로깅 시스템을 구축해 놓았지만 쌓인 로그들을 검색하고 관리할 수 있는 방법이 없을까...?
고민하고 자문을 구하던 중 엘라스특 서치를 사용해 로깅 프레임워크를 구현할 수 있다는 것을 알게 되었다. 그렇다면 로깅 시스템에 엘라스틱 서치를 적용하기 전 엘라스틱 서치가 무엇인지부터 알아봅시다.
사전지식
- 2015년 이후
beats추가되면서ELK보다 →ELK Stack이란 표현으로 더 많이 사용합니다. - 오픈소스에서 Stack이란?
개별적으로 역할하는 기능들을 모아서 연결해 유연하고 강력한 기능을 제공하는 기술단위
→ 즉 ELK도 하나의 스택이라 볼 수 있습니다. (ELK스택)


ElasticSearch (분석 및 저장기능)
- Data 저장소 역할
- Logstash를 통해 수신한 데이터의 저장소 역할을 합니다.
- Lucene 기반 검색 엔진
- 아파치 루씬: Java언어로 이루어진 오픈 소스 형태의 정보 검색 라이브러리
- RESTful 검색엔진
- JSON기반의 분산형 RESTful 검색엔진 입니다.
LogStash(수집기능)
- 수집로그 선정 + 엘라스틱 서치로 전송기능
- 수집할 로그를 선정해서
ElasticSearch전송하는 역할을 담당합니다.- Data 처리 파이프라인
- 서버사이드 데이터처리 파이프라인 입니다.
- 동시 Data 수집 (수집기능)
- 다양한 소스에서 동시에 데이터를 수집하고 변환하여 → stash 보관소로 보냅니다.
Kibana(시각화기능)
- Data 시각화
- 데이터를 시각적으로 탐색 + 실시간으로 분석할 수 있음
- HTML + Javascript엔진임
Beats
- 서버에 에이전트로 설치하여 다양한 유형의 데이터를 ElasticSearch또는 LogStash에 전송함
- 서버 에이전트 설치
- ElasticSearch에 전송
- LogStash에 전송
Beats의 종류
Filebeat: 보안장치, 클라우드, 컨테이너, 호스트 또는 OT에서 수집하는 로그와 파일을 경량화된 방식으로 전달
Metricbeat: 시스템과 서비스에서 메트릭을 수집함, CPU부터 메모리, Redis, NGINX까지 Metricbeat를 통해 다양한 시스템 통계를 전송할 수 있음
Packetbeat: 호스트와 컨테이너의 데이터를 LogStash 또는 ElasticSearch에 전송하는 경량 네트워크 패킷 분석기
Winlogbeat: Windows이벤트 로그를 ElasticSearch와 LogStash로 스트리밍함
Auditbeat: Linux 감사 프레임워크 데이터를 수집하고 파일 무결성 모니터링 이벤트를 실기산으로 전송해 추가적인 분석이 가능하도록 지원
Heartbeat: 활성 상태를 감지하고 서비스가 가능한지 모니터링 → URL 목록을 제공하면 Heartbeat에서 “잘 작동중인가?” 라는 간단한 질문을 한 후, 향후 분석을 위해 정보와 반응 시간을 전송함
Functionbeat: 클라우드 서비스 제공자의 Function as a Service(FaaS) 플랫폼에서의 기능으로 배포하여 클라우드 서비스로부터 데이터를 수집, 전송, 모니터링 합니다.

ELK Stack의 구성도
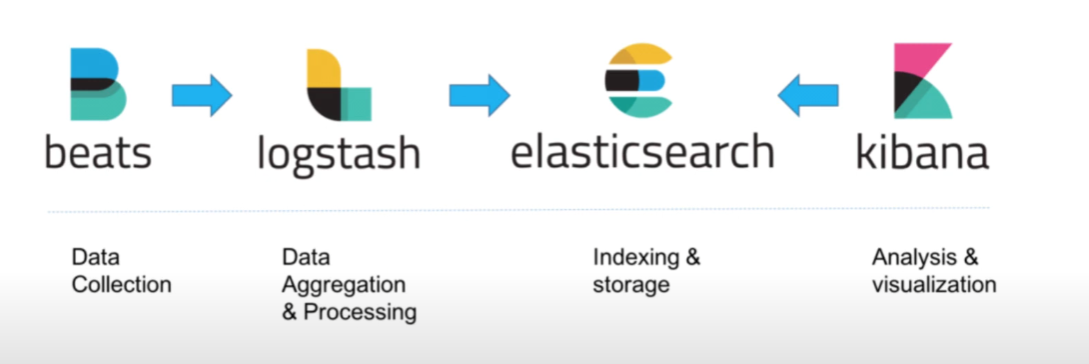
Beats를 통해 데이터를 수집하고 → Logstash로 전송되어 처리 → 이후 ElasticSearch로 전송된다.
ElasticSearch 저장소와 검색 등의 기능을 이용해 → Kibana에서 대시보드나 Discover 기능을 통해 시각화 할 수 있습니다.
ElasticSearch 아키텍처 및 용어
(엘라스틱 클러스터 구조, 아키텍쳐)
인덱스 내부구조
클러스터란?
여러대의 컴퓨터 혹은 구성요소들을 논리적으로 결합해 → 전체의 하나의 컴퓨터 혹은 하나의 구성 요소처럼 사용할 수 있게 해주는 기술
1. Elasticsearch 클러스터
ElasticSearch에서 가장 큰 시스템 단위를 의미
하나 이상의 노드의 집합 모든 노드는 서로 협력하여 데이터를 저장하고 검색 작업을 수행
서로 다른 클러스터는 데이터의 접근, 교환을 할 수 없는 독립적인 시스템으로 유지되며, 여러 대의 서버가 하나의 클러스터를 구성할 수 있고 한 서버에 여러 개의 클러스터가 존재할 수 있다.
2. 노드(Node)
클러스터에 포함된 단일 서버
데이터를 저장하고 클러스터의 색인화 및 검색 기능에 참여
역할에 따라 Master-eligible, Data, Ingest, Tribe 노드로 구분할 수 있습니다.
Master-eligible Node- 클러스터를 제어하는 마스터로 선택할 수 있는 노드
- 인덱스 생성, 삭제
- 클러스터 노드의 추적, 관리
- 데이터 입력 시 할당할 샤드 선택
- 클러스터를 제어하는 마스터로 선택할 수 있는 노드
Data Node- 데이터(Document)가 저장되는 노드
- 분산 저장되는 물리적 공간인 샤드가 배치되는 노드
- CRUD, 색인, 검색, 통계 등의 데이터 작업을 수행하므로 많은 자원을 필요로 한다.
- 따라서 모니터링 작업을 해야 하고, 마스터 노드와는 분리해야 한다.
Ingest Node- 데이터를 변환하는 등 사전 처리 파이프라인을 실행하는 역할
Coordination Only Node- 로드 밸런싱 역할을 담당
- 사용자의 요청을 받고 RR 방식으로 분산을 하는 노드
- 클러스터에 관련된 것은 마스터 노드로 넘기고, 데이터와 관련된 것은 데이터 노드로 넘긴다.
여러개의 노드로 클러스터를 구성하는 이유는??
다수의 노드로 클러스터를 구성하면 하나의 노드에 장애가 발생해도
다른 노드에 요청할 수 있기 때문에 안정적으로 클러스터를 유지할 수 있고 이를 통해서 높은 수준의 안정성을 보장할 수 있기 떄문입니다.
3. 인덱스(Index)
데이터를 저장하는 논리적 단위
예를 들어, 로그 데이터의 인덱스, 제품 정보의 인덱스 등으로 나눌 수 있습니다.
인덱스: RDBMS에서의 database와 대응하는 개념타입: table과 대응하는 개념도큐먼트: row와 대응하는 개념. JSON 형식
4. 샤드(Shard)
인덱스를 더 작은 부분으로 나눈 것
인덱스 내부의 색인된 데이터를 여러 물리적 공간에 나뉘어 저장.
각 샤드는 독립적인 Lucene 인덱스이며, → 여러 샤드를 사용하여 대규모 데이터를 분산하여 저장할 수 있습니다.
- 프라이머리 샤드
- 데이터의 원본
- Elasticsearch에서 데이터 업데이트 요청을 날리면 반드시 프라이머리 샤드에 요청하게 되고, 해당 내용은 레플리카 샤드에 복제된다.
- 레플리카 샤드(복제)
- 프라이머리 샤드의 복제본
- 원본 데이터가 망가졌을 때, 대신 사용하면서 장애를 극복하는 역할을 수행합니다.
- 따라서 원본인 프라이머리 샤드와 동일한 노드에 배정되지 않음
5. 세그먼트(Segment)
각 샤드 내부에서 데이터가 저장되는 단위
데이터가 추가되거나 업데이트되면 새로운 세그먼트로 기로됩니다.
각 샤드는 다수의 세그먼트로 구성되어 있으므로 검색 요청을 분산 처리하여 훨씬 효율적인 검색이 가능합니다.
- 샤드에서 검색 시, 먼저 각 세그먼트를 검색하여 결과를 조합한 후 최종 결과를 해당 샤드의 결과로 반환하게 된다.
- 세그먼트는 내부에 색인된 데이터가 역색인 구조로 저장되어 있으므로 검색 속도가 매우 빠르다.
