우선 라마(Llama) 2에 대해서는 데보션에 올라온 Meta LLM 패권 전쟁 격화시키다 : LlaMA2 상업적 이용가능 오픈소스로 공개 포스팅을 봐주세요.
라마2와 1의 기술적인 차이가 많지는 않은데요, 그 중에서도 모델 구조상 차이는 한 가지 뿐입니다.
바로 라마2에는 GQA (Grouped Query Attention)가 적용되었다는 점입니다.
이 기술은 추론 속도를 빠르게 하려고 도입되었는데요, 메타에서 개발한 것은 아니고 구글에서 발표하였습니다. 논문 링크
Grouped Query란
GQA를 설명하려면 우선 MQA (Multi-Query Attention)을 알아야 합니다.
그리고 MQA를 알려면 먼저 MHA (Multi-Head Attention)을 알아야 하는데요, MHA는 트랜스포머 논문에서 발표되었습니다.
이 글의 독자는 트랜스포머와 MHA는 잘 아신다고 가정하겠습니다.
그렇다면 MQA란 MHA와 어떤 차이가 있는 것일까요?
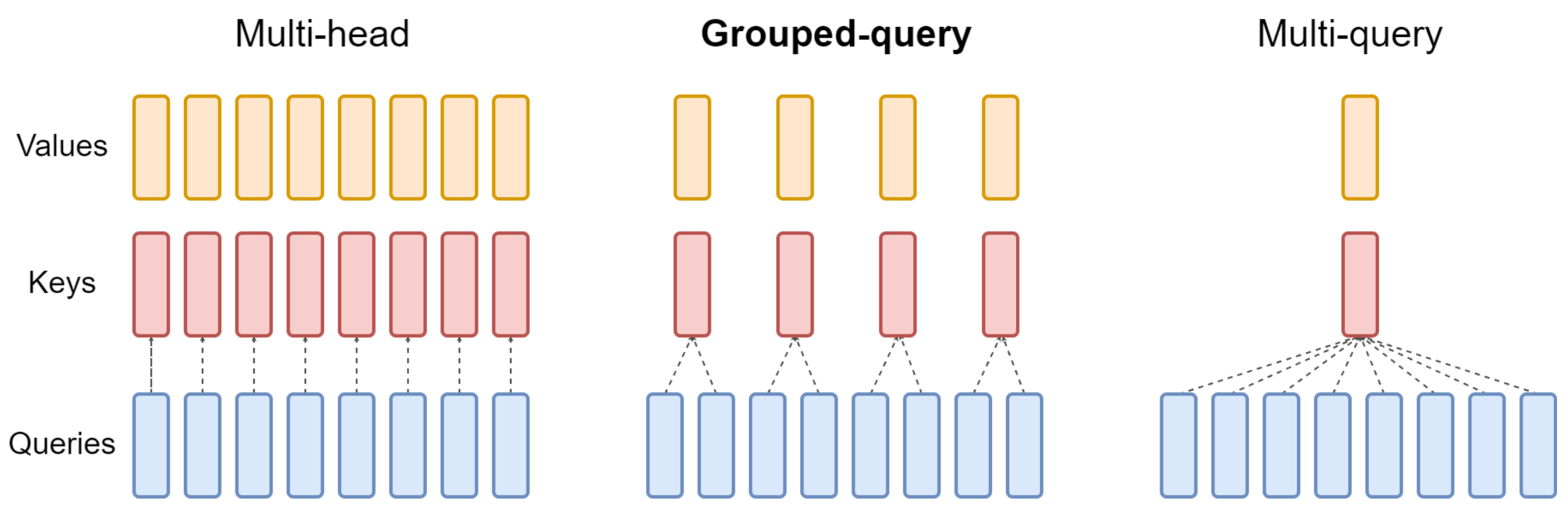
QKV (Query, Key, Value) head가 각각 H개씩 있는 MHA와 달리 MQA에서는 QKV 중에서 key와 value의 헤드가 하나씩만 있습니다.
Key와 value는 공유하는데, query는 여전히 여러개라서 multi query라고 부릅니다. 아래 그림의 왼쪽과 오른쪽을 보면 더 쉽게 이해할 수 있습니다.
MHA에 비해 MQA가 간결해 보입니다.
그림에서 짐작할 수 있듯, MQA는 메모리 대역폭을 절약할 수 있다는 장점이 있습니다.
그런데 MQA는 MHA에 비해 성능이 저하될 위험이 있고, 학습이 불안정하다는 문제가 있습니다.
이 문제를 해결하려고 GQA가 제안되었습니다.
위 그림의 가운데를 보면 GQA는 MHA와 MQA의 중간입니다.
H개 있던 KV 헤드를 1개로 줄이는 대신 적절한 G개의 그룹으로 줄이는 것입니다.
G가 1이 되면 MQA가 되고 H가 되면 MHA가 되니까 GQA는 MHA와 MQA를 포함한 일반화라고 볼 수 있습니다.
GQA의 성능
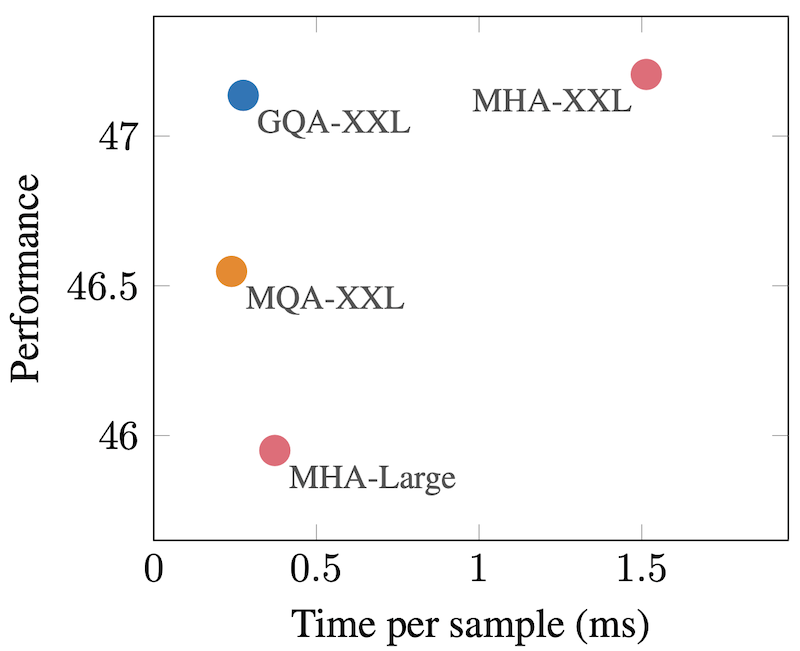
얼핏 보면 GQA는 MHA와 MQA의 중간에 있는 기법이니 성능도 어중간하지 않을까 걱정할 수 있는데요, 저자들이 T5 모델로 실험을 하였습니다.
아래 그림을 보면 GQA가 MQA와 비슷하게 빠르고 MHA와 비슷하게 성능이 좋은 훌륭한 방법임을 보여주고 있습니다.
보통 이렇게 두 가지 측면에서 모두 잘하기는 힘든데 역시 구글입니다.
GQA에서는 그룹 크기를 적절히 정해야 할 텐데 어떻게 정해줄까요?
대략 원래 있던 H의 제곱근 정도로 하면 됩니다. H가 64일 때 G가 8이면 적절한 성능이 나오는 것을 보여주는 그래프입니다:
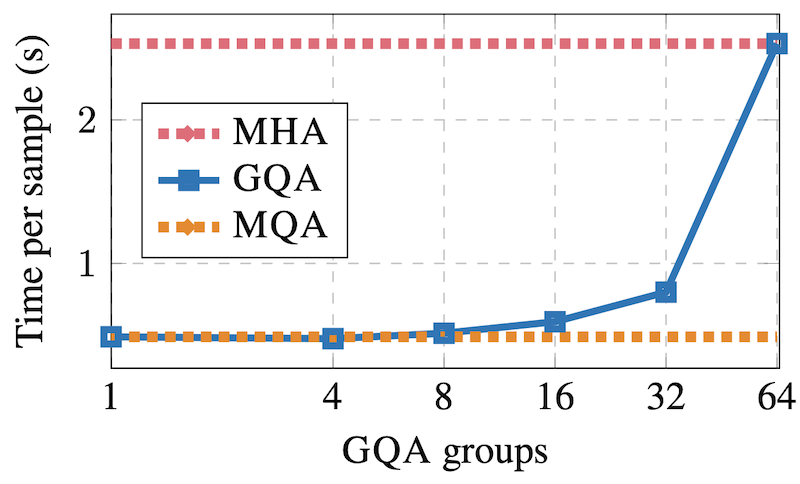
GQA는 학습 속도를 향상시키는 기술은 아니고요 (미미한 향상 효과는 있습니다), 위 그래프에 나오듯 추론 속도를 몇 배 향상시킵니다.
이미 만들어놓은 모델에도 GQA를 활용할 수 있을까?
LLM 학습에는 오랜 시간과 많은 자원이 투입되므로 모델을 다 만들어놓았는데 GQA를 새로 적용해서 다시 학습시키는 것은 큰 부담입니다.
다행히 GQA는 사후에 적용이 가능합니다.
아래는 pretrain된 모델에 대해서 추가로 𝛼%만큼 GQA로 학습시킬 때의 성능을 보여주는 그래프입니다. 𝛼가 높으면 좋지만, 아예 0일 때에도 GQA는 성능저하가 심하지 않습니다.
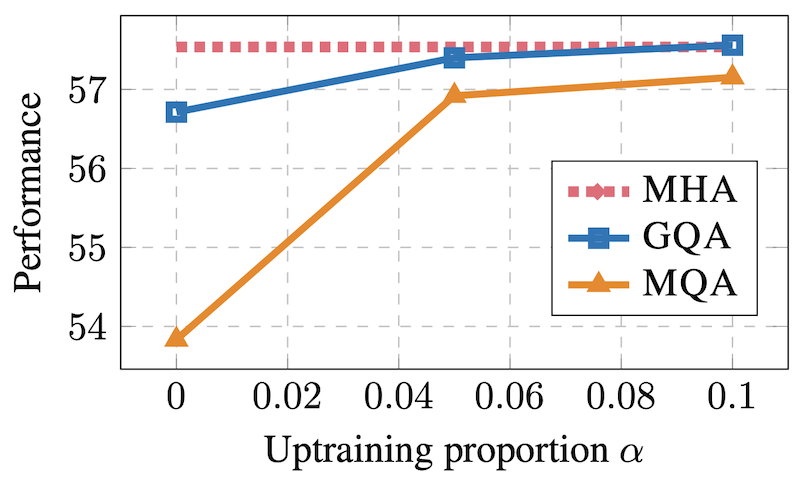
이 결과에 따르면 비록 라마2에서 7B, 13B는 GQA를 적용하지 않았고 70B만 GQA로 학습시켰지만, 7B, 13B에도 사용 가능하겠습니다.
물론 라마뿐만 아니라 다른 곳에서 만든 모델에도 마찬가지로 적용할 수 있습니다.
※ 이 포스팅에 등장하는 모든 그림은 GQA 논문에서 발췌하였습니다.
