MYSQL 인덱스 정리
데이터베이스는 프로그래밍에 있어서 데이터를 보관하는 저장소 개념입니다. 이런 데이터베이스를 다루는 것은 서버의 성능에 굉장히 많은 영향을 미치곤 합니다. 데이터베이스는 흔히 말하는 데이터 CRUD를 수행하는 주체이고, 이는 프로그램에 필요한 데이터가 많아지고 다양할수록 성능에 많은 영향을 끼치기 때문입니다. 이러한 이유로 데이터베이스를 다루는 기술은 매우 중요합니다. 데이터 베이스를 성능을 높히는데 있어 기본적이고 가장 중요한 개념인 인덱스가 있습니다. 인덱스는 쿼리문에 따라 어떤 인덱스가 타는 지 민감하게 변화하고, 원하는 인덱스를 타지 않는 등... 생각보다 복잡합니다. 그래서 오늘은 인덱스에 대해, 특히 제가 많이 사용하는 MYSQL의 인덱스에 대해 정리해보고자 합니다. MYSQL이라고 특별히 지칭하는 이유는 각 DBMS마다 쿼리를 최적화하는 Query Optimizer가 다르게 동작할 수 있기 때문입니다.
Query Optimizer
쿼리 최적화는 많은 관계형 데이터베이스 관리 시스템의 기능입니다. 쿼리 최적화 프로그램은 가능한 쿼리 계획을 고려하여 주어진 쿼리를 실행하는 가장 효율적인 방법을 결정하려고 합니다. 이 때 어떤 인덱스를 사용할 지 결정하게 됩니다.
인덱스란?
index [ˈɪndeks]
- 색인
- (물가임금 등의) 지수
- 지표
인덱스는 컴퓨터공학과 학생들에게는 데이터베이스의 인덱스보다 배열의 인덱스가 더욱 친숙하여 많이 혼돈이 옵니다. 그러나 자세히 들여다보고 생각하면 두 인덱스는 결국 비슷한 의미로 볼 수 있습니다. 인덱스는 결국 지정한 컬럼들을 기준으로 메모리 영역에 일종의 책갈피처럼 위치를 찾아가기 쉽게 만들어 놓은 것입니다. 데이터베이스는 기본적으로 unSortedList 정렬되지 않은 데이터이기 때문에 원하는 데이터를 찾기 위해서는 Full Scan을 하게 되어 있습니다. 우리가 unSortedList를 next로 모두 찾아가는 것과 동일하게 말입니다. 여기에 인덱스를 추가하여 원하는 데이터에 쉽게 접근할 수 있도록, 즉 SELECT 쿼리의 성능을 향상시키는 것입니다. UPDATE, DELETE도 결국 조건 문으로 조회를 하기 때문에 SELECT의 성능이 좋아지면 자연스레 같이 좋아지게 됩니다.
그렇다면 INSERT의 경우에는 어떨까요? INSERT는 성능이 저하됩니다. 사실 이 관점으로보면 UPDATE와 DELETE의 성능도 저하된다고 볼 수 있습니다. 인덱스는 마법처럼 그냥 성능이 좋아지게 만들어주는 것이 아니라 특정 컬럼에 맞춰 따로 찾기 좋게 정렬하여 저장해놓았기 때문에 성능이 좋아지는 것입니다. 따로 저장했기 때문에 해당 데이터에 변경(추가, 수정, 삭제)가 이루어진다면? 해당 데이터에 대하여 동기화 작업이 필요하기 때문에 이 작업에 대해서 성능이 저하된다는 것입니다.
인덱스 구성 방식
인덱스는 어떻게 저장해놨길래 성능이 좋아질 수 있는 걸까요? MYSQL에서 인덱스를 구성하는 방식은 B-Tree 방식과, Hash 방식 두 가지가 있습니다.
-
B-Tree 인덱스
가장 일반적으로 사용되는 인덱스 알고리즘입니다. 가장 오래된 알고리즘이고 성숙한 안정된 상태의 저장 방식입니다. 이 방식은 =, >, >=, <, <= 또는 BETWEEN 연산자를 사용하는 쿼리문의 비교에 사용할 수 있습니다. 또한 LIKE에 대한 인수가 %(와일드카드 문자)로 시작되지 않는 상수 문자열인 경우 색인을 LIKE 비교에 사용할 수 있습니다. -
Hash 인덱스
컬럼값을 해시값으로 계산하여 인덱싱하는 알고리즘입니다. 이는 = 연산자를 사용하는 평등 비교에만 사용되지만 매우 빠른 속도를 자랑합니다. 그리고 ORDER BY 작업에는 해당 컬럼의 Hash 인덱스가 존재하더라도 사용되지 않습니다.
인덱스 사용하기
인덱스의 크기
인덱스의 키는 길면 길수록 성능상 이슈가 있습니다. InnoDB (MySQL)은 디스크에 데이터를 저장하는 가장 기본 단위를 페이지라고 하며, 인덱스 역시 페이지 단위(16KB)로 관리 됩니다. 인덱스의 키 값이 커지게 된다면, 한 페이지에 넣을 수 있는 데이터의 수도 적어져 많은 페이지를 접근해야하고 이는 성능에 영향을 미치게 됩니다. 그리고 InnoDB에서는 인덱스를 생성할 수 있는 최대 컬럼의 크기를 767 Byte 로 제한하고 있습니다.
인덱스 컬럼 기준
인덱스를 생성하는데에 가장 조심해야할 점은 인덱스로 선정하는 컬럼입니다. 어떤 컬럼을 어떤 순서로 인덱스를 생성하냐에 따라서 성능에 많은 영향을 끼칩니다. 먼저 가장 중요시 해야하는 것은 선정하는 컬럼의 카디널리티(Cardinality) 입니다.
Cardinality
카디널리티(Cardinality)란 해당 컬럼의 중복된 수치를 나타냅니다. 카디널리티가 높다고 하면 해당 컬럼에 중복되는 값이 별로 없다는 뜻이고, 카디널리티가 낮다고 하면 해당 컬럼에 중복되는 값이 많다는 것을 뜻합니다. 예를 들면 주민등록번호는 카디널리티가 높고, 성별은 카디널리티가 낮습니다.
MYSQL의 Query Optimizer는 통계 정보를 이용하여 쿼리 플랜을 생성하게 됩니다. 이 통계 정보는 인덱스 컬럼에 대한 카디널리티/분포도에 의해 생성되기 때문에, 카디널리티에 유의하여 인덱스를 생성해야 합니다. 단일 인덱스를 생성하는 경우에는 카디널리티가 높은 컬럼으로 선정하는 것이 유리합니다. 인덱스를 통해 많은 부분을 걸러낼 수 있기 때문입니다.
그러나 복합인덱스의 경우에는 어떤 쿼리를 수행하는 지에 따라 다릅니다. 그래도 어느 정도의 규칙은 존재합니다.
=(Equal) 조건으로 쓰이는 컬럼을 좌측으로 배치 <, >, Between등의 Range 조건 혹은 order by, group by 조건으로 쓰이는 컬럼을 우측으로 배치으로 배치, 같은 조건이라면 카디널리티가 높은 컬럼 먼저 배치
Equal 조건을 좌측, Range 조건을 우측에 배치하는 것이 유리합니다. 그 이유는 Equal 구문은 단 하나만 만족하면 되기 때문에 좌측에 배치하여 먼저 정렬하고 Range 조건의 경우에는 해당 조건대로 정렬되어 있어야 찾기 편하기 때문입니다. 아래의 경우를 보면 Equal 구문과 Range 구문을 만족하는 데이터를 찾기 위해서 얼마나 많은 범위를 참조해야하는 지 비교하여 볼 수 있습니다.
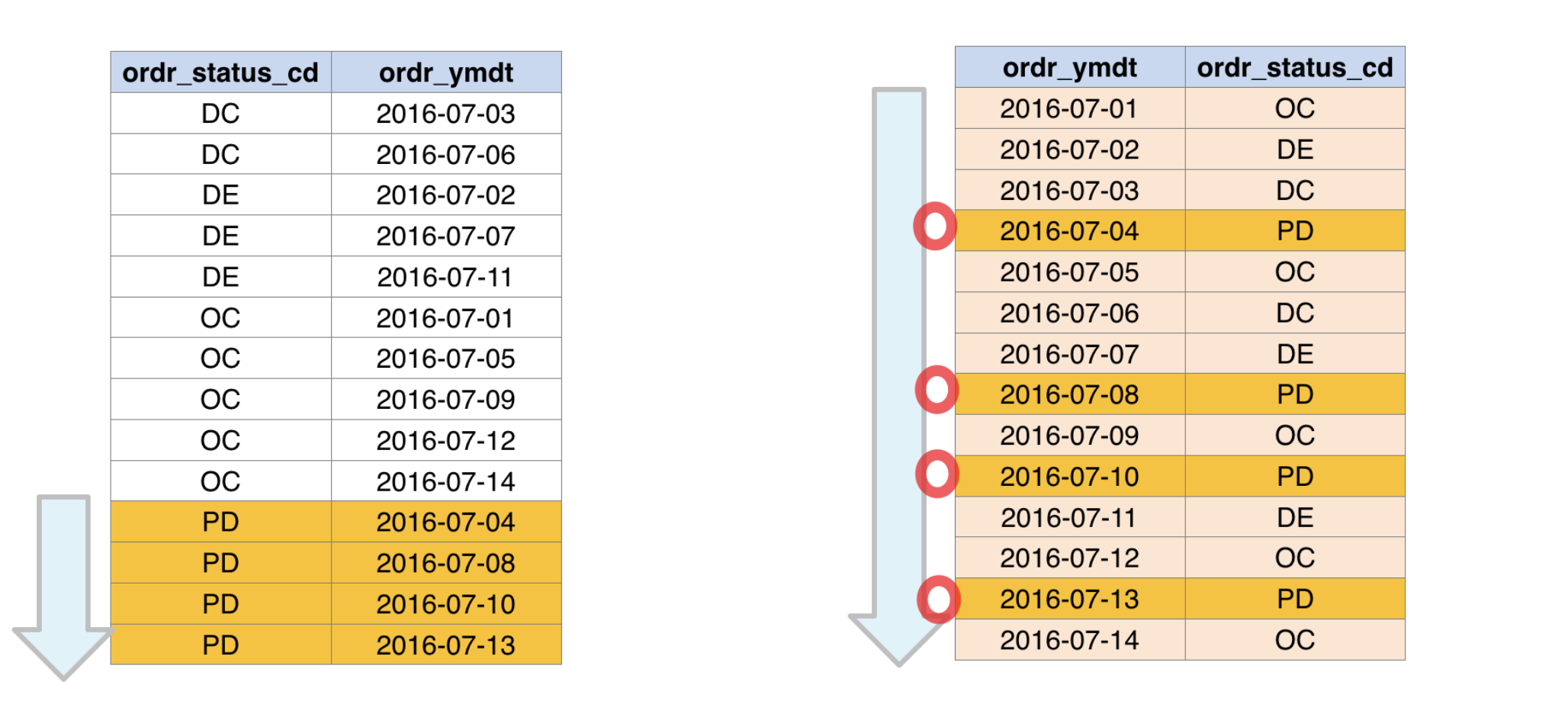
인덱스 사용 시 주의할 점
-
인덱스가 존재하더라도 부정형 쿼리에는 인덱스가 적용되지 않습니다.
-
AND 연산자는 각 조건들이 읽어와야할 ROW수를 줄이는 역할을 하지만, OR 연산자는 비교해야할 ROW가 더 늘어나기 때문에 풀 테이블 스캔이 발생할 확률이 높습니다.
-
인덱스로 사용된 컬럼값 그대로 사용해야만 인덱스가 사용됩니다. 컬럼 값에 연산을 가하거나, 다른 타입으로 조회하는 경우 인덱스를 타지 않습니다.
-
선행 조건에는 선택도가 좋은 컬럼으로 선정하는 것이 좋습니다. 첫번째 인덱스 컬럼이 조회 쿼리에 없으면 인덱스를 타지 않기 때문입니다.
-
인덱스는 적절한 수만 존재하는 것이 좋습니다.인덱스 종류에 따라 물리적인 공간을 요구하기 때문에 무분별한 인덱스는 오히려 용량만 차지하게 됩니다. 또한 Query Optimizer가 생성한 인덱스 중 어느 인덱스를 선택해야하는지에 대한 비용이 증가하기도 하고, 새로 추가함으로 원하지 않는 인덱스가 선택되어 성능이 저하되는 확률이 높아지기 때문에 인덱스를 생성하기 전에 많은 부분을 고려해보아야 합니다.
참조
https://jojoldu.tistory.com/243
https://mozi.tistory.com/199
https://dev.mysql.com/doc/refman/5.5/en/
