모델관리
모델 관리가 왜 필요할까?
만약 우리가 집에서 요리한다고 했을 때 요리한 것들을 레시피로 정리해야 어떤 조합이 좋은지 알 수 있다.
(여러 시행착오를 겪으면서 요리를 하기 때문이다.)
그 레시피 중에서 젤 좋은 레시피를 레스토랑(실제 서비스)에서 사용될 것이다.
이처럼 우리 ai 모델도 가장 좋은 성능을 보인 것만 이용해서 서비스로 이용될 것이다.
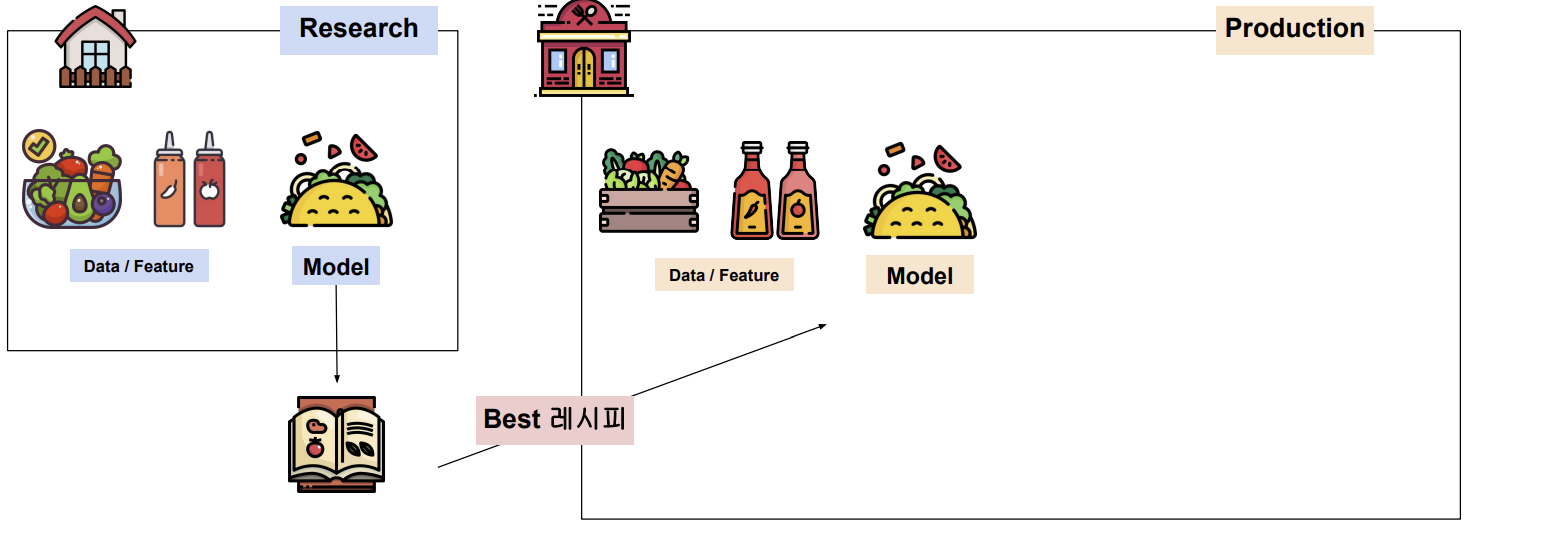
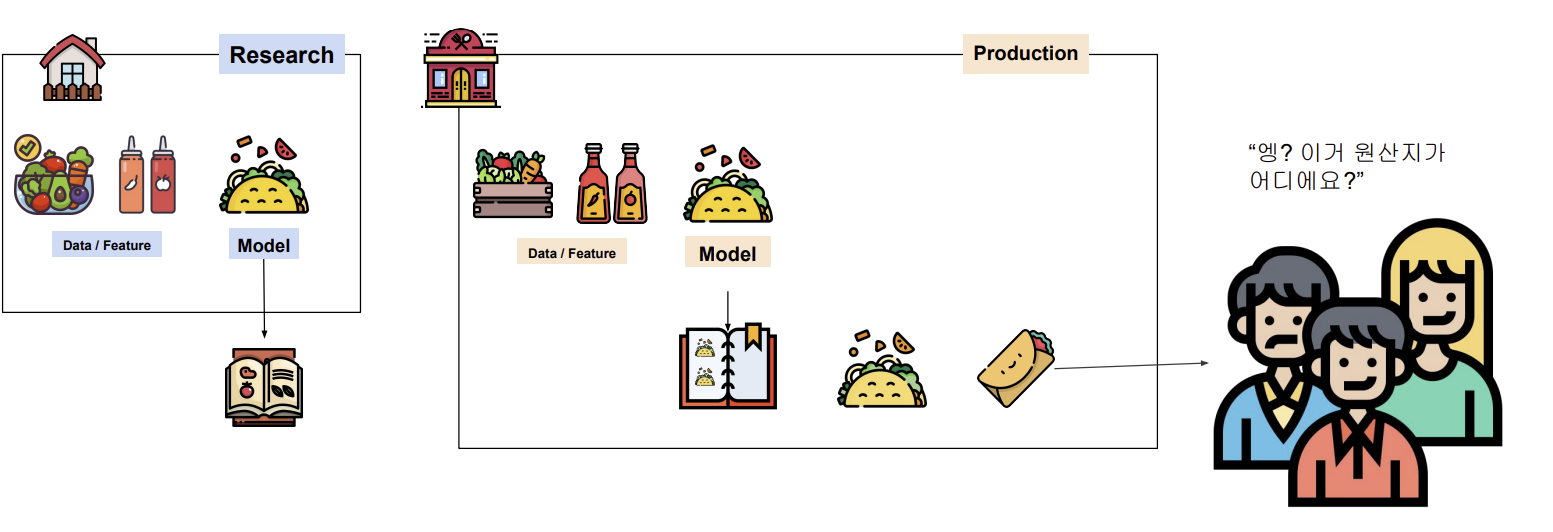
이 때 요리를 만드는 과정에서 부산물이 생길 수 있다.(모델 artifact, 이미지 등)
그것들을 잘 저장해야 되며,
모델을 만들때 다양한 종류의 모델이 있으므로, 언제 만든건지, 어떤 성능을 가지고 있는지, 모델 메타 정보등을 잘 기록해야 사용하는 사람도 제작 과정을 투명하게 알 수 있다.
모델과 관련된 관계자들도 모델이 잘 돌아가는지 잘 확인할 수 있을 것이다.
(또한 정해진 원칙들을 잘 준수하였는지 검사할 수 있다.)
모델 관리 기본
모델 관리에 있어서 3가지를 꼭 신경써야 된다.
-
모델 메타 데이터
모델 메타 데이터는 모델이 언제 만들어졌고, 어떤 데이터를 사용해서 만들어 졌는지를 저장한 데이터를 의미한다.이때 성능도 같이 저장한다.
-
모델 아티팩트
모델 아티팩트 = 모델의 학습된 결과물, 모델 파일(pickle,joblib 등) -
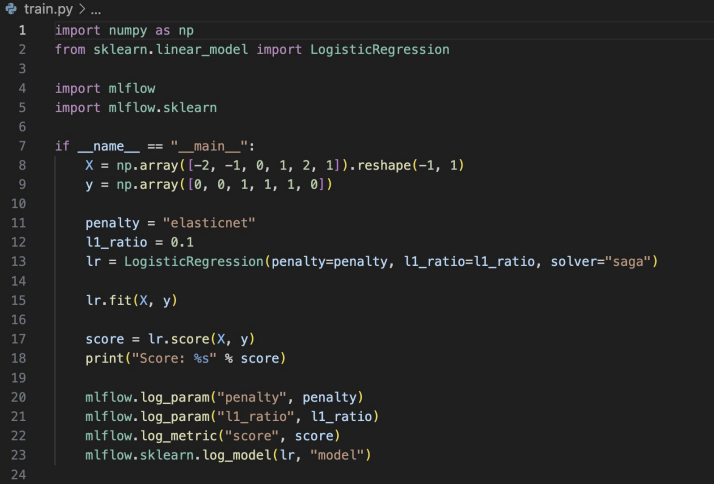
Feature/Data
모델을 위한 feature와 data이며, data도 버전에 따라 업데이트 될 수 있다.(레이블링 변경 등)
이런 관리를 유용하게 관리할 수 있게 도와주는 도구가 MLFlow이다.
MLFlow
오픈 소스 중에 유망한 도구이다!
이것와 견줄만한게 sas의 weight & bias 인데 유료이기 때문에 회사에서는 꺼려할 수 있다.(그래서 회사에서는 mlflow를 많이 사용한다.)

MLFlow의 핵심 기능
1) Experiment Management & Tracking
-
머신러닝 관련 “실험”들을 관리 하고, 각 실험의 내용들을 기록할 수 있다.
(예를 들어, 여러 사람이 하나의 MLflow 서버 위에서 각자 자기 실험을 만들고 공유할 수 있다.) -
실험을 정의하고, 실험을 실행할 수 있다. 이 실행은 머신 러닝 훈련 코드를 실행한 기록이다.
-
각 실행에 사용한 소스 코드, 하이퍼 파라미터, Metric, 부산물
(모델 Artifact, ChartImage)등을 저장
2) Model Registry
-
MLflow로 실행한 머신러닝 모델을 Model Registry(모델 저장소)에 등록할 수 있다.
-
모델 저장소에 모델이 저장될 때마다 해당 모델에 버전이 자동으로 올라간다. (Version 1 -> 2 -> 3..)
-
Model Registry에 등록된 모델은 다른 사람들에게 쉽게 공유 가능하고, 쉽게 활용할 수 있다.
3) Model Serving
-
Model Registry에 등록한 모델을 REST API형태의 서버로 Serving할 수 있다.
-
Input = Model의 Input
-
Output = Model의 Output
-
직접 Docker Image 만들지 않아도 생성할 수 있다.(아주 간단히)
mlflow는 모델 서빙보다는 model registry와 experiment관리에 사용하는것이 더 권장된다.
MLFlow의 핵심 요소
1) Tracking
- 머신러닝 코드 실행, 로깅을 위한 API
- 파라미터, 코드 버전, Metric, Artifact 로깅
- 웹 UI도 제공
- MLflow Tracking을 사용해 여러 실험 결과를 쉽게 기록하고 비교할 수 있음
- 팀에선 다른 사용자의 결과와 비교하며 협업
2) Model registry
-
모델 관리를 위한 체계적인 접근 방식을 제공
-
모델의 버전 관리
-
태그, 별칭 지정, 버저닝, 계보를 포함한 모델의 전체 수명 주기를 관리
3) Projects
-
머신러닝코드, Workflow, Artifact의 패키징을 표준화
-
재현이 가능하도록 관련된 내용을 모두 포함하는 개념
코드로 살펴보는 mlflow
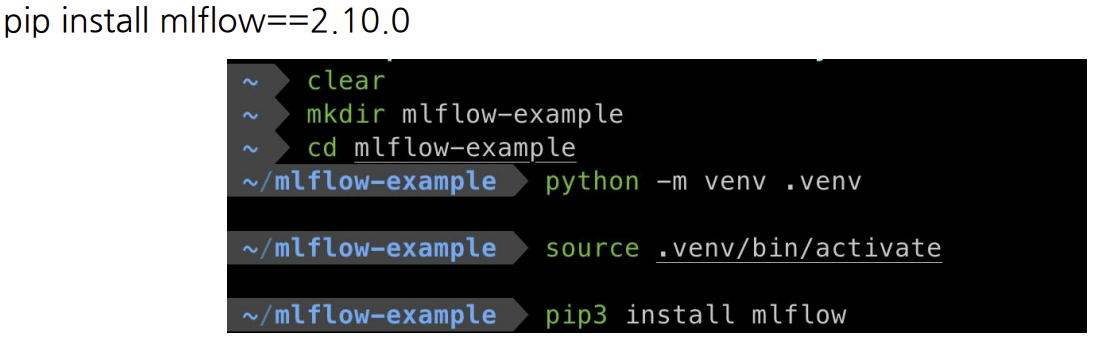
가상환경 생성 및 ml flow설치
mlflow ui 실행하기
mlflow server --host 127.0.0.1 --port 8080

localhost:8080으로 mlflow ui 접속하면 아래와 같은 화면이 뜬다.
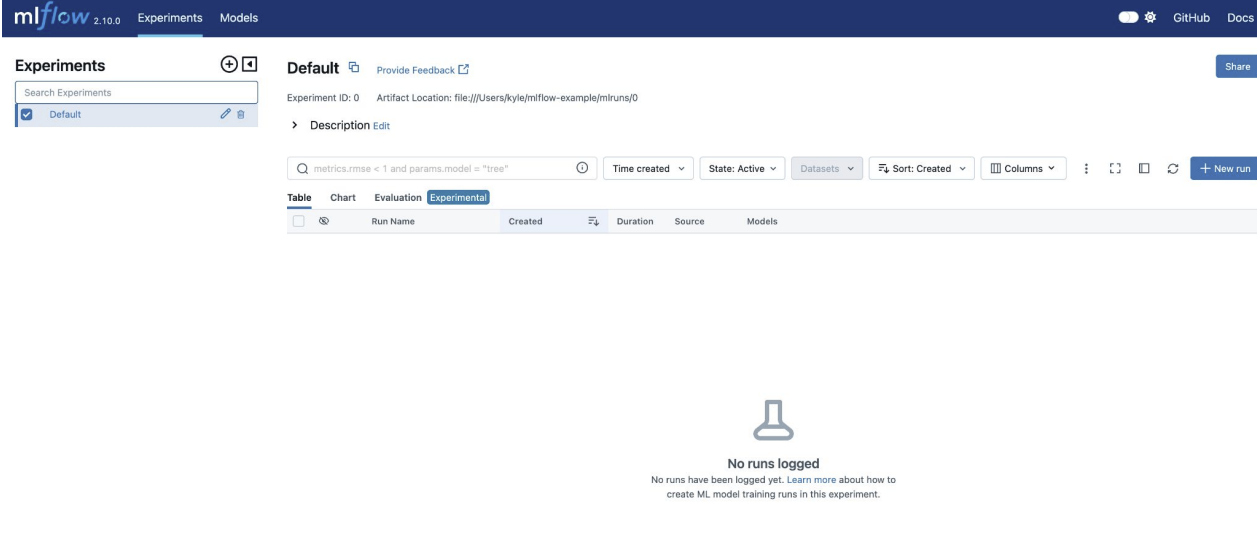
실험 생성
mlflow에서 제일 먼저 실험을 생성해야 한다.
하나의 Experiment는 진행하고 있는 머신러닝 프로젝트 단위로 구성
예) “개/고양이 이미지 분류 실험”, “택시 수요량 예측 분류 실험”
정해진 Metric으로 모델을 평가 예) RMSE, MSE, MAE, Accuracy
하나의 Experiment는 여러 Run(실행)을 가짐

ls-al를 사용해 폴더 확인하면 mlruns라는 폴더가 생김
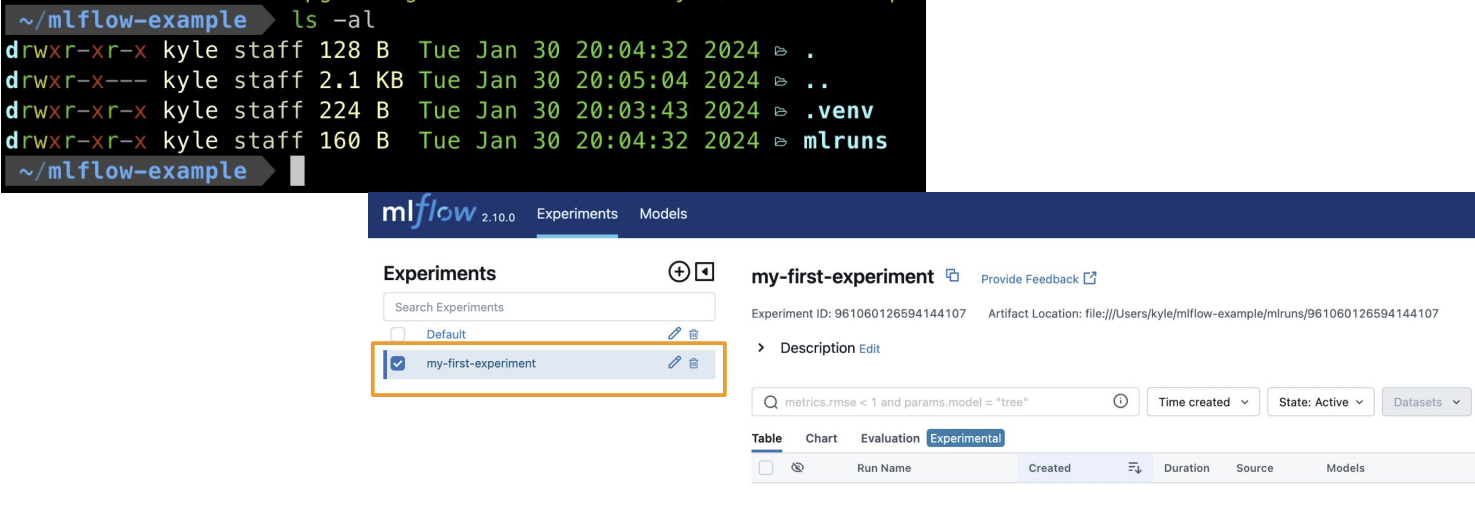
Experiment 리스트 확인
mlflow experiments search를 통해 확인할 수 있다.

모델에 필요한 라이브러리 설치 및 폴더 생성
pip3 install numpy scikit-learn
mkdir logistic_regression
cd logistic_regression폴더를 생성한 후, 머신러닝 코드 생성
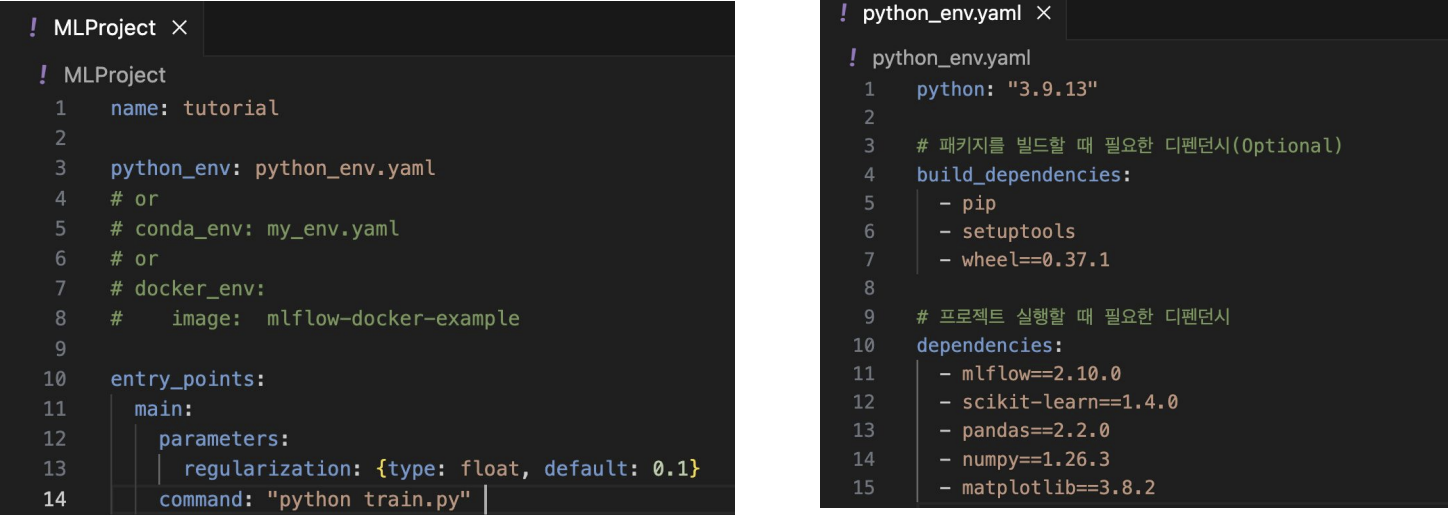
Project(프로젝트) 파일 만들기
MLflow를 사용한 코드의 프로젝트 메타 정보 저장
프로젝트를 어떤 환경에서 어떻게 실행시킬지 정의
패키지 모듈의 상단에 위치
MLProject(어떤 parameter와 명령어를 사용할건지),
python_env.yaml(어떤 파이썬 환경에서 실행할건지) 정의
RUN (실행)
하나의 run(모델 학습 코드)은 코드를 1번 실행한 것을 의미한다.
한번의 코드 실행 = 하나의 run 실행
run을 하면 여러가지 내용이 기록됨(mlflow에서 로깅했던 것들이 기록된다.)
run에서 로깅하는 것들
- Source : 실행한 Project의 이름
- Version : 실행 Hash
- Start & end time
- Parameters : 모델 파라미터
- Metrics : 모델의 평가 지표, Metric을 시각화 할 수 있음
- Tags : 관련된 Tag
- Artifacts : 실행 과정에서 생기는 다양한 파일들(이미지, 모델 Pickle 등)
mlflow run logistic_regression --experiment-namemy-first-experiment
을 치고 진행하면 python_env.yaml에 정의된 가상환경을 생성하고 실행된다.
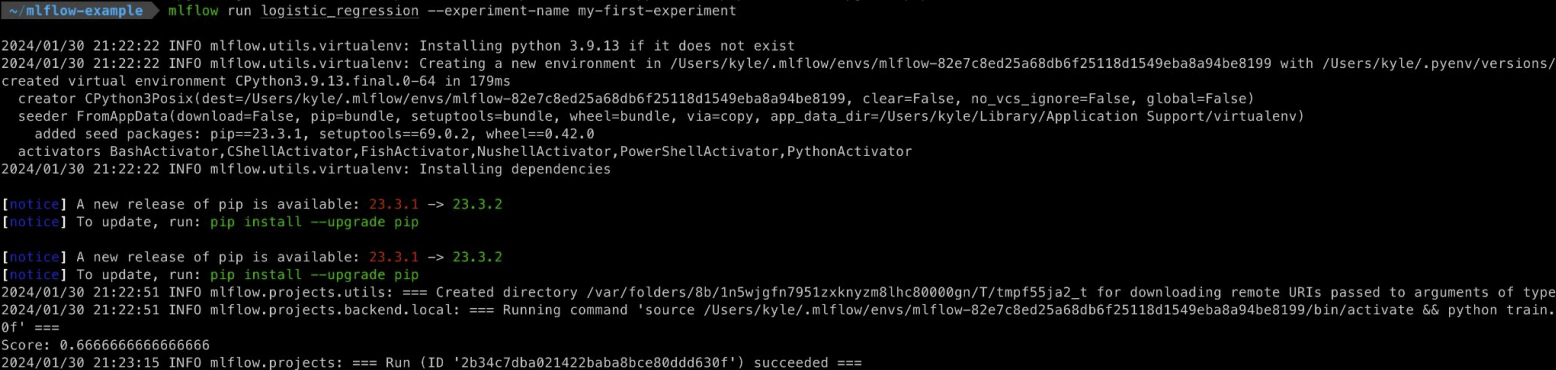
만약 현재 local에서 실행하고 싶다면 뒤에 --env-manager=local로 붙여서 실행하면 된다.
이렇게 하면 가상환경 추가 없이 바로 실행되서 빠르다.
localhost:8080으로 접속해서 보면 run을 한 기록이 남아있다.
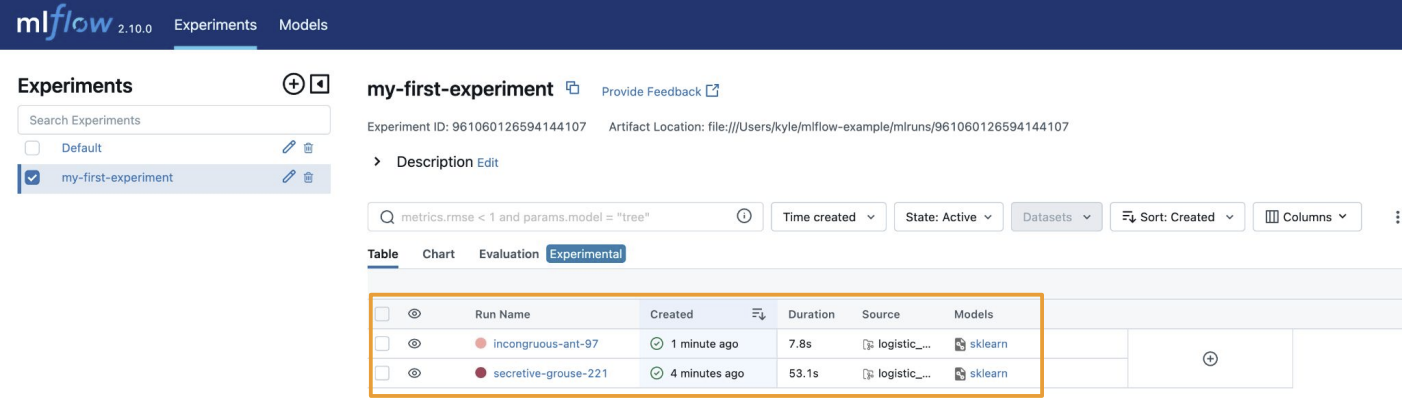
앞에서 mlflow.log_param을 통해 로깅한 값을 확인할 수 있다.
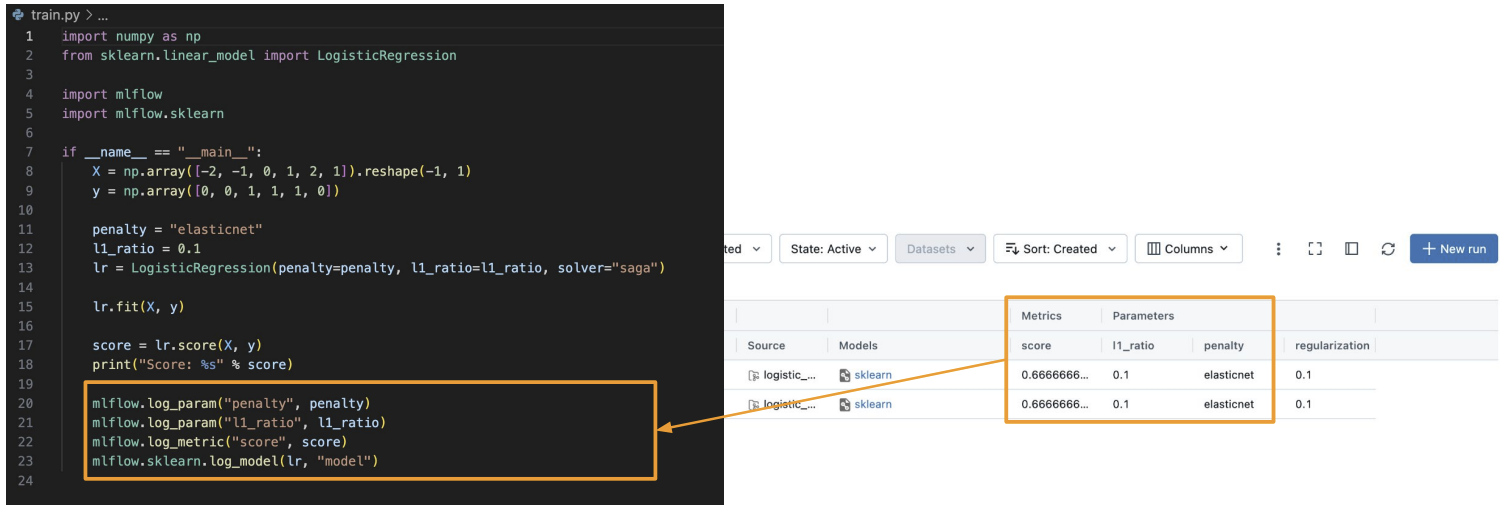
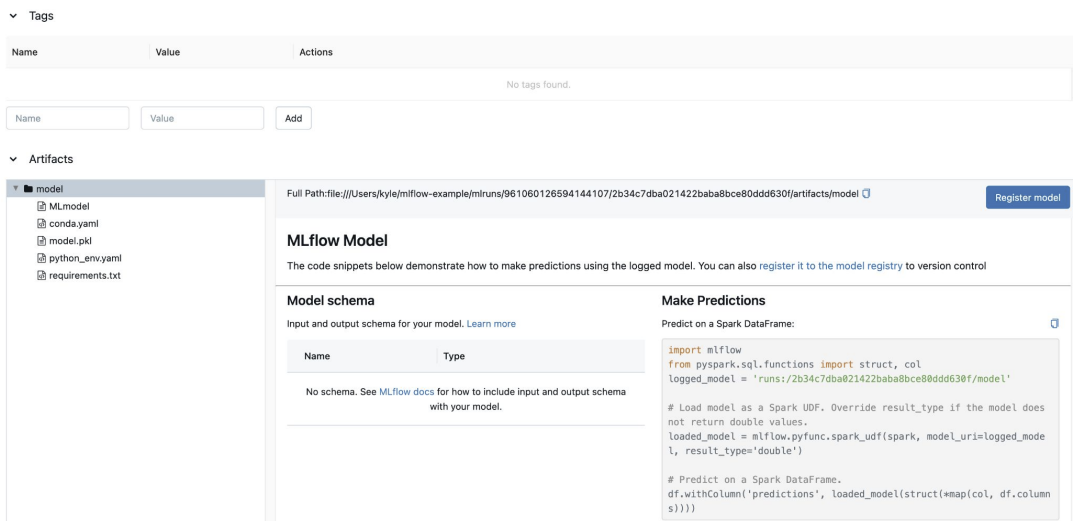
run name을 클릭하면 run에 대한 상세한 정보를 볼수 있다.
이때 하단에 artifact정보도 있어, MLflow Model을 예측하는 방법도 알려준다.
Experiments,run 관계
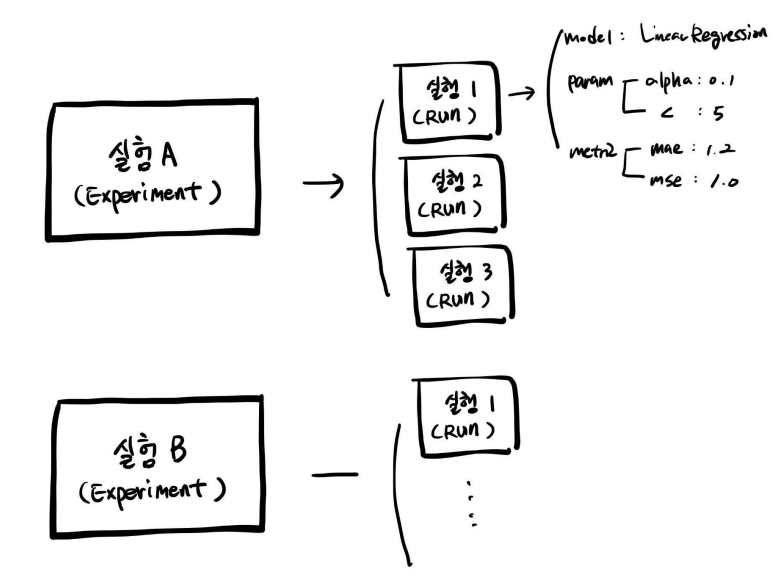
한 실험안에 다양한 run들이 실행되는 관계이다!!
run을 하면서 그 안에 모델, 파라미터, 결과값이 저장되는 것이다.
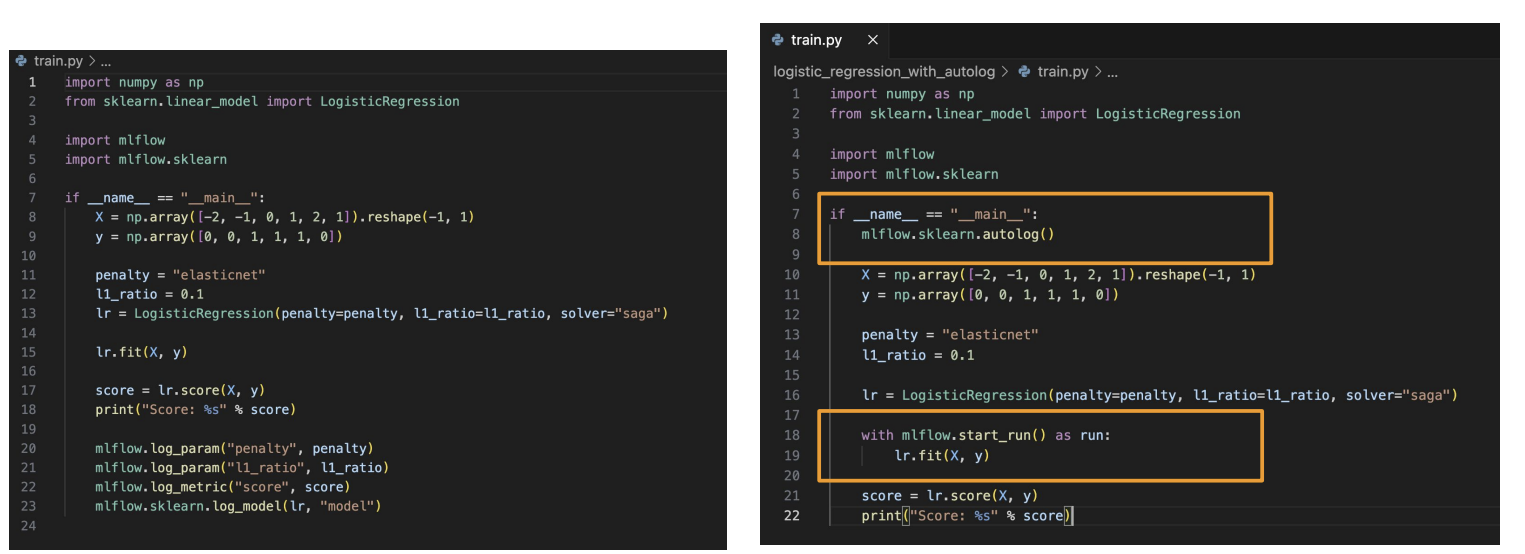
MLflow autolog
mlflow에서 log_params를 매번해서 로깅하는 것은 좀 번거로운 일이다.
로깅을 더 편하게 하는 방법은 없을까?
mlflow.autolog()를 사용하자!!
logistic_regression_with_autolog 폴더를 그 안에 train.py, ML Project 생성
아래의 사진에서 왼쪽은 우리가 배웠던대로 한것이고 오른쪽은 autolog를 적용한 것이다.
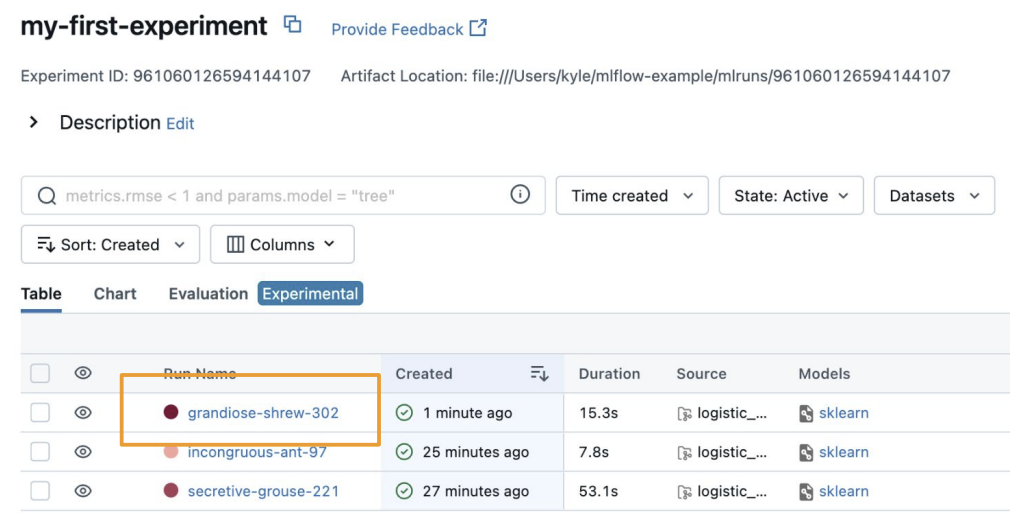
autolog를 사용한 결과를 살펴보면
mlflow run logistic_regression_with_autolog--experiment-namemy-first-experiment
--env-manager=local

localhost:8080로 살펴보면 새로운 로그 기록이 있다.
(더 살펴보면 그냥 하는것보다 autolog를 사용하면 더 자세하게 로깅하는 것을 알 수 있다.)
단, autulog는 모든 프레임워크에서 사용 가능한 것은 아니다.
ML flow에서 지원해주는 프레임워크들이 존재한다.
예) pytorch.nn.Module은 지원하지 않음 ( 반면 Pytorch Lightning은 지원)
MLflow Parameter
아래 왼쪽 사진처럼 파라미터를 받을 수도 있지만 오른쪽 사진처럼 파라미터를 지정해줄 수 있다.
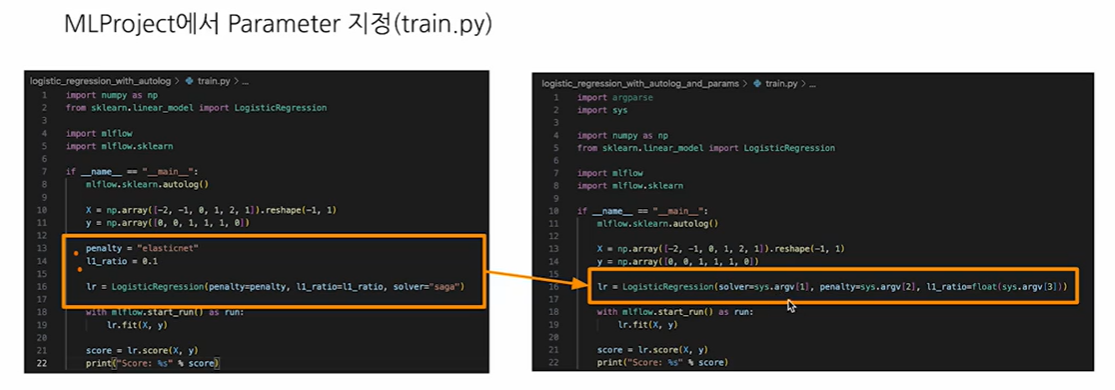
즉, 실행하는 시점에서 기입을 해줄 수 있게 되는 것이다.
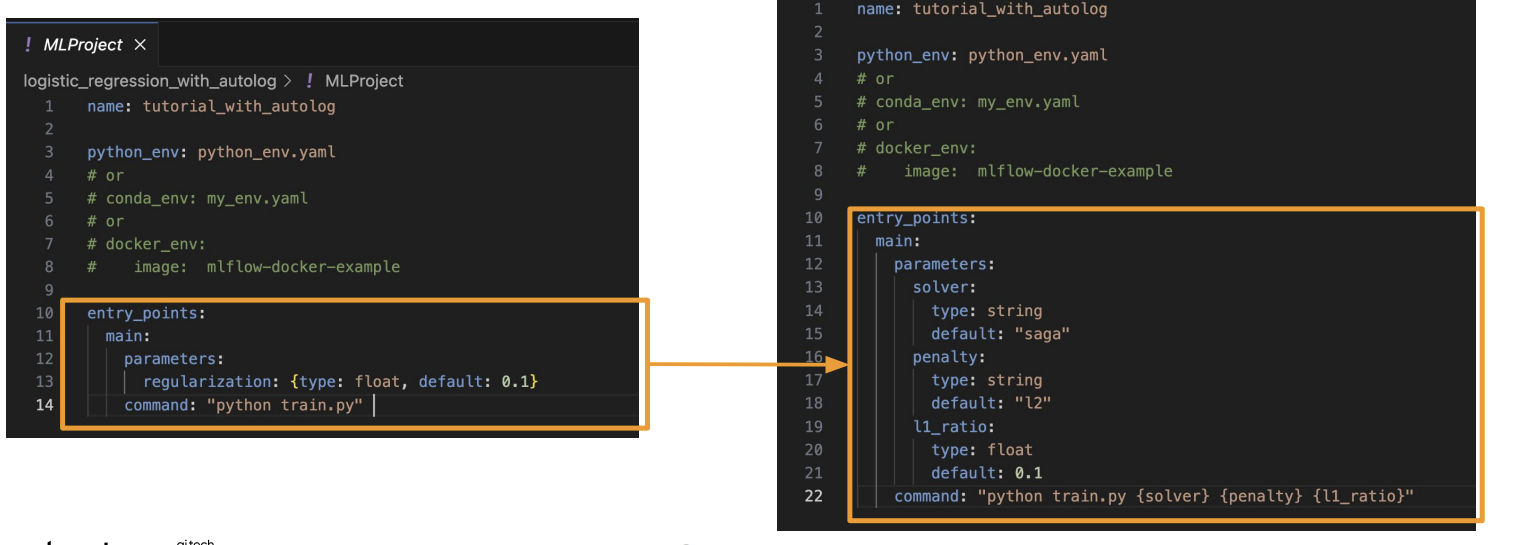
아니면 run을 할때도 파라미터를 수정해서 할 수도 있다.
MLflow를 통한 작업
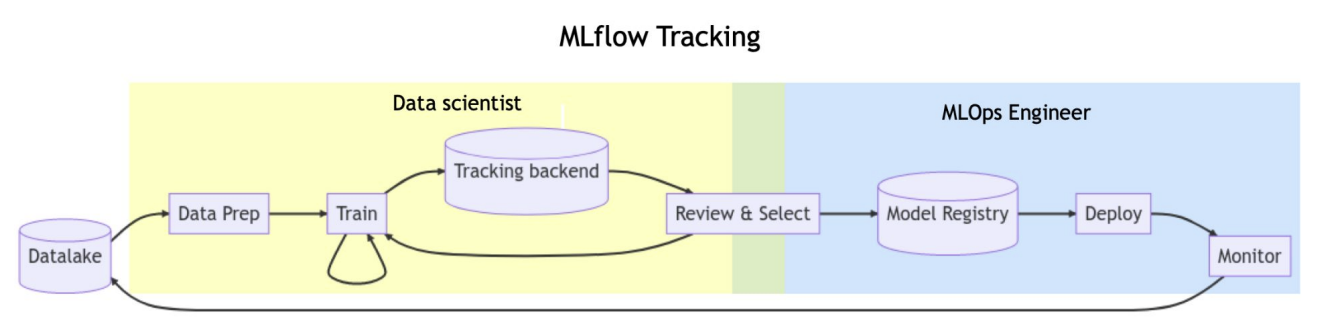
회사에서는 mlflow가 어떻게 사용될까
회사에 가면 data scientist와 mlops engineer 이렇게 두 개로 나뉘는 경우가 많다.
data scientist는 데이터를 전처리하여 학습하고, tracking backend로 데이터를 보내고, 모델을 리뷰하고 선정하는 과정을 거치고
mlops engineer는 data scientist가 선정한 모델을 model registry에서 가지고 와서 deploy하고 모니터링하는 과정을한다.
모델을 성능을 확인하는것은 서로 같이 한다고 볼 수 있다.
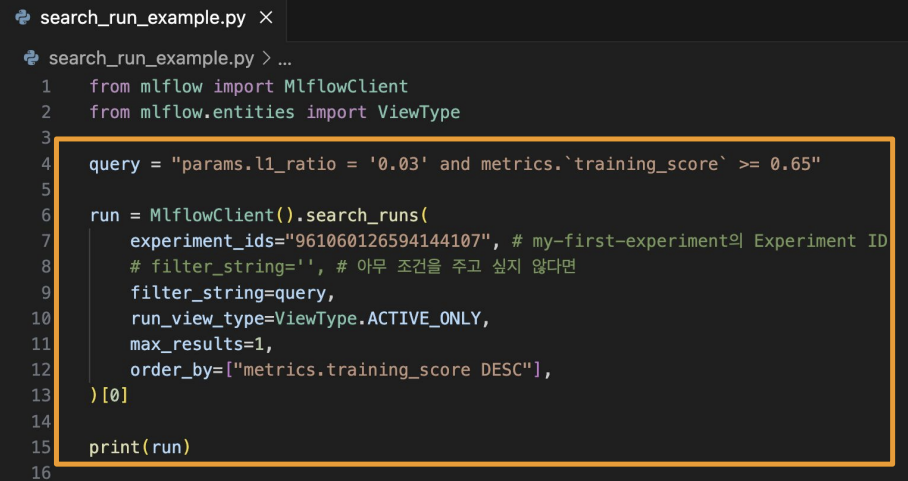
특정 run을 찾고 싶은 경우
우리가 특정 실험중에서 가장 좋았던 run을 찾고 싶은 경우에는 mlflow client에서 search_runs라는 함수를 이용하면 된다.
query 문법을 넣을 수도 있고, 특정 metric 기준으로 확인할 수 있다.
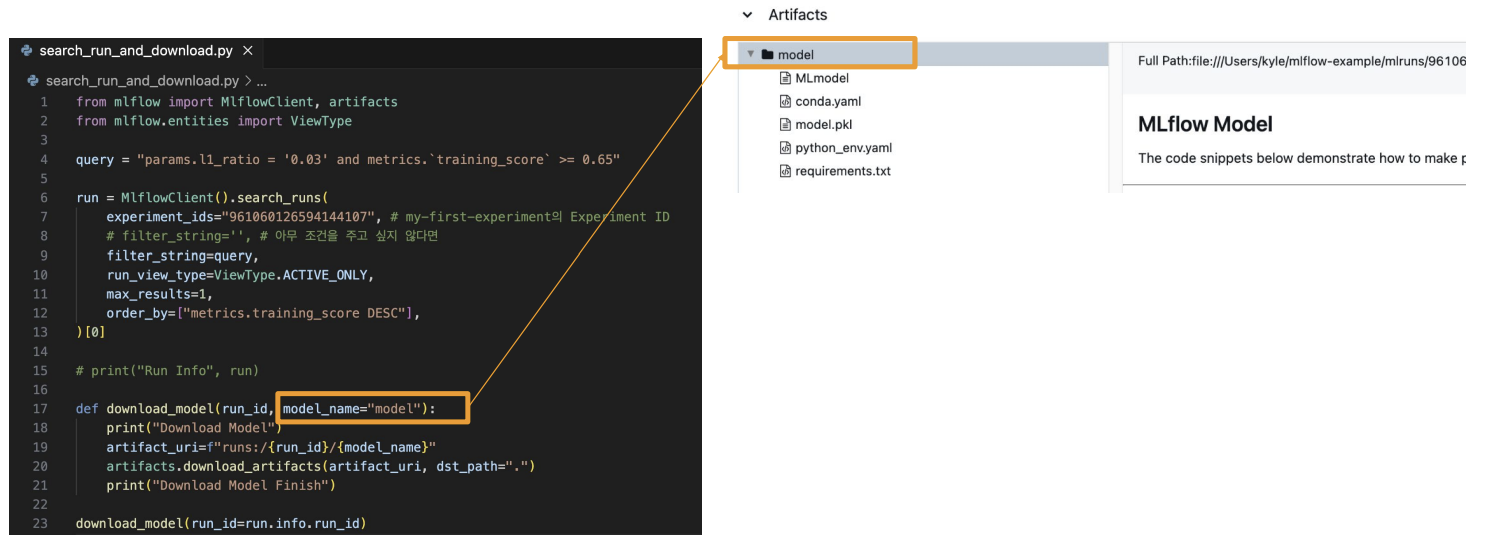
만약 찾은 모델을 다운로드까지 하고 싶다면 아래와 같이 download함수를 추가하면 모델이 다운 받아지는 것을 볼 수 있다.
(연구자들이 만든 모델을 이렇게 저장해서 사용할 수 있는것!!)
모델 평가
모델을 평가하는 기준은 두가지로 나눌 수 있다.
-
OFFLINE
단순함 / 과거 데이터를 기반 / 주기성
혹은 배치 / 훈련 후 정적인 모델 평가우리가 알고리즘을 개발하는 단계 대부분은 오프라인 평가이다.
-
ONLINE
복잡함 / 실시간 데이터에 기반 /
즉각적인 성능 평가 / 모델의 동적인 변화에 빠르게 대응실제 데이터가 들어올때 사용하는 평가이다.
offline 모델 평가
-
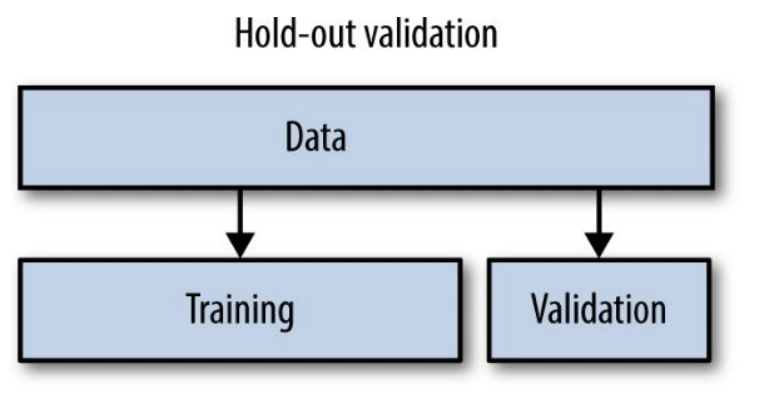
hold-out validation
우리가 대부분 하고 있던 hold-out validation이다.데이터를 훈련 세트와 테스트 세트로 나누어 모델을 훈련하고 평가
일정 비율의 데이터를 테스트에 예약하여 모델의 일반적인 성능을 평가
-
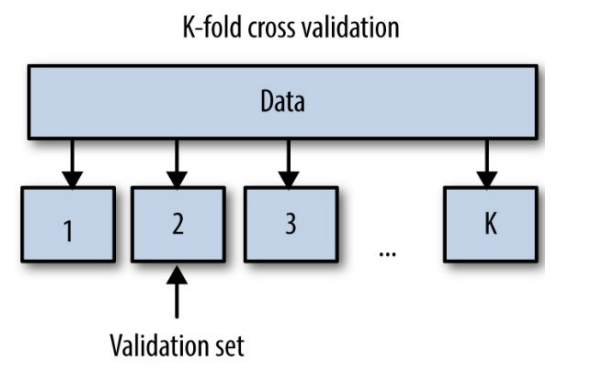
k-fold cross validation
그 다음 또 많이 쓰는 것이 k-fold cross validation이다.데이터를 K개의 부분집합(폴드)으로 나누고, 각 폴드를 한 번씩 테스트 세트로 사용
모델의 일반적인 성능을 더 정확하게 평가할 때 활용
-
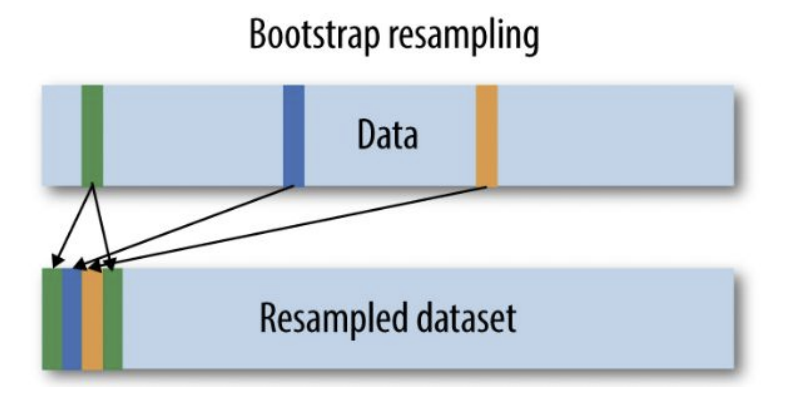
Bootstrap resampling
중복을 허용하여 원본 데이터셋에서 샘플을 랜덤하게 추출하여 여러 개의 부분 집합을 생성하는 방식이다.데이터셋의 분산을 고려하면서 모델의 성능을 더 견고하게 평가
online 모델 평가
-
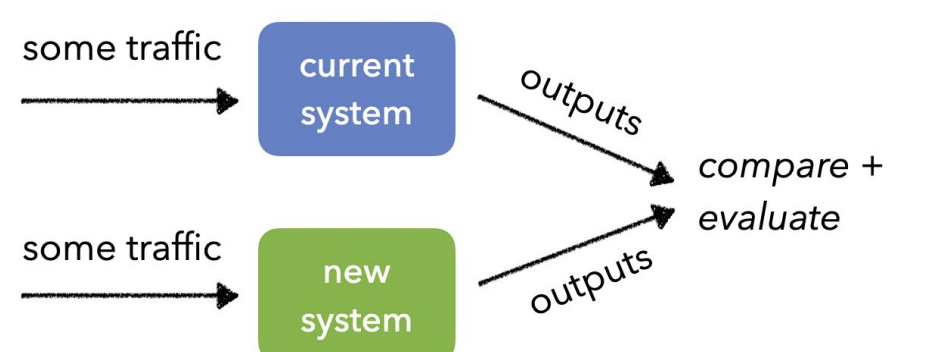
AB Test
같은 양의 트래픽을 두개 이상의 버전에 전송 하고 예측.
예측 결과를 비교 및 분석일반적인 AB 테스트는 통계적 유의미성을 얻기까지
시간이 매우 오래 걸려서 Multi-Armed Bandit과 같은 최적화 기법을 같이 쓰기도 한다.대부분 온라인 평가를 할때 많이 사용되는 방식이다.
-
Canary Test
카나리아(=새이름)는 석탄 광산에서 유독가스 누출의 위험을 알리는 용도로 사용

즉 새로운 버전의 모델로 트래픽이 들어가도 문제가 없는지 체크
현재 시스템에서 90%으로 새로운 시스템에서 10%의 데이터를 체크하는 방식으로 하게 된다!
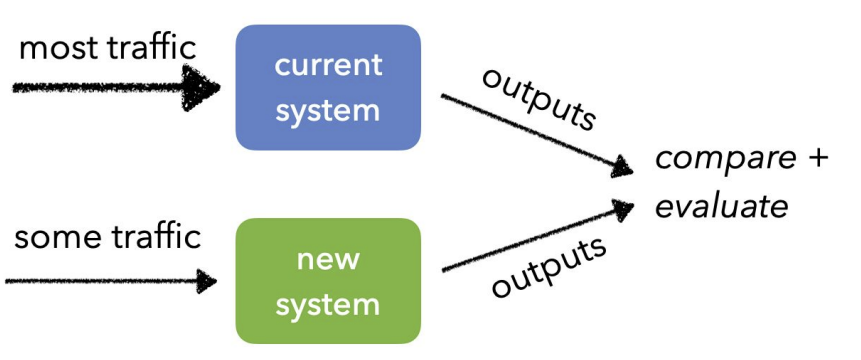
-
Shadow Test
프로덕션(=운영)과 같은 트래픽을 새로운 버전의 모델에 적용하는 방식이다.(둘다 100%의 데이터를 보내는 것)기존에 서빙된 모델에 영향을 최소화
새로운 버전의 모델에 정상적으로 예측하는지 확인
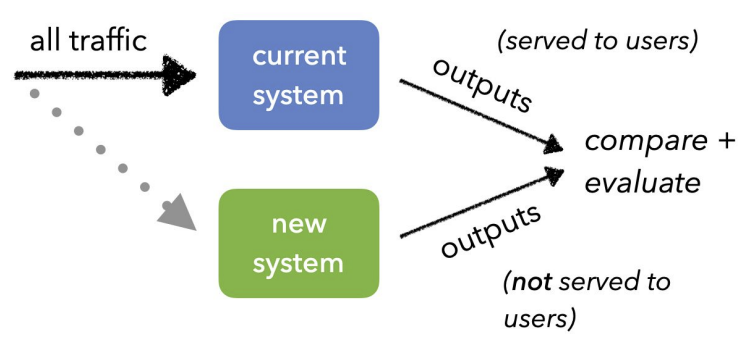
- 모든 트래픽은 현재 시스템에 전송
- 그림자처럼 같은 트래픽을 새로운 버전에 복제해서 전송
- 유저에게 직접 결과물이 전달되지 않음(=서빙되지 않음) => 새모델이 이슈가 있어도안 전
- 하지만 트래픽 복제 전송을 위한 인프라 구성 필요
End to End
결국엔 Offline과 Online평가를 반복하면서 최적의 모델을 서빙할 수 있도록 지속적으로 개선한다.
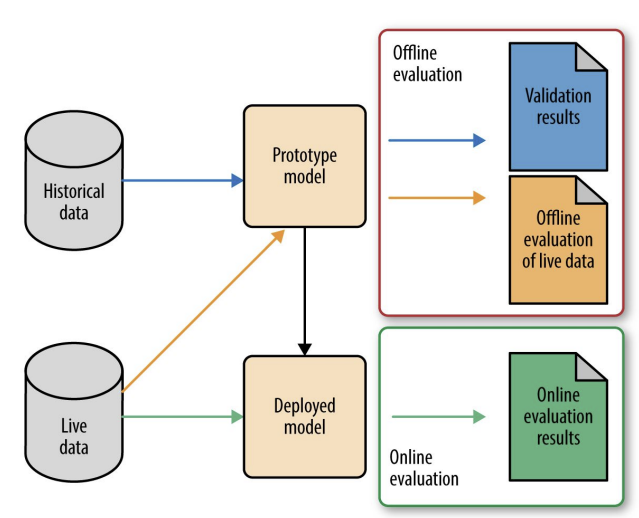
머신러닝 시스템 평가하는 디자인 패턴은 아래와 같이 있는 것을 알 수 있다.

