언어 모델의 학습 속도를 FLOPs로 측정하기
FLOPs란
FLoating-point Operations를 줄여서 FLOPs라고 합니다. 이름 그대로 부동소수점 연산의 개수를 뜻합니다. 모델 학습에 정수 연산이나 논리 연산이 없는 것은 아니지만, 부동소수점 연산의 비중이 대부분이기 때문에 FLOPs를 측정하면 모델 학습에 걸리는 시간을 예측할 수 있습니다. 대학교의 컴퓨터 구조 수업에서는 실제로 측정한 속도만이 진정한 지표이고 FLOPs는 결함이 있는 지표라고 배우는데요, 이는 부동소수점 연산의 비중이 낮은 경우에는 실제보다 소요시간이 적게 추정될 수 있고, 다양한 부동소수점 연산이 있는 경우에 연산마다 속도가 다를 수 있기 때문입니다. 언어 모델 학습시에는 다량의 행렬 곱셈 시간 즉 부동소수점 곱셈 연산 시간이 학습 시간을 좌우하기 때문에 FLOPs가 유의미한 지표가 됩니다
FLOPS
FLOPs 이외에 FLOPS라는 지표를 들어본 분도 계실 것입니다. FLOPS는 Floating-point Operations Per Second의 약자로서 1초당 처리되는 FLOPs를 뜻합니다. 즉 FLOPS가 진짜 속도를 나타내는 지표입니다. 문헌에 따라서 FLOPs / s로 표기하기도 합니다.
FLOPs 계산 방법
FLOPs는 공식에 따라 계산할 수 있습니다. 실제로 코드를 실행할 필요가 없이 계산기나 엑셀을 활용하면 됩니다. 공식은 아래와 같습니다. 이 공식은 NVIDIA에서 Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM 논문에서 발표했습니다.
FLOPs = 96*global_batch_size*sequence_length*layers*(hidden_size^2)*(1 + sequence_length/(6*hidden_size) + vocabulary_size/(16*layers*hidden_size))변수가 꽤 많아 보이는데요, 언어 모델을 학습시킬 때에는 모두 반드시 알고 있어야 하는 변수들입니다
layers와hidden_size는 GPT 언어 모델의 레이어 수와 히든 노드 수이고 이것들이 모델의 파라미터 수를 결정합니다. attention head의 개수는 연산량에 영향이 없습니다.global_batch_size는 미니배치 크기입니다. data parallel 학습을 하는 경우에 각각의 GPU에서 학습하는 배치 단위인micro_batch_size와 구분됩니다.global_batch_size == micro_batch_size * data_parallel_size입니다sequence_length는 배치에서 샘플 하나의 길이입니다. 언어 모델은 텍스트를 학습시키는데 한 샘플은 보통 토큰 2048개 길이입니다. 최근의 모델들은 이보다 더 긴 길이를 사용하는 경우도 많습니다vocabulary_size는 토크나이저의 크기입니다
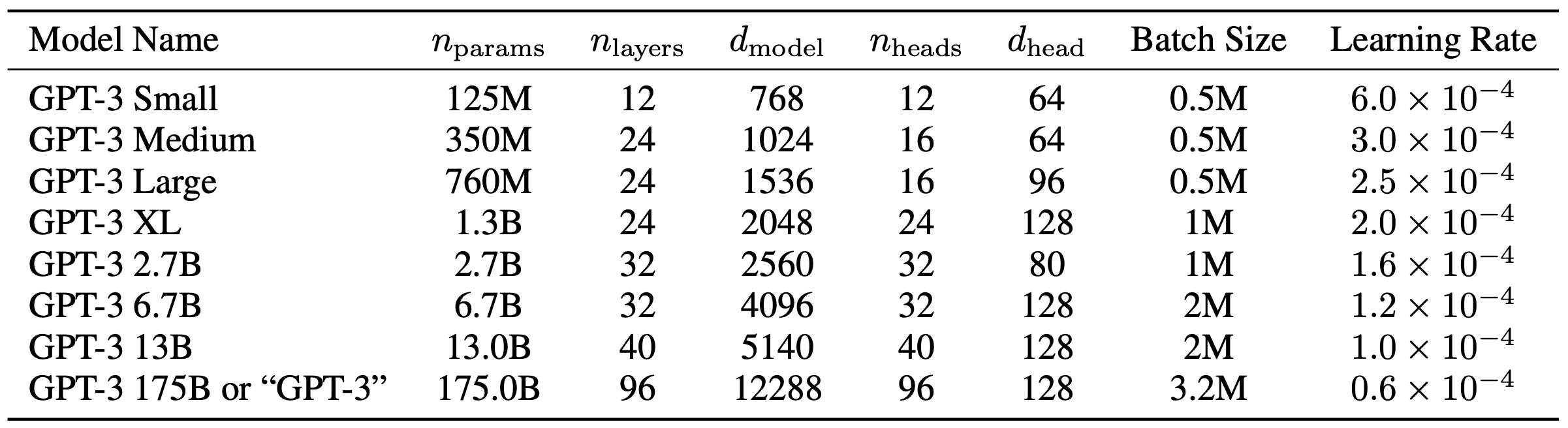
예를 들어 GPT3 6.7B의 경우 아래 표를 보면 layers는 32, hidden_size는 d_model과 같으므로 4096, batch_size는 2M인데 이는 토큰 단위이므로 샘플 수로 환산하면 1024, vocabulary_size는 tiktoken 라이브러리를 활용해서 알아보면 50257입니다.
이렇게 알아낸 숫자들을 공식에 대입해 보면 FLOPs는 아래와 같이 나옵니다. 수치가 꽤 큰데 FLOPs만으로는 해석이 용이하지 않고, FLOPS를 구해야 합니다.
FLOPs = 96*1024*2048*32*(4096^2)*(1 + 2048/(6*4096) + 50257/(16*32*4096)) = 119,683,816,368,373,760FLOPS 계산하기
FLOPs를 알아낸 뒤에 할 일은 FLOPS를 계산하는 것입니다. FLOPS는 1초당 FLOPs라고 말씀드렸죠. 학습의 한 iteration 즉, global_batch_size의 샘플을 처리하는 데에 몇 초가 걸리는지를 알아내면 FLOPS는 쉽게 구할 수 있습니다.
FLOPS = FLOPs * iter_per_secGPT3의 iter_per_sec는 알려져 있지 않지만, OpenLLaMA 6.7B 모델의 경우 TPU v4를 사용해서 1초당 2200 토큰을 학습했다고 알려져 있습니다. 그렇다면 2M 토큰 학습에는 953초가 걸렸을 것이므로 iter_per_sec은 1/953이 되겠습니다. FLOPS는 119,683,816,368,373,760이 나오네요. TPU v4가 pod당 1.1 exaflops로 알려져 있으니 1/10 정도가 나왔는데요 오픈라마 학습시에는 일부만 사용했을 수도 있습니다.
GPU를 사용하는 경우에는 계산된 FLOPS를 GPU 개수로 나눈 FLOPS/GPU로 비교를 하는 경우가 많습니다. 이러면 NVIDIA의 결과와 직접 비교할 수 있어서 사용하는 학습 코드가 얼마나 효율적인지 알 수 있습니다. 언어 모델 학습의 경우 이론적인 최대치인 약 300 TFLOPS/GPU의 절반인 150을 넘기면 괜찮다고 봅니다. (다만 최근 Flash Attention 2의 등장으로 200은 넘겨야 괜찮다는 주장이 있습니다)
토의
트랜스포머 모델은 self-attention이 연산 시간의 대부분을 차지합니다. 셀프어텐션 연산에는 입력 sequence의 길이의 제곱에 비례하는 시간이 걸리기 때문에 이것이 모델에서 입력 길이를 마냥 늘릴 수 없는 원인이 됩니다. 앞에서 제시했던 FLOPs 공식을 다시 보면 sequence_length가 곱하기로 들어가서 제곱에 비례하는 것이 맞다는 것을 확인할 수 있고요. 그런데 공식을 자세히 보면 두 번째 sequence_length는 6*hidden_size로 나누어 줍니다. 보통 hidden_size는 sequence_length에 비해 꽤 큰 값을 주게 됩니다. 그래서 실제 FLOPs를 구해 보면 sequence_length에 제곱 비례하는 결과가 나오지 않고 선형 비례에 가깝게 됩니다
FLOPs = 96*global_batch_size*sequence_length*layers*(hidden_size^2)*(1 + sequence_length/(6*hidden_size) + vocabulary_size/(16*layers*hidden_size))그런데 최근에는 기존의 1000~2000 수준을 넘어서 백만이나 십억 길이의 sequence_length를 처리할 수 있는 언어 모델이 등장했고, 이 모델들의 추론 시간은 sequence_length의 제곱에 비례하게 됩니다. 이를 극복하기 위한 방법들도 연구되고 있습니다.
