Multi-modal learning이란?
AI에서 멀티모달이라는 용어를 종종 들어봤을 것이다.
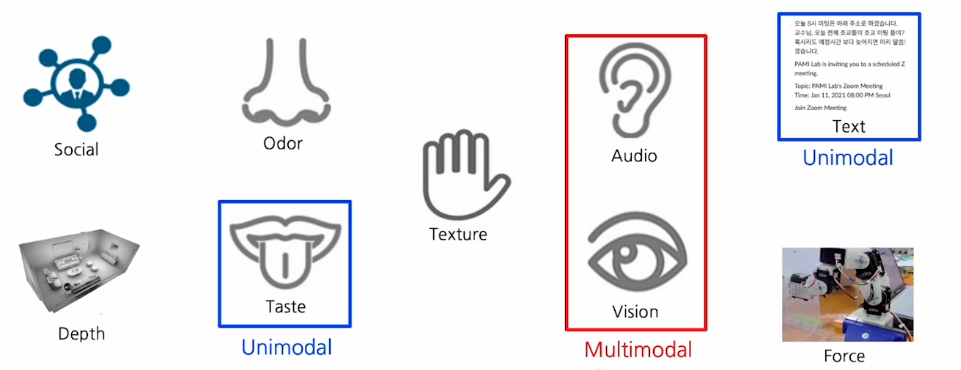
vision data와 text data 등 이런 data들이 각각 개별적으로 사용되는 것은 unimodal이라고 한다.
vision data, audio data, text data등 모두 포함하여 사용하는 것은 multimodal이라고 한다.
최근에 많이 떠오르는 것인데 서로 다른 데이터를 뉴럴 네트워크 구조에다가 합쳐서 사용하기만 하면 학습이 될것 같지만 꽤나 많은 어려움이 존재한다.
multi-modal의 힘든점
-
audio,image,text data를 보면 그 구조가 다르다.
이 뿐만이 아니라 3D,Lidar,열화상 카메라, 각종 센서들 마다 각기 다른 데이터 구조를 가지고 있다.
이런 다양한 구조 때문에 neural network를 설계할 때 앞 부분을 data에 맞는 design을 요구하게 된다.그래서 모델의 구조 설계가 매우 복잡하고 중요하다.

-
모달리티 데이터끼리의 구조가 다를 뿐만 아니라 그 데이터 구조안에 들어 있는 정보량도 다르다.
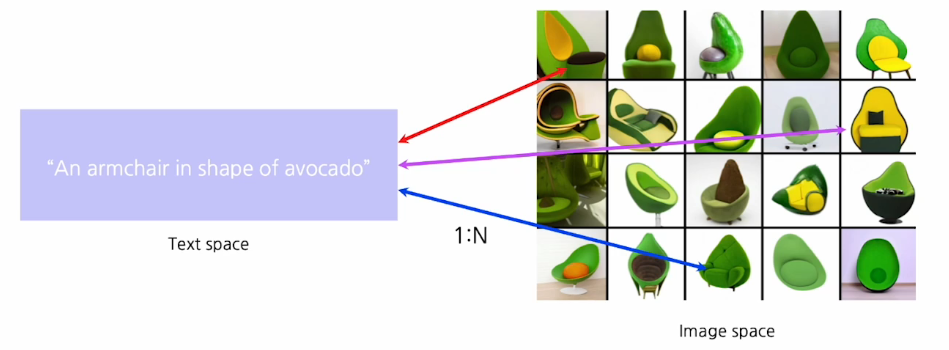
아래 사진과 같은 text를 보았을 때 이거에 해당하는 visual data는 하나만 일치하는 것이 아니라 많은 가능성들이 있다.그래서 서로 다른 모달리티 간에 매칭 관계는 1:N의 관계를 갖기 때문에 어려움이 있다. 우리가 일반적으로 하는 회귀로는 해결되지 않는다.
-
위와 같이 데이터 정보량의 불균형으로 인해서 2개 이상의 데이터를 합성했을 때 하나의 데이터를 사용하는 것보다 더 좋은 성능을 내지 못하는 경우가 많다.(bias 문제)
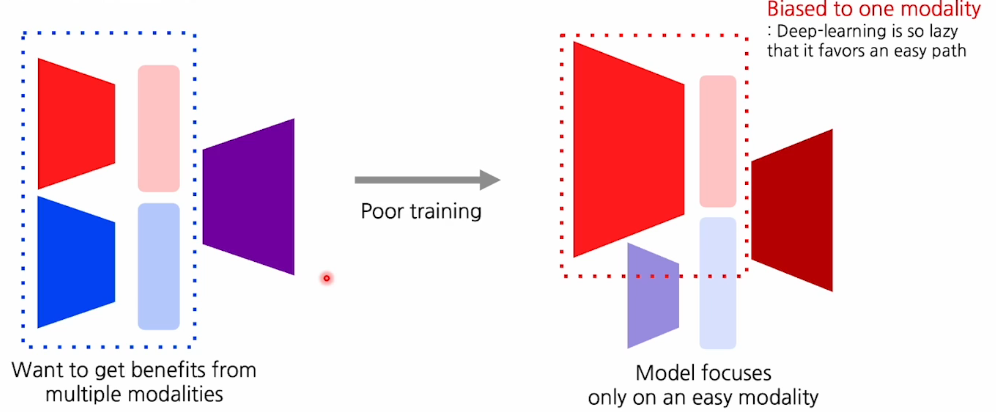
아래의 사진의 왼쪽을 보면
우리가 관심있는 tesk head(보라색)가 있고 input으로 서로 다른 모달리티를 활용을 해서 feature를 mapping 후 퓨전을 해서 target task를 수행한다.
이렇게 되면 우리는 서로의 모달리티가 서로다른 정보를 가지고 있기 때문에 서로의 보완된 정보를 갖고 있어 더 좋을 것 같지만 이렇게 학습하면 한쪽으로 biased되어 학습하게 된다.
예를 들어 액션 task일 때 input을 음성과 이미지를 넣는다면
이미지에는 액션과 관련된 정보가 명확하게 들어 있는 경우가 많은데
음성 데이터 같은 경우에 노이즈도 많고 배경 소리도 포함되어 있어 굉장히 노이지한 데이터를 제공한다.
그래서 음성으로는 학습이 어렵기 때문에 대부분의 학습이 이미지 기반으로 일어나게 된다.(biased, 성능이 떨어짐)
-
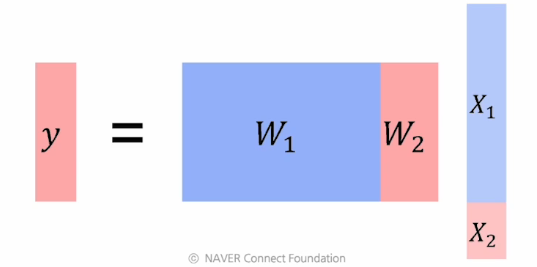
위와 같은 비슷한 불균형 문제가 dimension의 차이에 의해서도 일어난다.
우리가 만약 2가지 모달리티를 x1,x2라고 할 때,
이 두개의 dimension이 다른 경우에 weight를 보면 크게 나는 경우가 있을 수 있다. 그렇게 되면 y가 계산될 때 dimesion이 작은 feature는 상대적으로 기여할 수 있는 확률이 적어진다.
이러한 문제들 때문에 멀티모달 learning이 단순하지 않고 복잡하고 심오하다. 그럼에도 우리가 멀티모달을 이용하면 굉장히 많은 application을 할 수 있다.
이런 이점때문에 어려움에도 사람들이 계속 발전시키고 개선된 멀티모달 learning model과 학습법을 개발하고 있다.
인간의 multi modal process
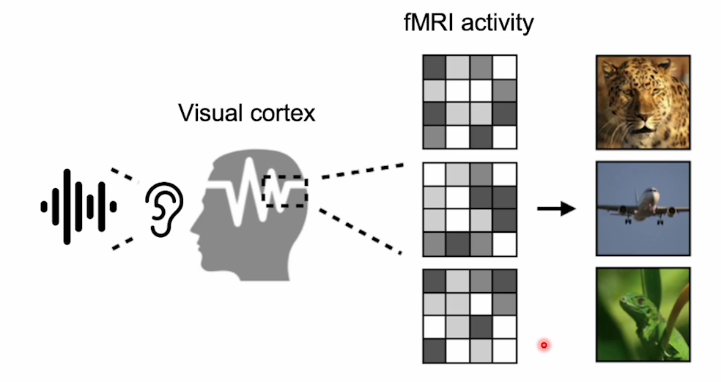
인간에게 사진을 보여주고 fMRI를 통해 뇌의 활동을 recoding한 후에
이미지에 대응하는 소리를 들려주면 우리의 뇌에서는 사진을 봤을 때 발생하는 신호의 패턴과 유사한 패턴이 나오게 된다.
즉 사진을 보든, 소리를 듣던, 비슷한 뇌의 활성화 정도를 갖는 것이다.
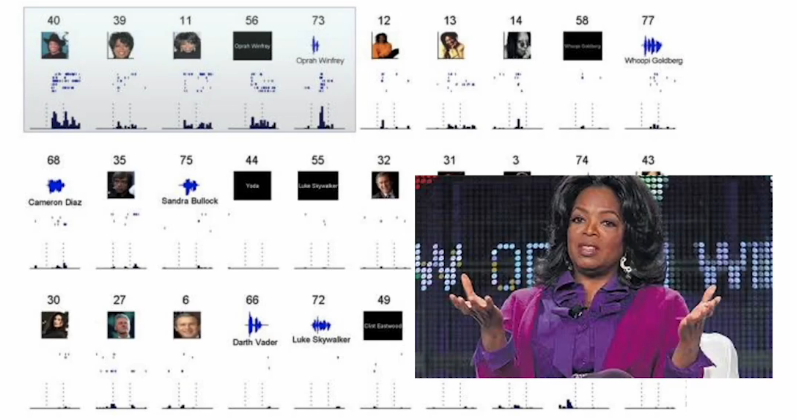
오프라 윈프리 예시
오프라 윈프리를 알고 있는 사람들에게 오프라 윈프리 사진을 보여줬을 때 그 때의 어떤 특정 뉴런이 activation이 된다.
다른 사람들의 사진들을 보여줬을 때 보다 같은 윈프리 사진을 보여줬을 때 특정 뉴런이 활성화 된다.
이 때 흥미로운 점은 오프라 윈프리 사진 뿐만 아니라 글자,소리로 주어졌을 때도 같은 뉴런이 활설화 된 것을 알 수 있다.
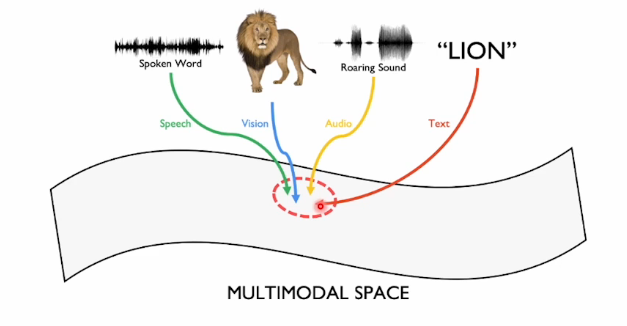
이걸 토대로 봤을 때 우리의 뇌는 모달리티에 상관없이 어떤 concept이 있을 때 그 컨셉을 학습하고 각각의 모달리티 정보들을(소리, 이미지, 텍스트 등) 하나의 concept space에 매핑하여 공통된 컨셉을 학습한다.
뉴럴 네트워크를 멀티모달 형태로 만들 때에도 이 방식을 적용하게 된다.
Multi-modal data
image data
이미지는 우리가 배웠듯이 행렬구조로 되어 있다.
RGB색을 나타내야 하기 때문에 3차원!

video data
이미지를 스택한 구조인데 color 축 뿐만 아니라 시간 축도 있어서 4차원 구조를 갖는다.
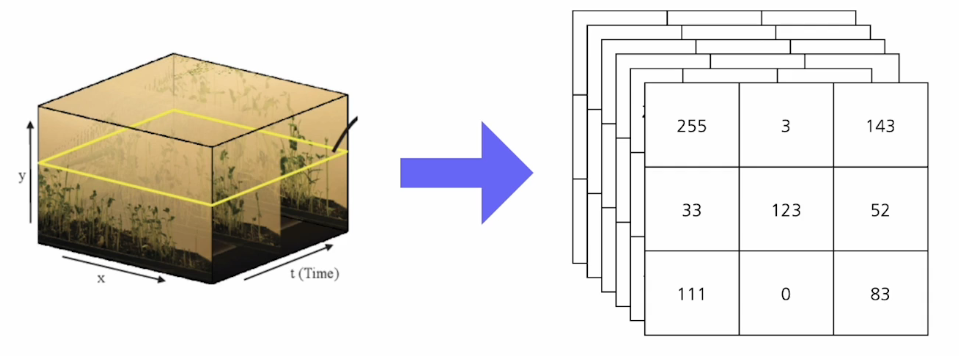
3D data
이미지와 비디오 구조와 다르게 되게 많은 데이터 표현 방법이 있다.
가장 흔한 표현 방법은 Mesh구조이다.
이 Mesh들은 각각의 vertex 포인트 형태로 이루어져 있고, vertex들이 선으로 이어진 형태로 vertex와 vertex를 포함하는 surface로 이루어졌다.
그 외에도 다양한 각도에서 정보를 모두 기록해서 3D화 하거나 Mesh구조를 파트별로 나눠서 파트별로 3D를 구성하는 것도 있다.
또는 특이하게 function을 정해서 그안에 3D 정보를 다 넣어 위치 값을 넣었을 때 안쪽이면 음수 바깥 쪽이면 양수가 나오는 식이다.

Text data
텍스트는 a,b,c,d 처럼 character로 모델링을 하면 철자별로 존재하게 되고 단어 내에서의 관계성을 파악하기 힘들다.
그래서 보통은 토큰,서브워드 단위로 구성한다.
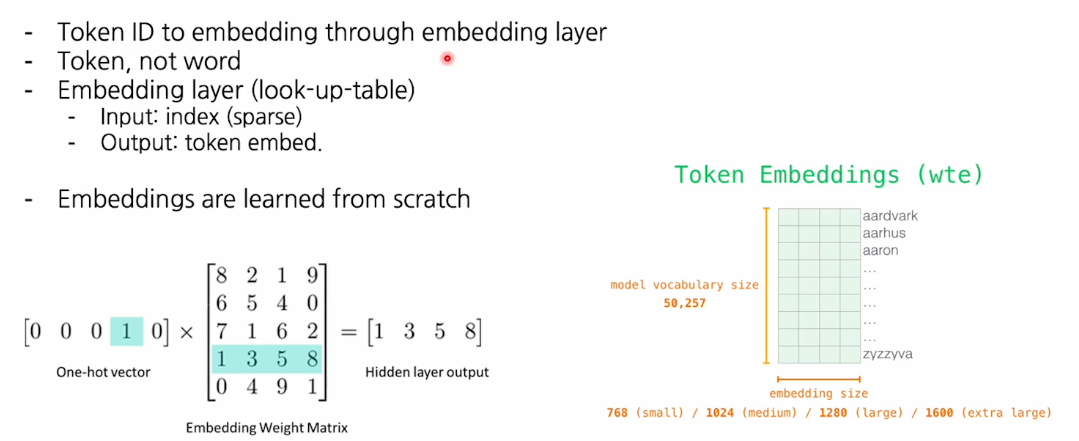
토큰(단어)하나마다 dense vector를 정의해서 assing한 데이터 구조를 갖게 되는데 이것을 word embedding이라고 한다.

워드 임베딩을 정의하기 위해서는 토큰이라는 단위가 필요한데 토큰은 단어가 될 수 있고, 서브워드가 될 수 있다. (최근에 서브워드를 많이 사용)
미리 토큰나이저를 정의를 해서 문장을 잘게 쪼개는 것을 tokenization이라고 한다.
서브워드마다 하나의 인덱스 값을 매핑하는데 이 인덱스 값은 추후에 워드 임베딩 벡터와 연결되어 있다.
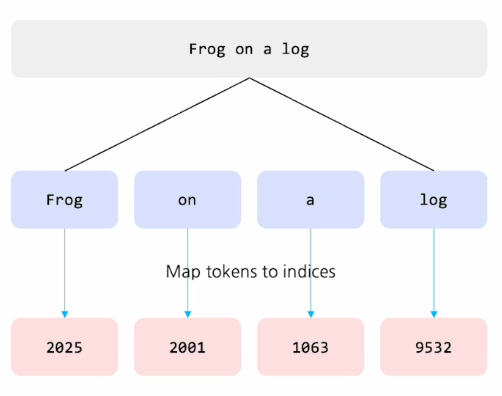
이렇게 input index가 주어지면 그것에 맞는 token embedding vector가 나온다.
Word2Vec
고정적으로 사용되던 embedding layer를 학습하는 방법에는 word2vec이 있다.
이 방법은 하나의 원핫 벡터가 들어왔을 때
embedding layer를 배치하고 거기서 특정 embedding vector가 출력이 되었을 때 그걸 decoding하는 또다른 weight를 설정을 해서 이 하나의 단어와 앞 과 뒤에 올 단어를 예측하는 self-supervised learning을 통해 embedding vector를 학습시키는 것이다.
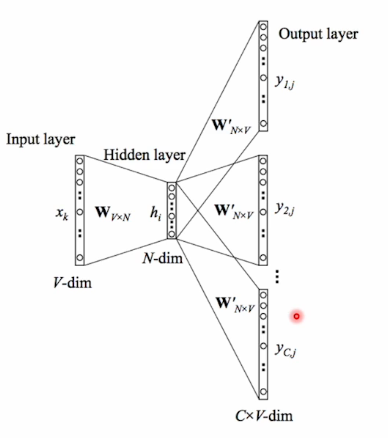
그래서 데이터가 주어지면 sliding widow 방식으로 들어가고 'the'라는 input이 주어지면 뒤에 있는 단어까지 estimation하는 형태로 train을 구성해 학습한다.
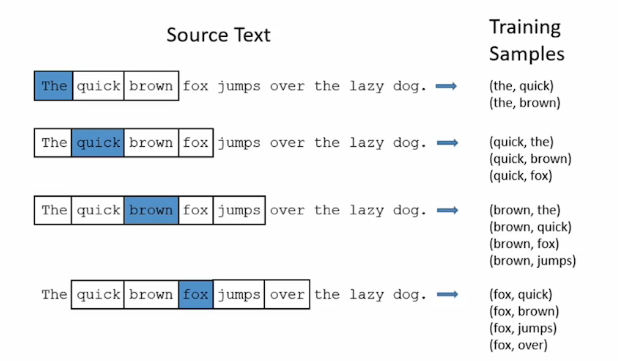
이런식으로 학습하면 학습된 feature vector의 표현이 굉장히 일반화된 성능을 갖는다.
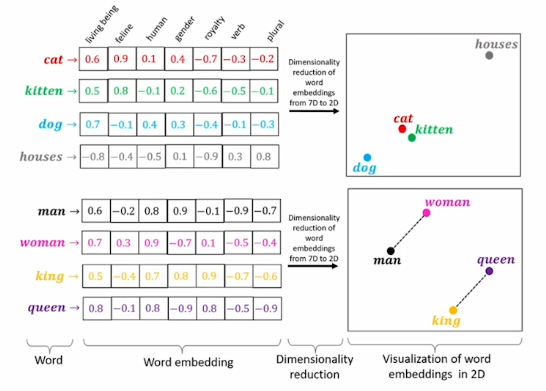
관계성을 학습했기 때문에 우리가 유도하지 않더라도 이들 사이의 sematic한 관계가 발현된다.
아래의 그림을 보면 의미가 비슷한 것끼리 묶이는 것을 볼 수 있고 남녀 관계성으로 man woman,king queen 사이의 거리가 같다는 것을 알 수 있다.
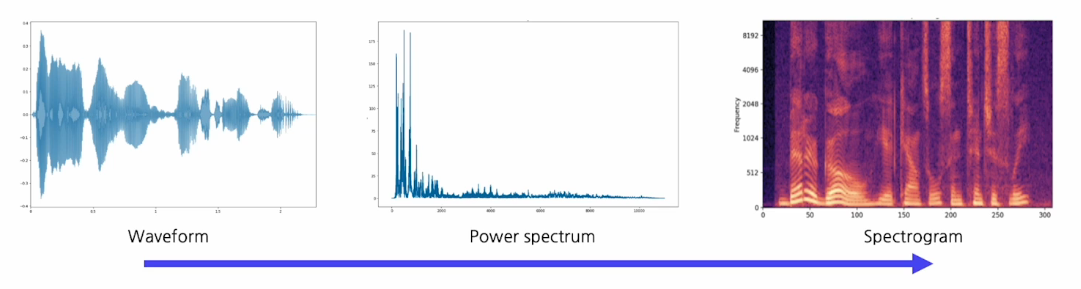
Sound data
sound data도 여러가지 표현이 있는데 1-D표현이나 스펙토그램으로 표현한다. 요즘에는 주로 스팩토그램을 많이 사용한다.
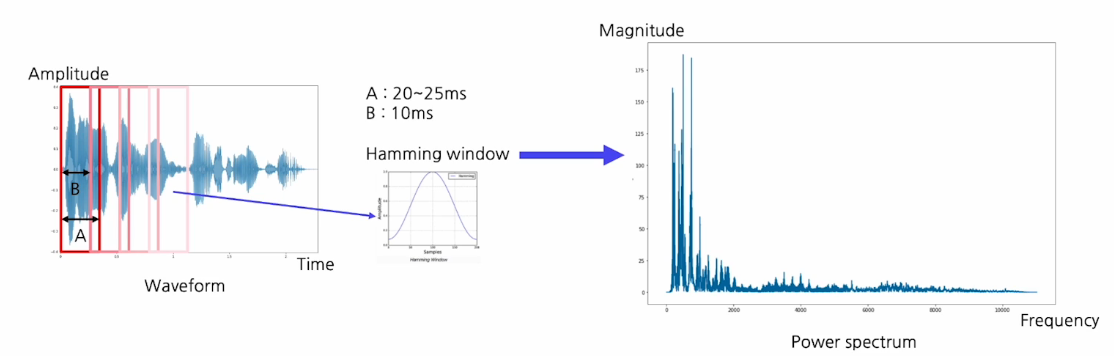
Fourier transform
1-D waveform을 스팩트로그램으로 바꾸기 위해서는 주파수 분석이 필요한데 Fourier transform을 사용한다.
푸리에 변환을 하고 나면 아래의 오른쪽 그래프와 같이 각 주파수의 성분이 얼마나 들어 있는지를 보여준다.(입력이 시간에 따라 흘러도 시간에 대한 정보가 사라짐)
그래서 시간의 정보를 유지하기 위해 input을 단위시간으로 짜르고(위도우 윙) 위도우 끝 쪽에 damage를 완화하기 위해 hamming window방식으로 waiting을 해서 가운데를 중점적으로 살펴보게 한다.
시간축의 신호가 들어오면 여러개의 sin(or cos) form을 두고 하나씩 내적하여 각 sin wave form이 얼만큼 들어 있는지 측정한다.
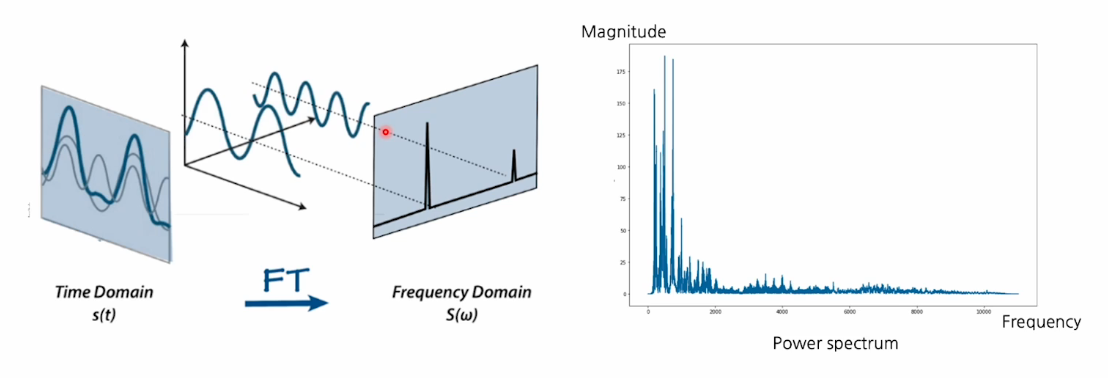
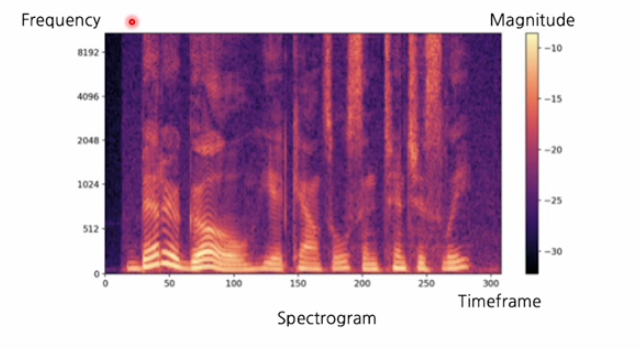
이번에는 위도우 단위로 모두 적용하여 x축은 시간 y축은 주파수 성분 색상은 각 주파수가 얼마나 있는지를 나타낸다. 시간에 따라서 waveform의 지분이 어떻게 생겼는지, 주파수의 특성을 분석 할 수 있다.
아래의 스펙트로그램을 보면 이미지와 굉장히 유사한 특성을 갖고 있다.
그래서 스팩트로그램이 2-D data로 표현된 특징을 이용해서
convolutional neural network와 같이 이미지에 적용하는 모델을 '
스펙트로그램에도 적용하는 모델링이 많다!
Mulit modal alignment
Joint embedding
Mulit modal alignment 다른 말로 joint embedding을 학습한다고 하기도 한다.
이 joint embedding을 학습하는 이유는 서로 다른 모달리티를 동일한 feature vector space상으로 옮겨서 매칭이 가능하도록 만드는데 강점이 있기 때문이다.
joint embedding을 학습하면 이미지 태깅이라던지, 이미지 retrieval를 수행할 수 있다.
-
이미지 tagging
예를 들어서 이미지가 feature vector로 변환되었을 때, 그것과 연관이 있는 text를 서로 매칭할 수 있는 embedding space가 존재하면 image feature vector를 통해서 이미지가 주어졌을 때 어떤 task tag가 어울리는지를 추천해주는 시스템 -
이미지 retrieval
text가 주어졌을 때 그것에 해당하는 이미지를 찾아주는 시스템

CLIP
multi modal alignment를 가장 foundation level로 잘 구현한 모델이 CLIP이다.
우리가 영상인식을 만들고 했을 때 이 영상 인식을 가장 간단하고 이상적으로 만드는 방법이 무엇일까?
이 세상에 있는 모든 데이터를 우리가 다 기억하고 데이터베이스화 할 수 있다면 새롭게 얻은 데이터도 과거의 데이터와 비교했을 때 적어도 하나는 유사할 것이다.
그래서 우리는 classificatino문제가 아닌 serach 문제가 될 것이다.
하지만 이렇게 저장할 수 있는 공간이 없겠지!
그래서 이것을 효율적으로 만들기 위해서 모든 데이터를 compress해서 간단한 모델로 모델화 하는게 머신러닝의 핵심이자 목표이다.
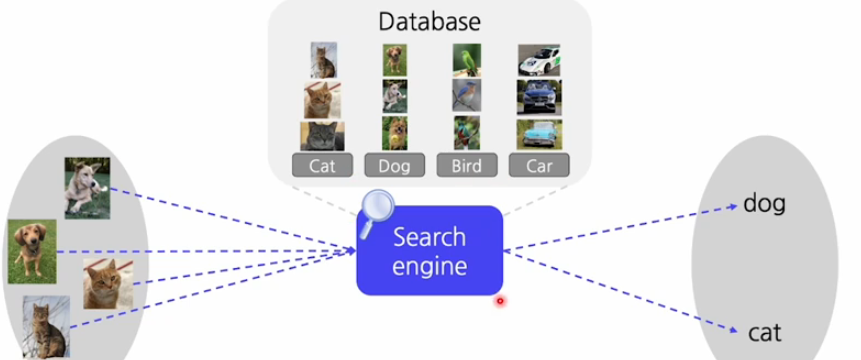
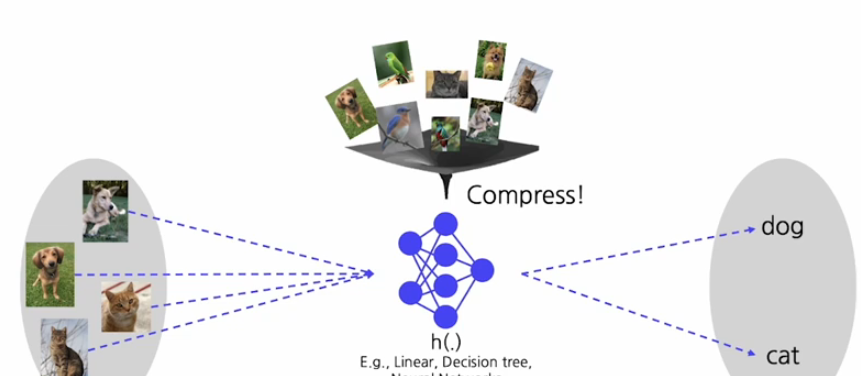
CLIP의 구조
위와 같은 영상인식기의 구조를 retrieval system처럼 만드는 구조로 생각해볼 수 있다. 그러면은 우리가 text encoder와 image encoder를 두고 개네들 각각을 feature embedding으로 바꾸어 준다. 그 두개를 비교대조화 할 수 있다면 우리가 간단하게 각 text에 대해서 이미지를 검색하고 각 이미지에 대해서 text를 검색할 수 있다.
만약 우리가 만개의 클래스를 미리 정의했다면 feature를 미리 뽑아 두고 , 이미지가 새로 주어졌을 때 그 이미지 feature를 만개의 text embedding과 비교를 하기만 하면 영상인식기를 쉽게 만들 수 있다.
이런 구조를 갖는 것이 CLIP이다.!(Contrastive Language-Image Pre-training)
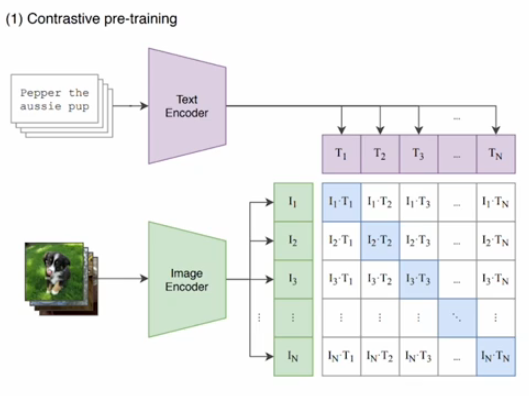
CLIP이라는 방법은 어떤 visual concept을 natural language를 이용을 해서 language와 image가 페어가 되있으면 이 두개의 관계를 joint embedding을 학습함으로써 관계를 학습한다.
그래서 text 모델과 image모델을 foundation level로 만들기 위해서 정말 다양한 텍스트와 이미지 데이터 pair를 인터넷에서 크롤링을 해서 데이터를 구축하였다.
이때 architecture는
text encoder는 Transformer를 이용하여 학습 진행
image encoder는 VIT나 Convolution neural network를 사용하여 학습 진행한다.
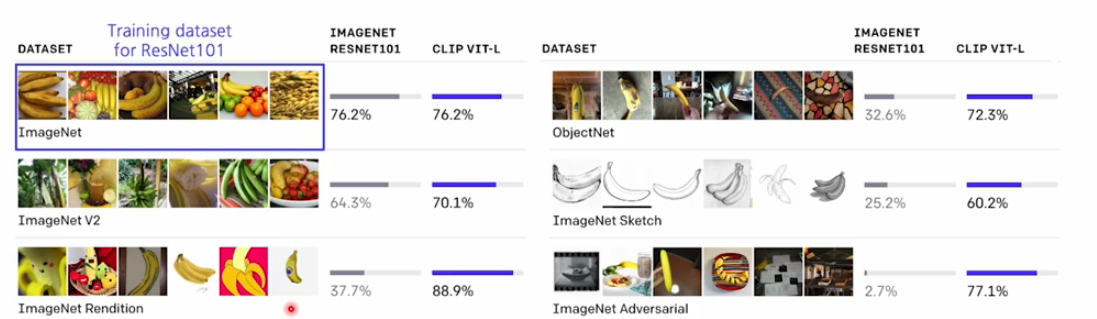
CLIP의 성능
학습된 CLIP은 흥미롭게도 domain이 다른 데이터에 대해서도
다른 training을 거치지 않고 많은 데이터로 학습 되어 있던 그 모델을
바로 사용하더라도 zero-shot으로 좋은 성능을 낸다.
(imagenet을 학습한 resnet은 다른 도메인의 데이터 셋에서는 성능이 크게 하락한다.)
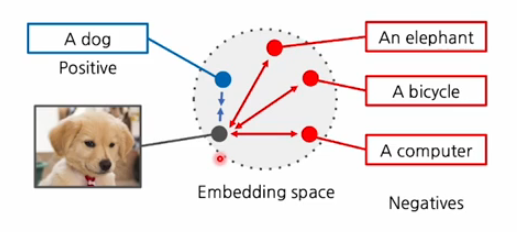
Contrastive Learning
CLIP 모델은 굉장히 많은 데이터를 사용하지만 사용하는 loss는 Contrastive Learning을 사용한다.
Contrastive Learning은 이미지가 주어졌을 때, 그거에 대응하는 텍스트에 대해서는 feature를 서로 당기고 서로 매칭 되지 않는 feature에 대해서는 서로 멀게 하는 형태로 학습하는 것을 의미한다.
좀 더 자세하게 설명하면 N개의 image와 text pair가 주어졌다고 가정하면 각각 encoder를 통해서 image embedding과 text embedding으로 변환하고 이들 사이의 각각의 cosine similarity를 측정해서 NxN matrix를 구성한다.
이 때 서로 pair인 것은 maximize하고 pair가 아닌 negative한 곳은 minimize한다.
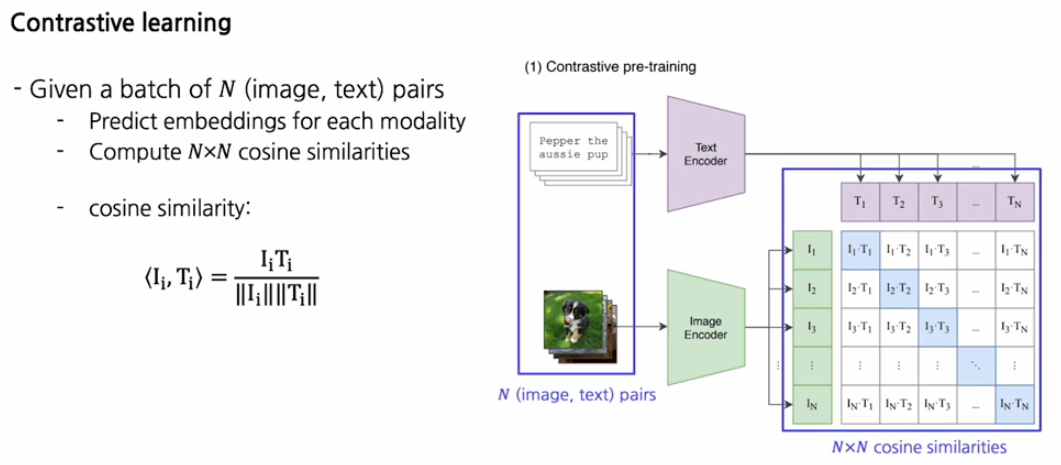
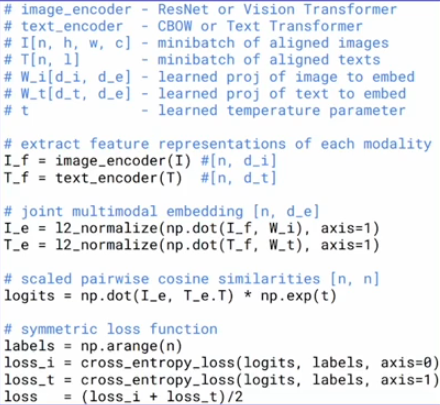
코드로 보면 이미지와 텍스트를 인코더로 넣고 normalize해준뒤,
내적을 해서 cosine similarity를 구하고 그 유사도를 cross_entropy_loss 사용해서 최종적인 loss를 최소화하는 방향으로 학습한다.
하나의 특징은 유사도를 구할 때 np.exp(t)를 통해서 cross_entropy_loss를 어느정도 민감하게 사용할 것인지 정하는 중요한 파라미터로 사용된다.
CLIP의 사용
이미지 텍스트 사이에 retrieval과 tagging을 할 뿐만 아니라 굉장히 다양한 곳에서 사용된다.
image captioning,video retrieval,text-to-image generation,motion generation,3d generation까지도 폭넓은 application에서 사용할 수 있다.
pretrained 된 CLIP을 사용할 수 있는 application에 대해 알아보자
ZeroCap
ZeroCap에서는 pretrained된 CLIP과 large language model인 (GPT-2)를 이용을 해서 또다른 훈련을 하지 않고 하나의 샘플에 대해서 최적화 하는 것만으로 caption을 찾아낸다.
기존의 image caption 모델 같은 경우는 이미지와 caption pair를 두고 학습하기 때문에 일반적인 것만 학습했었다. 예를 들어서 트럼프 대통령 사진이 있으면 어떤 남자가 사진을 찍고 있다 정도만 알 수 있었다.
CLIP이 인터넷에 정말 많은 데이터를 보고 학습이 되었고, language모델도 자체적으로 가지고 있는 언어적인 데이터가 많기 때문에 이 2개를 이용해 caption을 하면 트럼프 대통령임을 알고 있을 만큼 사전지식이 많다.

ZeroCap의 설계
설계를 설명하기 전에 background 지식으로 GPT-2가 어떻게 구성 되었는지 알아보자.
GPT-2에다가 input으로 image of a xxx를 넣으면 앞에 있는 image of a는 prepix라고 하고 이 prepix가 들어갔을 때 autoregressive한 형태로써 출력이 나오면 그것이 다음 input으로 들어가는 형태이다.
그때 미리 뽑아놓은 feature들을 context라고 부른다. context가 주어졌을 때 새로운 token이 들어오면 self-attention을 측정해 최종적인 출력을 만든다.
이때 context는 학습가능한 파라미터로 사용한다.
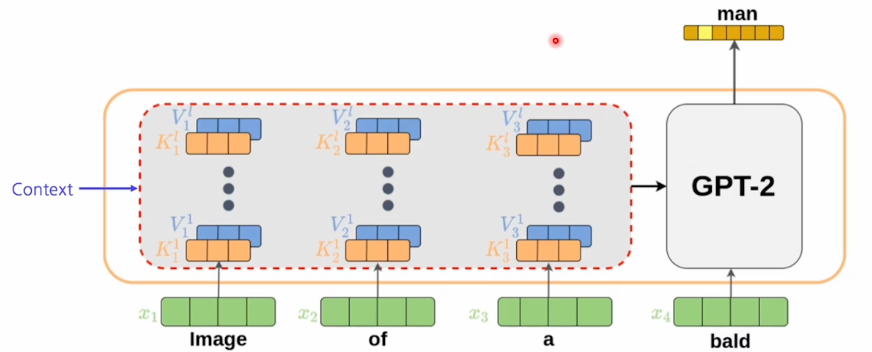
진행 과정
-
위와 같은 language 모델을 배치한 후 image of a를 넣고 그다음에 다음 단어 'bald'를 입력으로 넣는다.
-
그 다음에 이 bald라는 단어의 다음 단어를 예측하기 위해서 출력된 확률을 체크하고 출력된 단어들과 전체적인 문장 구성을 CLIP을 이용해서 embedding한다.
-
그 후에 이 단어의 이미지 출력과 실제 이미지의 align이 잘 맞는지를 확인하기 위해 CLIP loss를 사용한다.
-
이미지를 CLIP encoder에 넣고 visual feature를 뽑은 다음에 그 feature를 고정시킨뒤 gpt-2에서 출력된 text를 CLIP text encoder에 넣고 visual feature와 비교한다.
-
그 두개가 차이가 있다면 backpropagation을 통해 image of a와 같은 context feature들을 업데이트한다.
이걸 통해서 language 모델이 language에 대한 사전 지식을 가지고서
다음 단어를 예측할 수 있는 형태로 그리고 그 단어가 CLIP에서 뽑은 visual feature와 align이 잘 되도록 학습이 진행된다.
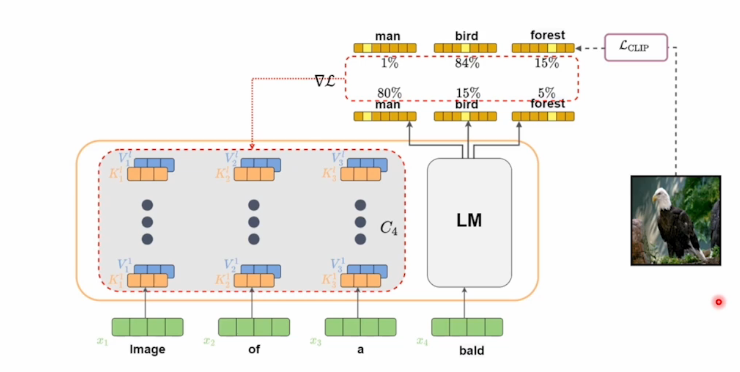
즉 language model이나 CLIP 자체를 업데이트 하지 않고 context feature만 업데이트하는 식으로 하나의 이미지에 대해서만 최적화되게 동작한다.
이렇게 업데이트를 하고 나면 bird에 대한 확률이 올라가게 되고 이 새라는 단어가 나오는 것을 이용해 다음 단어의 입력으로 넣어주게 되고 그 다음을 예측하며 한단계 한단계 업데이트를 진행한다.
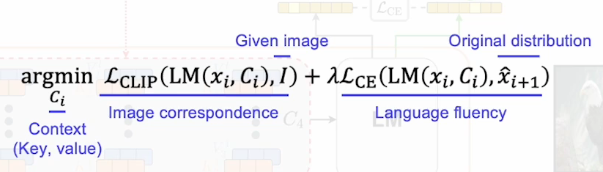
loss
다음 단어를 예측할 때 기존의 출력되고 있던 그런 vector들이 변화하지 않도록 유지하는 cross-entropy loss를 추가를 해준다.
loss는 language를 유창하게 할 수 있는 loss와 CLIP을 이용해서 image와 출력된 text간의 alignment를 잘 맞추는 loss를 구성해서 context를 업데이트 한다.
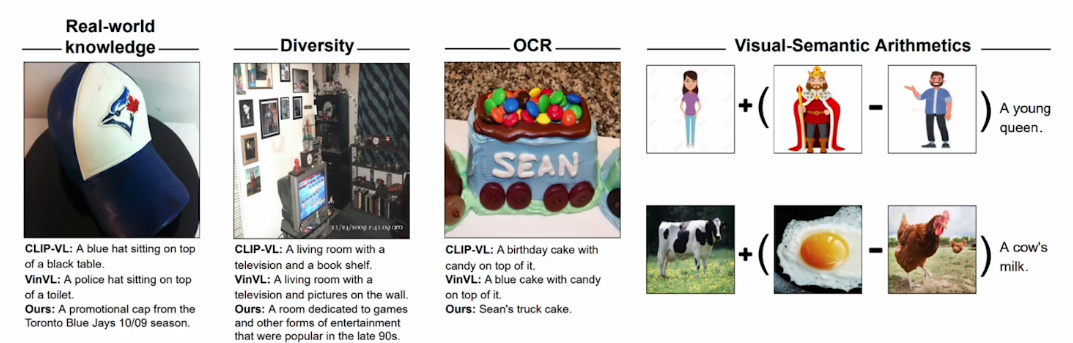
ZeroShot 결과
왼쪽에 야구모자를 보게 되면 다른 모델들은 그냥 모자라고 설명하지만 우리의 ZeroCap을 ZeroShot하면 어느 야구팀인지 언제 나온건지도 알 수 있다.
StyleCLIP
ZeroCAP에서는 language 모델을 text에 대한 prior로써 사용하고 text를 optimization하는 방법으로 caption을 하였다.
이번에는 반대로 text를 고정하고 image를 optimization하는 방법으로 응용할 수 있다는 것을 보여주겠다.
대표적인 예가 StyleCLIP이다.
StyleCLIP은 GAN 구조를 이용해서 image를 생성할 때 우리가 text를 주고서는 image를 추가하는 applicaiton이다.
CLIP을 이용하기 때문에 natural language를 주고 어떤 text든지 visual concept을 바로 전달할 수 있다.
미리 pre-fined된 몇가지 prepix prompt를 사용하지 않고 자연스러운 단어들을 넣어주면 이해하고 이미지에 반영해준다.

StyleCLIP의 구성
미리 pretrained 되어 있는 styleGAN(이미지 생성모델)이 있고,
이미지를 입력으로 받고 mapping network를 통해 conditional vector로 converting을 한후
이 conditional vector를 기반으로 이미지를 생성하는 것이다.
Suprised라는 단어를 넣어주면 단어에 맞겠끔 조작된 이미지가 생성될 수 있도록 하는게 style CLIP이다!!!
Suprised라는 단어와 일치하는 형태의 이미지를 유도하기 위해서
CLIP loss를 적용하게 되는데
suprised라는 text를 CLIP text encoder에 넣고 feature vector를 미리 뽑는다.
이 text feature와 styleGAN에서 생성된 이미지에서 나온 visual feature하고의 거리를 계산한다.(그때 거리는 cosine distance를 사용)
이 loss를 통해 역전파를 한다.
두번째 loss로써 identity를 그대로 유지할 수 있는 identity loss를 적용한다.그래서 원본과 출력된 이미지 사이에서의 사람의 identitiy를 바뀌지 않도록 한다.
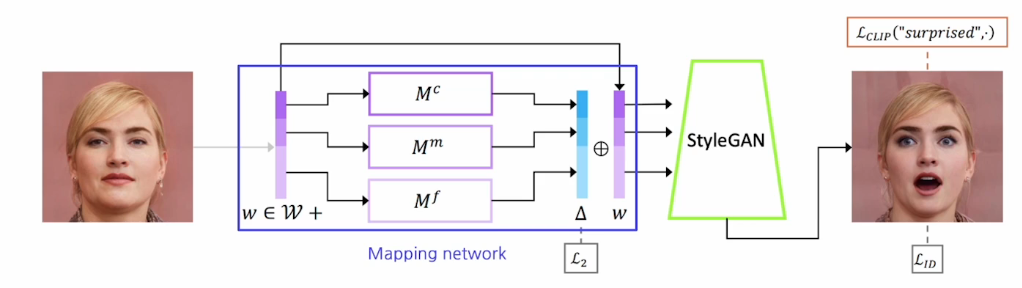
그리고 마지막으로 mapping network에서 conditional vector(w)를 추출해주는데 이 vector는 고정해놓고 resdiaul part(L2)를 배치해놓는다.
이 part를 학습 가능하게 하고 마치 ZeroCap에서의 context vector처럼 residual part부분을 최종적으로 역전파해서 학습한다.
이것도 마찬가지로 CLIP이나 StyleGAN의 구조는 건들지 않고 에서 loss를 measure한 것들이 역전파 되어서 residual vector하나만 학습이 되도록 하는 것이다!
StyleCLIP의 결과
주어진 샘플과 텍스트 pair에 대해서 굉장히 구체적이고 최적화하게 해서 image를 stylization을 해준다.
예를 들어서 여자 배우가 input으로 들어오면 겨울왕국의 엘사처럼 변경할 수 있고, 디카프리오를 트럼프화 시킬수도 있다.(사람의 얼굴 뿐만 아니라 자동차,동물도 가능하다.)

3D avartar(with pre-trained CLIP)
위의 ZeroCAP과 StyleCLIP의 장점은 학습을 추가적으로 하지 않고, text와 이미지 pair 데이터가 따로 존재하지 않아도 추가적인 데이터 없이 각 샘플들이 주어진 순간에 zero shot으로 결과를 생성할 수 있다는 장점이 있었다.
이 장점을 확장해서 3D에도 적용할 수 있다.
CLIP 같은 경우는 이미지와 text의 alignment를 측정하는 형태로만 학습되어 있어 이미지가 input으로 주어져야 한다.
하지만 3D는 이미지 형태로 되어 있지 않아 random 테크닉을 사용해야 한다. 그래서 미분가능한 랜더링을 사용해서 이미지로 converting한 다음에 CLIP에다 입력으로 넣어 주어 alignment를 측정하는 loss를 만들고 역전파가 가능하게 한다.
그래서 이 방법에서는 text가 주어졌을 때 생성된 중간 단계의 3d를 랜더링해서 역전파 흐름을 만들어 주고 texture를 최적화 할 수 있는 parameterization을 둠으로써 styleCLIP과 비슷한 방식으로 최적화 하여 4D 아바타를 생성한다.
2022년에는 캡틴 아메리카 라는 text가 주어지면 CLIP만 사용하여 그럴듯한 texture를 얻었지만 현재는 추가적인 몇가지 리터치를 통해 좋은 퀄리티의 texture를 보여준다.

ImageBIND
지금까지 CLIP의 굉장히 파워풀한 성능에 대해서 확인을 하고 다양한 잠재적인 가능성에 대해서 살펴봤는데 CLIP은 단순히 text와 image관계만 학습함으로써 그 둘이 어느정도 align이 되었는지 아닌지를 평가했을 때 다양한 application을 만들 수 있었다.
그렇다면 만약에 우리가 text,image뿐만 아니라 depth,다른 센서들에 대해서도 관계성을 파악할 수 있고, align할 수 있다면 좋겠다!!
그런 시도를 한 것이 ImageBIND이다!
ImageBIND 같은 경우에 하나의 joint embedding space를 만드는데 거기다 video,audio,image,text,depth,열화상,특수한 센서등에 대한 모든 feature들을 하나의 space에 다 올려놓는 시도를 한다.

ImageBIND
ImageBIND는 text와 image가 잘 align된 space를 가지고 나서 다른 모달리티에 대한 feature mapping들을 별도로 학습하는 형태로 진행이 된다.
나머지 부분은 CLIP과 굉장히 유사한 형태로 이루어져 있다.
loss function은 마찬가지로 contrast learning을 수행하는데 좀더 강력한 InfoNCE loss를 사용한다.
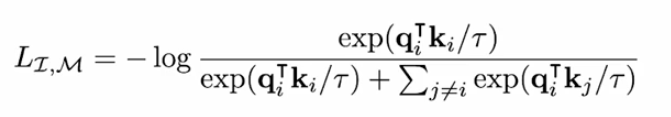
응용
이렇게 학습된 imageBIND모델을 통해서 오디오가 주어졌을 때 이미지가 비디오를 검색을 하거나 , Depth가 주어졌을 때 text를 검색할 수 있다.
그리고 이미지와 소리를 합쳐서 이미지를 stylization하거나 소리로 부터 이미지를 생성하는 응용도 만들 수가 있다.
또한 오디오에서 나는 소리에 해당되는 부분을 segmentation할 수 도 있다.
Cross-modal Translation
지금까지 visual data와 text data를 하나의 space에 올려놓고 활용할 수 있는 alignment modeling에 대해 살펴봤다.
지금 배우게 될 Cross-modal Translation은 멀티 모달 task에서 주로 디자인 하는 패턴이다.
Cross-modal Translation은 하나의 모달리티에서 부터 다른 모달리티로 번역을 하는 형태의 application이다.
예를 들면 text가 주어지면 이미지를 생성하거나 소리가 주어졌을 때 그거에 대한 captioning을 하거나
이렇게 input과 output의 모달리티가 변환되는 모델들을 전부 Cross-modal Translation라고 한다.
Text-to-image generation
가장 대표적인 cross-modal translation이다.
최근에 이미지 생성 모델의 발전으로 인해서 많은 사람들의 관심을 받고 있따.
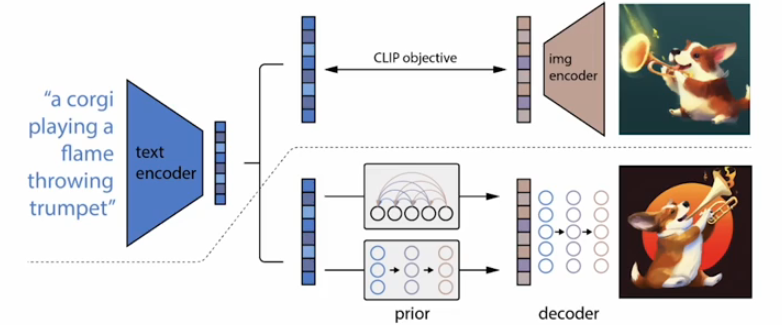
DALL-E2
지금은 3까지 나오고 좋은 모델들이 많지만 오늘은 DALL-E2를 배워보자
DALL-E는 CLIP과 diffusion 모델로 구성되어 있다.
CLIP을 먼저 학습해놓고 CLIP feature와 이미지를 생성하는 diffusion모델을 별도로 생성해서 연결하는 모듈방식으로 접근하였다.
Sound-to-image
text-to-image도 어렵지만 sound-to-image는 더 어렵다!!
소리의 데이터 구조와 이미지 구조가 다르기 때문이다
특히 이미지는 객체에 대한 정보가 분명한 반면에 소리같은 경우는 back ground 노이즈와 함께 섞여 구분하기 힘들다.
또한 outlier문제가 있는데 이미지 밖에서 소리가 나는 것이라 실제로 소리와 시각 이벤트의 연관성이 없는 경우가 많다.


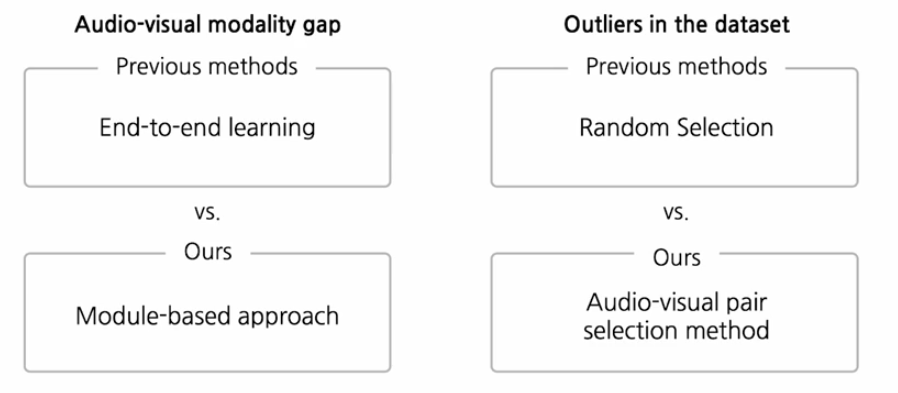
문제 해결방안
기존의 연구들은 end-to-end learning, random selection을 하는데
이태헌 교수님이 참여했던 연구에서는 end-to-end보다는 DALL-E처럼 모듈 base approach를 사용해서 개별적으로 학습해서 모달리티 갭 문제를 최대한 완화하려고 했고,
outlier문제에 대해서는 audio-visual pair에 대해서 조금더 적절한 선택을 하는 방법을 도입해서 outlier를 최대한 필터링 하였다.
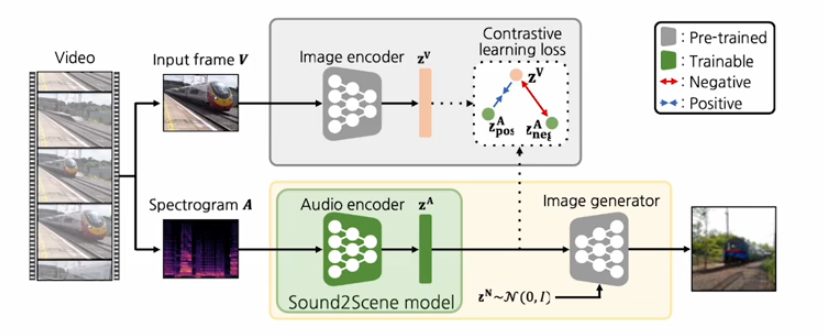
model based approach
전체전인 구조는 아래의 사진과 같다.
video에서 부터 input frame을 뽑고 그것에 해당하는 audio를 뽑아서 스펙토그램 형태로 가지고 있고,
image encoder,audio encoder,image generator 3개의 모듈을 구성해서 사용한다.
순서
1.
먼저 self-supervised learning나 pretrained된 모델을 이용해서 image encoder와 image generator를 먼저 학습한다.
(이때 image generator는 image encoder에서 들어오는 feature를 condition으로 받아서 autoencoding하는 형태로 학습을 진행하기 때문에 이미지 to 이미지라 학습이 더 잘된다)
그래서 첫번째 이 모듈 베이스 접근의 목적은 visual embedding scale를 강하게 만들고, 이미지 generator를 강하게 하는 것이다.
-
이렇게 학습된 이미지 인코더와 generator는 fix시켜놓는다. 더이상 훈련하지 않게 한다.
-
학습가능한 audio encoder를 도입한다. 그래서 소리가 들어왔을 때 feature를 뽑고 그 피쳐를 이미지 feature domain에 align시킨다.
이때 contrastive learning을 사용해서 학습한다.
이러면 오디오 인코더는 이미지 인코더의 행동을 따라하는 식으로 학습한다.
그래서 이미지 인코더가 visual space를 강하게 anchor를 잡고 있으면 audio가 주어졌을 때 audio feature가 align되면서 강한 visual feature에 잘 align되게 학습된다.
이렇게 하면 노이즈가 많이 낀 소리가 들어와도 그 내에서 최대한 visual feature와 연관된 부분들을 잘 extraction하는 강한 오디오 인코더가 학습이 될 것이다.
- 이렇게 학습한 오디오 인코더를 이미지 generator에 입력으로 넣어준다.
추가적인 학습없이 바로 연결할 수 있는 이유는 image encoder자체가 이미지 generator와 호환성이 있도록 학습이 되어 있고 오디오 encoder가 image encoder를 따라하도록 학습되었기 때문에 가능하다.
Speech-to-Face
사람의 목소리로부터 얼굴도 만들수 있지 않을까?라는 생각에서 나온 연구이다.
모델 디자인은 face recognition을 가지고 face feature를 뽑고
그거에 맞는 face encoder를 미리 학습한다.
pre-train되고 fix된 face encoder를 나두고 voice decoder부분만 별도로 학습한다.
이런 식으로 모달리티 gap을 중간에 끊어서 가면서 gap을 완화하는 형태를 가진다.
여기서 face decoder는 face를 굉장히 퀄리티 있게 생성할 수 있도록 face specific한 모델을 따로 학습을 한다.
face recognition 모델은 pretrain된 VGG-face model을 사용한다.
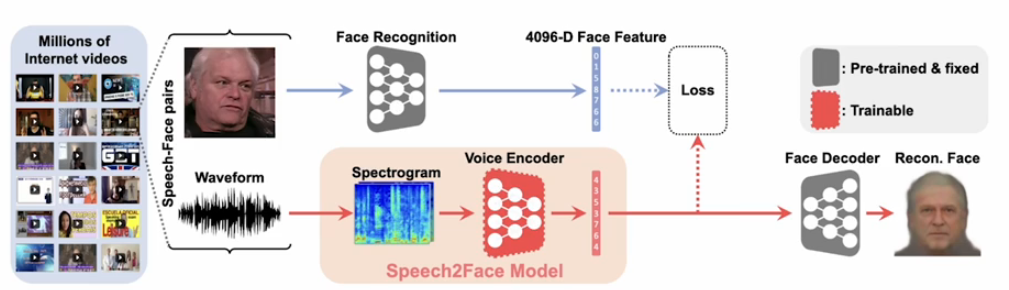
Image-to-Speech
이미지에서부터 스피치를 합성하는 cross-modal translation에서도 위와 같은 방법을 사용할 수 있다.
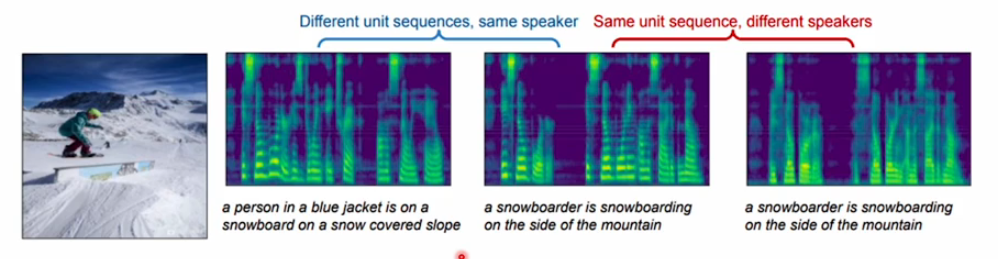
이미지로부터 스피치를 합성하는데 있어서
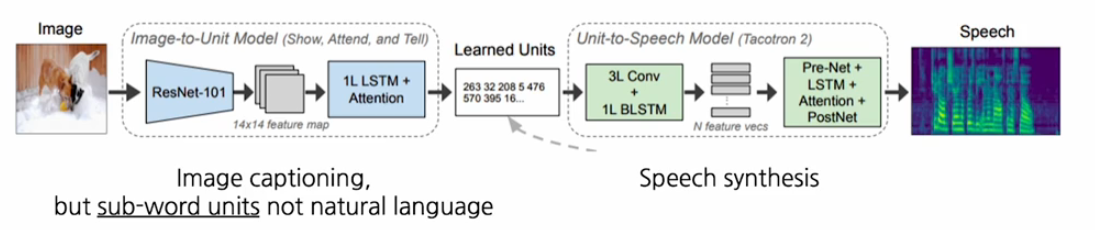
먼저 visual encoder를 사용하고 그다음에 먼저 speech decoder를 학습한다.
따로 학습된 speech decoder를 중간에 연결을 시켜줘서 바로 스피치를 생성할 수 있도록 만들어준다.
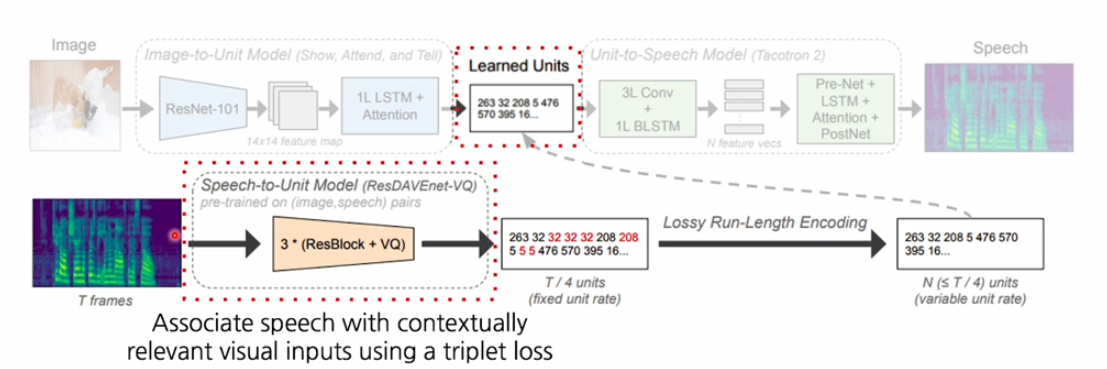
이때 스피치 encoder를 잘 학습하기 위해서 스피치에서부터 중간 feature로 바꾸고 그것을 다시 speech로 decoding하는 모듈을 먼저 학습하고 그 후에 이미지에서 부터 스피치를 브릿징하는 형태로 학습한다.
즉 module based approach와 유사하게 작동한다.
정리
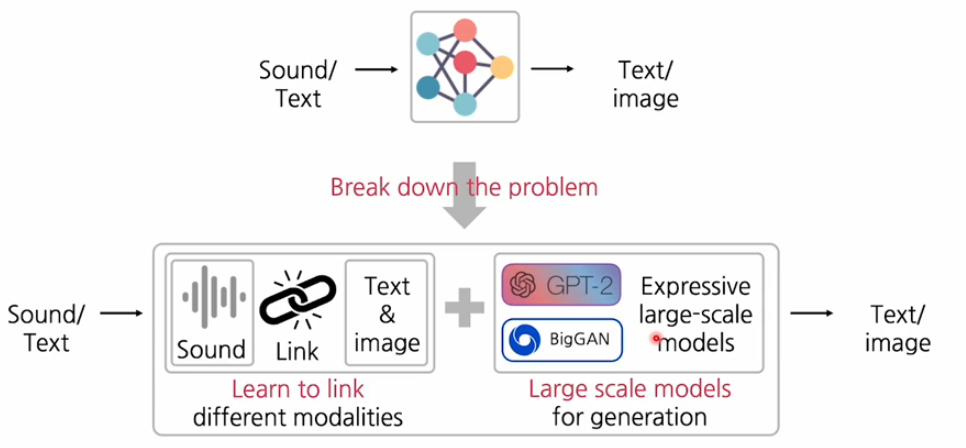
이렇게 여러가지 application을 통해서 cross-modal translation을 구현할 때 한번에 end-to-end로 구현하기 보다는 이 문제 자체가 어렵기 때문에 작은 문제로 break down하는 것이 핵심 포인트이다!~
그랬을 때 가장 핵심적인 방법은 strong한 decoder를 잘 학습해놓고 그 다음에 input 모달리티와 decoder사이의 연결부분을 브릿지 부분을 잘 학습하는 이런 module approach가 효과적이다.