을 개발할건지,
어떻게 제품화해서 배포할건지,
사용자들이 꾸준히 사용할 수 있게 어떻게 유지 보수할건지,
그 이상의 것들까지 다 포함한 이런 모든 일련의 과정을 ML lifecycle이라고 한다.
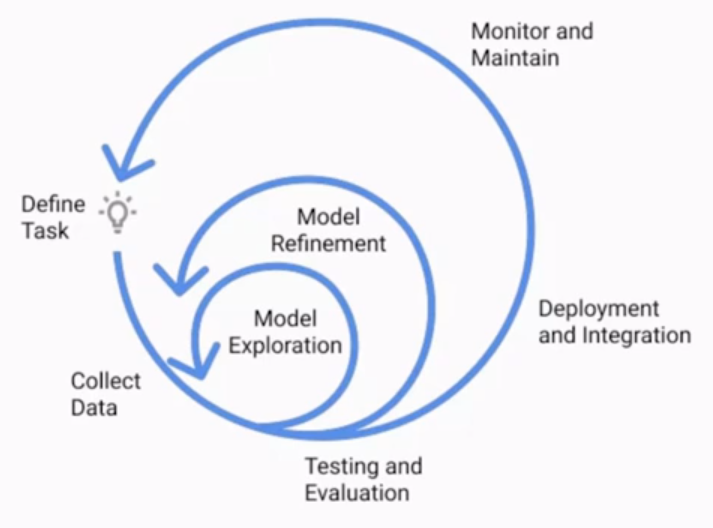
data를 수집하는 단계에서 test하고 평가하는 단계 사이에 있는
model exploration(일주일 마다 성능이 향상되는 모델을 빠르게 바꿔주는 과정)과
model refinement(매일 매일 늘어나는 data가 계속 업데이트되고 실시간 훈련 하는 과정)는
매우 중요한 부분을 차지한다.
- 머신러닝 cycle 단계
- 계획하기
성공지표(평가지표) 및 목표 세우기 - 데이터 준비
데이터 수집, labeling, 데이터 정리, 데이터 처리 및 관리 - 모델 엔지니어링
계획단계에서 세운 모든 정보들을 이용해 모델을 구축 및 학습 및 검증
만든 모델이 시스템에 들어갈 수 있게 모델 경량화 및 모델 해석 - 모델 평가
모델을 product화 해도 되는지 테스트 해보기 - 모델 배포
- 유지 및 보수
- 사이클의 요소마다 해당되는 직업
1) 데이터 엔지니어(data collection, data preprocessing)
2) 데이터 사이언티스트(새로운 모델을 배우고 모델을 개발하는 일, 파이토치,텐서플로우를 잘 만져야 함)
3) ML 엔지니어, 개발자(실제로 모델을 코드 실행시키고 배포하고 product화 하는 사람(여러가지 언어를 할 수 있는 사람))