Load Average 란?
Load Average는 Load 값의 평균을 나타낸 수치로, 꽤 중요한 수치입니다.
Linux 계열 OS에서는 uptime이나 top 명령어를 통해 볼 수 있습니다. 아래와 같이 1분, 5분, 15분 단위로 각각 계산하여 보여줍니다.
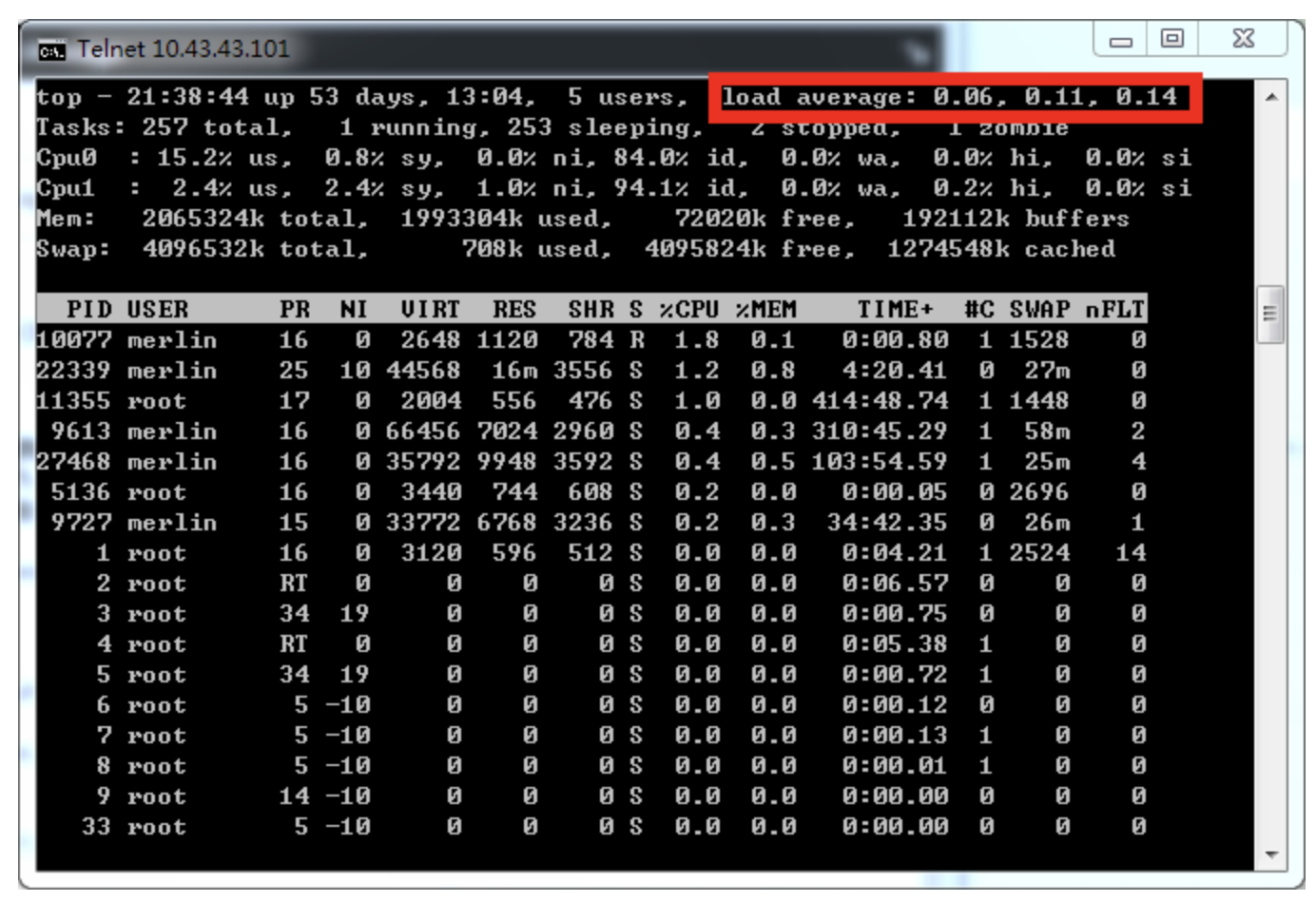
출처 : https://www.programering.com/a/MDO4EDMwATk.html
그렇다면 Load가 무엇이기에 Load Average가 중요하다는 걸까?
말로 설명하자면 Load는 시스템에서 실행 중인 thread (task) 요구를 평균 실행 횟수 와 대기 중인 thread의 수로 보여주는 "시스템 부하 평균"이라고 합니다다.
너무 추상적이니 좀 더 개념적으로 자세히 살펴봅시다.
한정적인 자원인 CPU를 OS의 Process Scheduler가 Queue를 이용하여, CPU 자원을 점유할 Process를 조절합니다.
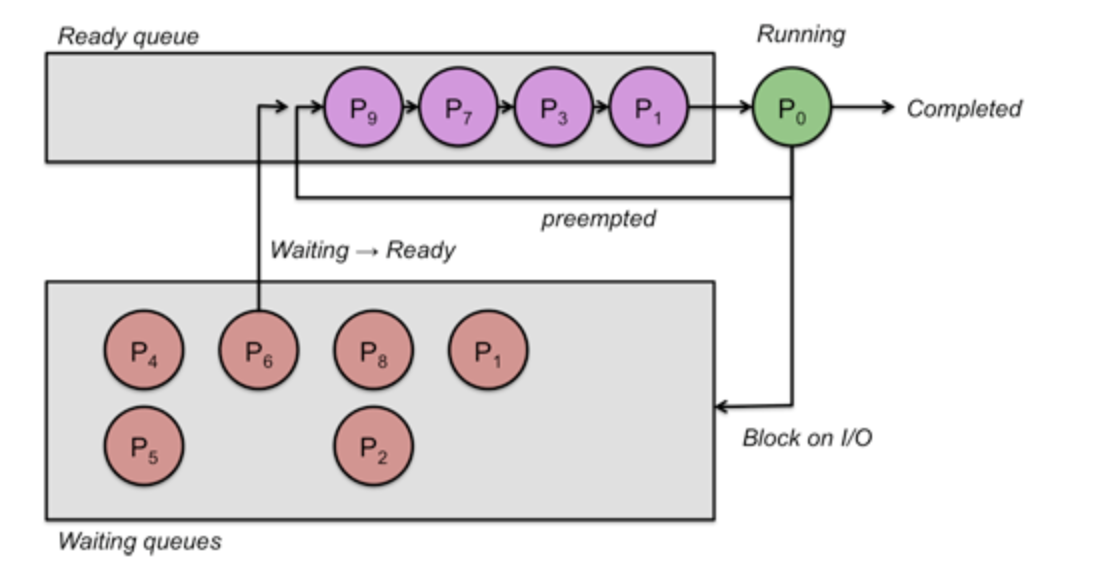
출처 : cs.rutgers.edu
Process Scheduler는 Process Descriptor를 이용해서 프로세스 상태를 정의하고 관리합니다.
- TASK_RUNNING : 실행 가능 상태로, CPU에 의해 실행 중이거나 처리가 가능한 상태,
- TASK_INTERRUPTIBLE : 인터럽트에 의해 상태가 변할 수 있고, 자신의 신호를 기다리는 상태
- TASK_UNINTERRUPTIBLE : 인터럽트에 의해 상태가 변하지않고, 자신의 신호를 기다리는 상태
- TASK_ZOMBIE : TASK가 종료되었지만, 아직 부모 TASK에게 정보를 넘겨주지 않은 상태 (wait4 system call을 기다리는 상태)
- TASK_STOPPED : TASK가 중단된 상태
프로세스의 상태 값은 아래와 같이 변화합니다.
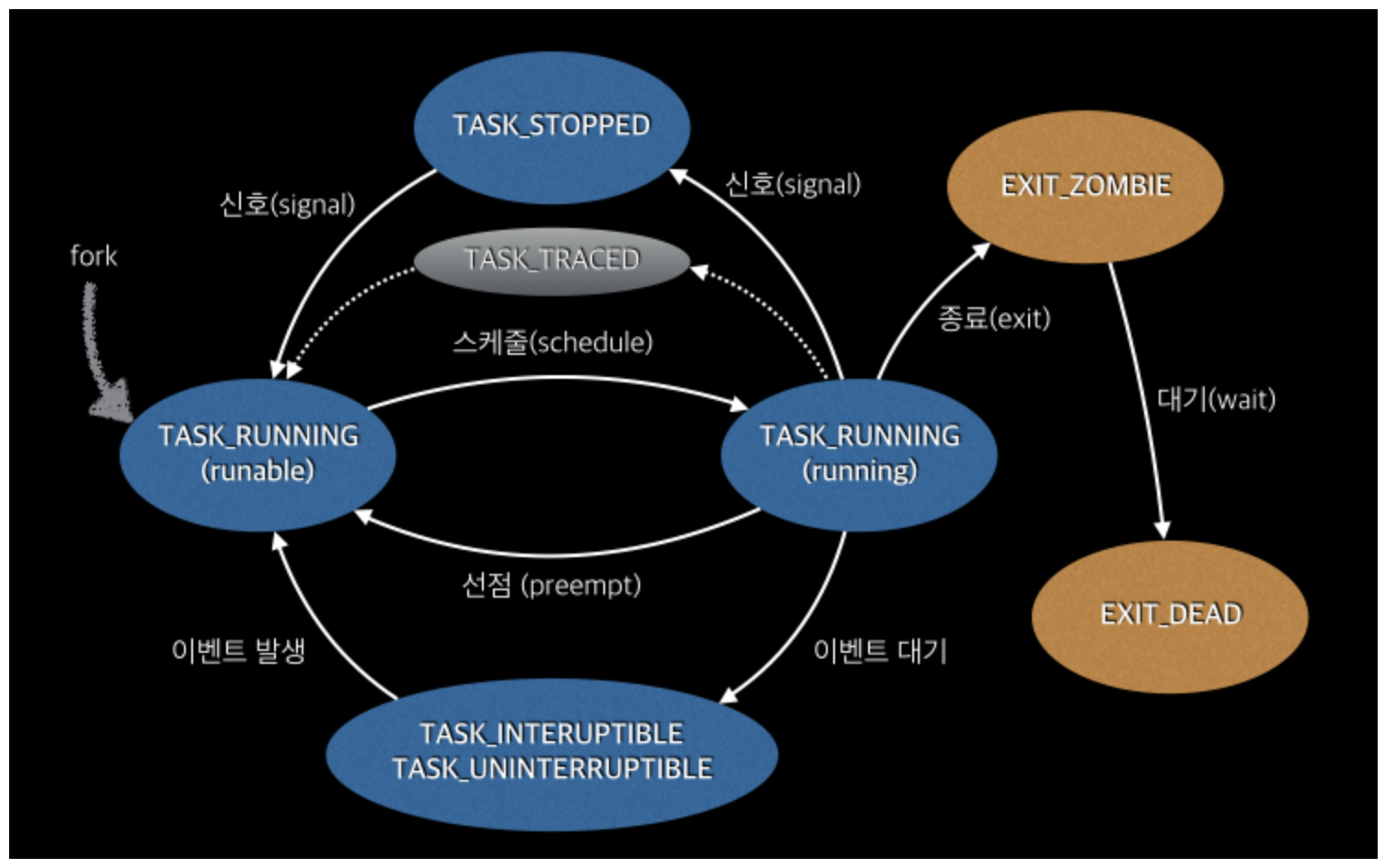
출처 : https://lunatine.net/2016/02/19/about-load-average/
Load는 여기서 TASK_RUNNING(현재 CPU를 점유하지 않은)과 TASK_UNINTERRUPTIBLE 상태를 가진 프로세스를 수치로 표현한 값으로,처리를 위해서 기다리고 있는 가용가능한 상태의 프로세스를 뜻합니다.
프로그래머는 실제 코드를 보고 싶어지기 때문에.... 실제로 Linux는 Load를 어떻게 계산하는지 알아보았습니다.
CentOS6 기반이 되는 kernel 2.6.32 (kernel/sched.c - RHEL6) 실제로 Load 값을 계산하는 부분을 살펴보았습니다.
static void calc_load_account_active(struct rq *this_rq)
{
long nr_active, delta;
nr_active = this_rq->nr_running; //현재 ready_queue의 TASK_RUNNING
nr_active += (long) this_rq->nr_uninterruptible; //현재 ready_queue의 TASK_UNINTERRUPTIBLE
if (nr_active != this_rq->calc_load_active) {
delta = nr_active - this_rq->calc_load_active;
//현재 ready_queue의 활성화된 로드는 RUNNING + UNINTERRUPTIBLE
this_rq->calc_load_active = nr_active;
atomic_long_add(delta, &calc_load_tasks);
}
}
void calc_global_load(void)
{
unsigned long upd = calc_load_update + 10;
long active;
if (time_before(jiffies, upd))
return;
active = atomic_long_read(&calc_load_tasks); //저장된 로드 값을 가져온 후 계산
active = active > 0 ? active * FIXED_1 : 0;
avenrun[0] = calc_load(avenrun[0], EXP_1, active);
avenrun[1] = calc_load(avenrun[1], EXP_5, active);
avenrun[2] = calc_load(avenrun[2], EXP_15, active);
calc_load_update += LOAD_FREQ;
}
Load Average를 실제로 구현한 코드를 보니, 1분, 5분, 15분의 평균은 구라였습니다.
사실 모든 Load 값을 저장하고 평균을 낼 수 없기에 통계학이나 주식에서 자주 사용되는 이동 평균과 지수평활법을 이용하여 계산합니다.
과거 시점의 평균 값을 토대로, 변화 값(delta)를 이용하여 계산하는 방법입니다.
그렇기에, 실제 놀고 있는 서버에 single-thread 프로그램을 실행시키면 아래와 같은 그래프를 띕니다. 1분 평균이 1.0이 아니고, 5분 평균이 1.0도 아닙니다....
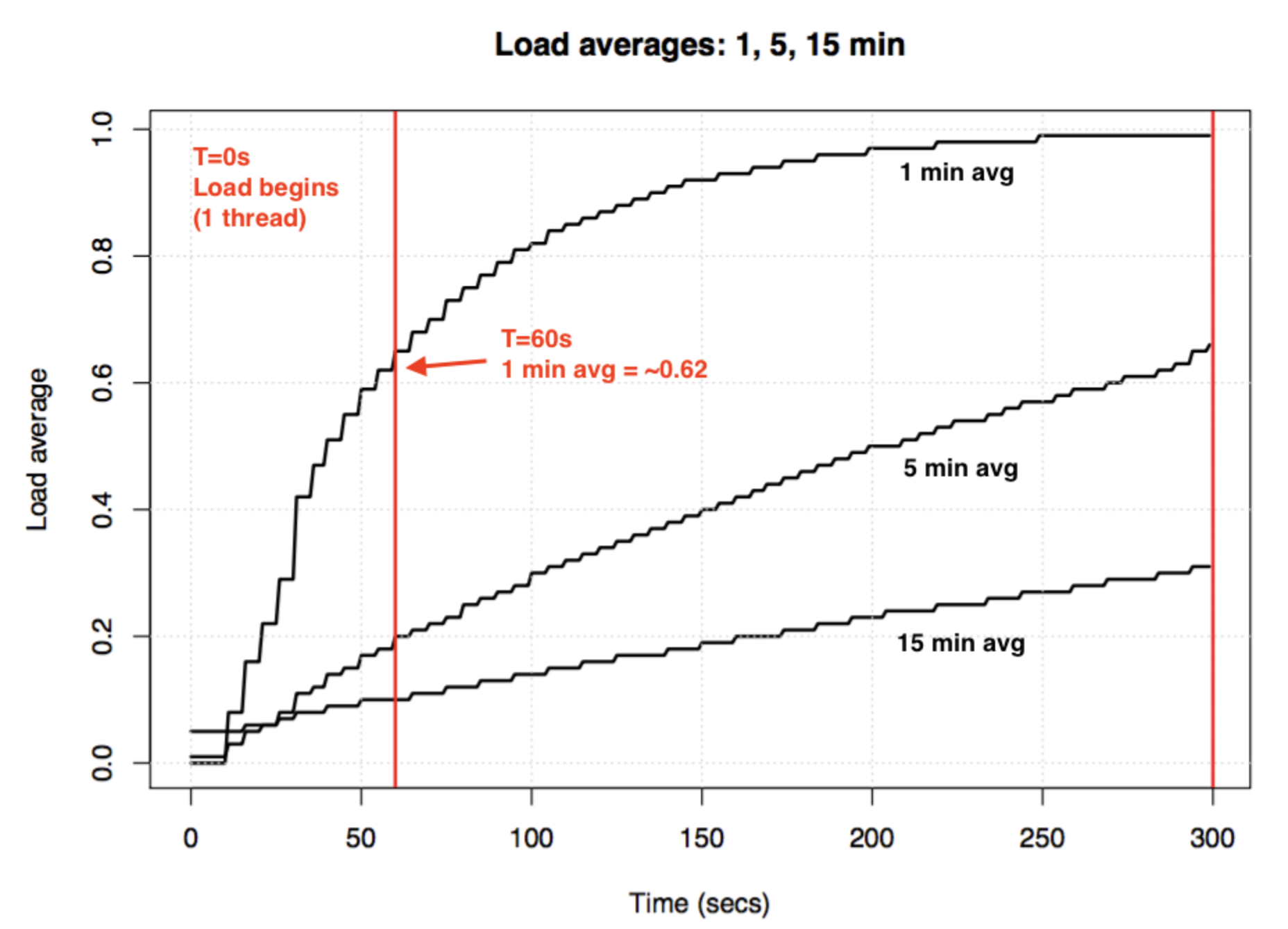
출처 : http://www.brendangregg.com/blog/2017-08-08/linux-load-averages.html
Load Average 어떻게 보아야하는가
Load Average가 정확한 값이 아니라면.... 어떤 정보를 얻어야하고, 어떤 수준이 위험한 수준인가가 가장 첫 번째로 떠오릅니다.
대부분은 Load average를 이용하여 이런 정보들을 얻는다고 합니다.
- average가 0이라면 idle 상태이다.
- 1분 평균이 5, 15분 평균보다 낮다면 Load가 증가하고 있다.
- 1분 평균이 5, 15분 평균보다 높다면 Load가 감소하고 있다.
- Load가 시스템의 코어 개수를 넘어간다면 성능상 문제가 발생할 수 있다.
명확해졌나....??
Linux의 Uninterruptible Task는 어떤가
Linux의 Load에는 TASK_RUNNING 뿐만 아니라 TASK_UNINTERRUPTIBLE까지도 포함된다는데 이는 적절한가??
CPU 수요뿐만 아니라 disk I/O와 같은 작업도 Load에 포함하는 것이 적절한가??
Linux는 kernel이 runnable한 프로세스만을 load average로 계산하는 것보다, noninterruptible한 I/O 작업도 포함해야한다고 합니다.
그 이유는 swap에 있었다. 프로세스가 swapping을 하거나, noninterruptible한 I/O 작업도 자원을 소모한다고 보기 때문입니다.
만약 load average에 이를 포함하지 않는다면, 더 느린 swap disk 바꾸었을 때 load average가 줄어드는 현상을 이해할 수 없을 것이고, 포함하는 것이 더 시스템의 속도에 대해 일관적인 지표를 보여줄 것입니다.
하지만!!! 아무리 그래도 Linux의 Load Average가 너무 높게 나올 때가 있다....
Linux가 위와 같은 개념을 세울 때는 1993년도 였고, TASK_UNINTERRUPTIBLE로 설정되는 코드가 13개 정도였다고 합니다. 현재는 이를 설정하는 새로운 코드들이 많이 추가되었고,(약 400개) 이들 중에 Load Average에 포함되면 않되는 요소들이 존재할 가능성이 보입니다.
우리가 원하는게 Thread, Task가 필요한 자원인가? 물리적 자원인가? Thread가 필요한 자원이라면 지금 Load Average 는 좋습니다.
이후 이 사람은 60초 동안 커널 스택을 보아 약 400개 가량 추가되었다는 TASK_UNINTERRUPTIBLE을 살펴봅니다...
대단한 사람... 실제로 살펴보니, Linux에서 말하는 Load Average는 "System Load Average"라고 할 수 있었습니다.
완전 유휴 상태가 아닌 thread 수를 측정합니다. 이는 다양한 자원에 대한 수요에 대해 알 수 있는 장점이 있습니다.
CPU Load Average라면 Load Average/CPU와 같은 간단한 수식을 측정 지표로 삼을 수 있지만, Linux의 System Load Average는 다양한 리소스 유형들을 다루기 때문에 CPU로만 나눌 수 없고, 상대적 비교에 사용해야 유리합니다. 내가 정상작동하는 Load Average를 알고 현재 얼마나 증가하고 있는지를 판단하는....
Linux는 그러면 어떤 지표를 가지고 판단하는 것이 좋은가
Linux는 Load Average로 어떤 리소스에 대한 수요가 높아지는지 확실하지 않기 때문에, 다른 지표가 필요합니다.
CPU, Disk에 대한 각각의 지표를 이해하고, 자신만의 체크리스트를 가지고 살펴보는 것을 추천하고 있었습니다.
그러면 Load Average는 어디에 사용하는가.... 이는 클라우드 컴퓨팅 마이크로 서비스에 대한 scale-up 정책에서 다른 지표들과 함께 많이 사용됩니다. 이러한 정책을 가졌을 때 scale-up하지 않는 것보다 잘못 scale-up한 것이 더 안전하기 때문에 더 많은 지표를 가지고 측정해야합니다.
글쓴이는 load average를 historical 정보로만 사용한다. 성능이 저하되는 cloud에 접속했을 때 1분 평균이 15분 평균보다 많이 낮은 것을 발견하면 성능이 저하되는 문제를 라이브로 볼 수 없다는 것을 알 수 있습니다. 거기까지이고 바로 다른 지표를 참조하러 간다고 합니다.
참고 : http://izreal.egloos.com/v/36669, http://www.brendangregg.com/blog/2017-08-08/linux-load-averages.html, https://lunatine.net/2016/02/19/about-load-average/,
