<데이터베이스 ERD 학습 중 새로 정리한 사항>
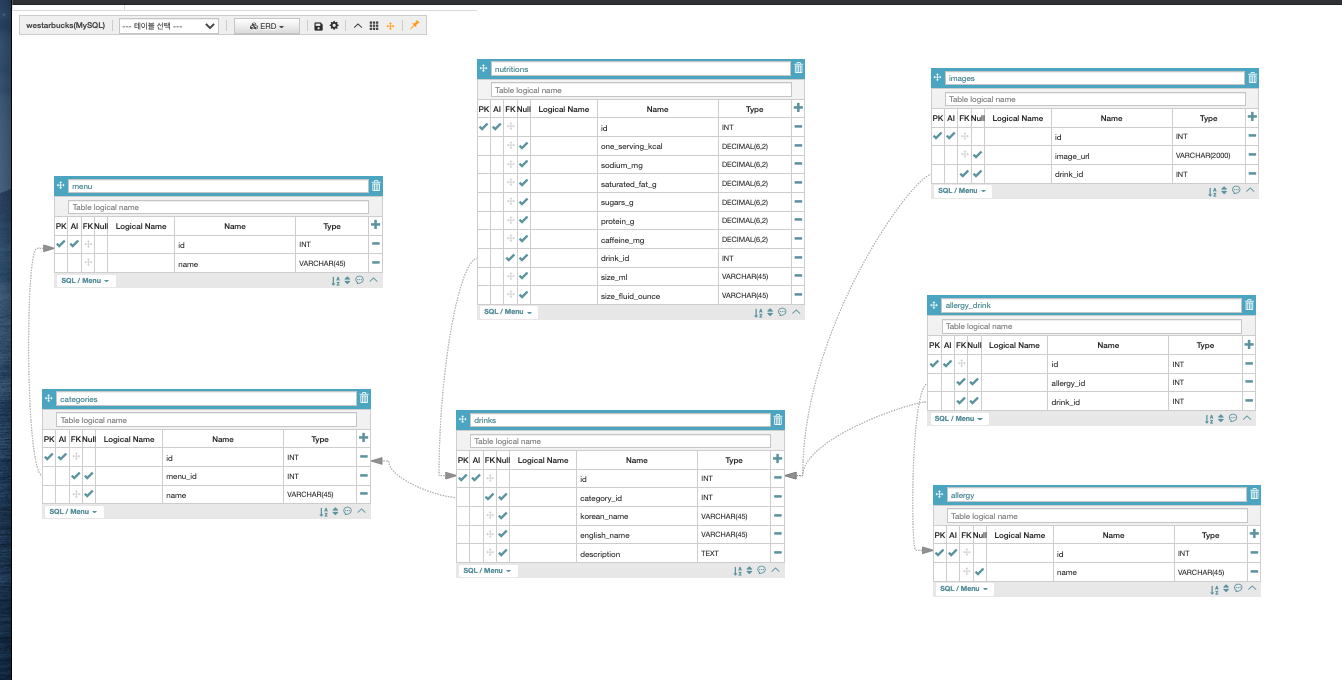
평소 궁금했던 것이 Foreign-key의 방향과 테이블 간의 관계(1:1, 1:다, 다:다)와 전에 했던 내용이 어떻게 구성되어 있고 어떤 식으로 수정되면 좋을지 고민하다가 멘토님께 다음과 같은 질문을 남겼다.(내용은 CRUD 스타벅스 자료)
분류의 전제 : 분석하다보니 뭔가 의미가 중요한 테이블이 (주제가 되는 테이블) 안에 들어가는 테이블을 받는다는 느낌을 받고 분석했습니다.
← : Foreign key 방향
Menu ← Categories : 메뉴 요소 당(음료, 푸드…) 카테고리(콜드브루, 브레드…) 의 하나에 하니씩 내용을 받아서 one to one.
Categories ← Drinks : 카테고리의 요소들이 실제 음료명을 하나에 하나씩 내용을 받아서 one to one.
Drinks ← Nutritions : 음료 하나 하나가 영양 성분의 내용 모두를 한 변수로 받기 때문에 one to one. 처음에는 영양 요소가 여러개가 있어서 one to many 로 생각했으나 drink가 포화지방 따로, 카페인 따로 foreign-key가 연결된게 아니라고 생각해서 one-to-one이라 분석했습니다.
Drinks ← Images : 음료 당 이미지 링크가 1:1로 매칭되므로 one-to-one.
Allergies와 Drinks의 관계 : foreign-key만 뺄 수 있게 ERD가 테이블 하나로 빠져 있는 것은 음료 하나 당 여러 알러지를 가질 수 있다는 뜻으로 생각했습니다. 그리고 음료의 프라임키에 바로 알러지를 연결하면 음료명이 중복되는 현상을 겪을 수 있으므로 드링크_id와 알러지_id를 따로 뺀 것이라고 정리하면서 생각이 들었습니다. 이렇게 되면 음료도, 알러지도 서로 다수의 값을 가질 수 있으므로 N:N 관계, 즉 many to many라 질문을 정리하면서 결정했습니다.(원래는 one to many라고 판단했습니다.)-
동기분과 생각 정리 :
결론 : 1, 2번 케이스는 one to many
이유 : 메뉴와 카테고리, 카테고리와 드링크의 관계는 참조당하는 쪽과 참조를 사용하는 쪽이라고 볼 수 있는데 참조하는 쪽은(외래키를 쓰는 쪽) 그 결과가 many하게 나온다.(콜드브루 : id1, 바닐라크림 콜드브루 : id1, 에스프레소 : id2) 따라서 고유값을 가지는 참조 당하는 쪽이 one, 참조하는 쪽이 many가 되어 one-to-many 가 된다. -
one to one의 경우는? : 참조 당하는쪽과 참조하는 쪽이 1:1인 경우
-
앞으로 to many가 되는 경우 : 고유값이 되는 id(참조 당하는 쪽) 를 테이블에 포함한다. 그리고 N 형태가 된다.(Foreign key 갖고)
-
여기에 따른 멘토님 답변 정리 :
마지막에 알러지와 드링크의 관계는 생각하다보니 1:다가 아니라 테이블이 추가된 다 : 다 였다.
- 그래서 우리조 테이블의 개선 사항??
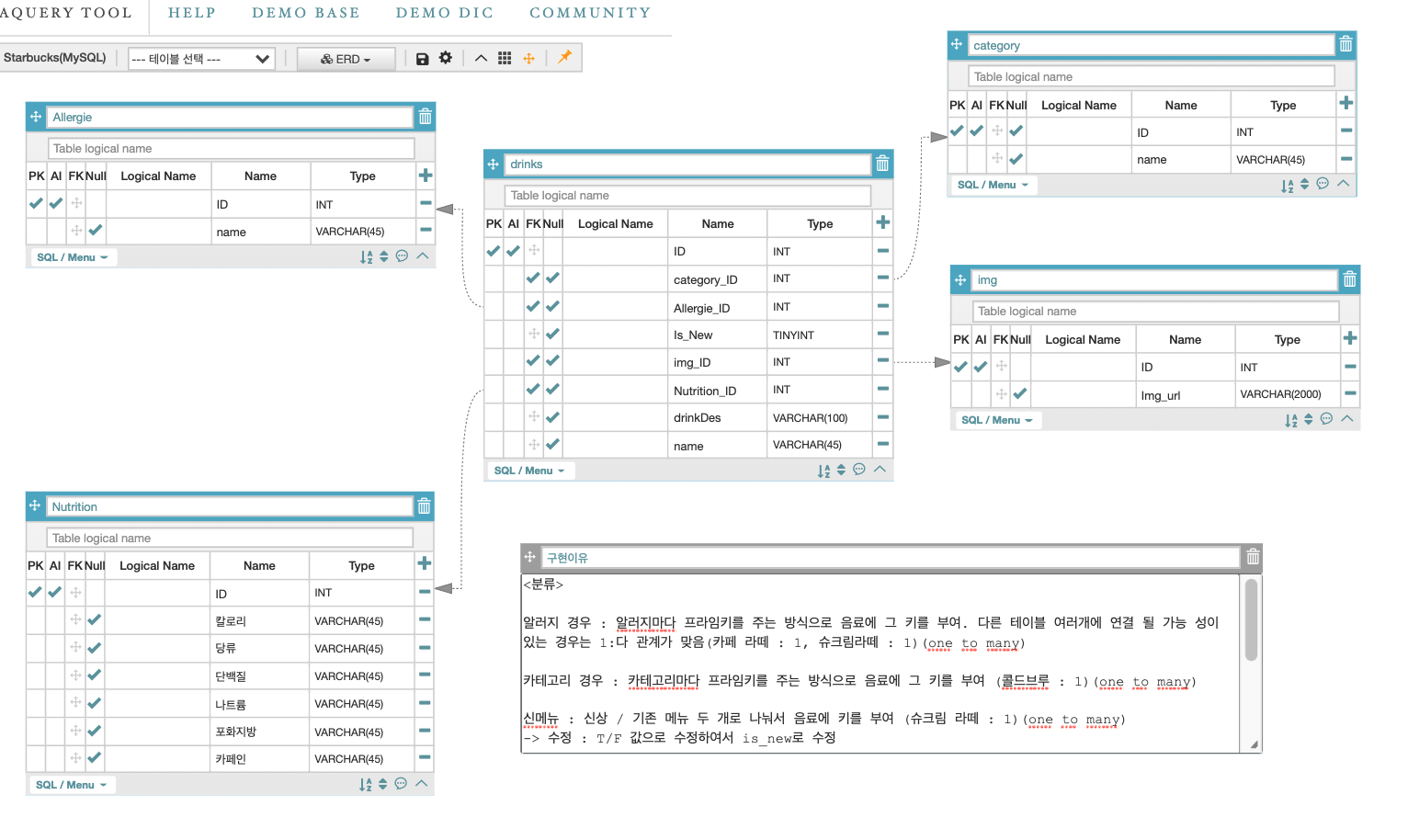
물론 틀린건 아니다. 배열로 치면
음료 | 알러지 | 카테고리 | 영양성분 | ...
이런식으로 나왔을 것이다. 근데 문제는 알러지가 겹치는 경우.
음료1 | 알러지1 | 카테고리 | 영양성분 | ...
음료1 | 알러지2 | 카테고리 | 영양성분 | ...
음료1 | 알러지3 | 카테고리 | 영양성분 | ...
그러면 이 줄이 두 줄, 세 줄 이렇게 중복 이 생긴다.
그래서 아예 테이블을 중복값을 분리해서 생각하는 데이터베이스를 만드는 것이 가장 최적화된 것이라고 판단했다.(결국은.. 과제 때 본 테이블이 최적이다.)
