비동기(Asynchronous) 프로그래밍
코딩을 하면서 내가 만든 프로그램이 자원을 어떻게 더 효율적으로 사용하도록 만들 것인지에 대한 고민들을 하면서, 비동기 프로그래밍이라는 이야기가 자주 나오지만 막상 비동기 프로그래밍에 대한 정의를 내리라고 하거나, 해당 프로세스가 어떻게 동작을 하는지 정확히 말하려고하면 말문이 막히고 내가 알고있던 개념이 맞나 싶을 때가 있습니다. 오늘도 비동기 프로그래밍이 효율적이라고는 하지만 정확히 어떤 방식으로 자원을 효율적으로 관리하는지 정확히 이해하지 못하고 있다고 생각되어 정리를 해보고자 합니다. ‘비동기’라는 단어를 둘러싸고 있는 비슷한, 혹은 반대편에 있는 여러 용어와 개념들은 항상 머릿속을 헷갈리게 만듭니다. 이와 관련된 개념들을 머릿속에 잘 저장해둘 수 있도록 각 용어들에 대해 정리해보고자 합니다.
비동기(Asynchronous) 프로그래밍이란?
비동기 프로그래밍에 대해서 설명하는 글에서 가장 많이 하는 말은
동기(Synchronous) 프로그래밍은 하나의 요청이 들어오면 끝날 때까지 기다린 후 다음 요청을 받는다.
비동기(Asynchronous) 프로그래밍은 요청이 들어오면 끝날 때까지 기다리지 않고 다음 요청을 받는다.
이러한 관점으로 설명하게 됩니다. 네이밍에서도 느낄 수 있듯이 요청과 작업이 끝나는 시간이 동기적으로 이루어지느냐 마느냐에서 차이가 나는 것입니다. 간단하고 명료하고 헷갈릴 것이 전혀없습니다. 비동기라는 단어의 뜻 자체가 요청과 결과가 동기적으로 이루어지지 않는다 이기 때문입니다. 그러나 항상 비동기 프로그래밍을 이야기하면서 자주 보이는 단어가 Non-Blocking I/O입니다. 저에게 있어서는 요녀석이 머리를 복잡하게 만드는 주범이었죠. 그래서 I/O 관련 내용은 다 빼고, 비동기 프로그래밍이란 것에 집중하면 이는 프로그래밍 모델일 뿐입니다. 그 말은 즉슨, 이는 프로그램의 주 실행흐름을 멈추어서 기다리는 부분없이 즉시 다음 작업을 수행할 수 있도록 만드는 프로그래밍 방식을 말합니다. 이는 코드의 실행 결과 처리 및 활용을 별도의 채널에 맡겨둔 뒤 결과를 기다리지 않고 바로 다음 코드를 실행하는 방식으로 프로그램을 진행한다는 뜻입니다. 비동기 프로그래밍을 구현하는 방식은 크게 보아 언어에서 지원하는 문법을 사용하는 방식(future, promise와 같은 객체 형태의 결과를 요청 즉시 돌려받는 방식이나, Python의 코루틴(Coroutine)과 같은 언어의 문법을 이용하는 방식 등)과 함수 전달을 통해 처리하는 방식(함수를 값처럼 사용(First-class function)하는 것을 지원하는 언어에서 콜백 함수(Callback function)를 전달하여 결과를 처리하는 방식) 등이 있습니다. 여기까지가 우리가 일반적으로 이해하는 비동기 프로그래밍입니다. 이 비동기 프로그래밍 모델은 어플리케이션 단계의 프로그래밍적인 관점으로 이야기가 끝이납니다. 왜냐하면 비동기 프로그래밍 이니까요.
그런데 왜 여기서 Non-Blocking I/O라는게 등장하냐... 왜냐하면 우리들의 프로그램이 요청에 대한 응답이 느려지는 가장 큰 이유는 연산 작업이 아닌 I/O 작업 때문이고, 이는 우리가 작성하는 어플리케이션 단계에서 조절할 수 있는 것이 아니라 커널단까지 내려가도 비동기적으로 동작해야 진정한 비동기 프로그램이 아닌가라는 생각 때문인 것 같습니다.
Blocking I/O란?
기본적으로 linux 운영체제는 Blocking I/O으로 동작하고 있습니다. Blocking I/O는 아래의 그림과 같이 동작하게 됩니다.

- 사용자(Application)이 커널에 recvfrom을 이용해 데이터 read를 요청합니다.
- 커널이 보내줄 데이터를 준비하고 카피하여 가져오게 되고, 사용자는 이 작업 동안 기다리게 됩니다.
- 데이터가 입력되면 사용자에게 결과가 전달되어야만 사용자(Application)이 자신의 작업에 비로소 복귀할 수 있습니다.
말 그대로 블락이 되고, 어플리케이션에서 다른 작업을 수행하지 못하고 대기하게 되므로 자원이 낭비됩니다. 문제는 이 대기가 어플리케이션이 바빠서 발생하는 것이 아니라, 커널이 데이터를 가져오는 작업을 기다리는 것이 핵심입니다. 이러한 자원 낭비를 개선하고자 Non-blocking I/O가 등장하게 되었습니다.
Non-Blocking I/O란?
blocking I/O를 개선시킨 방향으로 I/O 작업이 진행되는 동안 유저 프로세스의 작업을 중단시키지 않는 방식이다.
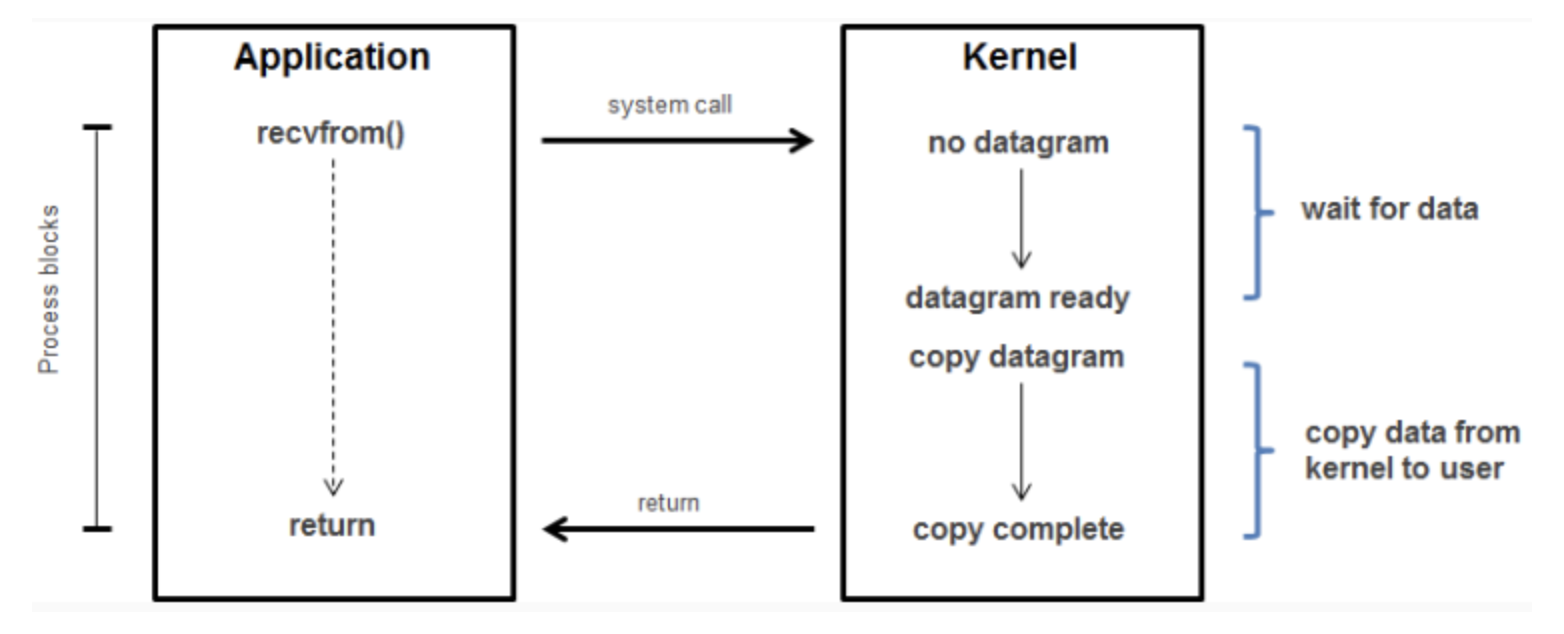
- 사용자(Application)이 커널에 recvfrom을 이용해 데이터 read를 요청합니다.
- 데이터가 준비되었든지 안되었는지 상관없이 바로 결과가 반환됩니다.
- recvfrom 함수는 non-blocking 설정이 된 경우, 입력 데이터가 없으면 입력 데이터가 없다는 결과 메세지(EWOULDBLOCK)를 반환합니다.
- 데이터가 있을 때까지 이를 반복합니다.
- 데이터가 입력되면 사용자에게 결과가 전달됩니다.
위의 방법의 경우에는 데이터가 준비된 이후에만 중단되기 때문에 어플리케이션에서 오랜시간 작업이 중단되는 일 없이도 I/O 작업을 진행할 수 있습니다. 그러나 이는 Polling 방식으로 blocking I/O보다 시스템 호출을 자주하고, Context Switching이 자주 발생할 수 있기 때문에 이 또한 자원의 비효율성은 존재합니다.
위와 같은 방식을 동기식 Non-Blocking I/O라고 합니다. 결국 하나의 요청에 대한 결과를 받을 때까지 사용자(Application)는 물어봐야한다는 것이죠. 현재까지 소개해드린 방법은 모두 동기식으로 "얘가 언제 오나" 무작정 기다리는 방법(동기식 Blocking I/O)과, 다른 일을 하다가 중간중간 "아직이니?" 체크하는 방법(동기식 Non-Blocking I/O)입니다. 결국은 그 아이가 언제오는 지 계속 궁금해하는 상태라는 거죠!
Asynchronous Non-Blocking I/O
위의 비효율적인 방식을 개선한 것이 Asynchronous I/O 입니다.
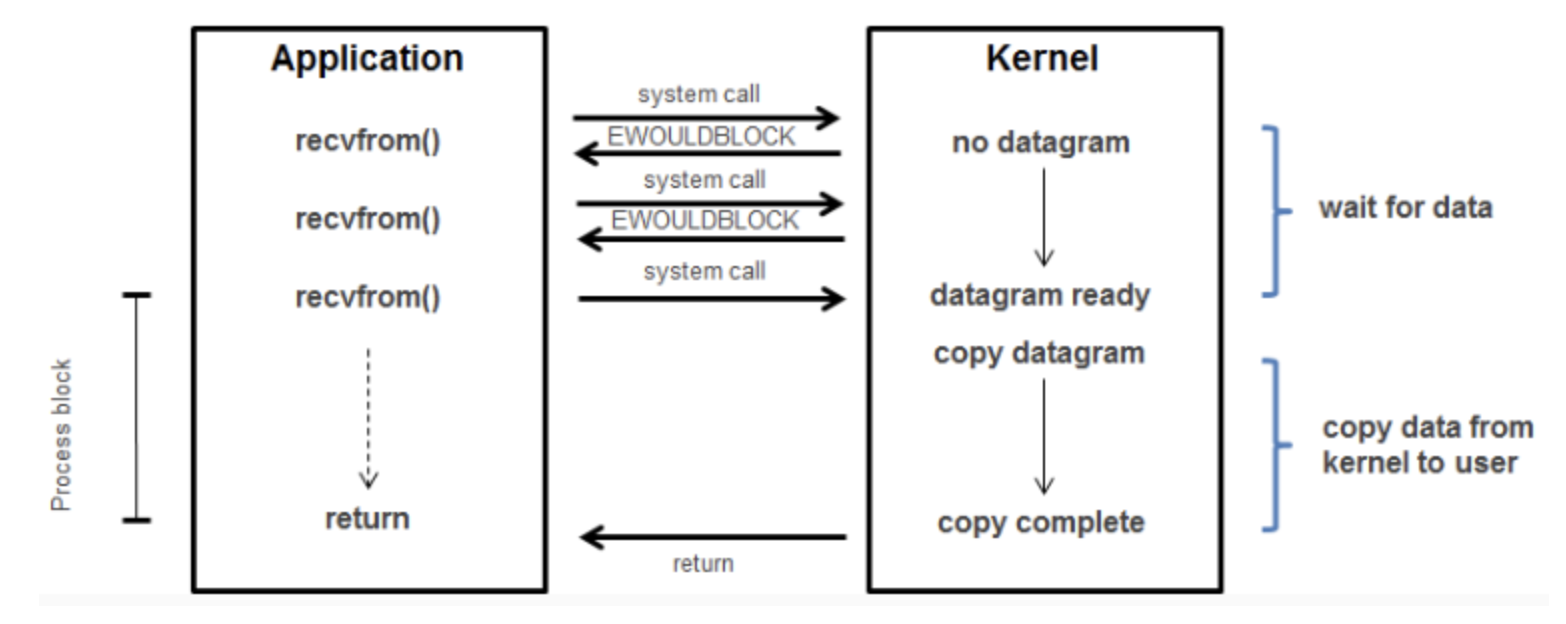
- 사용자(Application)이 커널에 recvfrom을 이용해 데이터 read를 요청합니다.
- 데이터가 준비되었든지 안되었는지 상관없이 바로 결과가 반환됩니다.
- 사용자(Application)은 다른 작업을 수행합니다.
- 커널에 IO 응답(response)가 도착하면 신호(signal)나, 쓰레드 기반 콜백(callback)으로 IO 전달(transaction)합니다.
위에서 보이는 듯이 I/O 처리가 완료된 타이밍으로 결과를 회신하는 I/O모델을 비동기 I/O라고 합니다. 이제 정말 요청을 보내고 아무 걱정없이 기다리지 않고 수행하다가, 결과를 받아보는 형태가 되는 겁니다.
리눅스의 Asynchronous I/O를 기준으로 설명하면, 기존의 전통적인 IO 모델에서는 단일 핸들로 식별되는 하나의 블로킹 IO가 있었고 이를 파일 설명자(file descriptor)로 불렀습니다. 이는 파일, 파이프, 소켓 등등에 모두 적용되었다. 사용자는 하나의 전달(transfer)을 하고 시스템 콜이 그에 대한 리턴을 해줬습니다.
이제 Asynchronous I/O에서는 복수의 전달을 할 수 있게 되었습니다. 이를 위해 각각의 전달들을 식별하기 위한 식별자가 필요하여 AIOCB(AIO Control Block) 구조체로 구현되었습니다. AIOCB는 전달에 관한 모든 정보를 담고 있고, IO에서 알림이 발생하면(완료, completion), 이를 유일하게 식별하기 위해 AIOCB 구조체가 준비됩니다.
추가 : I/O 다중화 (Multiplexing)
I/O관련된 내용을 정리하다 보면 반드시 언급되는 것이 I/O 다중화입니다. 이는 I/O Multiplexer에 의해 핸들링되고, poll(), select(), epoll() 시스템 호출을 이용해 여러 파일 디스크립터를 하나의 프로세스로 관리합니다.
Select
select는 지정한 소켓의 변화를 확인하고자 사용되는 함수로, 소켓에 변화가 생길 때 까지 기다리다 어떤 소켓이 어떤 동작을 하면 동작한 소켓을 제외한 나머지 소켓을 제거하고 해당 소켓에 대한 확인을 진행합니다. 확인하는 과정은 for 루프를 이용합니다. 디스크립터 수에 제한되어 있어 불편함은 있으나, 사용이 쉽고 지원 OS 가 많아 이식성이 좋은 편입니다.
Poll
poll은 select의 문제였던 디스크립터 수 제한이 없습니다. 처리 방식은 select와 비슷하며, 어려개의 파일 디스크립터를 동시에 모니터링 하다 한개라도 읽을 수 있는 상태면 블로킹을 해제합니다.
ePoll
epoll API 는 Linux 커널 2.5.44에서부터 도입되었습니다. 파일 디스크립터 수에 제한이 없으며 상태 변화 모니터링도 크게 개선되었습니다. 구체적으로 파일 디스크립터 상태를 커널에서 감시하고 변화된 내용을 직접 확인할 수 있기 때문에 select, poll 처럼 루프를 사용한 모니터링이 불필요하기 때문에 효율적인 I/O 를 구현할 수 있습니다.
일반적으로 성능이 가장 좋은 epoll()이 가장많이 이용됩니다. 하지만 epoll()은 POSIX 표준이 아니이고 Linux Kernel 2.6 이후에서만 지원합니다.
참고
https://tech.peoplefund.co.kr/2017/08/02/non-blocking-asynchronous-concurrency.html#fn:7
https://djkeh.github.io/articles/Boost-application-performance-using-asynchronous-IO-kor/
https://ju3un.github.io/network-basic-1/
https://sjh836.tistory.com/109
https://ssup2.github.io/theory_analysis/Event_Driven_Architecture_on_Linux/
