오랜만에 돌아왔습니다...
그동안 엘라스틱 서치 도입,성능개선, CICD와 무중단배포 구축 등 여러 일을 진행하다 보니 수많은 트러블 슈팅과 배움에 시간이 걸렸습니다.
앞으로 하나하나 그동안의 과정을 정리해 보려고 합니다.
그 중 오늘은 저번에 연재했던 elasticsearch를
프로젝트에 도입하게 된 과정과 겪었던 트러블 슈팅에 관해서 인사이트를 나누고자 합니다.
엘라스틱 서치를 도입해 서버에 나타나는 로그를 검색하고 쉽게 찾을 수 있도록해
로깅 프레임워크를 구현하고자 하였습니다.
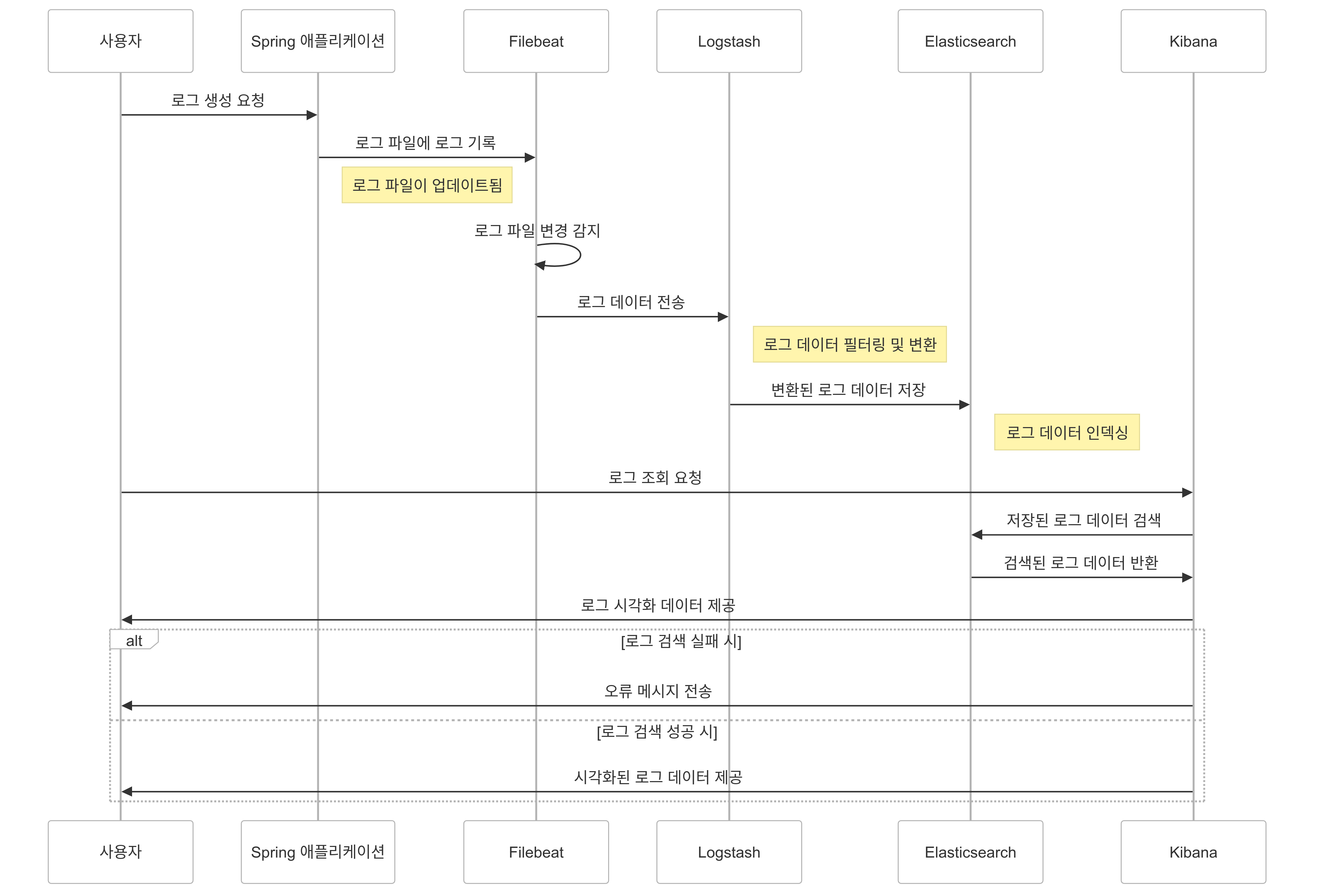
로깅 시스템 시퀀스 다이어그램
먼저 엘라스틱 서치로 로깅을 검색하기 위해
로깅파일을 어떻게 수집하고 처리할 것인지에 대한 시퀀스 다이어그램을 짜는것이 필요했습니다.
따라서 다음과 같은 전략을 짜보았습니다.
1. Spring 애플리케이션에서 로그가 생성됩니다.
2. Filebeat가 Spring 애플리케이션에서 생성된 로그를 수집합니다.
3. Logstash는 Filebeat에서 전달받은 로그를 처리합니다.
4. Elasticsearch는 Logstash로부터 처리된 로그를 저장합니다.
5. Kibana는 Elasticsearch에 저장된 로그를 시각화하여 사용자에게 제공합니다. (UI제공)
첫번째 시도: EC2하나를 더 띄워서 로깅 프레임 워크 구축하자
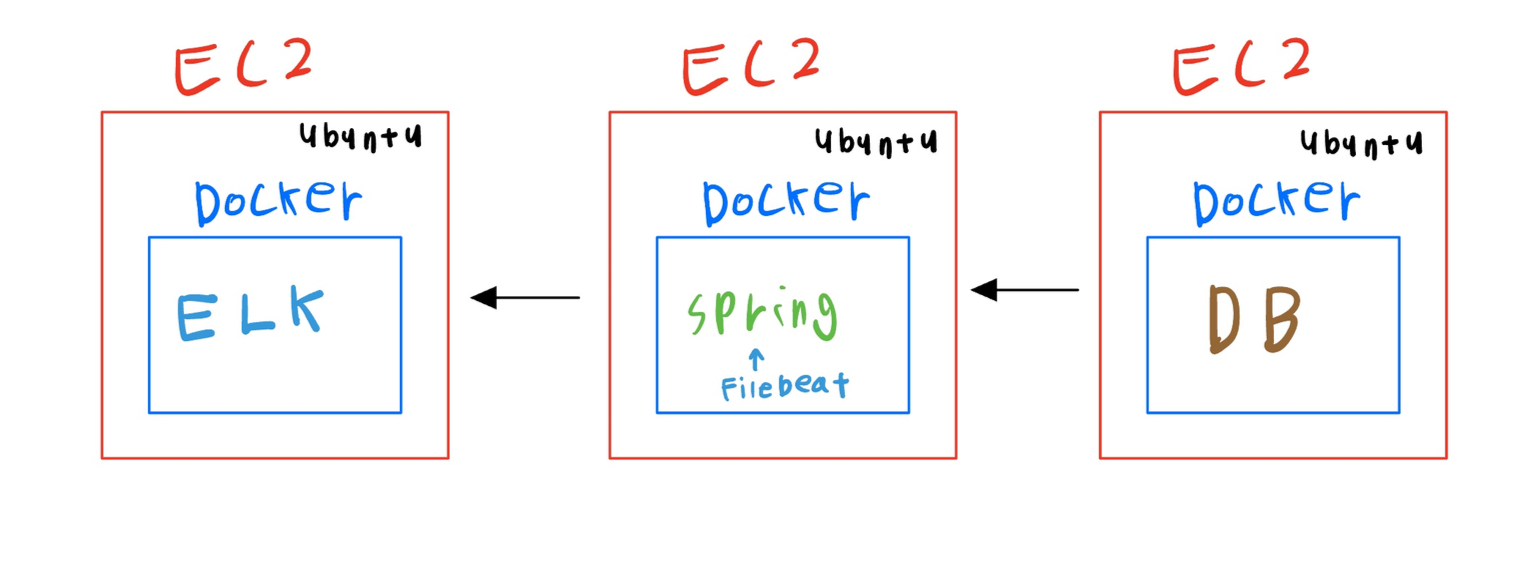
1. 현재 저희의 서버는 각각의 EC2 안에 Spring, DB가 띄어져 있습니다.
2. 로그 수집을 위해 Filebeat를 스프링 서버에 붙이고
3. 하나의 EC2서버를 더 띄우고 우분투와 도커를 설치한 후
ELK 이미지를 통해 컨테이너를 설치해 로깅검색 시스템을 만들고자 하였습니다.
의문점: 왜 굳이 하나의 EC2로 띄우지 않고 이렇게 복잡하게 설계했나요???
재정적인 문제 때문이었습니다.
하나의 EC2안에 ELK, Spring, DB를 다 띄우는것이 좋습니다.
하지만 프리티어를 계산해보니 13GB정도의 용량이 주어집니다.
운영체제, 도커, 스프링을 설치하면 ELK를 설치할 용량이 나오지 않았습니다.
따라서 여러개의 EC2를 띄우고 연결하는 방법을 사용해야 했습니다.
트러블슈팅: 결국 돈이 문제다.
하나의 EC2안에 Ubuntu, Docker, ELK를 전부 설치하려 했지만!
용량문제가 또 터져버렸습니다!
이것을 해결하기 위해선 → EC2서버의 티어를 올려 용량을 확보하는 것이 해결책이라는 생각이 들었고 팀원들과 긴급 회의에 들어갔습니다.
AWS 티어를 올려서 EC2용량을 확보하는 것에 대한 회의를 2시간 정도 나누어보았습니다.
결론은 아래와 같이 나왔습니다.
- 아직 실제 서비스가 되지 않았고 구현단계이기 때문에 로깅시스템 하나를 위해서 서버의 티어를 올리게 되는것은 부적절 할 수 있을것 같다.
- 티어를 올리게 되면 서버비가 한달에 20만원 정도 넘게 나오는데 이것이 부담이 되는 사람들이 있을 것 같다.
따라서 다른 해결책을 찾아야 했습니다.
팀원들과 회의를 한 결과 내 컴퓨터에 가상머신을 설치해 ELK 설치, 스프링, DB까지 연결해
내 PC를 로깅서버로 사용하면 용량문제가 해결될것 이라는 결론이 나왔습니다.
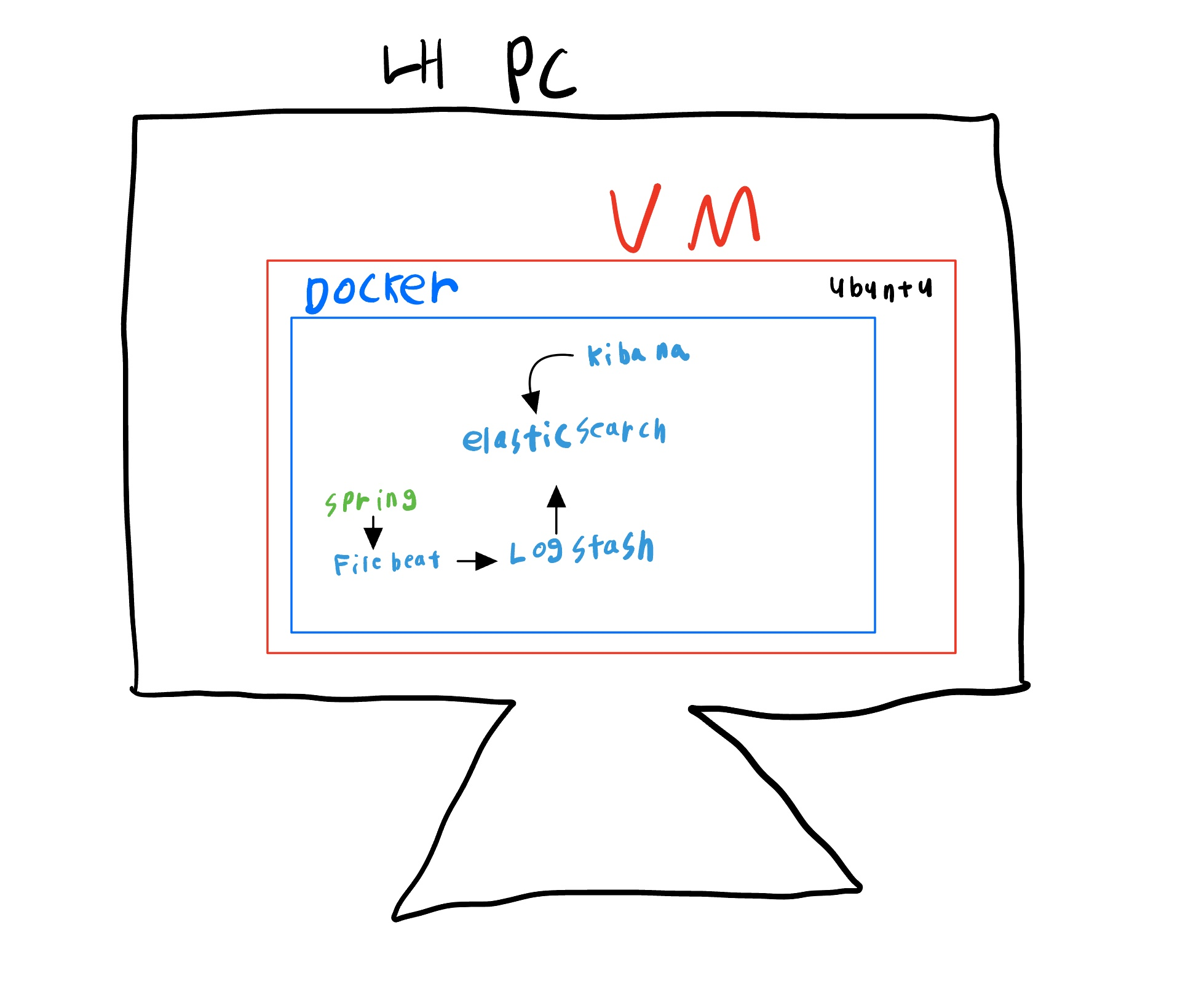
두번째 시도: 로컬환경에 가상서버를 만들어보자
PC에 VM을 설치했지만 실행되지 않는 문제가 있었습니다.
AMD 바이오스에서 가상머신을 활성화 하는 것으로 해결할 수 있었습니다.
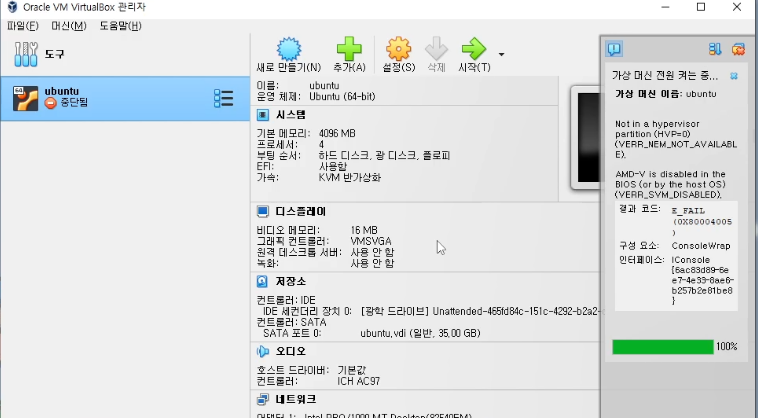
용량 50GB, 메모리8GB의 가상 서버를 만들었습니다.
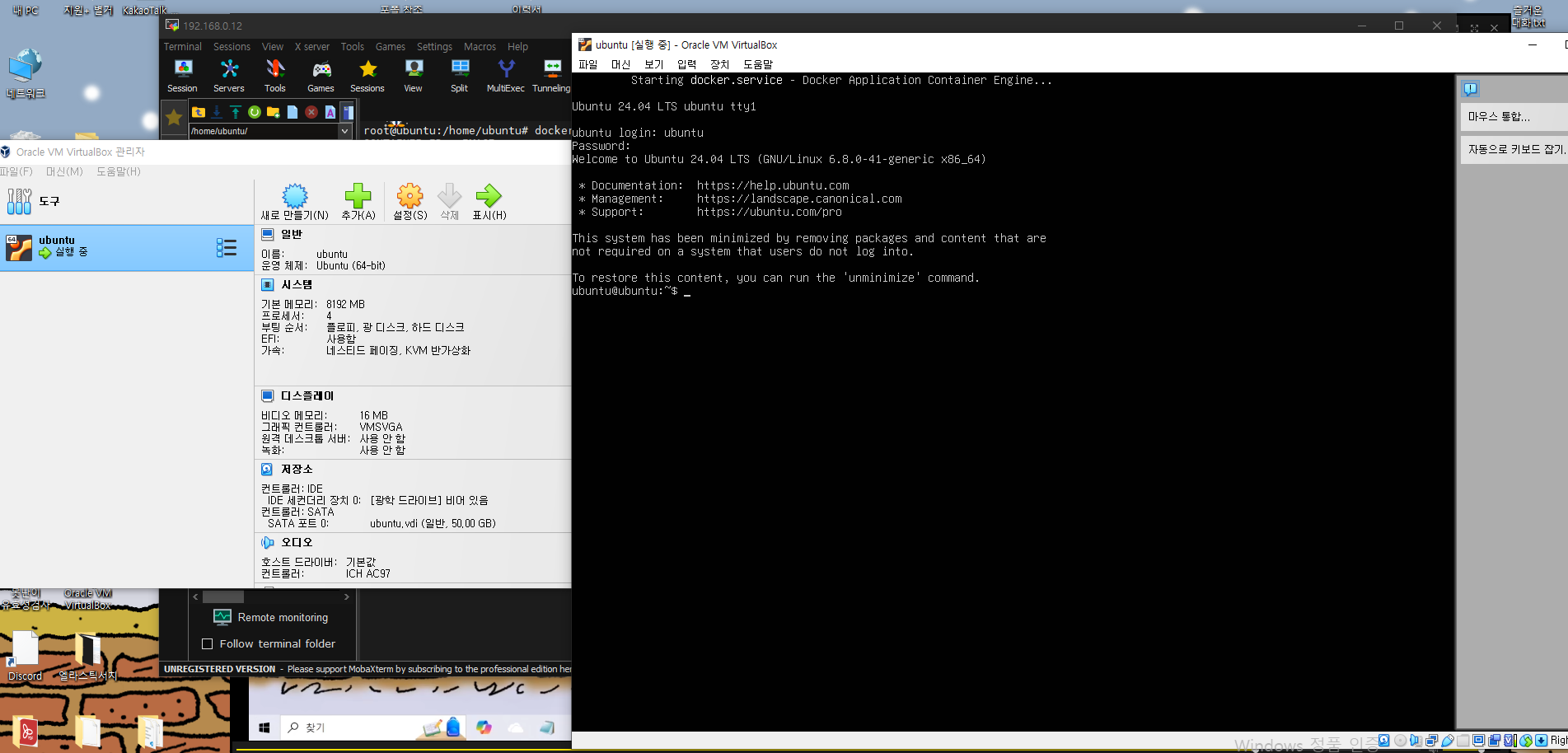
가상 서버에 로깅 프레임 워크를 만들자.
1. 가상 서버에 Docker-Compose.yml 파일을 만들고
yml 파일안에 이미지 주소를 넣어 ELK를 간편하게 설치 할 수 있었습니다.
-
vim docker-compose.yml (docker-compose.yml 문서 작성)
-
문서를 작성한 후 :wq 로 저장
-
docker-compose up -d 명령어로 yml파일을 보고 설치를 해줍니다
version: '3.7' services: elasticsearch: image: docker.elastic.co/elasticsearch/elasticsearch:8.9.0 container_name: elasticsearch environment: - discovery.type=single-node - ES_JAVA_OPTS=-Xms512m -Xmx512m - xpack.security.http.ssl.enabled=false - xpack.security.transport.ssl.enabled=false - xpack.security.enabled=false ulimits: memlock: soft: -1 hard: -1 volumes: - es_data:/home/ubuntu/elasticsearch/data ports: - "9200:9200" logstash: image: docker.elastic.co/logstash/logstash:8.9.0 container_name: logstash volumes: - ./logstash/pipeline:/home/ubuntu/logstash/pipeline ports: - "5044:5044" - "9600:9600" kibana: image: docker.elastic.co/kibana/kibana:8.9.0 container_name: kibana environment: - ELASTICSEARCH_HOSTS=http://elasticsearch:9200 # - ELASTICSEARCH_SSL_VERIFICATIONMODE=none ports: - "5601:5601" volumes: es_data:
2. logstash를 → elasticsearch에 연결하기 위해 logstash설정파일을 만들었습니다.
- cd /home/ubuntu (폴더위치로 이동)
- mkdir logstash (디렉토리 만들기)
- mkdir pipeline (디렉토리 만들기)
- vim /home/ubuntu/logstash/pipeline/logstash.conf (logstash설정파일 만들기)
input { beats { port => 5044 } } filter { # 필요한 필터링 옵션 추가 가능 } output { elasticsearch { hosts => ["http://elasticsearch:9200"] index => "%{[@metadata][beat]}-%{+YYYY.MM.dd}" } }
3. 현재 배포되고있는 Spring 서버는 DocherHub에 올라와 있습니다.
따라서 “Spring 이미지&컨테이너 생성 및 실행” 하여
저의 가상머신으로 복제설치를 완료했습니다.
docker run \
--name cleanroom -d \
-p 8080:8080 \
-e PROFILES=local \
-e ENV=local \
-e DB_URL=jdbc:mysql://db.clean-room.co.kr:3306/cleanroom \
-e DB_USERNAME=root \
-e DB_PASSWORD=Roqkdwjd1! \
-e JWT_SECRET=mIUc5GmVucQYgVv6hNRPVO3kPvnV2SbRXYxB7aQ9g= \
-e SERVER_IP=192.168.0.12 \
-e SERVER_PORT=8080 \
-v /home/ubuntu/logs:/logs \
jhchoen/cleanroom:latest4. 스프링의 로그를 수집하기 위해 Filebeat를 설치하였습니다.
- cd /home/ubuntu/ (홈으로 이동)
- mkdir filebeat (디렉토리 만들기)
- cd /home/ubuntu/filebeat (이동)
- vim filebeat.yml (filebeat.yml만들기)
cd /home/ubuntu/
mkdir filebeat
cd /home/ubuntu/filebeat
vim filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/*.log # 수집할 로그 파일 경로
output.logstash:
hosts: ["192.168.0.12:5044"] # Logstash 호스트와 포트 설정5. 이후 logs 라는 로그를 수집할 폴더를 만들어주고 Filebeat와 폴더를 연결해주었습니다.
- cd /home/ubuntu/(홈으로 이동)
- mkdir logs (디렉토리 만들기)
docker run -d \ --name filebeat \ -v /home/ubuntu/filebeat/filebeat.yml:/usr/share/filebeat/filebeat.yml \ -v /home/ubuntu/logs:/var/log \ docker.elastic.co/beats/filebeat:7.17.10
지금까지 작업 확인
elasticsearch,Logstash,kibana설치를 완료- Spring 이미지&컨테이너 생성 및 실행
- Filebeat를 설치 및 → Logstash 연결
logstash설치 및 →elasticsearch에 연결
여기까지 완료했습니다. docker ps 명령어로 잘 설치가 되어있음을 확인할 수 있습니다.

이제 elasticsearch 가 Kibana에 잘 뜨는지 확인만 하면 됩니다.
Kibana 설정 및 모니터링
VM이 켜져있는 상태에서 키바나를 접속할 수 있습니다.
홈 화면 왼쪽에서 Stack Management로 이동합니다.
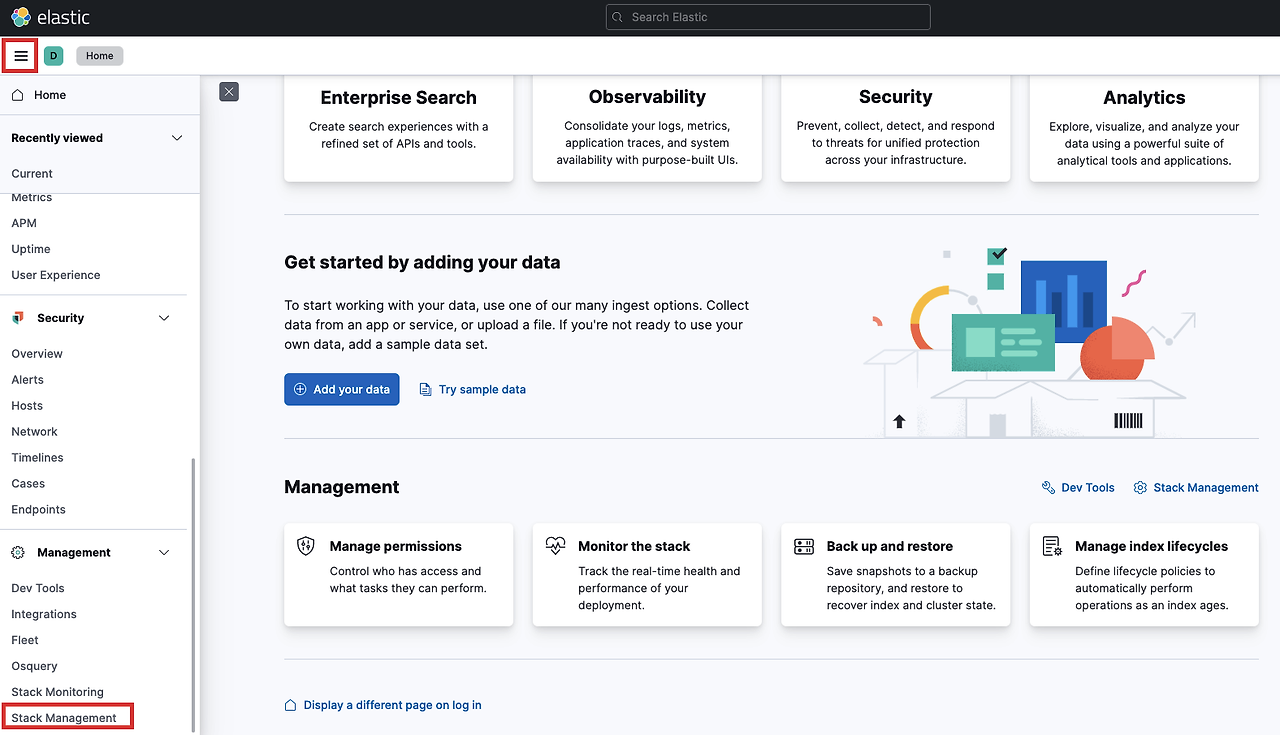
Index Patterns을 클릭하고, Create index pattern을 누릅니다.
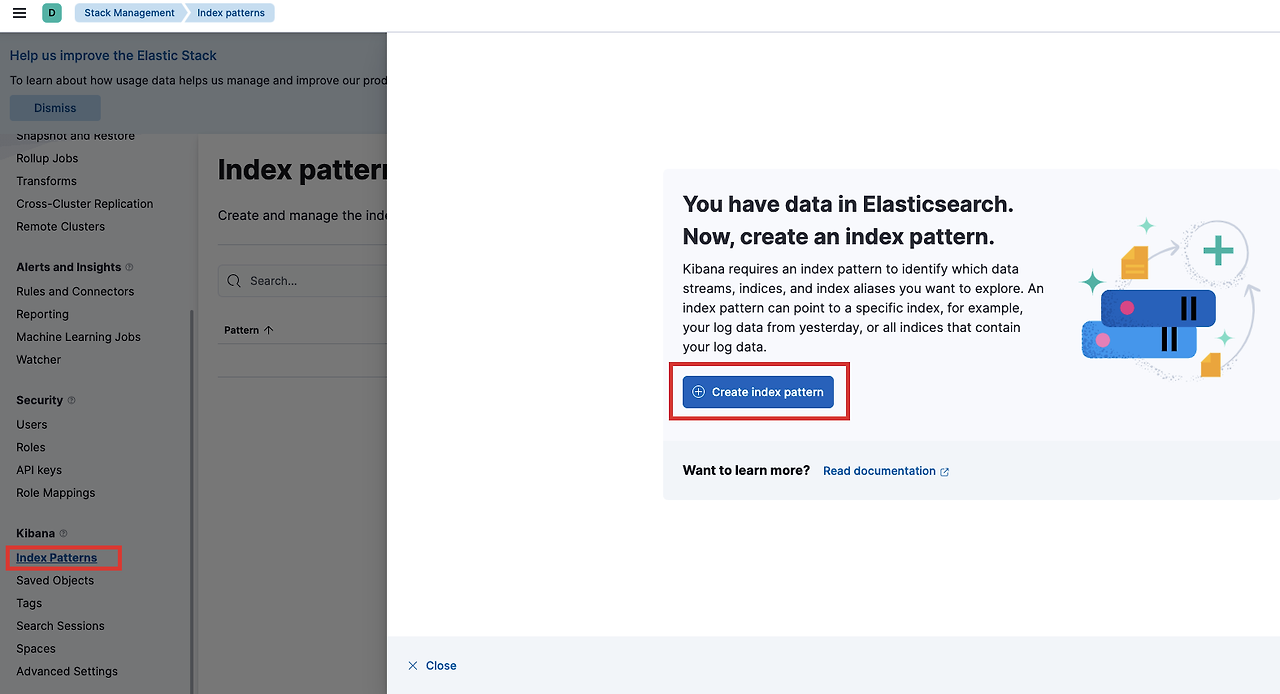
logstash*로 인덱스 패턴을 추가해줍니다.
이제 모니터링 화면(Discover)에서 로그를 확인할 수 있게 됩니다.
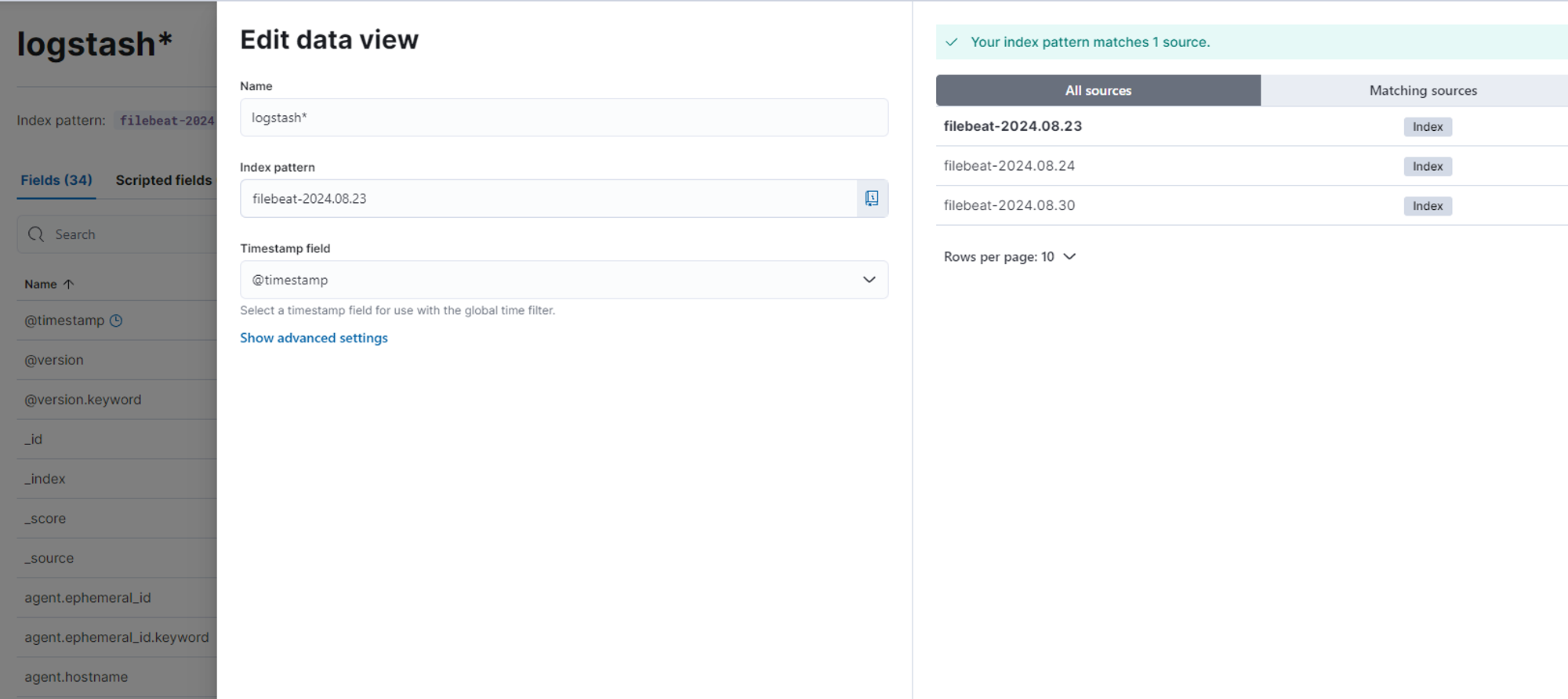
Discover로 이동하여 로그를 검색하고 확인할 수 있게 되었습니다.
로그 검색 방법
- 기본 검색
특정 키워드가 포함된 로그를 검색하려면 다음과 같이 입력하면 됩니다.message: "ERROR"
-
날짜 범위 검색
특정 시간 범위 내의 로그를 검색하려면 다음과 같이 할 수 있습니다.@timestamp >= "2024-08-23T19:46:00" AND @timestamp <= "2024-08-23T19:47:00" -
여러 조건을 사용한 검색
여러 조건을 결합하여 더 구체적인 로그를 검색할 수 있습니다.
아래 쿼리는host.name이 "my-server"이고status가 "500"인 모든 로그를 반환합니다.host.name: "my-server" AND status: "500" -
필드 존재 여부 검색
특정 필드가 존재하는 로그만 검색 할 수 있습니다.
아래 쿼리는error필드가 존재하는 모든 로그를 반환합니다._exists_: error
- 와일드카드 검색
특정 패턴을 포함하는 로그를 검색하려면*를 사용할 수 있습니다.
아래 쿼리는message필드에 "exception"이 포함된 모든 로그를 검색합니다.```java message: "*exception*" ```
- 복합 조건 검색
여러 조건을 복합적으로 사용할 수도 있습니다.
아래 쿼리는host.name이 "my-server" 또는 "another-server"이고status가 "404"인 로그를 검색합니다.(host.name: "my-server" OR host.name: "another-server") AND status: "404"
